
 Périphériques technologiques
IA
J'ai créé un chatbot vocal alimenté par l'API ChatGPT, veuillez suivre les instructions
Périphériques technologiques
IA
J'ai créé un chatbot vocal alimenté par l'API ChatGPT, veuillez suivre les instructions
J'ai créé un chatbot vocal alimenté par l'API ChatGPT, veuillez suivre les instructions

L'article d'aujourd'hui se concentre sur la création d'une application Web Chatbot vocale privée à l'aide de l'API ChatGPT. L’objectif est d’explorer et de découvrir davantage de cas d’utilisation potentiels et d’opportunités commerciales pour l’intelligence artificielle. Je vous guiderai étape par étape tout au long du processus de développement pour m'assurer que vous comprenez et puissiez reproduire le processus par vous-même.
Pourquoi vous en avez besoin
- Tout le monde n'apprécie pas les services basés sur la dactylographie, imaginez les enfants qui apprennent encore à écrire ou les personnes âgées qui ne peuvent pas voir correctement les mots à l'écran. Le Chatbot IA basé sur la voix est la solution à ce problème, comme la façon dont il a aidé mon enfant à demander à son Chatbot vocal de lui lire une histoire avant d'aller au lit.
- Compte tenu des options d'assistant existantes disponibles, telles que Siri d'Apple et Alexa d'Amazon, l'ajout d'une interaction vocale au modèle GPT peut ouvrir un plus large éventail de possibilités. L'API ChatGPT présente l'avantage de sa capacité supérieure à créer des réponses cohérentes et contextuelles qui, combinées à l'idée de connectivité vocale pour la maison intelligente, pourraient offrir une multitude d'opportunités commerciales. L'assistant vocal que nous avons créé dans cet article servira de point d'entrée.
Assez de théorie, commençons.
1. Schéma fonctionnel
Dans cette application, nous sommes divisés en trois modules clés dans l'ordre de traitement :
- La synthèse vocale de l'API Bokeh et Web Speech
- Le chat est effectué via l'API OpenAI GPT-3.5
- gTTS Text to Speech
FrameWeb construit par Streamlit.
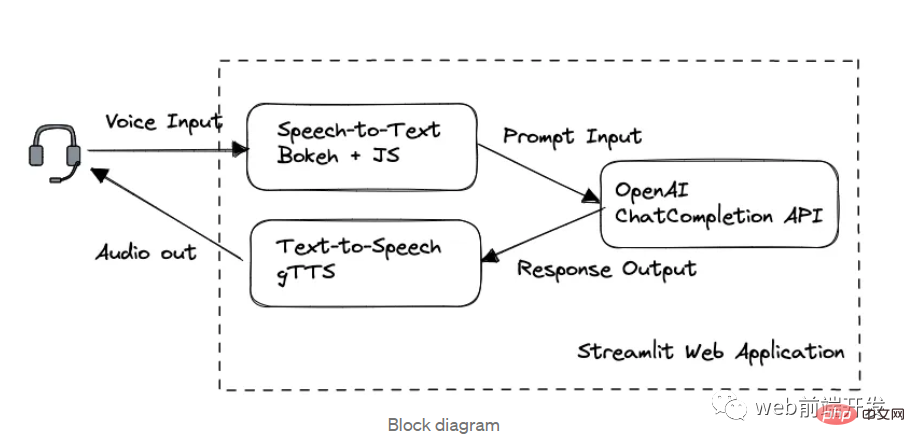
Si vous savez déjà comment utiliser l'API OpenAI sous le modèle GPT 3.5 et comment concevoir des applications Web à l'aide de Streamlit, il est recommandé de sauter la partie 1 et la partie 2 pour gagner du temps de lecture.
2. API OpenAI GPT
Obtenez votre clé API
Si vous possédez déjà une clé API OpenAI, conservez-la au lieu d'en créer une nouvelle. Cependant, si vous êtes nouveau sur OpenAI, créez un nouveau compte et retrouvez la page suivante dans le menu de votre compte :
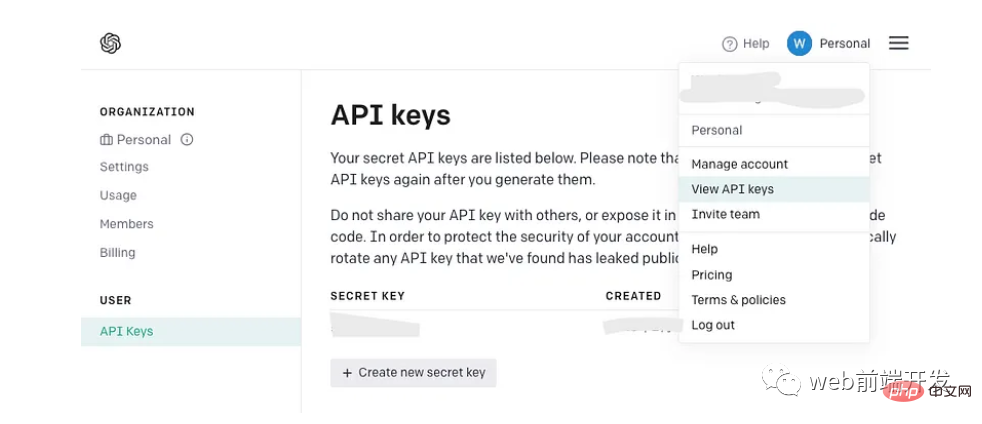
Une fois que vous avez généré votre clé API, n'oubliez pas qu'elle n'apparaîtra qu'une seule fois, alors faites assurez-vous de le copier dans un endroit sûr pour une utilisation future.
Utilisation de l'API ChatCompletion
Actuellement, GPT-4.0 vient de sortir, et l'API de ce modèle n'est pas encore entièrement publiée, je vais donc vous présenter le développement du modèle toujours GPT 3.5, qui suffit à compléter notre Chatbot vocal IA démonstration.
Jetons maintenant un coup d'œil à la démo la plus simple d'OpenAI pour comprendre la définition de base de l'API ChatCompletion (également connue sous le nom d'API gpt-3.5 ou API ChatGPT) :
Package d'installation :
!pip install opena
Si vous avez déjà développé à partir d'OpenAI Pour certains modèles GPT existants, vous devrez peut-être mettre à niveau votre package via pip :
!pip install --upgrade openai
Créez et envoyez une invite :
import openai
complete = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)Recevez une réponse textuelle :
message=complete.choices[0].message.content
Étant donné que l'API GPT 3.5 est une API de complétion de texte basée sur le chat, créez assurez-vous de demander ChatCompletion. Le corps du message contient l'historique de la conversation comme contexte et vous souhaitez que le modèle fasse référence à une réponse plus contextuelle en réponse à votre demande actuelle.
Pour implémenter cette fonctionnalité, les objets de liste du corps du message doivent être organisés dans l'ordre suivant :
- Les messages système sont définis comme définissant le comportement du chatbot en ajoutant des instructions au contenu en haut de la liste des messages. Comme mentionné dans l'introduction, cette fonctionnalité n'est actuellement pas entièrement publiée dans gpt-3.5-turbo-0301.
- Un message utilisateur représente la saisie ou la requête d'un utilisateur, tandis qu'un message d'assistance fait référence à la réponse correspondante de l'API GPT-3.5. De telles conversations en binôme fournissent une référence pour des modèles sur le contexte.
- Le dernier message utilisateur fait référence à l'invite demandée au moment présent.
3. Développement Web
Nous continuerons à utiliser la puissante bibliothèque Streamlit pour créer des applications Web.
Streamlit est un framework open source qui permet aux scientifiques et aux développeurs de données de créer et de partager rapidement des applications Web interactives pour des projets d'apprentissage automatique et de science des données. Il fournit également de nombreux widgets qui peuvent être créés avec une seule ligne de code Python, comme st.table(...).
Si vous n'êtes pas très doué en développement Web et n'êtes pas disposé à créer une grande application commerciale comme moi, Streamlit est toujours l'un de vos meilleurs choix car il ne nécessite presque aucune expertise en HTML.
Regardons un exemple rapide de création d'une application Web Streamlit :
Pack d'installation :
!pip install streamlit
Créez un fichier Python « demo.py » :
import streamlit as st
st.write("""
# My First App
Hello *world!*
""")Exécutez sur une machine locale ou un serveur distant :
!python -m streamlit run demo.py
Imprimez ceci une fois exporté, vous pouvez accéder à votre site Web via l'adresse et le port indiqués :
You can now view your Streamlit app in your browser. Network URL: http://xxx.xxx.xxx.xxx:8501 External URL: http://xxx.xxx.xxx.xxx:8501

Streamlit 提供的所有小部件的用法可以在其文档页面中找到:https://docs.streamlit.io/library/api-reference
4.语音转文字的实现
此 AI 语音聊天机器人的主要功能之一是它能够识别用户语音并生成我们的 ChatCompletion API 可用作输入的适当文本。
OpenAI 的 Whisper API 提供的高质量语音识别是一个很好的选择,但它是有代价的。或者,来自 Javascript 的免费 Web Speech API 提供可靠的多语言支持和令人印象深刻的性能。
虽然开发 Python 项目似乎与定制的 Javascript 不兼容,但不要害怕!在下一部分中,我将介绍一种在 Python 程序中调用 Javascript 代码的简单技术。
不管怎样,让我们看看如何使用 Web Speech API 快速开发语音转文本演示。您可以找到它的文档(地址:https://wicg.github.io/speech-api/)。
语音识别的实现可以很容易地完成,如下所示。
var recognition = new webkitSpeechRecognition(); recognition.continuous = false; recognition.interimResults = true; recognition.lang = 'en'; recognition.start();
通过方法 webkitSpeechRecognition() 初始化识别对象后,需要定义一些有用的属性。continuous 属性表示您是否希望 SpeechRecognition 函数在语音输入的一种模式处理成功完成后继续工作。
我将其设置为 false,因为我希望语音聊天机器人能够以稳定的速度根据用户语音输入生成每个答案。
设置为 true 的 interimResults 属性将在用户语音期间生成一些中间结果,以便用户可以看到从他们的语音输入输出的动态消息。
lang 属性将设置请求识别的语言。请注意,如果它在代码中是未设置,则默认语言将来自 HTML 文档根元素和关联的层次结构,因此在其系统中使用不同语言设置的用户可能会有不同的体验。
识别对象有多个事件,我们使用 .onresult 回调来处理来自中间结果和最终结果的文本生成结果。
recognition.onresult = function (e) {
var value, value2 = "";
for (var i = e.resultIndex; i < e.results.length; ++i) {
if (e.results[i].isFinal) {
value += e.results[i][0].transcript;
rand = Math.random();
} else {
value2 += e.results[i][0].transcript;
}
}
}5.引入Bokeh库
从用户界面的定义来看,我们想设计一个按钮来启动我们在上一节中已经用 Javascript 实现的语音识别。

Streamlit 库不支持自定义 JS 代码,所以我们引入了 Bokeh。Bokeh 库是另一个强大的 Python 数据可视化工具。可以支持我们的演示的最佳部分之一是嵌入自定义 Javascript 代码,这意味着我们可以在 Bokeh 的按钮小部件下运行我们的语音识别脚本。
为此,我们应该安装 Bokeh 包。为了兼容后面会提到的streamlit-bokeh-events库,Bokeh的版本应该是2.4.2:
!pip install bokeh==2.4.2
导入按钮和 CustomJS:
from bokeh.models.widgets import Button from bokeh.models import CustomJS
创建按钮小部件:
spk_button = Button(label='SPEAK', button_type='success')
定义按钮点击事件:
spk_button.js_on_event("button_click", CustomJS(code="""
...js code...
"""))定义了.js_on_event()方法来注册spk_button的事件。
在这种情况下,我们注册了“button_click”事件,该事件将在用户单击后触发由 CustomJS() 方法嵌入的 JS 代码块…js 代码…的执行。
Streamlit_bokeh_event
speak 按钮及其回调方法实现后,下一步是将 Bokeh 事件输出(识别的文本)连接到其他功能块,以便将提示文本发送到 ChatGPT API。
幸运的是,有一个名为“Streamlit Bokeh Events”的开源项目专为此目的而设计,它提供与 Bokeh 小部件的双向通信。你可以在这里找到它的 GitHub 页面。
这个库的使用非常简单。首先安装包:
!pip install streamlit-bokeh-events
通过 streamlit_bokeh_events 方法创建结果对象。
result = streamlit_bokeh_events( bokeh_plot = spk_button, events="GET_TEXT,GET_ONREC,GET_INTRM", key="listen", refresh_on_update=False, override_height=75, debounce_time=0)
使用 bokeh_plot 属性来注册我们在上一节中创建的 spk_button。使用 events 属性来标记多个自定义的 HTML 文档事件
- GET_TEXT 接收最终识别文本
- GET_INTRM 接收临时识别文本
- GET_ONREC 接收语音处理阶段
我们可以使用 JS 函数 document.dispatchEvent(new CustomEvent(…)) 来生成事件,例如 GET_TEXT 和 GET_INTRM 事件:
spk_button.js_on_event("button_click", CustomJS(code="""
var recognition = new webkitSpeechRecognition();
recognition.continuous = false;
recognition.interimResults = true;
recognition.lang = 'en';
var value, value2 = "";
for (var i = e.resultIndex; i < e.results.length; ++i) {
if (e.results[i].isFinal) {
value += e.results[i][0].transcript;
rand = Math.random();
} else {
value2 += e.results[i][0].transcript;
}
}
document.dispatchEvent(new CustomEvent("GET_TEXT", {detail: {t:value, s:rand}}));
document.dispatchEvent(new CustomEvent("GET_INTRM", {detail: value2}));
recognition.start();
}
"""))并且,检查事件 GET_INTRM 处理的 result.get() 方法,例如:
tr = st.empty()
if result:
if "GET_INTRM" in result:
if result.get("GET_INTRM") != '':
tr.text_area("**Your input**", result.get("GET_INTRM"))这两个代码片段表明,当用户正在讲话时,任何临时识别文本都将显示在 Streamlit text_area 小部件上:
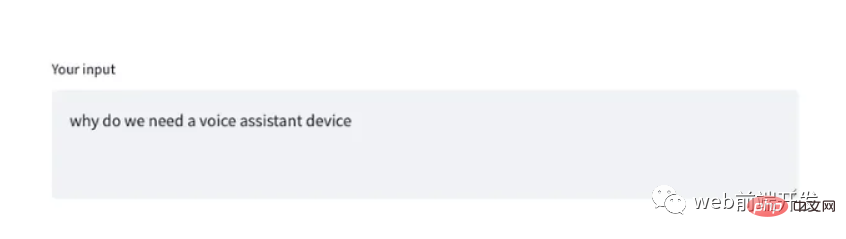
6. 文字转语音实现
提示请求完成,GPT-3.5模型通过ChatGPT API生成响应后,我们通过Streamlit st.write()方法将响应文本直接显示在网页上。

但是,我们需要将文本转换为语音,这样我们的 AI 语音 Chatbot 的双向功能才能完全完成。
有一个名为“gTTS”的流行 Python 库能够完美地完成这项工作。在与谷歌翻译的文本转语音 API 接口后,它支持多种格式的语音数据输出,包括 mp3 或 stdout。你可以在这里找到它的 GitHub 页面。
只需几行代码即可完成转换。首先安装包:
!pip install gTTS
在这个演示中,我们不想将语音数据保存到文件中,所以我们可以调用 BytesIO() 来临时存储语音数据:
sound = BytesIO() tts = gTTS(output, lang='en', tld='com') tts.write_to_fp(sound)
输出的是要转换的文本字符串,你可以根据自己的喜好,通过tld从不同的google域中选择不同的语言by lang。例如,您可以设置 tld='co.uk' 以生成英式英语口音。
然后,通过 Streamlit 小部件创建一个像样的音频播放器:
st.audio(sound)
全语音聊天机器人
要整合上述所有模块,我们应该完成完整的功能:
- 已完成与 ChatCompletion API 的交互,并在用户和助手消息块中定义了附加的历史对话。使用 Streamlit 的 st.session_state 来存储运行变量。
- 考虑到 .onspeechstart()、.onsoundend() 和 .onerror() 等多个事件以及识别过程,在 SPEAK 按钮的 CustomJS 中完成了事件生成。
- 完成事件“GET_TEXT、GET_ONREC、GET_INTRM”的事件处理,以在网络界面上显示适当的信息,并管理用户讲话时的文本显示和组装。
- 所有必要的 Streamit 小部件
请找到完整的演示代码供您参考:
import streamlit as st
from bokeh.models.widgets import Button
from bokeh.models import CustomJS
from streamlit_bokeh_events import streamlit_bokeh_events
from gtts import gTTS
from io import BytesIO
import openai
openai.api_key = '{Your API Key}'
if 'prompts' not in st.session_state:
st.session_state['prompts'] = [{"role": "system", "content": "You are a helpful assistant. Answer as concisely as possible with a little humor expression."}]
def generate_response(prompt):
st.session_state['prompts'].append({"role": "user", "content":prompt})
completinotallow=openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages = st.session_state['prompts']
)
message=completion.choices[0].message.content
return message
sound = BytesIO()
placeholder = st.container()
placeholder.title("Yeyu's Voice ChatBot")
stt_button = Button(label='SPEAK', button_type='success', margin = (5, 5, 5, 5), width=200)
stt_button.js_on_event("button_click", CustomJS(code="""
var value = "";
var rand = 0;
var recognition = new webkitSpeechRecognition();
recognition.continuous = false;
recognition.interimResults = true;
recognition.lang = 'en';
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'start'}));
recognition.onspeechstart = function () {
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'running'}));
}
recognition.onsoundend = function () {
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'stop'}));
}
recognition.onresult = function (e) {
var value2 = "";
for (var i = e.resultIndex; i < e.results.length; ++i) {
if (e.results[i].isFinal) {
value += e.results[i][0].transcript;
rand = Math.random();
} else {
value2 += e.results[i][0].transcript;
}
}
document.dispatchEvent(new CustomEvent("GET_TEXT", {detail: {t:value, s:rand}}));
document.dispatchEvent(new CustomEvent("GET_INTRM", {detail: value2}));
}
recognition.onerror = function(e) {
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'stop'}));
}
recognition.start();
"""))
result = streamlit_bokeh_events(
bokeh_plot = stt_button,
events="GET_TEXT,GET_ONREC,GET_INTRM",
key="listen",
refresh_on_update=False,
override_height=75,
debounce_time=0)
tr = st.empty()
if 'input' not in st.session_state:
st.session_state['input'] = dict(text='', sessinotallow=0)
tr.text_area("**Your input**", value=st.session_state['input']['text'])
if result:
if "GET_TEXT" in result:
if result.get("GET_TEXT")["t"] != '' and result.get("GET_TEXT")["s"] != st.session_state['input']['session'] :
st.session_state['input']['text'] = result.get("GET_TEXT")["t"]
tr.text_area("**Your input**", value=st.session_state['input']['text'])
st.session_state['input']['session'] = result.get("GET_TEXT")["s"]
if "GET_INTRM" in result:
if result.get("GET_INTRM") != '':
tr.text_area("**Your input**", value=st.session_state['input']['text']+' '+result.get("GET_INTRM"))
if "GET_ONREC" in result:
if result.get("GET_ONREC") == 'start':
placeholder.image("recon.gif")
st.session_state['input']['text'] = ''
elif result.get("GET_ONREC") == 'running':
placeholder.image("recon.gif")
elif result.get("GET_ONREC") == 'stop':
placeholder.image("recon.jpg")
if st.session_state['input']['text'] != '':
input = st.session_state['input']['text']
output = generate_response(input)
st.write("**ChatBot:**")
st.write(output)
st.session_state['input']['text'] = ''
tts = gTTS(output, lang='en', tld='com')
tts.write_to_fp(sound)
st.audio(sound)
st.session_state['prompts'].append({"role": "user", "content":input})
st.session_state['prompts'].append({"role": "assistant", "content":output})输入后:
!python -m streamlit run demo_voice.py
您最终会在网络浏览器上看到一个简单但智能的语音聊天机器人。
请注意:不要忘记在弹出请求时允许网页访问您的麦克风和扬声器。
就是这样,一个简单聊天机器人就完成了。
最后,希望您能在本文中找到有用的东西,感谢您的阅读!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
Le DALL-E 3 a été officiellement introduit en septembre 2023 en tant que modèle considérablement amélioré par rapport à son prédécesseur. Il est considéré comme l’un des meilleurs générateurs d’images IA à ce jour, capable de créer des images avec des détails complexes. Cependant, au lancement, c'était exclu
 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
 Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Selon les informations de ce site Web du 5 juillet, GlobalFoundries a publié un communiqué de presse le 1er juillet de cette année, annonçant l'acquisition de la technologie de nitrure de gallium (GaN) et du portefeuille de propriété intellectuelle de Tagore Technology, dans l'espoir d'élargir sa part de marché dans l'automobile et Internet. des objets et des domaines d'application des centres de données d'intelligence artificielle pour explorer une efficacité plus élevée et de meilleures performances. Alors que des technologies telles que l’intelligence artificielle générative (GenerativeAI) continuent de se développer dans le monde numérique, le nitrure de gallium (GaN) est devenu une solution clé pour une gestion durable et efficace de l’énergie, notamment dans les centres de données. Ce site Web citait l'annonce officielle selon laquelle, lors de cette acquisition, l'équipe d'ingénierie de Tagore Technology rejoindrait GF pour développer davantage la technologie du nitrure de gallium. g
 SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
Selon les informations de ce site le 1er août, SK Hynix a publié un article de blog aujourd'hui (1er août), annonçant sa participation au Global Semiconductor Memory Summit FMS2024 qui se tiendra à Santa Clara, Californie, États-Unis, du 6 au 8 août, présentant de nombreuses nouvelles technologies de produit. Introduction au Future Memory and Storage Summit (FutureMemoryandStorage), anciennement Flash Memory Summit (FlashMemorySummit) principalement destiné aux fournisseurs de NAND, dans le contexte de l'attention croissante portée à la technologie de l'intelligence artificielle, cette année a été rebaptisée Future Memory and Storage Summit (FutureMemoryandStorage) pour invitez les fournisseurs de DRAM et de stockage et bien d’autres joueurs. Nouveau produit SK hynix lancé l'année dernière
 SearchGPT : Open AI affronte Google avec son propre moteur de recherche IA
Jul 30, 2024 am 09:58 AM
SearchGPT : Open AI affronte Google avec son propre moteur de recherche IA
Jul 30, 2024 am 09:58 AM
L’Open AI fait enfin son incursion dans la recherche. La société de San Francisco a récemment annoncé un nouvel outil d'IA doté de capacités de recherche. Rapporté pour la première fois par The Information en février de cette année, le nouvel outil s'appelle à juste titre SearchGPT et propose un c
