
 Périphériques technologiques
IA
Google lance Vid2Seq multimodal, comprenant le QI vidéo en ligne, les sous-titres ne seront pas hors ligne CVPR 2023 |
Périphériques technologiques
IA
Google lance Vid2Seq multimodal, comprenant le QI vidéo en ligne, les sous-titres ne seront pas hors ligne CVPR 2023 |
Google lance Vid2Seq multimodal, comprenant le QI vidéo en ligne, les sous-titres ne seront pas hors ligne CVPR 2023 |

Des médecins chinois et des scientifiques de Google ont récemment proposé le modèle de langage visuel pré-entraîné Vid2Seq, capable de distinguer et de décrire plusieurs événements dans une vidéo. Cet article a été accepté par CVPR 2023.
Récemment, des chercheurs de Google ont proposé un modèle de langage visuel pré-entraîné pour décrire des vidéos multi-événements - Vid2Seq, qui a été accepté par CVPR23.
Auparavant, comprendre le contenu vidéo était une tâche difficile, car les vidéos contenaient souvent plusieurs événements se produisant à différentes échelles de temps.
Par exemple, une vidéo d'un musher attachant un chien à un traîneau puis le chien commençant à courir implique une épreuve longue (le traîneau à chiens) et une épreuve courte (le chien est attaché au traîneau).
Une façon de faire progresser la recherche sur la compréhension des vidéos consiste à utiliser la tâche dense d'annotation vidéo, qui consiste à localiser et à décrire temporellement tous les événements dans une vidéo d'une minute.

Adresse papier : https://arxiv.org/abs/2302.14115
L'architecture Vid2Seq améliore le modèle de langage avec des horodatages spéciaux, lui permettant de prédire de manière transparente les limites des événements et les descriptions de texte dans la même séquence de sortie.
Pour pré-entraîner ce modèle unifié, les chercheurs ont exploité des vidéos de narration non étiquetées en reformulant les limites des phrases du discours transcrit en limites de pseudo-événements et en utilisant les phrases de discours transcrites comme annotations de pseudo-événements.

Vue d'ensemble du modèle Vid2Seq
Le modèle Vid2Seq résultant est pré-entraîné sur des millions de vidéos commentées, améliorant ainsi l'état de l'art sur divers benchmarks d'annotation vidéo denses, notamment YouCook2, ViTT et ActivityNet Captions.
Vid2Seq est également bien adapté aux paramètres d'annotation vidéo dense de quelques plans, aux tâches d'annotation de segments vidéo et aux tâches d'annotation vidéo standard.

Modèle de langage visuel pour une annotation vidéo dense
L'architecture Multimodale Transformer a actualisé le SOTA de diverses tâches vidéo, telles que la reconnaissance d'actions. Cependant, adapter une telle architecture à la tâche complexe de localisation et d’annotation conjointes d’événements dans des vidéos d’une durée d’une minute n’est pas simple.
Pour atteindre cet objectif, les chercheurs améliorent le modèle de langage visuel avec des marqueurs temporels spéciaux (tels que des marqueurs de texte) qui représentent des horodatages discrets dans la vidéo, similaires à Pix2Seq dans le domaine spatial.
Pour une entrée visuelle donnée, le modèle Vid2Seq résultant peut à la fois accepter l'entrée et générer du texte et des séquences horodatées.
Tout d'abord, cela permet au modèle Vid2Seq de comprendre les informations temporelles de l'entrée vocale transcrite, qui est projetée sous la forme d'une seule séquence de jetons. Deuxièmement, cela permet à Vid2Seq de prédire conjointement des annotations d'événements denses dans le temps dans la vidéo tout en générant une seule séquence de marqueurs.
L'architecture Vid2Seq comprend un encodeur visuel et un encodeur de texte qui encodent respectivement les images vidéo et l'entrée vocale transcrite. Les encodages résultants sont ensuite transmis à un décodeur de texte, qui prédit automatiquement la séquence de sortie des annotations d'événements denses, ainsi que leur positionnement temporel dans la vidéo. L'architecture est initialisée avec une base visuelle solide et un modèle de langage fort.

Pré-formation à grande échelle sur les vidéos
La collecte manuelle d'annotations pour une annotation vidéo dense est particulièrement coûteuse en raison du caractère intensif de la tâche.
Par conséquent, les chercheurs ont pré-entraîné le modèle Vid2Seq à l'aide de vidéos de narration non étiquetées, facilement disponibles à grande échelle. Ils ont également utilisé l'ensemble de données YT-Temporal-1B, qui comprend 18 millions de vidéos commentées couvrant un large éventail de domaines.
Les chercheurs utilisent des phrases vocales transcrites et leurs horodatages correspondants comme supervision, qui sont projetés comme une séquence symbolique unique.
Vid2Seq est ensuite pré-entraîné avec un objectif génératif qui apprend au décodeur à prédire uniquement les séquences vocales transcrites en fonction d'une entrée visuelle, et un objectif de débruitage qui encourage l'apprentissage multimodal, obligeant le modèle à prédire la parole transcrite bruyante. Prédire les masques dans le contexte de séquence et d’entrée visuelle. En particulier, du bruit est ajouté à la séquence vocale en masquant de manière aléatoire les jetons d'étendue.

Résultats de référence sur les tâches en aval
Le modèle Vid2Seq pré-entraîné résultant peut être affiné sur les tâches en aval via un simple objectif de maximum de vraisemblance qui utilise le forçage de l'enseignant (c'est-à-dire, étant donné le jeton de vérité terrain précédent, prédire le jeton suivant).
Après un réglage fin, Vid2Seq surpasse SOTA sur trois benchmarks d'annotation vidéo dense en aval standard (ActivityNet Captions, YouCook2 et ViTT) et deux benchmarks d'annotation de clips vidéo (MSR-VTT, MSVD).
Dans l'article, il y a des études d'ablation supplémentaires, des résultats qualitatifs et des résultats dans les tâches de réglage de quelques plans et d'annotation de paragraphes vidéo.
Tests qualitatifs
Les résultats montrent que Vid2Seq peut prédire des limites et des annotations d'événements significatives, et que les annotations et les limites prédites sont significativement différentes de l'entrée vocale transcrite (cela montre également l'importance des marqueurs visuels dans l'entrée).

L'exemple suivant concerne une série d'instructions dans une recette de cuisine. Il s'agit d'un exemple de prédiction d'annotation d'événement dense par Vid2Seq sur l'ensemble de validation YouCook2 :

L'exemple suivant est l'annotation d'événement dense de Vid2Seq sur le Ensemble de validation ActivityNet Captions Exemples prédictifs, Dans toutes ces vidéos, il n'y a pas de discours transcrit.
Cependant, il y aura encore des cas d'échec, comme la photo marquée en rouge ci-dessous dit qu'il s'agit d'une personne qui enlève son chapeau devant la caméra.
Benchmarking SOTA
Le tableau 5 compare Vid2Seq aux méthodes d'annotation vidéo dense les plus avancées : Vid2Seq actualise SOTA sur trois ensembles de données : YouCook2, ViTT et ActivityNet Captions. Les indicateurs SODA de

Vid2Seq sur YouCook2 et ActivityNet Captions sont respectivement 3,5 et 0,3 points supérieurs à ceux de PDVC et UEDVC. Et E2ESG utilise une pré-formation en texte brut dans le domaine sur Wikihow, et Vid2Seq est meilleure que cette méthode. Ces résultats montrent que le modèle Vid2Seq pré-entraîné possède une forte capacité à étiqueter des événements denses.
Le Tableau 6 évalue les performances de localisation d'événements du modèle d'annotation vidéo dense. Comparé à YouCook2 et ViTT, Vid2Seq est supérieur dans la gestion des annotations vidéo denses en tant que tâche de génération de séquence unique.

Cependant, Vid2Seq ne fonctionne pas bien sur les sous-titres ActivityNet par rapport à PDVC et UEDVC. Par rapport à ces deux méthodes, Vid2Seq intègre moins de connaissances préalables sur la localisation temporelle, tandis que les deux autres méthodes incluent des composants spécifiques à une tâche tels que des compteurs d'événements ou entraînent un modèle séparément pour la sous-tâche de localisation.
Détails de mise en œuvre
- Architecture
L'encodeur de transformateur temporel visuel, l'encodeur de texte et le décodeur de texte ont tous 12 couches, 12 têtes, intégrant la dimension 768, la dimension cachée MLP 2048.
Les séquences de l'encodeur et du décodeur de texte sont tronquées ou complétées à L=S=1000 jetons lors de la pré-formation, et S=1000 et L=256 jetons lors du réglage fin. Lors de l'inférence, le décodage par recherche de faisceau est utilisé, les 4 premières séquences sont suivies et une normalisation de longueur de 0,6 est appliquée.
- Formation
L'auteur utilise l'optimiseur Adam, β=(0,9, 0,999), sans perte de poids.
Pendant la pré-formation, un taux d'apprentissage de 1e^-4 est utilisé, échauffé linéairement (à partir de 0) au cours des 1000 premières itérations et maintenu constant dans les itérations restantes.
Pendant le réglage fin, utilisez un taux d'apprentissage de 3e^-4, en échauffant linéairement (en partant de 0) dans les 10 premiers % des itérations et en maintenant la désintégration du cosinus (jusqu'à 0) dans les 90 % des itérations restantes. Dans le processus, un lot de 32 vidéos est utilisé et réparti sur 16 puces TPU v4.
L'auteur a effectué 40 ajustements d'époque sur YouCook2, 20 ajustements d'époque pour ActivityNet Captions et ViTT, 5 ajustements d'époque pour MSR-VTT et 10 ajustements d'époque pour MSVD.
Conclusion
Vid2Seq proposé par Google est un nouveau modèle de langage visuel pour l'annotation vidéo dense. Il peut effectuer efficacement un pré-entraînement à grande échelle sur des vidéos de narration non étiquetées et effectuer diverses annotations vidéo denses en aval. Résultats SOTA obtenus sur le benchmark.
Présentation de l'auteur
Premier auteur de l'article : Antoine Yang

Antoine Yang est doctorant en troisième année dans l'équipe WILLOW de l'Inria et de l'École Normale Supérieure de Paris. Ses encadrants sont Antoine Miech, Josef Sivic, Ivan Laptev et Cordelia Schmid.
Les recherches actuelles se concentrent sur l'apprentissage de modèles de langage visuel pour la compréhension vidéo. Il a effectué un stage au Laboratoire Arche de Noé de Huawei en 2019, a obtenu un diplôme d'ingénieur de l'Ecole Polytechnique de Paris et un master en mathématiques, vision et apprentissage de l'Université Nationale Paris-Saclay en 2020, et a effectué un stage chez Google Research en 2022.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1677
1677
 14
1431
52
1334
25
1280
29
1257
24
14
1431
52
1334
25
1280
29
1257
24

 Comment supprimer complètement les langues d'affichage indésirables sur Windows 11
Sep 24, 2023 pm 04:25 PM
Comment supprimer complètement les langues d'affichage indésirables sur Windows 11
Sep 24, 2023 pm 04:25 PM
Travaillez trop longtemps sur la même configuration ou partagez votre PC avec d’autres. Certains modules linguistiques peuvent être installés, ce qui crée souvent des conflits. Il est donc temps de supprimer les langues d’affichage indésirables dans Windows 11. En parlant de conflits, lorsqu'il existe plusieurs modules linguistiques, appuyer par inadvertance sur Ctrl+Maj modifie la disposition du clavier. Si l’on n’y prend pas garde, cela peut constituer un obstacle à la tâche à accomplir. Alors passons directement à la méthode ! Comment supprimer la langue d’affichage de Windows 11 ? 1. Dans Paramètres, appuyez sur + pour ouvrir l'application Paramètres, accédez à Heure et langue dans le volet de navigation et cliquez sur Langue et région. WindowsJe clique sur les points de suspension à côté de la langue d'affichage que vous souhaitez supprimer et sélectionnez Supprimer dans le menu contextuel. Cliquez sur "
 3 façons de changer de langue sur iPhone
Feb 02, 2024 pm 04:12 PM
3 façons de changer de langue sur iPhone
Feb 02, 2024 pm 04:12 PM
Ce n'est un secret pour personne que l'iPhone est l'un des gadgets électroniques les plus conviviaux, et l'une des raisons pour cela est qu'il peut être facilement personnalisé à votre guise. Dans Personnalisation, vous pouvez changer la langue en une langue différente de celle que vous avez sélectionnée lors de la configuration de votre iPhone. Si vous maîtrisez plusieurs langues ou si le paramètre de langue de votre iPhone est incorrect, vous pouvez le modifier comme nous l'expliquons ci-dessous. Comment changer la langue de l'iPhone [3 méthodes] iOS permet aux utilisateurs de changer librement la langue préférée sur l'iPhone pour s'adapter aux différents besoins. Vous pouvez changer la langue d'interaction avec Siri pour faciliter la communication avec l'assistant vocal. Dans le même temps, lorsque vous utilisez le clavier local, vous pouvez facilement basculer entre plusieurs langues pour améliorer l'efficacité de la saisie.
 En ajoutant des fonctionnalités audiovisuelles complètes à de grands modèles de langage, DAMO Academy ouvre la source Video-LLaMA
Jun 09, 2023 pm 09:28 PM
En ajoutant des fonctionnalités audiovisuelles complètes à de grands modèles de langage, DAMO Academy ouvre la source Video-LLaMA
Jun 09, 2023 pm 09:28 PM
La vidéo joue un rôle de plus en plus important dans la culture actuelle des médias sociaux et Internet. Douyin, Kuaishou, Bilibili, etc. sont devenus des plateformes populaires pour des centaines de millions d'utilisateurs. Les utilisateurs partagent leurs moments de vie, leurs œuvres créatives, leurs moments intéressants et d'autres contenus autour de vidéos pour interagir et communiquer avec les autres. Récemment, de grands modèles de langage ont démontré des capacités impressionnantes. Peut-on équiper les grands modèles d'« yeux » et d'« oreilles » pour qu'ils puissent comprendre les vidéos et interagir avec les utilisateurs ? Partant de ce problème, les chercheurs de la DAMO Academy ont proposé Video-LLaMA, un grand modèle doté de capacités audiovisuelles complètes. Video-LLaMA peut percevoir et comprendre les signaux vidéo et audio dans la vidéo, et peut comprendre les instructions saisies par l'utilisateur pour effectuer une série de tâches complexes basées sur l'audio et la vidéo,
 Comment définir la langue de l'ordinateur Win10 sur le chinois ?
Jan 05, 2024 pm 06:51 PM
Comment définir la langue de l'ordinateur Win10 sur le chinois ?
Jan 05, 2024 pm 06:51 PM
Parfois, nous installons simplement le système informatique et constatons que le système est en anglais. Dans ce cas, nous devons changer la langue de l'ordinateur en chinois. Alors, comment changer la langue de l'ordinateur en chinois dans le système Win10 ? . Comment changer la langue de l'ordinateur dans Win10 en chinois 1. Allumez l'ordinateur et cliquez sur le bouton Démarrer dans le coin inférieur gauche. 2. Cliquez sur l'option de paramètres à gauche. 3. Sélectionnez « Heure et langue » sur la page qui s'ouvre. 4. Après l'ouverture, cliquez sur « Langue » sur la gauche. 5. Ici, vous pouvez définir la langue de l'ordinateur souhaitée.
 Correctif : Alt + Shift ne change pas de langue sous Windows 11
Oct 11, 2023 pm 02:17 PM
Correctif : Alt + Shift ne change pas de langue sous Windows 11
Oct 11, 2023 pm 02:17 PM
Bien que Alt+Shift ne change pas la langue sous Windows 11, vous pouvez utiliser Win+Spacebar pour obtenir le même effet. Assurez-vous également d’utiliser les touches Alt+Shift gauche et non celles situées sur le côté droit du clavier. Pourquoi Alt+Shift ne peut-il pas changer la langue ? Vous n'avez plus de langues parmi lesquelles choisir. Les raccourcis clavier de la langue de saisie ont été modifiés. Un bug dans la dernière mise à jour de Windows vous empêche de changer la langue de votre clavier. Désinstallez les dernières mises à jour pour résoudre ce problème. Vous êtes dans la fenêtre active d'une application qui utilise les mêmes raccourcis clavier pour effectuer d'autres actions. Comment utiliser AltShift pour changer la langue sous Windows 11 ? 1. Utilisez la séquence de touches correcte. Tout d'abord, assurez-vous que vous utilisez la bonne méthode d'utilisation de la combinaison +.
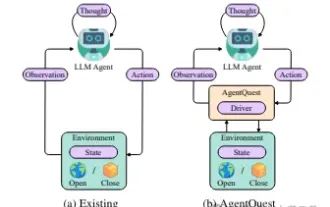 Explorer les limites des agents : AgentQuest, un cadre de référence modulaire pour mesurer et améliorer de manière globale les performances des grands agents de modèles de langage
Apr 11, 2024 pm 08:52 PM
Explorer les limites des agents : AgentQuest, un cadre de référence modulaire pour mesurer et améliorer de manière globale les performances des grands agents de modèles de langage
Apr 11, 2024 pm 08:52 PM
Basées sur l'optimisation continue de grands modèles, les agents LLM, ces puissantes entités algorithmiques ont montré leur potentiel pour résoudre des tâches de raisonnement complexes en plusieurs étapes. Du traitement du langage naturel à l'apprentissage profond, les agents LLM deviennent progressivement le centre d'intérêt de la recherche et de l'industrie. Ils peuvent non seulement comprendre et générer le langage humain, mais également formuler des stratégies, effectuer des tâches dans divers environnements et même utiliser des appels d'API et du codage pour créer. solutions. Dans ce contexte, l'introduction du framework AgentQuest constitue une étape importante. Il fournit non seulement une plate-forme d'analyse comparative modulaire pour l'évaluation et l'avancement des agents LLM, mais fournit également aux chercheurs des outils puissants pour suivre et améliorer les performances de ces agents à un moment donné. niveau plus granulaire
 Vous pouvez jouer simplement en bougeant votre bouche ! Utilisez l'IA pour changer de personnage et attaquer les ennemis : 'Ayaka, utilisez Kamiri-ryu Frost Destruction'
May 13, 2023 pm 07:52 PM
Vous pouvez jouer simplement en bougeant votre bouche ! Utilisez l'IA pour changer de personnage et attaquer les ennemis : 'Ayaka, utilisez Kamiri-ryu Frost Destruction'
May 13, 2023 pm 07:52 PM
En ce qui concerne les jeux nationaux devenus populaires dans le monde entier au cours des deux dernières années, Genshin Impact remporte définitivement la palme. Selon le rapport d'enquête sur les revenus des jeux mobiles du premier trimestre de cette année publié en mai, "Genshin Impact" a fermement remporté la première place parmi les jeux mobiles de tirage de cartes avec un avantage absolu de 567 millions de dollars américains. Cela a également annoncé que "Genshin Impact" a été. en ligne en seulement 18 ans. Quelques mois plus tard, les revenus totaux de la seule plateforme mobile dépassaient les 3 milliards de dollars américains (environ 13 milliards de RM). Désormais, la dernière version 2.8 de l'île avant l'ouverture de Xumi est attendue depuis longtemps. Après une longue période de draft, il y a enfin de nouvelles intrigues et zones à jouer. Mais je ne sais pas combien il y a d’« Empereurs du Foie ». Maintenant que l’île a été entièrement explorée, l’herbe a recommencé à pousser. Il y a un total de 182 coffres au trésor + 1 boîte Mora (non incluse). Il n'y a pas lieu de s'inquiéter de la période des herbes longues. La zone Genshin Impact ne manque jamais de travail. Non, pendant les hautes herbes
 Quel bruit ! ChatGPT comprend-il la langue ? PNAS : étudions d'abord ce qu'est la « compréhension »
Apr 07, 2023 pm 06:21 PM
Quel bruit ! ChatGPT comprend-il la langue ? PNAS : étudions d'abord ce qu'est la « compréhension »
Apr 07, 2023 pm 06:21 PM
Se demander si une machine peut y penser, c'est comme demander si un sous-marin peut nager. ——Dijkstra Même avant la sortie de ChatGPT, l'industrie avait déjà flairé les changements apportés par les grands modèles. Le 14 octobre de l'année dernière, les professeurs Melanie Mitchell et David C. Krakauer de l'Institut de Santa Fe ont publié une revue sur arXiv, étudiant de manière approfondie tous les aspects de « la capacité des modèles linguistiques pré-entraînés à grande échelle à comprendre les débats pertinents ». décrit les arguments « pour » et « contre », ainsi que les problèmes clés de la science du renseignement au sens large qui découlent de ces arguments. Lien papier : https://arxiv.o
