
 Périphériques technologiques
IA
Pourquoi les modèles arborescents surpassent toujours l'apprentissage profond sur les données tabulaires
Périphériques technologiques
IA
Pourquoi les modèles arborescents surpassent toujours l'apprentissage profond sur les données tabulaires
Pourquoi les modèles arborescents surpassent toujours l'apprentissage profond sur les données tabulaires

Dans cet article, j'expliquerai en détail l'article "Pourquoi les modèles basés sur des arbres surpassent-ils toujours l'apprentissage profond sur les données tabulaires" Cet article explique un phénomène qui a été observé par les praticiens de l'apprentissage automatique du monde entier dans divers domaines - Phénomène. Les modèles basés sur les réseaux sont bien meilleurs pour analyser les données tabulaires que les réseaux d'apprentissage profond/neuraux.
Notes sur le papier
Ce papier a subi de nombreux prétraitements. Par exemple, des éléments tels que la suppression des données manquantes peuvent nuire aux performances de l'arborescence, mais les forêts aléatoires sont idéales pour les situations de données manquantes si vos données sont très désordonnées : elles contiennent de nombreuses fonctionnalités et dimensions. La robustesse et les avantages de la RF la rendent supérieure aux solutions plus « avancées », sujettes à des problèmes.

La majeure partie du reste du travail est assez standard. Personnellement, je n'aime pas appliquer trop de techniques de prétraitement, car cela peut entraîner la perte de nombreuses nuances de l'ensemble de données, mais les étapes suivies dans le document produisent essentiellement le même ensemble de données. Il est toutefois important de noter que la même méthode de traitement est utilisée lors de l’évaluation des résultats finaux.
L'article utilise également la recherche aléatoire pour le réglage des hyperparamètres. Il s'agit également de la norme de l'industrie, mais d'après mon expérience, la recherche bayésienne est mieux adaptée à la recherche dans un espace de recherche plus large.
En comprenant cela, nous pouvons approfondir notre question principale : pourquoi les méthodes basées sur les arbres surpassent l'apprentissage profond ?
1 Les réseaux de neurones ont tendance à être des solutions trop fluides
C'est l'auteur qui partage que les réseaux de neurones d'apprentissage profond ne peuvent pas rivaliser avec l'aléatoire. Première cause de concurrence forestière. En bref, les réseaux de neurones ont du mal à créer la meilleure adéquation lorsqu’il s’agit de fonctions/limites de décision non fluides. Les forêts aléatoires réussissent mieux dans des modèles étranges/irréguliers/irréguliers.

Si je devais deviner la raison, il se pourrait que les dégradés soient utilisés dans les réseaux de neurones et que les dégradés reposent sur des espaces de recherche différentiables, qui par définition sont lisses, de sorte que les points pointus et certaines fonctions aléatoires ne peuvent pas être distingués. Je recommande donc d'apprendre des concepts d'IA tels que les algorithmes évolutifs, la recherche traditionnelle et des concepts plus basiques, car ces concepts peuvent conduire à d'excellents résultats dans diverses situations où NN échoue.
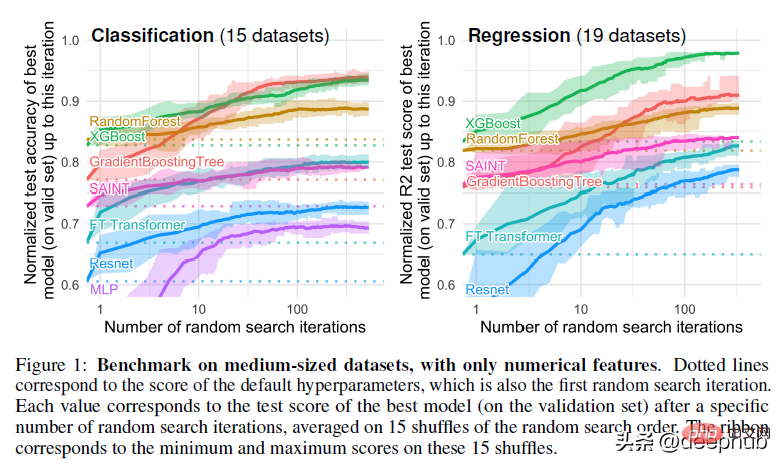
Pour un exemple plus concret de la différence dans les limites de décision entre les méthodes basées sur les arbres (RandomForests) et les apprenants profonds, jetez un œil à la figure ci-dessous -
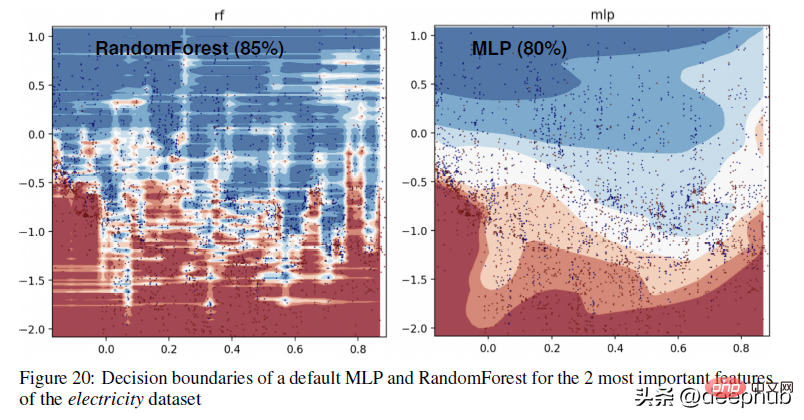
En annexe, l'auteur explique la visualisation ci-dessus ci-dessous :
Dans cette partie, nous pouvons voir que RandomForest est capable d'apprendre des motifs irréguliers sur l'axe des x (correspondant aux caractéristiques de date) que MLP ne peut pas apprendre. Nous montrons cette différence dans les hyperparamètres par défaut, qui est un comportement typique des réseaux de neurones, mais en pratique, il est difficile (mais pas impossible) de trouver des hyperparamètres qui apprennent avec succès ces modèles.
2. Les propriétés non informatives affecteront les réseaux neuronaux de type MLP
Un autre facteur important, en particulier pour les grands ensembles de données qui codent plusieurs relations simultanément. Si vous fournissez des fonctionnalités non pertinentes à un réseau de neurones, les résultats seront terribles (et vous gaspillerez plus de ressources pour entraîner votre modèle). C'est pourquoi il est si important de consacrer beaucoup de temps à l'exploration EDA/domaine. Cela aidera à comprendre les fonctionnalités et à garantir que tout se passe bien.
Les auteurs de l'article ont testé les performances du modèle lors de l'ajout de fonctionnalités aléatoires et de la suppression de fonctionnalités inutiles. Sur la base de leurs résultats, 2 résultats très intéressants ont été trouvés
La suppression d'un grand nombre de fonctionnalités réduit l'écart de performances entre les modèles. Cela montre clairement que l’un des avantages des modèles arborescents est leur capacité à juger si les fonctionnalités sont utiles et à éviter l’influence des fonctionnalités inutiles.
L'ajout de fonctionnalités aléatoires à l'ensemble de données montre que les réseaux de neurones se dégradent beaucoup plus gravement que les méthodes arborescentes. ResNet souffre particulièrement de ces propriétés inutiles. L'amélioration du transformateur peut être due au fait que le mécanisme d'attention qu'il contient sera utile dans une certaine mesure.
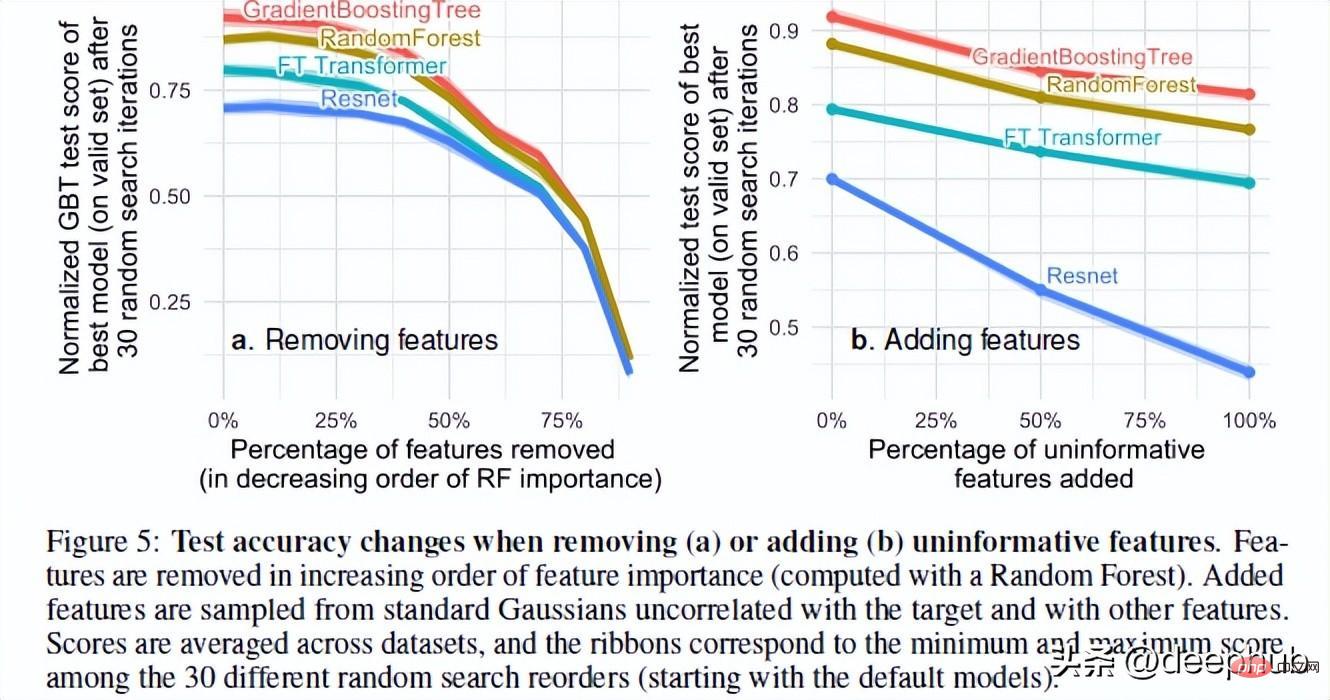
Une explication possible de ce phénomène est la façon dont les arbres de décision sont conçus. Quiconque a suivi un cours d'IA connaîtra les concepts de gain d'information et d'entropie dans les arbres de décision. Cela permet à l'arbre de décision de choisir le meilleur chemin en comparant les fonctionnalités restantes.
Retour au sujet, il y a une dernière chose qui rend RF plus performant que NN en ce qui concerne les données tabulaires. C'est l'invariance rotationnelle.
3. Les NN sont invariants par rotation, mais les données réelles ne le sont pas.
Les réseaux de neurones sont invariants par rotation. Cela signifie que si vous effectuez une opération de rotation sur vos ensembles de données, cela ne modifiera pas leurs performances. Après la rotation de l'ensemble de données, les performances et le classement des différents modèles ont considérablement changé. Bien que ResNets ait toujours été le pire, il a conservé ses performances d'origine après la rotation, tandis que tous les autres modèles ont considérablement changé.
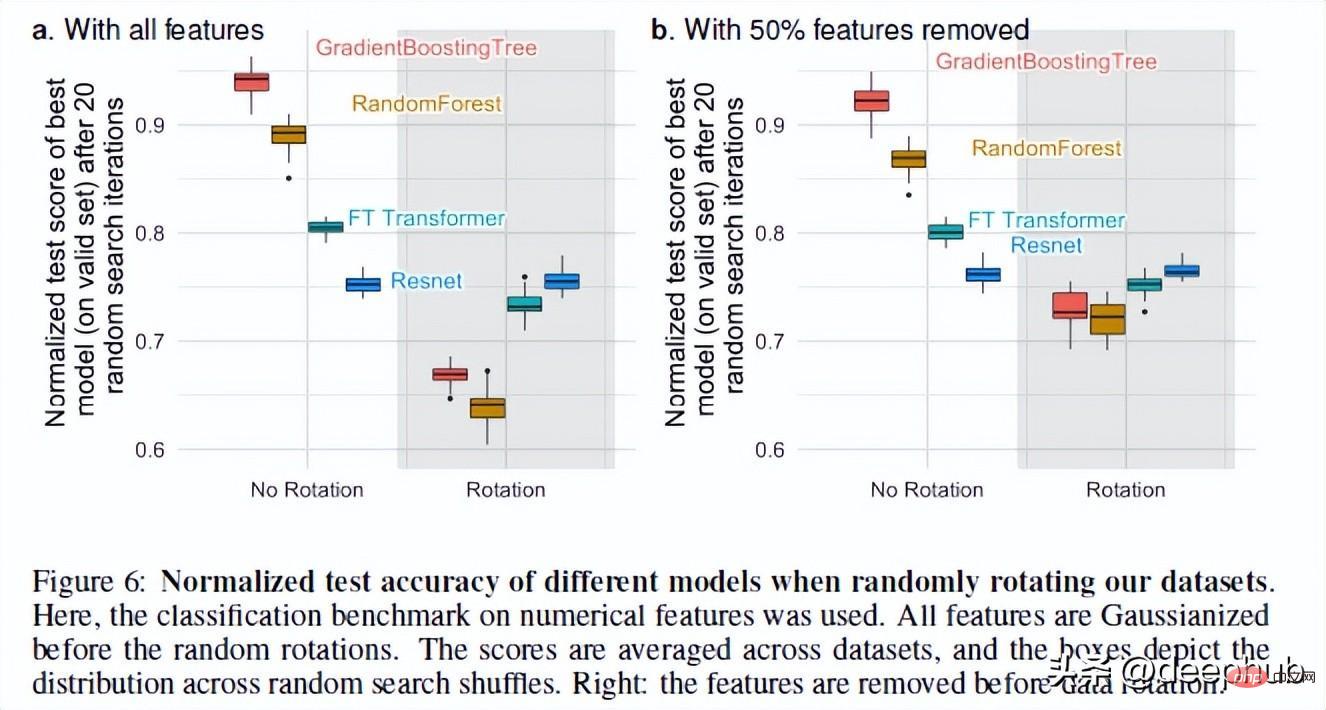
C'est un phénomène très intéressant : que signifie exactement la rotation d'un ensemble de données ? Il n'y a pas d'explications détaillées dans l'ensemble de l'article (j'ai contacté l'auteur et je suivrai ce phénomène). Si vous avez des idées, partagez-les également dans les commentaires.
Mais cette opération nous permet de voir pourquoi la variance de rotation est importante. Selon les auteurs, prendre des combinaisons linéaires de fonctionnalités (ce qui rend les ResNets invariants) peut en fait déformer les fonctionnalités et leurs relations.
L'obtention de biais de données optimaux en codant les données originales, qui peuvent mélanger des caractéristiques avec des propriétés statistiques très différentes et ne peuvent pas être récupérées par un modèle invariant par rotation, offrira de meilleures performances au modèle.
Résumé
C'est un article très intéressant Bien que l'apprentissage profond ait fait de grands progrès sur les ensembles de données texte et image, il n'a fondamentalement aucun avantage sur les données tabulaires. L'article utilise 45 ensembles de données provenant de différents domaines pour les tests, et les résultats montrent que même sans tenir compte de leur vitesse supérieure, les modèles arborescents restent à la pointe de la technologie sur des données modérées (~ 10 000 échantillons).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Méthodes et étapes d'utilisation de BERT pour l'analyse des sentiments en Python
Jan 22, 2024 pm 04:24 PM
Méthodes et étapes d'utilisation de BERT pour l'analyse des sentiments en Python
Jan 22, 2024 pm 04:24 PM
BERT est un modèle de langage d'apprentissage profond pré-entraîné proposé par Google en 2018. Le nom complet est BidirectionnelEncoderRepresentationsfromTransformers, qui est basé sur l'architecture Transformer et présente les caractéristiques d'un codage bidirectionnel. Par rapport aux modèles de codage unidirectionnels traditionnels, BERT peut prendre en compte les informations contextuelles en même temps lors du traitement du texte, de sorte qu'il fonctionne bien dans les tâches de traitement du langage naturel. Sa bidirectionnalité permet à BERT de mieux comprendre les relations sémantiques dans les phrases, améliorant ainsi la capacité expressive du modèle. Grâce à des méthodes de pré-formation et de réglage fin, BERT peut être utilisé pour diverses tâches de traitement du langage naturel, telles que l'analyse des sentiments, la dénomination
 YOLO est immortel ! YOLOv9 est sorti : performances et vitesse SOTA~
Feb 26, 2024 am 11:31 AM
YOLO est immortel ! YOLOv9 est sorti : performances et vitesse SOTA~
Feb 26, 2024 am 11:31 AM
Les méthodes d'apprentissage profond d'aujourd'hui se concentrent sur la conception de la fonction objectif la plus appropriée afin que les résultats de prédiction du modèle soient les plus proches de la situation réelle. Dans le même temps, une architecture adaptée doit être conçue pour obtenir suffisamment d’informations pour la prédiction. Les méthodes existantes ignorent le fait que lorsque les données d’entrée subissent une extraction de caractéristiques couche par couche et une transformation spatiale, une grande quantité d’informations sera perdue. Cet article abordera des problèmes importants lors de la transmission de données via des réseaux profonds, à savoir les goulots d'étranglement de l'information et les fonctions réversibles. Sur cette base, le concept d'information de gradient programmable (PGI) est proposé pour faire face aux différents changements requis par les réseaux profonds pour atteindre des objectifs multiples. PGI peut fournir des informations d'entrée complètes pour la tâche cible afin de calculer la fonction objectif, obtenant ainsi des informations de gradient fiables pour mettre à jour les pondérations du réseau. De plus, un nouveau cadre de réseau léger est conçu
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Intégration d'espace latent : explication et démonstration
Jan 22, 2024 pm 05:30 PM
Intégration d'espace latent : explication et démonstration
Jan 22, 2024 pm 05:30 PM
L'intégration d'espace latent (LatentSpaceEmbedding) est le processus de mappage de données de grande dimension vers un espace de faible dimension. Dans le domaine de l'apprentissage automatique et de l'apprentissage profond, l'intégration d'espace latent est généralement un modèle de réseau neuronal qui mappe les données d'entrée de grande dimension dans un ensemble de représentations vectorielles de basse dimension. Cet ensemble de vecteurs est souvent appelé « vecteurs latents » ou « latents ». encodages". Le but de l’intégration de l’espace latent est de capturer les caractéristiques importantes des données et de les représenter sous une forme plus concise et compréhensible. Grâce à l'intégration de l'espace latent, nous pouvons effectuer des opérations telles que la visualisation, la classification et le regroupement de données dans un espace de faible dimension pour mieux comprendre et utiliser les données. L'intégration d'espace latent a de nombreuses applications dans de nombreux domaines, tels que la génération d'images, l'extraction de caractéristiques, la réduction de dimensionnalité, etc. L'intégration de l'espace latent est le principal
 Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Dans la vague actuelle de changements technologiques rapides, l'intelligence artificielle (IA), l'apprentissage automatique (ML) et l'apprentissage profond (DL) sont comme des étoiles brillantes, à la tête de la nouvelle vague des technologies de l'information. Ces trois mots apparaissent fréquemment dans diverses discussions de pointe et applications pratiques, mais pour de nombreux explorateurs novices dans ce domaine, leurs significations spécifiques et leurs connexions internes peuvent encore être entourées de mystère. Alors regardons d'abord cette photo. On constate qu’il existe une corrélation étroite et une relation progressive entre l’apprentissage profond, l’apprentissage automatique et l’intelligence artificielle. Le deep learning est un domaine spécifique du machine learning, et le machine learning
 Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Près de 20 ans se sont écoulés depuis que le concept d'apprentissage profond a été proposé en 2006. L'apprentissage profond, en tant que révolution dans le domaine de l'intelligence artificielle, a donné naissance à de nombreux algorithmes influents. Alors, selon vous, quels sont les 10 meilleurs algorithmes pour l’apprentissage profond ? Voici les meilleurs algorithmes d’apprentissage profond, à mon avis. Ils occupent tous une position importante en termes d’innovation, de valeur d’application et d’influence. 1. Contexte du réseau neuronal profond (DNN) : Le réseau neuronal profond (DNN), également appelé perceptron multicouche, est l'algorithme d'apprentissage profond le plus courant lorsqu'il a été inventé pour la première fois, jusqu'à récemment en raison du goulot d'étranglement de la puissance de calcul. années, puissance de calcul, La percée est venue avec l'explosion des données. DNN est un modèle de réseau neuronal qui contient plusieurs couches cachées. Dans ce modèle, chaque couche transmet l'entrée à la couche suivante et
 1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
Adresse papier : https://arxiv.org/abs/2307.09283 Adresse code : https://github.com/THU-MIG/RepViTRepViT fonctionne bien dans l'architecture ViT mobile et présente des avantages significatifs. Ensuite, nous explorons les contributions de cette étude. Il est mentionné dans l'article que les ViT légers fonctionnent généralement mieux que les CNN légers sur les tâches visuelles, principalement en raison de leur module d'auto-attention multi-têtes (MSHA) qui permet au modèle d'apprendre des représentations globales. Cependant, les différences architecturales entre les ViT légers et les CNN légers n'ont pas été entièrement étudiées. Dans cette étude, les auteurs ont intégré des ViT légers dans le système efficace.
 Comment utiliser les modèles hybrides CNN et Transformer pour améliorer les performances
Jan 24, 2024 am 10:33 AM
Comment utiliser les modèles hybrides CNN et Transformer pour améliorer les performances
Jan 24, 2024 am 10:33 AM
Convolutional Neural Network (CNN) et Transformer sont deux modèles d'apprentissage en profondeur différents qui ont montré d'excellentes performances sur différentes tâches. CNN est principalement utilisé pour les tâches de vision par ordinateur telles que la classification d'images, la détection de cibles et la segmentation d'images. Il extrait les caractéristiques locales de l'image via des opérations de convolution et effectue une réduction de dimensionnalité des caractéristiques et une invariance spatiale via des opérations de pooling. En revanche, Transformer est principalement utilisé pour les tâches de traitement du langage naturel (NLP) telles que la traduction automatique, la classification de texte et la reconnaissance vocale. Il utilise un mécanisme d'auto-attention pour modéliser les dépendances dans des séquences, évitant ainsi le calcul séquentiel dans les réseaux neuronaux récurrents traditionnels. Bien que ces deux modèles soient utilisés pour des tâches différentes, ils présentent des similitudes dans la modélisation des séquences.
