
 Périphériques technologiques
IA
Méthode d'adaptation de domaine virtuel-réel pour la détection et la classification de voies de conduite autonomes
Périphériques technologiques
IA
Méthode d'adaptation de domaine virtuel-réel pour la détection et la classification de voies de conduite autonomes
Méthode d'adaptation de domaine virtuel-réel pour la détection et la classification de voies de conduite autonomes

Article arXiv « Adaptation du domaine Sim-to-Real pour la détection et la classification des voies dans la conduite autonome », mai 2022, travail à l'Université de Waterloo, Canada.

Bien que le cadre de détection et de classification supervisée pour la conduite autonome nécessite de grands ensembles de données annotées, la méthode Unsupervised Domain Adaptation (UDA, Unsupervised Domain Adaptation) pilotée par des données synthétiques générées par l'éclairage d'environnements de simulation réels est peu coûteuse, Solution qui prend moins de temps. Cet article propose un schéma UDA de méthodes discriminantes et génératives contradictoires pour les applications de détection et de classification des lignes de voie dans la conduite autonome.
Présente également le générateur d'ensembles de données Simulanes, qui tire parti des énormes scènes de circulation et des conditions météorologiques de CARLA pour créer un ensemble de données synthétiques naturelles. Le cadre UDA proposé prend l'ensemble de données synthétiques étiquetées comme domaine source, tandis que le domaine cible est constitué des données réelles non étiquetées. Utilisez la génération contradictoire et le discriminateur de fonctionnalités pour déboguer le modèle d'apprentissage et prédire l'emplacement et la catégorie de la voie du domaine cible. L'évaluation est effectuée avec des ensembles de données réelles et synthétiques.
Le framework UDA open source se trouve sur githubcom/anita-hu/sim2real-lane-detection, et le générateur d'ensembles de données se trouve sur github.com/anita-hu/simulanes.
La conduite dans le monde réel est diversifiée, avec des conditions de circulation, des conditions météorologiques et des environnements variables. La diversité des scénarios de simulation est donc cruciale pour la bonne adaptabilité du modèle au monde réel. Il existe de nombreux simulateurs open source pour la conduite autonome, à savoir CARLA et LGSVL. Cet article choisit CARLA pour générer l'ensemble de données de simulation. En plus de l'API Python flexible, CARLA contient également un riche contenu cartographique pré-dessiné couvrant des scènes urbaines, rurales et routières.
Générateur de données de simulation Simulanes génère une variété de scénarios de simulation dans des environnements urbains, ruraux et routiers, y compris 15 catégories de voies et une météo dynamique. La figure montre des échantillons de l'ensemble de données synthétiques. Les piétons et les véhicules participants sont générés de manière aléatoire et placés sur la carte, augmentant ainsi la difficulté de l'ensemble de données par occlusion. Selon les ensembles de données TuSimple et CULane, le nombre maximum de voies à proximité du véhicule est limité à 4 et les ancrages de rangée sont utilisés comme étiquettes.

Étant donné que le simulateur CARLA ne fournit pas directement les étiquettes d'emplacement des voies, le système de points de cheminement de CARLA est utilisé pour générer des étiquettes. Un waypoint CARLA est une position prédéfinie que le pilote automatique du véhicule doit suivre, située au centre de la voie. Afin d'obtenir l'étiquette de position de voie, le waypoint de la voie actuelle est déplacé vers la gauche et la droite de W/2, où W est la largeur de voie donnée par le simulateur. Ces points de cheminement déplacés sont ensuite projetés dans le système de coordonnées de la caméra et ajustés par spline pour générer des étiquettes le long de points d'ancrage de rangée prédéterminés. L'étiquette de classe est donnée par le simulateur et constitue l'une des 15 classes.
Pour générer un ensemble de données avec N images, divisez N uniformément sur toutes les cartes disponibles. À partir de la carte CARLA par défaut, les villes 1, 3, 4, 5, 7 et 10 ont été utilisées, tandis que les villes 2 et 6 n'ont pas été utilisées en raison des différences entre les étiquettes de position des voies extraites et les positions des voies de l'image. Pour chaque carte, les véhicules participants apparaissent à des endroits aléatoires et se déplacent de manière aléatoire. La météo dynamique est obtenue en changeant doucement la position du soleil en fonction sinusoïdale du temps et en produisant occasionnellement des tempêtes, qui affectent l'apparence de l'environnement à travers des variables telles que la couverture nuageuse, le volume d'eau et l'eau stagnante. Pour éviter d'enregistrer plusieurs images au même emplacement, vérifiez si le véhicule s'est déplacé de l'emplacement de l'image précédente et régénérez un nouveau véhicule s'il est resté à l'arrêt trop longtemps.
Lorsque l'algorithme sim-to-real est appliqué à la détection de voie, une approche de bout en bout est adoptée et le Modèle de détection de voie ultra-rapide (UFLD) est utilisé comme réseau de base. UFLD a été choisi car son architecture légère peut atteindre 300 images/seconde avec la même résolution d'entrée tout en atteignant des performances comparables aux méthodes de pointe. UFLD formule la tâche de détection de voie comme une méthode de sélection basée sur les lignes, où chaque voie est représentée par une série de positions horizontales de lignes prédéfinies, c'est-à-dire des ancres de ligne. Pour chaque ancre de ligne, la position est divisée en w cellules de grille. Pour l'ancre de la i-ème voie et de la j-ème rangée, la prédiction d'emplacement devient un problème de classification, où le modèle génère la probabilité Pi,j de sélectionner la cellule de grille (w+1). La dimension supplémentaire dans la sortie est l'absence de voies.
UFLD propose une branche de segmentation auxiliaire pour agréger des fonctionnalités à plusieurs échelles afin de modéliser des fonctionnalités locales. Elle n'est utilisée que lors de la formation. Avec la méthode UFLD, la perte d'entropie croisée est utilisée pour la perte de segmentation Lseg. Pour la classification des voies, une petite branche de la couche entièrement connectée (FC) est ajoutée pour recevoir les mêmes fonctionnalités que la couche FC pour la prédiction de la position des voies. La perte de classification de voie Lcls utilise également la perte d'entropie croisée.
Pour atténuer le problème de dérive de domaine des paramètres UDA, UNIT(« Réseaux de traduction d'image à image non supervisés», NIPS, 2017) & MUNIT(« Traduction multimodale d'image à image non supervisée, » ECCV 2018) méthode de génération contradictoire et méthode discriminante contradictoire utilisant un discriminateur de fonctionnalités. Comme le montre la figure : une méthode de génération contradictoire (A) et une méthode de discrimination contradictoire (B) sont proposées. UNIT et MUNIT sont représentés en (A), qui montre l'entrée du générateur pour la traduction d'image. Les entrées de style supplémentaires dans MUNIT sont affichées avec des lignes bleues en pointillés. Pour plus de simplicité, la sortie de l'encodeur de style MUNIT est omise car elle n'est pas utilisée pour la traduction d'image.

Les résultats expérimentaux sont les suivants :
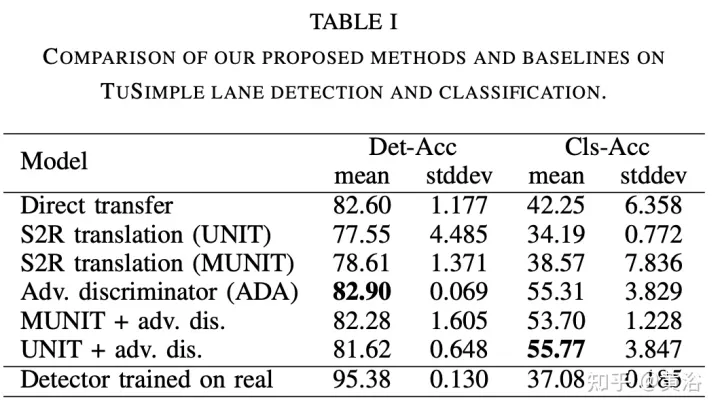

Gauche : méthode de transfert direct, droite : méthode d'identification contradictoire (ADA)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
DDREASE est un outil permettant de récupérer des données à partir de périphériques de fichiers ou de blocs tels que des disques durs, des SSD, des disques RAM, des CD, des DVD et des périphériques de stockage USB. Il copie les données d'un périphérique bloc à un autre, laissant derrière lui les blocs corrompus et ne déplaçant que les bons blocs. ddreasue est un puissant outil de récupération entièrement automatisé car il ne nécessite aucune interruption pendant les opérations de récupération. De plus, grâce au fichier map ddasue, il peut être arrêté et repris à tout moment. Les autres fonctionnalités clés de DDREASE sont les suivantes : Il n'écrase pas les données récupérées mais comble les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement. Récupérer les données de plusieurs fichiers ou blocs en un seul
 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
