
 Périphériques technologiques
IA
Interprétation de CRISP-ML(Q) : processus du cycle de vie de l'apprentissage automatique
Périphériques technologiques
IA
Interprétation de CRISP-ML(Q) : processus du cycle de vie de l'apprentissage automatique
Interprétation de CRISP-ML(Q) : processus du cycle de vie de l'apprentissage automatique

Traducteur | Bugatti
Reviewer | Sun Shujuan
Actuellement, il n'existe pas de pratiques standard pour la création et la gestion d'applications d'apprentissage automatique (ML). Les projets d’apprentissage automatique sont mal organisés, manquent de répétabilité et ont tendance à échouer à long terme. Par conséquent, nous avons besoin d’un processus qui nous aide à maintenir la qualité, la durabilité, la robustesse et la gestion des coûts tout au long du cycle de vie de l’apprentissage automatique.
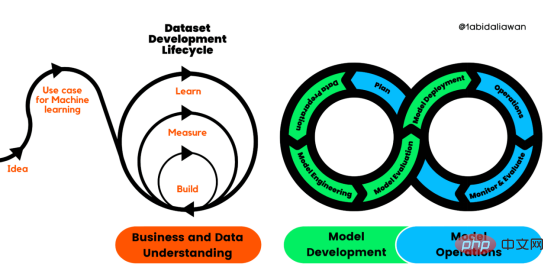
Figure 1. Processus du cycle de vie du développement de l'apprentissage automatique
Le processus standard intersectoriel pour le développement d'applications d'apprentissage automatique à l'aide de méthodes d'assurance qualité (CRISP-ML(Q)) est une version améliorée de CRISP-DM pour garantir que la machine apprendre la qualité des produits.
CRISP-ML (Q) comporte six étapes distinctes :
1. Compréhension de l'activité et des données
2 Préparation des données
3. Évaluation du modèle
5. et Maintenance
Ces étapes nécessitent une itération et une exploration constantes pour créer de meilleures solutions. Même si le cadre est ordonné, les résultats d’une étape ultérieure peuvent déterminer si nous devons réexaminer l’étape précédente.
Figure 2. Assurance qualité à chaque étape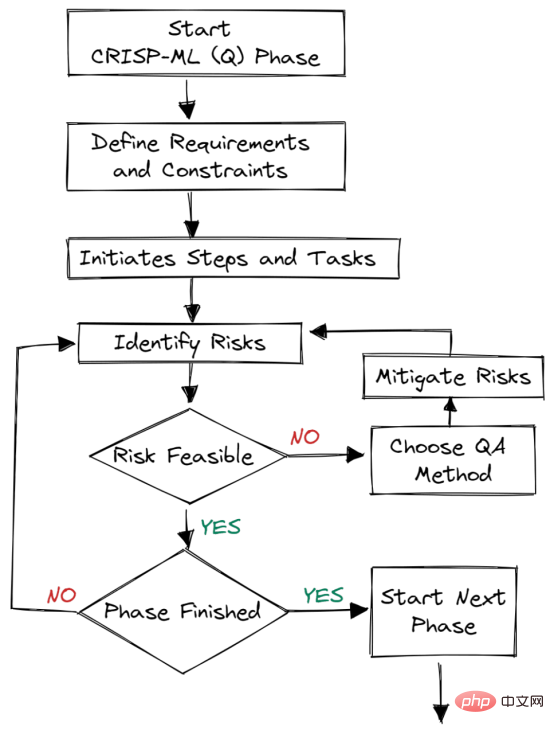 Des méthodes d'assurance qualité sont introduites à chaque étape du cadre. Cette approche comporte des exigences et des contraintes, telles que des mesures de performances, des exigences en matière de qualité des données et de robustesse. Cela permet de réduire les risques qui ont un impact sur le succès des applications d’apprentissage automatique. Cela peut être réalisé en surveillant et en entretenant en permanence l’ensemble du système.
Des méthodes d'assurance qualité sont introduites à chaque étape du cadre. Cette approche comporte des exigences et des contraintes, telles que des mesures de performances, des exigences en matière de qualité des données et de robustesse. Cela permet de réduire les risques qui ont un impact sur le succès des applications d’apprentissage automatique. Cela peut être réalisé en surveillant et en entretenant en permanence l’ensemble du système.
Par exemple : dans les entreprises de commerce électronique, la dérive des données et des concepts entraînera une dégradation du modèle ; si nous ne déployons pas de systèmes pour surveiller ces changements, l'entreprise subira des pertes, c'est-à-dire des clients.
Compréhension des affaires et des données
Au début du processus de développement, nous devons déterminer la portée du projet, les critères de réussite et la faisabilité de l'application ML. Après cela, nous avons commencé le processus de collecte de données et de vérification de la qualité. Le processus est long et difficile.
Portée :Ce que nous espérons réaliser en utilisant un processus d'apprentissage automatique. Est-ce pour fidéliser les clients ou réduire les coûts d’exploitation grâce à l’automatisation ?
Critères de réussite : Nous devons définir des indicateurs de réussite commerciaux, d'apprentissage automatique (indicateurs statistiques) et économiques (KPI) clairs et mesurables.
Faisabilité : Nous devons garantir la disponibilité des données, l'adéquation aux applications d'apprentissage automatique, les contraintes juridiques, la robustesse, l'évolutivité, l'interprétabilité et les besoins en ressources.
Collecte de données : Activez la reproductibilité en collectant des données, en les versionnant et en assurant un flux constant de données réelles et générées.
Vérification de la qualité des données : Assurez la qualité en maintenant les descriptions, les exigences et les validations des données.
Pour garantir la qualité et la reproductibilité, nous devons enregistrer les propriétés statistiques des données et le processus de génération des données. Préparation des données
La deuxième étape est très simple. Nous préparerons les données pour la phase de modélisation. Cela comprend la sélection des données, le nettoyage des données, l'ingénierie des fonctionnalités, l'amélioration et la normalisation des données.
1. Nous commençons par la sélection des fonctionnalités, la sélection des données et la gestion des classes déséquilibrées par suréchantillonnage ou sous-échantillonnage.
2. Ensuite, concentrez-vous sur la réduction du bruit et la gestion des valeurs manquantes. À des fins d'assurance qualité, nous ajouterons des tests unitaires de données pour réduire les valeurs erronées.
3. Selon le modèle, nous effectuons l'ingénierie des fonctionnalités et l'augmentation des données telles que l'encodage à chaud et le clustering.
4. Normalisez et étendez les données. Cela réduit le risque de fonctionnalités biaisées.
Pour garantir la reproductibilité, nous avons créé des pipelines de modélisation, de transformation et d'ingénierie de fonctionnalités.
Ingénierie des modèles
Les contraintes et exigences des phases métier et de compréhension des données détermineront la phase de modélisation. Nous devons comprendre les problèmes commerciaux et comment nous développerons des modèles d’apprentissage automatique pour les résoudre. Nous nous concentrerons sur la sélection, l'optimisation et la formation des modèles, en garantissant les mesures de performances, la robustesse, l'évolutivité, l'interprétabilité du modèle et en optimisant les ressources de stockage et de calcul.
1. Recherche sur l'architecture des modèles et problèmes commerciaux similaires.
2. Définir les indicateurs de performance du modèle.
3. Sélection du modèle.
4. Comprendre les connaissances du domaine en intégrant des experts.
5. Formation de modèle.
6. Compression et intégration du modèle.
Pour garantir la qualité et la reproductibilité, nous stockerons et contrôlerons les métadonnées du modèle, telles que l'architecture du modèle, les données de formation et de validation, les hyperparamètres et les descriptions d'environnement.
Enfin, nous suivrons les expériences de ML et créerons des pipelines de ML pour créer des processus de formation reproductibles.
Évaluation du modèle
C'est l'étape où nous testons et nous assurons que le modèle est prêt à être déployé.
- Nous testerons les performances du modèle sur l'ensemble de données de test.
- Évaluez la robustesse du modèle en fournissant des données aléatoires ou fausses.
- Améliorez l'interprétabilité du modèle pour répondre aux exigences réglementaires.
- Comparez les résultats aux mesures de réussite initiales automatiquement ou avec des experts du domaine.
Chaque étape de la phase d'évaluation est enregistrée pour l'assurance qualité.
Déploiement de modèles
Le déploiement de modèles est l'étape où nous intégrons des modèles d'apprentissage automatique dans les systèmes existants. Le modèle peut être déployé sur des serveurs, des navigateurs, des logiciels et des appareils périphériques. Les prédictions du modèle sont disponibles dans les tableaux de bord BI, les API, les applications Web et les plug-ins.
Processus de déploiement du modèle :
- Définir l'inférence matérielle.
- Évaluation de modèles en environnement de production.
- Assurer l'acceptation et la convivialité des utilisateurs.
- Fournissez des plans de sauvegarde pour minimiser les pertes.
- Stratégie de déploiement.
Surveillance et maintenance
Les modèles dans les environnements de production nécessitent une surveillance et une maintenance continues. Nous surveillerons la rapidité du modèle, les performances matérielles et les performances logicielles.
La surveillance continue est la première partie du processus ; si les performances descendent en dessous d'un seuil, une décision est prise automatiquement pour recycler le modèle sur de nouvelles données. De plus, la partie maintenance ne se limite pas au recyclage des modèles. Cela nécessite des mécanismes de prise de décision, l’acquisition de nouvelles données, la mise à jour des logiciels et du matériel et l’amélioration des processus de ML en fonction de cas d’utilisation métier.
En bref, c'est l'intégration, la formation et le déploiement continus de modèles ML.
Conclusion
La formation et la validation des modèles ne représentent qu'une petite partie des applications ML. Transformer une idée initiale en réalité nécessite plusieurs processus. Dans cet article, nous présentons CRISP-ML(Q) et comment il se concentre sur l'évaluation des risques et l'assurance qualité.
Nous définissons d'abord les objectifs commerciaux, collectons et nettoyons les données, construisons le modèle, vérifions le modèle avec des ensembles de données de test, puis le déployons dans l'environnement de production.
Les éléments clés de ce cadre sont la surveillance et la maintenance continues. Nous surveillerons les données et les mesures logicielles et matérielles pour déterminer s'il convient de recycler le modèle ou de mettre à niveau le système.
Si vous débutez dans les opérations d'apprentissage automatique et souhaitez en savoir plus, lisez le cours MLOps gratuit examiné par DataTalks.Club. Vous acquerrez une expérience pratique des six phases et comprendrez la mise en œuvre pratique de CRISP-ML.
Titre original : Making Sense of CRISP-ML(Q): The Machine Learning Lifecycle Process, auteur : Abid Ali Awan
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Les startups d'IA ont collectivement transféré leurs emplois vers OpenAI, et l'équipe de sécurité s'est regroupée après le départ d'Ilya !
Jun 08, 2024 pm 01:00 PM
Les startups d'IA ont collectivement transféré leurs emplois vers OpenAI, et l'équipe de sécurité s'est regroupée après le départ d'Ilya !
Jun 08, 2024 pm 01:00 PM
" sept péchés capitaux" » Dissiper les rumeurs : selon des informations divulguées et des documents obtenus par Vox, la haute direction d'OpenAI, y compris Altman, était bien au courant de ces dispositions de récupération de capitaux propres et les a approuvées. De plus, OpenAI est confronté à un problème grave et urgent : la sécurité de l’IA. Les récents départs de cinq employés liés à la sécurité, dont deux de ses employés les plus en vue, et la dissolution de l'équipe « Super Alignment » ont une nouvelle fois mis les enjeux de sécurité d'OpenAI sur le devant de la scène. Le magazine Fortune a rapporté qu'OpenA
 Comment évaluer la rentabilité du support commercial des frameworks Java
Jun 05, 2024 pm 05:25 PM
Comment évaluer la rentabilité du support commercial des frameworks Java
Jun 05, 2024 pm 05:25 PM
L'évaluation du rapport coût/performance du support commercial pour un framework Java implique les étapes suivantes : Déterminer le niveau d'assurance requis et les garanties de l'accord de niveau de service (SLA). L’expérience et l’expertise de l’équipe d’appui à la recherche. Envisagez des services supplémentaires tels que les mises à niveau, le dépannage et l'optimisation des performances. Évaluez les coûts de support commercial par rapport à l’atténuation des risques et à une efficacité accrue.
 Le modèle 70B génère 1 000 jetons en quelques secondes, la réécriture du code dépasse GPT-4o, de l'équipe Cursor, un artefact de code investi par OpenAI
Jun 13, 2024 pm 03:47 PM
Le modèle 70B génère 1 000 jetons en quelques secondes, la réécriture du code dépasse GPT-4o, de l'équipe Cursor, un artefact de code investi par OpenAI
Jun 13, 2024 pm 03:47 PM
Modèle 70B, 1000 tokens peuvent être générés en quelques secondes, ce qui se traduit par près de 4000 caractères ! Les chercheurs ont affiné Llama3 et introduit un algorithme d'accélération. Par rapport à la version native, la vitesse est 13 fois plus rapide ! Non seulement il est rapide, mais ses performances sur les tâches de réécriture de code dépassent même GPT-4o. Cette réalisation vient d'anysphere, l'équipe derrière le populaire artefact de programmation d'IA Cursor, et OpenAI a également participé à l'investissement. Il faut savoir que sur Groq, un framework d'accélération d'inférence rapide bien connu, la vitesse d'inférence de 70BLlama3 n'est que de plus de 300 jetons par seconde. Avec la vitesse de Cursor, on peut dire qu'il permet une édition complète et quasi instantanée des fichiers de code. Certaines personnes l'appellent un bon gars, si tu mets Curs
 Comment la courbe d'apprentissage des frameworks PHP se compare-t-elle à celle d'autres frameworks de langage ?
Jun 06, 2024 pm 12:41 PM
Comment la courbe d'apprentissage des frameworks PHP se compare-t-elle à celle d'autres frameworks de langage ?
Jun 06, 2024 pm 12:41 PM
La courbe d'apprentissage d'un framework PHP dépend de la maîtrise du langage, de la complexité du framework, de la qualité de la documentation et du support de la communauté. La courbe d'apprentissage des frameworks PHP est plus élevée par rapport aux frameworks Python et inférieure par rapport aux frameworks Ruby. Par rapport aux frameworks Java, les frameworks PHP ont une courbe d'apprentissage modérée mais un temps de démarrage plus court.
 Comment les options légères des frameworks PHP affectent-elles les performances des applications ?
Jun 06, 2024 am 10:53 AM
Comment les options légères des frameworks PHP affectent-elles les performances des applications ?
Jun 06, 2024 am 10:53 AM
Le framework PHP léger améliore les performances des applications grâce à une petite taille et une faible consommation de ressources. Ses fonctionnalités incluent : une petite taille, un démarrage rapide, une faible utilisation de la mémoire, une vitesse de réponse et un débit améliorés et une consommation de ressources réduite. Cas pratique : SlimFramework crée une API REST, seulement 500 Ko, une réactivité élevée et un débit élevé.
 Quelles sont les applications des coroutines Go en intelligence artificielle et en machine learning ?
Jun 05, 2024 pm 03:23 PM
Quelles sont les applications des coroutines Go en intelligence artificielle et en machine learning ?
Jun 05, 2024 pm 03:23 PM
Les applications des coroutines Go dans le domaine de l'intelligence artificielle et de l'apprentissage automatique incluent : la formation et la prédiction en temps réel : tâches de traitement parallèle pour améliorer les performances. Optimisation des hyperparamètres parallèles : explorez différents paramètres simultanément pour accélérer l'entraînement. Informatique distribuée : répartissez facilement les tâches et profitez du cloud ou du cluster.
 China Mobile : l'humanité entre dans la quatrième révolution industrielle et a officiellement annoncé « trois plans »
Jun 27, 2024 am 10:29 AM
China Mobile : l'humanité entre dans la quatrième révolution industrielle et a officiellement annoncé « trois plans »
Jun 27, 2024 am 10:29 AM
Selon les informations du 26 juin, lors de la cérémonie d'ouverture de la Conférence mondiale des communications mobiles 2024 de Shanghai (MWC Shanghai), le président de China Mobile, Yang Jie, a prononcé un discours. Il a déclaré qu'actuellement, la société humaine entre dans la quatrième révolution industrielle, dominée par l'information et profondément intégrée à l'information et à l'énergie, c'est-à-dire la « révolution de l'intelligence numérique », et la formation de nouvelles forces productives s'accélère. Yang Jie estime que de la « révolution de la mécanisation » entraînée par les machines à vapeur, à la « révolution de l'électrification » entraînée par l'électricité et les moteurs à combustion interne, en passant par la « révolution de l'information » entraînée par les ordinateurs et Internet, chaque cycle de révolution industrielle est basé sur « L'information et « l'énergie » constituent l'axe principal, apportant le développement de la productivité
