
 Périphériques technologiques
IA
Un remplacement de ChatGPT qui peut être exécuté sur un ordinateur portable est ici, avec un rapport technique complet en pièce jointe
Périphériques technologiques
IA
Un remplacement de ChatGPT qui peut être exécuté sur un ordinateur portable est ici, avec un rapport technique complet en pièce jointe
Un remplacement de ChatGPT qui peut être exécuté sur un ordinateur portable est ici, avec un rapport technique complet en pièce jointe

GPT4All est un chatbot formé sur la base d'une grande quantité de données d'assistant propres (y compris du code, des histoires et des conversations). Les données comprennent environ 800 000 éléments de données générées par GPT-3.5-Turbo. Il est complété sur la base de LLaMa et peut fonctionner sur M1. Mac, Windows et autres environnements. Comme son nom l’indique, le moment est peut-être venu où tout le monde peut utiliser le GPT personnel.
Depuis qu'OpenAI a publié ChatGPT, les chatbots sont devenus de plus en plus populaires ces derniers mois.
Bien que ChatGPT soit puissant, il est presque impossible pour OpenAI de l'ouvrir en source. De nombreuses personnes travaillent sur l'open source, comme LLaMA, qui a été open source par Meta il y a quelque temps. Il s'agit d'un terme général désignant une série de modèles avec des quantités de paramètres allant de 7 milliards à 65 milliards. Parmi eux, le modèle LLaMA à 13 milliards de paramètres peut surpasser le paramètre GPT-3 à 175 milliards « sur la plupart des benchmarks ».
L'open source de LLaMA a profité à de nombreux chercheurs. Par exemple, Stanford a ajouté le réglage des instructions à LLaMA et formé un nouveau modèle de 7 milliards de paramètres appelé Alpaca (basé sur LLaMA 7B). Les résultats montrent que les performances d'Alpaca, un modèle léger avec seulement 7 paramètres B, sont comparables à des modèles de langage à très grande échelle tels que GPT-3.5.
Pour un autre exemple, le modèle que nous allons présenter ensuite, GPT4All, est également un nouveau modèle de langage 7B basé sur LLaMA. Deux jours après le lancement du projet, le nombre d'étoiles a dépassé les 7,8k.

Adresse du projet : https://github.com/nomic-ai/gpt4all
En termes simples, GPT4All est formé sur 800 000 éléments de données de GPT-3.5-Turbo, y compris des questions textuelles, des descriptions d'histoires, etc. Tournez le dialogue et le code.
Selon le projet, M1 peut fonctionner sous Mac, Windows et d'autres environnements.

Jetons d'abord un coup d'œil à l'effet. Comme le montre la figure ci-dessous, les utilisateurs peuvent communiquer avec GPT4All sans aucune barrière, par exemple en demandant au modèle : « Puis-je exécuter un grand modèle de langage sur un ordinateur portable ? » La réponse de GPT4All est : « Oui, vous pouvez utiliser un ordinateur portable pour vous entraîner et testez des réseaux de neurones ou des modèles d'apprentissage automatique pour d'autres langues naturelles (comme l'anglais ou le chinois). Surtout, vous avez besoin de suffisamment de mémoire disponible (RAM) pour s'adapter à la taille de ces modèles..."
Ensuite, si vous ne le faites pas). Si vous ne savez pas exactement de quelle quantité de mémoire vous avez besoin, vous pouvez également continuer à demander à GPT4All, et il vous donnera ensuite une réponse. À en juger par les résultats, la capacité de GPT4All à mener plusieurs cycles de dialogue est toujours très forte.

Échantillonnage en temps réel sur Mac M1
Certaines personnes appellent cette recherche "un changement de jeu. Avec la bénédiction de GPT4All, vous pouvez désormais exécuter GPT localement sur MacBook."

Similaire à GPT-4, GPT4All fournit également un « rapport technique ».

Adresse du rapport technique : https://s3.amazonaws.com/static.nomic.ai/gpt4all/2023_GPT4All_Technical_Report.pdf
Ce rapport technique préliminaire décrit brièvement les détails de construction de GPT4All. Les chercheurs ont divulgué les données collectées, les procédures de traitement des données, le code de formation et les poids finaux du modèle pour promouvoir la recherche ouverte et la reproductibilité. Ils ont également publié une version quantifiée 4 bits du modèle, ce qui signifie que presque tout le monde peut exécuter le modèle sur un processeur.
Ensuite, voyons ce qui est écrit dans ce rapport.
Rapport technique GPT4All
1. Collecte et tri des données
Du 20 mars 2023 au 26 mars 2023, les chercheurs ont utilisé l'API GPT-3.5-Turbo OpenAI pour collecter environ 1 million de paires de réponses aux invites.
Tout d’abord, les chercheurs ont collecté différents échantillons de questions/invites en exploitant trois ensembles de données accessibles au public :
- Sous-ensemble chip2 unifié de LAION OIG
- Un ensemble de sous-échantillons aléatoires de questions de codage de questions Stackoverflow
- Ensemble de sous-échantillons Bigscience/P3 pour le réglage des instructions
Reportez-vous au projet Alpaca de l'Université de Stanford (Taori et al., 2023), les chercheurs ont payé des sommes considérables attention à la préparation et à la conservation des données. Après avoir collecté l'ensemble de données initial de paires générées par des invites, ils ont chargé les données dans Atlas pour les organiser et les nettoyer, en supprimant tous les échantillons dans lesquels GPT-3.5-Turbo n'a pas répondu aux invites et a produit une sortie mal formée. Cela réduit le nombre total d’échantillons à 806 199 paires générées par des invites de haute qualité. Ensuite, nous avons supprimé l'intégralité du sous-ensemble Bigscience/P3 de l'ensemble de données de formation final, car sa diversité de sortie était très faible. P3 contient de nombreuses invites homogènes qui génèrent des réponses courtes et homogènes de GPT-3.5-Turbo.
Cette méthode d'élimination a abouti à un sous-ensemble final de 437 605 paires générées par des invites, comme le montre la figure 2.

Formation de modèles
Les chercheurs ont affiné plusieurs modèles dans une instance de LLaMA 7B (Touvron et al., 2023). Le modèle associé à leur première diffusion publique a été formé avec LoRA (Hu et al., 2021) en 4 époques sur 437 605 exemples post-traités. Les hyperparamètres détaillés du modèle et le code de formation peuvent être trouvés dans la bibliothèque de ressources appropriée et dans les journaux de formation du modèle.
Reproductibilité
Les chercheurs ont publié toutes les données (y compris les générations P3 inutilisées), le code de formation et les poids du modèle afin que la communauté puisse les reproduire. Les chercheurs intéressés peuvent trouver les dernières données, les détails de la formation et les points de contrôle dans le référentiel Git.
Coût
Il a fallu environ quatre jours aux chercheurs pour construire ces modèles, et le coût du GPU était de 800 $ (loué auprès de Lambda Labs et Paperspace, y compris plusieurs formations ayant échoué), plus 500 $ de frais supplémentaires pour l'API OpenAI.
Le modèle final publié, gpt4all-lora, peut être formé en 8 heures environ sur le DGX A100 8x 80 Go de Lambda Labs, pour un coût total de 100 $.
Ce modèle peut être exécuté sur un ordinateur portable ordinaire. Comme l'a dit un internaute : "Il n'y a aucun coût sauf la facture d'électricité." Une évaluation préliminaire du modèle a été réalisée sur des données d'évaluation humaine. Le rapport compare également la perplexité de ce modèle en matière de vérité terrain avec le modèle public d'alpaga-lora le plus connu (contribué par l'utilisateur de huggingface chainyo). Ils ont constaté que tous les modèles présentaient de très grandes perplexités sur un petit nombre de tâches et rapportaient des perplexités allant jusqu'à 100. Les modèles affinés sur cet ensemble de données collectées ont montré une perplexité moindre dans l'évaluation de l'auto-instruction par rapport à Alpaca. Les chercheurs affirment que cette évaluation n'est pas exhaustive et qu'il y a encore place à une évaluation plus approfondie - ils invitent les lecteurs à exécuter le modèle sur un processeur local (documentation disponible sur Github) et à obtenir une compréhension qualitative de ses capacités.
Enfin, il est important de noter que les auteurs ont publié des données et des détails de formation dans l'espoir que cela accélérera la recherche ouverte LLM, notamment dans les domaines de l'alignement et de l'interprétabilité. Les poids et données des modèles GPT4All sont uniquement destinés à des fins de recherche et sont sous licence contre toute utilisation commerciale. GPT4All est basé sur LLaMA, qui dispose d'une licence non commerciale. Les données de l'assistant ont été collectées à partir du GPT-3.5-Turbo d'OpenAI, dont les conditions d'utilisation interdisent le développement de modèles qui concurrencent commercialement OpenAI. 
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Publication du classement national CSRankings 2024 en informatique ! La CMU domine la liste, le MIT sort du top 5
Mar 25, 2024 pm 06:01 PM
Publication du classement national CSRankings 2024 en informatique ! La CMU domine la liste, le MIT sort du top 5
Mar 25, 2024 pm 06:01 PM
Les classements majeurs nationaux en informatique 2024CSRankings viennent d’être publiés ! Cette année, dans le classement des meilleures universités CS aux États-Unis, l'Université Carnegie Mellon (CMU) se classe parmi les meilleures du pays et dans le domaine de CS, tandis que l'Université de l'Illinois à Urbana-Champaign (UIUC) a été classé deuxième pendant six années consécutives. Georgia Tech s'est classée troisième. Ensuite, l’Université de Stanford, l’Université de Californie à San Diego, l’Université du Michigan et l’Université de Washington sont à égalité au quatrième rang mondial. Il convient de noter que le classement du MIT a chuté et est sorti du top cinq. CSRankings est un projet mondial de classement des universités dans le domaine de l'informatique initié par le professeur Emery Berger de la School of Computer and Information Sciences de l'Université du Massachusetts Amherst. Le classement est basé sur des objectifs
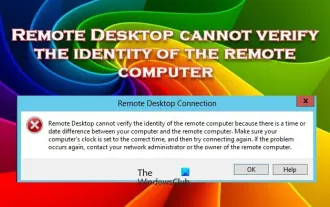 Le Bureau à distance ne peut pas authentifier l'identité de l'ordinateur distant
Feb 29, 2024 pm 12:30 PM
Le Bureau à distance ne peut pas authentifier l'identité de l'ordinateur distant
Feb 29, 2024 pm 12:30 PM
Le service Bureau à distance Windows permet aux utilisateurs d'accéder aux ordinateurs à distance, ce qui est très pratique pour les personnes qui doivent travailler à distance. Cependant, des problèmes peuvent survenir lorsque les utilisateurs ne peuvent pas se connecter à l'ordinateur distant ou lorsque Remote Desktop ne peut pas authentifier l'identité de l'ordinateur. Cela peut être dû à des problèmes de connexion réseau ou à un échec de vérification du certificat. Dans ce cas, l'utilisateur devra peut-être vérifier la connexion réseau, s'assurer que l'ordinateur distant est en ligne et essayer de se reconnecter. De plus, s'assurer que les options d'authentification de l'ordinateur distant sont correctement configurées est essentiel pour résoudre le problème. De tels problèmes avec les services Bureau à distance Windows peuvent généralement être résolus en vérifiant et en ajustant soigneusement les paramètres. Le Bureau à distance ne peut pas vérifier l'identité de l'ordinateur distant en raison d'un décalage d'heure ou de date. Veuillez vous assurer que vos calculs
 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Tongyi Qianwen est à nouveau open source, Qwen1.5 propose six modèles de volume et ses performances dépassent GPT3.5
Feb 07, 2024 pm 10:15 PM
Tongyi Qianwen est à nouveau open source, Qwen1.5 propose six modèles de volume et ses performances dépassent GPT3.5
Feb 07, 2024 pm 10:15 PM
À temps pour la Fête du Printemps, la version 1.5 du modèle Tongyi Qianwen (Qwen) est en ligne. Ce matin, la nouvelle de la nouvelle version a attiré l'attention de la communauté IA. La nouvelle version du grand modèle comprend six tailles de modèle : 0,5B, 1,8B, 4B, 7B, 14B et 72B. Parmi eux, les performances de la version la plus puissante surpassent GPT3.5 et Mistral-Medium. Cette version inclut le modèle de base et le modèle Chat et fournit une prise en charge multilingue. L'équipe Tongyi Qianwen d'Alibaba a déclaré que la technologie pertinente avait également été lancée sur le site officiel de Tongyi Qianwen et sur l'application Tongyi Qianwen. De plus, la version actuelle de Qwen 1.5 présente également les points forts suivants : prend en charge une longueur de contexte de 32 Ko ; ouvre le point de contrôle du modèle Base+Chat ;
 Abandonnez l'architecture codeur-décodeur et utilisez le modèle de diffusion pour la détection des contours avec de meilleurs résultats. L'Université nationale de technologie de la défense a proposé DiffusionEdge.
Feb 07, 2024 pm 10:12 PM
Abandonnez l'architecture codeur-décodeur et utilisez le modèle de diffusion pour la détection des contours avec de meilleurs résultats. L'Université nationale de technologie de la défense a proposé DiffusionEdge.
Feb 07, 2024 pm 10:12 PM
Les réseaux actuels de détection des contours profonds adoptent généralement une architecture d'encodeur-décodeur, qui contient des modules d'échantillonnage ascendant et descendant pour mieux extraire les fonctionnalités à plusieurs niveaux. Cependant, cette structure limite le réseau à produire des résultats de détection de contour précis et détaillés. En réponse à ce problème, un article sur AAAI2024 propose une nouvelle solution. Titre de la thèse : DiffusionEdge : DiffusionProbabilisticModelforCrispEdgeDetection Auteurs : Ye Yunfan (Université nationale de technologie de la défense), Xu Kai (Université nationale de technologie de la défense), Huang Yuxing (Université nationale de technologie de la défense), Yi Renjiao (Université nationale de technologie de la défense), Cai Zhiping (Université nationale de technologie de la défense) Lien vers l'article : https ://ar
 Les grands modèles peuvent également être découpés, et Microsoft SliceGPT augmente considérablement l'efficacité de calcul de LAMA-2.
Jan 31, 2024 am 11:39 AM
Les grands modèles peuvent également être découpés, et Microsoft SliceGPT augmente considérablement l'efficacité de calcul de LAMA-2.
Jan 31, 2024 am 11:39 AM
Les grands modèles de langage (LLM) comportent généralement des milliards de paramètres et sont formés sur des milliards de jetons. Cependant, ces modèles sont très coûteux à former et à déployer. Afin de réduire les besoins de calcul, diverses techniques de compression de modèles sont souvent utilisées. Ces techniques de compression de modèles peuvent généralement être divisées en quatre catégories : distillation, décomposition tensorielle (y compris la factorisation de bas rang), élagage et quantification. Les méthodes d'élagage existent depuis un certain temps, mais beaucoup nécessitent un réglage fin de la récupération (RFT) après l'élagage pour maintenir les performances, ce qui rend l'ensemble du processus coûteux et difficile à faire évoluer. Des chercheurs de l'ETH Zurich et de Microsoft ont proposé une solution à ce problème appelée SliceGPT. L'idée principale de cette méthode est de réduire l'intégration du réseau en supprimant des lignes et des colonnes dans la matrice de pondération.
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
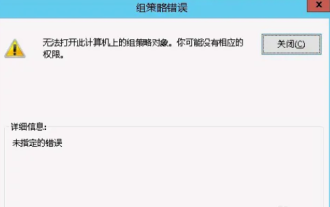 Impossible d'ouvrir l'objet Stratégie de groupe sur cet ordinateur
Feb 07, 2024 pm 02:00 PM
Impossible d'ouvrir l'objet Stratégie de groupe sur cet ordinateur
Feb 07, 2024 pm 02:00 PM
Parfois, le système d'exploitation peut mal fonctionner lors de l'utilisation d'un ordinateur. Le problème que j'ai rencontré aujourd'hui était que lors de l'accès à gpedit.msc, le système indiquait que l'objet de stratégie de groupe ne pouvait pas être ouvert car les autorisations appropriées pouvaient faire défaut. L'objet de stratégie de groupe sur cet ordinateur n'a pas pu être ouvert. Solution : 1. Lors de l'accès à gpedit.msc, le système indique que l'objet de stratégie de groupe sur cet ordinateur ne peut pas être ouvert en raison d'un manque d'autorisations. Détails : Le système ne parvient pas à localiser le chemin spécifié. 2. Une fois que l'utilisateur a cliqué sur le bouton de fermeture, la fenêtre d'erreur suivante apparaît. 3. Vérifiez immédiatement les enregistrements du journal et combinez les informations enregistrées pour découvrir que le problème réside dans le fichier C:\Windows\System32\GroupPolicy\Machine\registry.pol.
