
 Périphériques technologiques
IA
L'art de la conception de systèmes : lorsque les applications HPC et IA deviennent courantes, où doit aller l'architecture GPU ?
Périphériques technologiques
IA
L'art de la conception de systèmes : lorsque les applications HPC et IA deviennent courantes, où doit aller l'architecture GPU ?
L'art de la conception de systèmes : lorsque les applications HPC et IA deviennent courantes, où doit aller l'architecture GPU ?


Nous avons mentionné il y a de nombreuses années que la formation des charges de travail d'IA avec suffisamment de données et l'utilisation de réseaux de neurones convolutifs devenaient progressivement monnaie courante, et les grands centres HPC (High Performance Computing) du monde le faisaient depuis de nombreuses années. Laissez cette charge au GPU de NVIDIA. Pour des tâches telles que la simulation et la modélisation, les performances du GPU sont tout à fait exceptionnelles. Essentiellement, la simulation/modélisation HPC et la formation en IA sont en fait une sorte de convergence harmonique, et les GPU, en tant que processeurs massivement parallèles, sont particulièrement efficaces pour effectuer ce type de travail.
Mais depuis 2012, la révolution de l'IA a officiellement éclaté et les logiciels de reconnaissance d'images ont amélioré pour la première fois la précision à un niveau supérieur à celui des humains. Nous sommes donc très curieux de savoir combien de temps peut durer le point commun d’un traitement efficace du HPC et de l’IA sur des GPU similaires. Ainsi, à l'été 2019, grâce au raffinement et à l'itération du modèle, nous avons essayé d'utiliser l'unité mathématique de précision mixte pour obtenir les mêmes résultats que les calculs FP64 dans le benchmark Linpack. Avant que Nvidia ne lance le GPU "Ampere" GA100 l'année suivante, nous avons une fois de plus essayé de tester les performances de traitement du HPC et de l'IA. À cette époque, Nvidia n'avait pas encore lancé le GPU "Ampere" A100, le géant des cartes graphiques n'avait donc pas encore officiellement opté pour la formation de modèles d'IA sur des cœurs tenseurs de précision mixte. La réponse est bien sûr désormais claire : les charges de travail HPC sur les unités vectorielles FP64 nécessitent quelques ajustements architecturaux pour maximiser les performances du GPU. Il ne fait aucun doute qu'elles sont un peu des « citoyens de seconde zone ». Mais à cette époque, tout était encore possible.
Avec le lancement du GPU « Hopper » GH100 de Nvidia plus tôt cette année, il existe un écart plus grand dans les améliorations de performances intergénérationnelles entre l’IA et le HPC. Non seulement cela, lors de la récente conférence GTC 2022 d'automne, le co-fondateur de Nvidia et CET Huang Jensen a déclaré que la charge de travail de l'IA elle-même était également devenue divergente, obligeant Nvidia à commencer à explorer le secteur des processeurs - ou, plus précisément, cela devrait être le cas. appelé contrôleur de mémoire étendue optimisé orienté GPU.
Nous discuterons de cette question en détail plus tard.
Deux fleurs s'épanouissent, une de chaque côté
Commençons par le jugement le plus clair. Si Nvidia souhaite que son GPU ait des performances FP64 plus élevées pour prendre en charge les applications HPC à virgule flottante 64 bits telles que la modélisation météorologique, les calculs de dynamique des fluides, l'analyse par éléments finis, la chromodynamique quantique et d'autres simulations mathématiques de haute intensité, alors l'accélérateur L'idée de conception devrait être comme ceci : créez un produit qui n'a pas de cœurs tenseurs ni de cœurs FP32 CUDA (principalement utilisés comme shaders graphiques dans l'architecture CUDA).
Mais je crains que seulement quelques centaines de clients soient prêts à acheter un tel produit, donc le prix d'une seule puce peut atteindre des dizaines de milliers, voire des centaines de milliers de dollars. Ce n'est qu'ainsi que les coûts de conception et de fabrication peuvent être atteints. être couvert. Afin de bâtir une activité plus grande et plus rentable, Nvidia doit concevoir une architecture plus générale dont les capacités mathématiques vectorielles sont tout simplement supérieures à celles des processeurs.
Ainsi, depuis que NVIDIA a décidé de se lancer sérieusement dans la conception de produits pour les applications HPC il y a 15 ans, ils se sont concentrés sur les scénarios HPC qui utilisent les opérations mathématiques à virgule flottante FP32, y compris les données simple précision utilisées dans le traitement sismique, le traitement du signal et la génomique. -typer les charges de travail et les tâches de traitement, et améliorer progressivement les capacités FP64 du GPU.
L'accélérateur K10 lancé en juillet 2012 est équipé de deux GPU "Kepler" GK104, qui sont exactement les mêmes GPU utilisés dans les cartes graphiques de jeu. Il possède 1536 cœurs FP32 CUDA et n’utilise aucun cœur FP64 dédié. Sa prise en charge FP64 se fait uniquement par logiciel, il n'y a donc pas de gain de performances appréciable : les deux GPU GK104 fonctionnent à 4,58 téraflops sur les tâches FP32 et 190 gigaflops sur FP64, soit un rapport de 24 pour 1. Le K20X, présenté lors de la SC12 Supercomputing Conference fin 2012, utilise le GPU GK110, avec des performances FP32 de 3,95 téraflops et FP64 de 1,31 téraflops, soit un ratio porté à 3:1. À ce stade, le produit est initialement disponible pour les applications HPC et les utilisateurs qui forment des modèles d’IA dans l’espace informatique académique/hyperscale. La carte accélératrice GPU K80 utilise deux GPU GK110B à l'époque, car Nvidia n'avait pas ajouté le support FP64 au GPU "Maxwell" le plus haut de gamme, le GK110 B est donc devenu l'option la plus populaire et la plus rentable à l'époque. Les performances FP32 du K80 sont de 8,74 téraflops et les performances FP64 de 2,91 téraflops, tout en conservant un rapport de 3 pour 1.
Pour le GPU GP100 "Pascal", l'écart entre le HPC et l'IA s'est encore creusé avec l'introduction de l'indicateur de précision mixte FP16, mais le rapport du vecteur FP32 au vecteur FP64 s'est encore converti à 2 pour 1, et après le " Volta" GV100 " Il a été maintenu dans les GPU les plus récents tels que l'Ampère” GA100 et le “Hopper” GH100. Dans l'architecture Volta, NVIDIA a introduit pour la première fois l'unité mathématique matricielle Tensor Core avec une matrice fixe Lei small, qui a considérablement amélioré les capacités de calcul en virgule flottante (et entière) et a continué à conserver l'unité vectorielle dans l'architecture.
Ces noyaux tenseurs sont utilisés pour traiter des matrices de plus en plus grandes, mais la précision de fonctionnement spécifique est de plus en plus faible, de sorte que ce type d'équipement a atteint un débit de charge d'IA extrêmement exagéré. Ceci est bien sûr indissociable de la nature statistique floue de l’apprentissage automatique lui-même, et cela laisse également un écart énorme avec les mathématiques de haute précision requises par la plupart des algorithmes HPC. La figure ci-dessous montre la représentation logarithmique de l'écart de performances entre l'IA et le HPC. Je pense que vous pouvez déjà voir la différence de tendance entre les deux :
.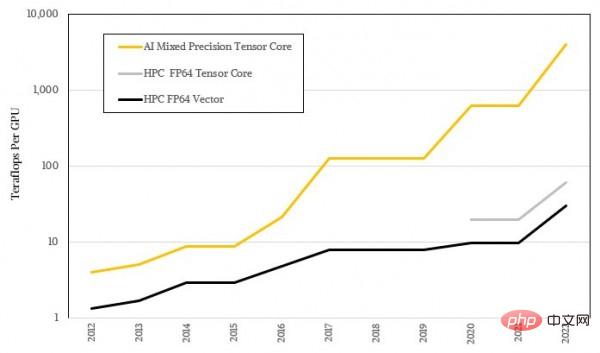
La forme logarithmique ne semble pas assez choquante, examinons-la à nouveau en utilisant le rapport réel :
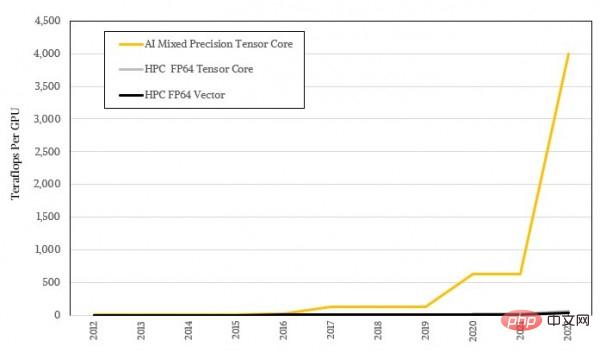
L'art de la conception de systèmes : lorsque les applications HPC et IA deviennent courantes, où devrait l'architecture GPU aller?
Toutes les applications HPC ne peuvent pas être ajustées pour les cœurs tenseurs, et toutes les applications ne peuvent pas transférer des opérations mathématiques vers les cœurs tenseurs, donc NVIDIA conserve toujours certaines unités vectorielles dans son architecture GPU. De plus, de nombreuses organisations HPC ne peuvent pas réellement proposer de solveurs itératifs comme HPL-AI. Le solveur HPL-AI utilisé dans le test de référence Linpack utilise HPL Linpack standard avec des opérations FP16 plus FP32, et un peu d'opérations FP64 pour converger vers la même réponse que les calculs de force brute FP64 purs. Ce solveur itératif est capable de fournir une accélération effective de 6,2x sur le supercalculateur Frontier du laboratoire national d'Oak Ridge et de 4,5x sur le supercalculateur Fugaku du laboratoire RIKEN. Si davantage d'applications HPC peuvent recevoir leurs propres solveurs HPL-AI, alors le problème de la « séparation » de l'IA et du HPC sera résolu, je pense, ce jour viendra.
Mais en même temps, pour de nombreuses charges de travail, les performances du FP64 restent le seul facteur décisif. Et Nvidia, qui a gagné beaucoup d'argent grâce à sa puissante puissance de calcul IA, n'aura certainement pas beaucoup de temps pour s'occuper du marché HPC dans un court laps de temps.
Deux autres fleurs s'épanouissent, et une branche chacune
On peut voir que l'architecture GPU de NVIDIA vise principalement des performances d'IA plus élevées tout en maintenant des performances HPC acceptables, et l'approche à deux volets guide les clients dans la mise à jour de leur matériel tous les trois ans. Du point de vue des performances pures du FP64, le débit FP64 des GPU Nvidia a été multiplié par 22,9 au cours des dix années allant de 2012 à 2022, passant de 1,3 téraflops du K20X à 30 téraflops du H100. Si l’unité matricielle tensorielle peut être utilisée avec le solveur itératif, l’augmentation peut atteindre 45,8 fois. Mais si vous êtes un utilisateur de formation en IA qui n'a besoin que d'un calcul parallèle à grande échelle et de faible précision, alors le changement de performances du FP32 au FP8 est exagéré. La puissance de calcul du FP32 a été augmentée des premiers téraflops à 4 pétaflops du FP8. matrice, ce qui représente une amélioration de 1012,7 fois. Et si nous le comparons à l'algorithme d'IA codé en FP64 sur le GPU K20X à l'époque (pratique courante à l'époque), l'amélioration des performances au cours des dix dernières années n'est que de 2 fois pitoyable.
Évidemment, la différence de performances entre les deux ne peut pas être qualifiée d'énorme. Huang Renxun lui-même a également mentionné que le camp actuel de l'IA lui-même est à nouveau divisé en deux. Un type est un modèle de base géant pris en charge par le modèle de transformateur, également connu sous le nom de grand modèle de langage. Le nombre de paramètres de ces modèles augmente rapidement et la demande de matériel augmente également. Par rapport au modèle de réseau neuronal précédent, le modèle de transformateur d'aujourd'hui représente complètement une autre époque, comme le montre l'image ci-dessous :

Veuillez pardonner cette image d'être un peu floue, mais le fait est : pour le premier groupe qui ne le fait pas contiennent des transformateurs Pour les modèles IA, les exigences informatiques ont augmenté 8 fois en deux ans, mais pour les modèles IA contenant des transformateurs, les exigences informatiques ont augmenté 275 fois en deux ans ; Si des opérations en virgule flottante sont utilisées pour le traitement, il doit y avoir 100 000 GPU dans le système pour répondre à la demande (ce n'est pas un gros problème). Cependant, le passage à la précision FP4 doublera le nombre de calculs. À l'avenir, lorsque le GPU utilisera des transistors de 1,8 nm, la puissance de calcul augmentera d'environ 2,5 fois, il y aura donc encore un écart d'environ 55 fois. Si les opérations du FP2 pouvaient être mises en œuvre (en supposant qu'une telle précision soit suffisante pour résoudre le problème), la quantité de calcul pourrait être réduite de moitié, mais cela nécessiterait l'utilisation d'au moins 250 000 GPU. De plus, les grands modèles de transformateurs de langage sont souvent difficiles à étendre, et surtout économiquement réalisables. Ce type de modèle est donc devenu exclusif aux entreprises géantes, tout comme les armes nucléaires ne sont entre les mains que des pays puissants.
Quant au système de recommandation en tant que « moteur économique numérique », il nécessite non seulement une augmentation exponentielle du nombre de calculs, mais aussi une échelle de données qui dépasse largement la capacité mémoire d'un grand modèle de langage ou même d'un GPU. Huang Renxun a mentionné dans son précédent discours d'ouverture du GTC :
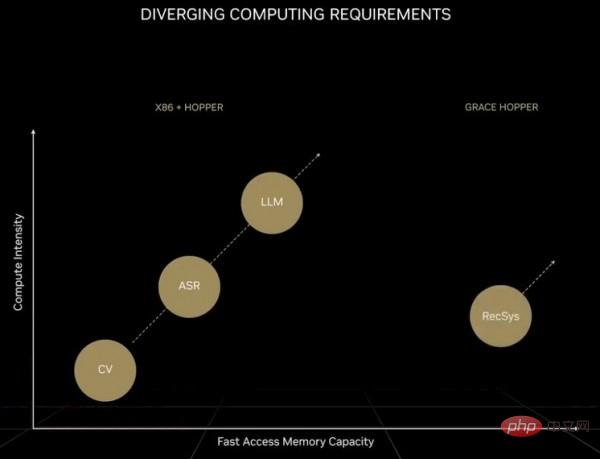
"Par rapport aux grands modèles de langage, la quantité de données rencontrée par chaque unité de calcul lors du traitement du système de recommandation est d'un ordre de grandeur plus grande. De toute évidence, le système de recommandation nécessite non seulement une vitesse de mémoire plus rapide, mais nécessite également 10 fois la vitesse de mémoire de le grand modèle de langage. Capacité de mémoire. Bien que les grands modèles de langage maintiennent une croissance exponentielle au fil du temps et nécessitent une puissance de calcul constante, les systèmes de recommandation maintiennent également ce taux de croissance et continuent de consommer davantage de modèles de langage et de recommandations. Les modèles d'IA d'aujourd'hui ont des exigences informatiques différentes. Les systèmes de recommandation peuvent s'adapter à des milliards d'utilisateurs et à des milliards d'éléments, pour chaque article, chaque vidéo et chaque publication sociale. La représentation numérique correspondante est appelée une intégration. Chaque table d'intégration peut en contenir des dizaines. de téraoctets de données et doit être traité par plusieurs GPU. Lors du traitement des systèmes de recommandation, cela nécessite un traitement parallèle des données dans certaines parties du réseau. D'autres parties du réseau sont nécessaires pour mettre en œuvre un traitement parallèle modèle, ce qui impose des exigences plus élevées en matière de données. différentes parties de l'ordinateur. "
Comme le montre la figure ci-dessous, il s'agit de l'architecture de base du système de recommandation :
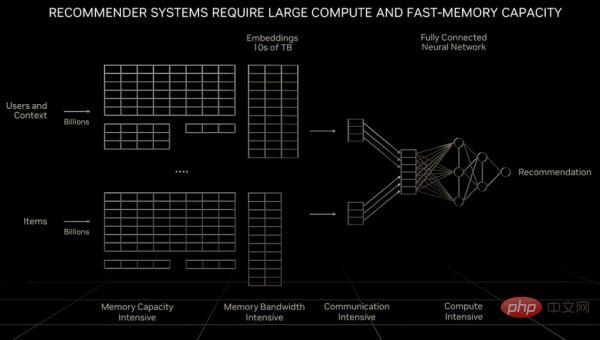
Afin de comprendre et de décider des particularités. En raison de problèmes de capacité de mémoire et de bande passante, NVIDIA a développé le Processeur du serveur Arm "Grace" et étroitement couplé au GPU Hopper. Nous plaisantons également en disant que si la quantité de mémoire principale requise est très importante, Grace n'est en réalité que le contrôleur de mémoire de Hopper. Mais à long terme, il suffit peut-être de connecter un certain nombre de ports CXL exécutant le protocole NVLink au GPU de nouvelle génération de Hooper.
Ainsi, la super puce Grace-Hopper produite par NVIDIA équivaut à placer un cluster CPU de niveau « enfant » dans un énorme cluster d'accélération GPU de niveau « adulte ». Ces processeurs Arm peuvent prendre en charge les charges de travail traditionnelles C++ et Fortran, mais à un prix : les performances de la partie CPU dans le cluster hybride ne représentent qu'un dixième des performances du GPU dans le cluster, mais le coût est 3 à 3 fois supérieur. d'un cluster CPU pur conventionnel 5 fois.
D'ailleurs, nous respectons et comprenons tous les choix d'ingénierie faits par NVIDIA. Grace est un excellent CPU et Hopper est également un excellent GPU. La combinaison des deux produira certainement de bons résultats. Mais ce qui se passe aujourd’hui, c’est que nous sommes confrontés à trois charges de travail distinctes sur la même plateforme, chacune tirant l’architecture dans une direction différente. Calcul haute performance, grands modèles de langage et systèmes de recommandation, ces trois frères ont leurs propres caractéristiques, et il est tout simplement impossible d'optimiser l'architecture en même temps de manière rentable.
Et il est évident que l’IA présente de grands avantages, alors que le HPC perd peu à peu du terrain. Cette situation dure depuis près de dix ans. Si HPC veut achever sa transformation, son code doit se rapprocher des systèmes de recommandation et des grands modèles de langage, plutôt que de continuer à insister sur l'exécution du code C++ et Fortran existant sur FP64. Et il est évident que les clients HPC bénéficient d’une prime pour chaque opération par rapport aux clients IA. Par conséquent, à moins que les experts HPC ne trouvent une méthode de développement universelle pour des solveurs itératifs capables de modéliser le monde physique avec une précision moindre, il sera difficile d’inverser cette situation passive.
Depuis des décennies, nous avons toujours pensé que la nature elle-même n'est pas conforme aux lois mathématiques. Nous sommes obligés d’utiliser des mathématiques de haute précision pour décrire les effets de la nature, ou nous utilisons un langage inapproprié pour décrire la réalité objective. Bien entendu, la nature peut être plus subtile que nous l’imaginons, et les solveurs itératifs sont plus proches de la réalité que nous souhaitons modéliser. Si tel est le cas, cela pourrait être une bénédiction pour l’humanité, encore plus chanceuse que la coïncidence accidentelle du HPC et de l’IA il y a dix ans.
Après tout, il n'y a pas de route au monde Quand il y a plus de gens qui marchent, cela devient une route.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
