
 Périphériques technologiques
IA
Parlons de reconnaissance d'image : réseau de neurones récurrents
Périphériques technologiques
IA
Parlons de reconnaissance d'image : réseau de neurones récurrents
Parlons de reconnaissance d'image : réseau de neurones récurrents

Cet article est réimprimé du compte public WeChat « Vivre à l'ère de l'information ». L'auteur vit à l'ère de l'information. Pour réimprimer cet article, veuillez contacter le compte public Vivre à l’ère de l’information.
Le réseau neuronal récurrent (RNN) est principalement utilisé pour résoudre des problèmes de données de séquence. La raison pour laquelle il s’agit d’un réseau neuronal récurrent est que la sortie actuelle d’une séquence est également liée à la sortie précédente. Le réseau RNN mémorise les informations des moments précédents et les applique au calcul de sortie actuel. Contrairement au réseau neuronal convolutif, les neurones des couches cachées du réseau neuronal récurrent sont connectés les uns aux autres. déterminé par l'entrée La sortie de la couche est composée de la sortie des neurones cachés à l'instant précédent. Bien que le réseau RNN ait obtenu des résultats remarquables, il présente certains défauts et limites, tels que : difficulté de formation, faible précision, faible efficacité, longue durée, etc. Par conséquent, certains modèles de réseau améliorés basés sur RNN ont été progressivement développés, tels que comme : Mémoire Long Court Terme (LSTM), RNN bidirectionnel, LSTM bidirectionnel, GRU, etc. Ces modèles RNN améliorés ont montré des résultats exceptionnels dans le domaine de la reconnaissance d’images et sont largement utilisés. En prenant le réseau LSTM comme exemple, nous présenterons sa structure principale de réseau.
La mémoire à long terme (LSTM) résout les problèmes de disparition ou d'explosion de gradient dans RNN et peut apprendre les problèmes de dépendance à long terme. Sa structure est la suivante.
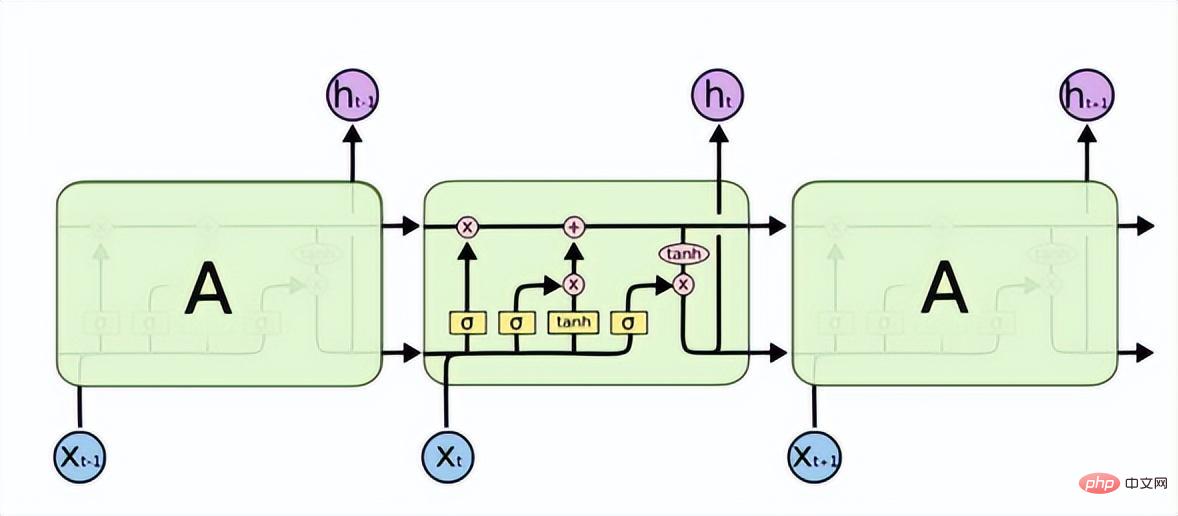
LSTM dispose de trois portes pour transmettre sélectivement les informations : la porte d'oubli, la porte d'entrée et la porte de sortie. La porte d'oubli détermine quelles informations peuvent passer par cette cellule. Il est mis en œuvre à travers une couche neuronale sigmoïde. Son entrée est et la sortie est un vecteur avec une valeur comprise entre (0, 1), représentant la proportion de chaque partie de l'information autorisée à passer. 0 signifie « ne laisser passer aucune information », 1 signifie « laisser passer toutes les informations ».
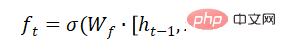
La porte d'entrée détermine la quantité de nouvelles informations ajoutées à l'état de la cellule. Une couche tanh génère un vecteur, qui est le contenu alternatif pour la mise à jour.
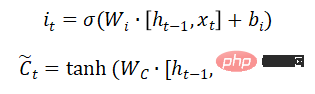
Mettre à jour l'état de la cellule :
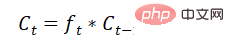
Quelle partie des informations de la décision de la porte de sortie est émise :
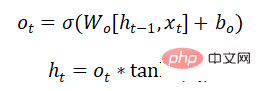
Le modèle de réseau GRU résout également le problème de la disparition du gradient ou gradient dans RNN Les problèmes tels que les explosions peuvent apprendre des dépendances à long terme. C'est une déformation du LSTM. La structure est plus simple que le LSTM, a moins de paramètres et le temps de formation est également plus court que le LSTM. Il est également largement utilisé dans la reconnaissance vocale, la description d’images, le traitement du langage naturel et d’autres scénarios.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment télécharger l'image de fond d'écran Windows Spotlight sur PC
Aug 23, 2023 pm 02:06 PM
Comment télécharger l'image de fond d'écran Windows Spotlight sur PC
Aug 23, 2023 pm 02:06 PM
Les fenêtres ne négligent jamais l’esthétique. Des champs verts bucoliques de XP au design tourbillonnant bleu de Windows 11, les fonds d’écran par défaut sont une source de plaisir pour les utilisateurs depuis des années. Avec Windows Spotlight, vous avez désormais un accès direct chaque jour à des images magnifiques et impressionnantes pour votre écran de verrouillage et votre fond d’écran. Malheureusement, ces images ne traînent pas. Si vous êtes tombé amoureux de l'une des images phares de Windows, vous voudrez savoir comment les télécharger afin de pouvoir les conserver comme arrière-plan pendant un certain temps. Voici tout ce que vous devez savoir. Qu’est-ce que WindowsSpotlight ? Window Spotlight est un programme de mise à jour automatique du fond d'écran disponible dans Personnalisation et dans l'application Paramètres.
 YOLO est immortel ! YOLOv9 est sorti : performances et vitesse SOTA~
Feb 26, 2024 am 11:31 AM
YOLO est immortel ! YOLOv9 est sorti : performances et vitesse SOTA~
Feb 26, 2024 am 11:31 AM
Les méthodes d'apprentissage profond d'aujourd'hui se concentrent sur la conception de la fonction objectif la plus appropriée afin que les résultats de prédiction du modèle soient les plus proches de la situation réelle. Dans le même temps, une architecture adaptée doit être conçue pour obtenir suffisamment d’informations pour la prédiction. Les méthodes existantes ignorent le fait que lorsque les données d’entrée subissent une extraction de caractéristiques couche par couche et une transformation spatiale, une grande quantité d’informations sera perdue. Cet article abordera des problèmes importants lors de la transmission de données via des réseaux profonds, à savoir les goulots d'étranglement de l'information et les fonctions réversibles. Sur cette base, le concept d'information de gradient programmable (PGI) est proposé pour faire face aux différents changements requis par les réseaux profonds pour atteindre des objectifs multiples. PGI peut fournir des informations d'entrée complètes pour la tâche cible afin de calculer la fonction objectif, obtenant ainsi des informations de gradient fiables pour mettre à jour les pondérations du réseau. De plus, un nouveau cadre de réseau léger est conçu
 Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Les modèles d'apprentissage profond pour les tâches de vision (telles que la classification d'images) sont généralement formés de bout en bout avec des données provenant d'un seul domaine visuel (telles que des images naturelles ou des images générées par ordinateur). Généralement, une application qui effectue des tâches de vision pour plusieurs domaines doit créer plusieurs modèles pour chaque domaine distinct et les former indépendamment. Les données ne sont pas partagées entre différents domaines. Lors de l'inférence, chaque modèle gérera un domaine spécifique. Même s'ils sont orientés vers des domaines différents, certaines caractéristiques des premières couches entre ces modèles sont similaires, de sorte que la formation conjointe de ces modèles est plus efficace. Cela réduit la latence et la consommation d'énergie, ainsi que le coût de la mémoire lié au stockage de chaque paramètre du modèle. Cette approche est appelée apprentissage multidomaine (MDL). De plus, les modèles MDL peuvent également surpasser les modèles simples.
 Comment utiliser la technologie de segmentation sémantique d'images en Python ?
Jun 06, 2023 am 08:03 AM
Comment utiliser la technologie de segmentation sémantique d'images en Python ?
Jun 06, 2023 am 08:03 AM
Avec le développement continu de la technologie de l’intelligence artificielle, la technologie de segmentation sémantique des images est devenue une direction de recherche populaire dans le domaine de l’analyse d’images. Dans la segmentation sémantique d'image, nous segmentons différentes zones d'une image et classons chaque zone pour obtenir une compréhension globale de l'image. Python est un langage de programmation bien connu. Ses puissantes capacités d'analyse et de visualisation de données en font le premier choix dans le domaine de la recherche sur les technologies d'intelligence artificielle. Cet article expliquera comment utiliser la technologie de segmentation sémantique d'images en Python. 1. Les connaissances préalables s’approfondissent
 1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
Adresse papier : https://arxiv.org/abs/2307.09283 Adresse code : https://github.com/THU-MIG/RepViTRepViT fonctionne bien dans l'architecture ViT mobile et présente des avantages significatifs. Ensuite, nous explorons les contributions de cette étude. Il est mentionné dans l'article que les ViT légers fonctionnent généralement mieux que les CNN légers sur les tâches visuelles, principalement en raison de leur module d'auto-attention multi-têtes (MSHA) qui permet au modèle d'apprendre des représentations globales. Cependant, les différences architecturales entre les ViT légers et les CNN légers n'ont pas été entièrement étudiées. Dans cette étude, les auteurs ont intégré des ViT légers dans le système efficace.
 Comment implémenter la reconnaissance vocale et la synthèse vocale en C++ ?
Aug 26, 2023 pm 02:49 PM
Comment implémenter la reconnaissance vocale et la synthèse vocale en C++ ?
Aug 26, 2023 pm 02:49 PM
Comment implémenter la reconnaissance vocale et la synthèse vocale en C++ ? La reconnaissance vocale et la synthèse vocale constituent aujourd’hui l’une des directions de recherche les plus populaires dans le domaine de l’intelligence artificielle et jouent un rôle important dans de nombreux scénarios d’application. Cet article présentera comment utiliser C++ pour implémenter des fonctions de reconnaissance vocale et de synthèse vocale basées sur la plateforme ouverte Baidu AI, et fournira des exemples de code pertinents. 1. Reconnaissance vocale La reconnaissance vocale est une technologie qui convertit la parole humaine en texte. Elle est largement utilisée dans les assistants vocaux, les maisons intelligentes, la conduite autonome et d'autres domaines. Ce qui suit est l'implémentation de la reconnaissance vocale en utilisant C++
 Technologie de détection et de reconnaissance des visages implémentée à l'aide de Java
Jun 18, 2023 am 09:08 AM
Technologie de détection et de reconnaissance des visages implémentée à l'aide de Java
Jun 18, 2023 am 09:08 AM
Avec le développement continu de la technologie de l’intelligence artificielle, la technologie de détection et de reconnaissance des visages est devenue de plus en plus largement utilisée dans la vie quotidienne. Dans diverses occasions, telles que les systèmes de contrôle d'accès facial, les systèmes de paiement facial, les moteurs de recherche de visage, etc., les technologies de détection et de reconnaissance faciale sont largement utilisées. En tant que langage de programmation largement utilisé, Java peut également mettre en œuvre une technologie de détection et de reconnaissance des visages. Cet article explique comment utiliser Java pour implémenter la technologie de détection et de reconnaissance des visages. 1. Technologie de détection de visage La technologie de détection de visage fait référence à la technologie qui détecte les visages dans les images ou les vidéos. en J
 iOS 17 : Comment utiliser le recadrage en un clic des photos
Sep 20, 2023 pm 08:45 PM
iOS 17 : Comment utiliser le recadrage en un clic des photos
Sep 20, 2023 pm 08:45 PM
Avec l'application iOS 17 Photos, Apple facilite le recadrage des photos selon vos spécifications. Lisez la suite pour savoir comment. Auparavant, dans iOS 16, le recadrage d'une image dans l'application Photos impliquait plusieurs étapes : appuyez sur l'interface d'édition, sélectionnez l'outil de recadrage, puis ajustez le recadrage à l'aide d'un geste de pincement pour zoomer ou en faisant glisser les coins de l'outil de recadrage. Dans iOS 17, Apple a heureusement simplifié ce processus afin que lorsque vous zoomez sur une photo sélectionnée dans votre bibliothèque Photos, un nouveau bouton Recadrer apparaisse automatiquement dans le coin supérieur droit de l'écran. En cliquant dessus, l'interface de recadrage complète s'affichera avec le niveau de zoom de votre choix. Vous pourrez ainsi recadrer la partie de l'image que vous aimez, faire pivoter l'image, inverser l'image, appliquer un rapport d'écran ou utiliser des marqueurs.
