
 Périphériques technologiques
IA
Ensembles de données et perception de conduite dans des conditions météorologiques répétitives et difficiles
Périphériques technologiques
IA
Ensembles de données et perception de conduite dans des conditions météorologiques répétitives et difficiles
Ensembles de données et perception de conduite dans des conditions météorologiques répétitives et difficiles

Article arXiv « Ithaca365 : Dataset and Driving Perception under Repeated and Challenging Weather Conditions », mis en ligne le 1er 22 août, travaux des universités de Cornell et de l'État de l'Ohio.

Ces dernières années, les capacités de perception des véhicules autonomes se sont améliorées grâce à l'utilisation d'ensembles de données à grande échelle, qui sont souvent collectées dans des endroits spécifiques et dans de bonnes conditions météorologiques. Cependant, afin de répondre à des exigences de sécurité élevées, ces systèmes de détection doivent fonctionner de manière robuste dans diverses conditions météorologiques, notamment la neige et la pluie.
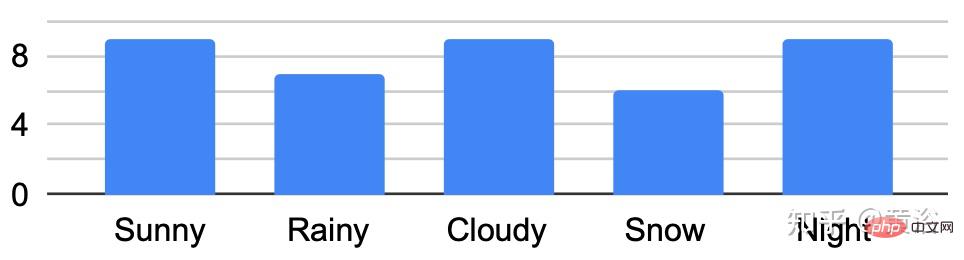
Cet article propose un ensemble de données pour parvenir à une conduite autonome robuste, en utilisant un nouveau processus de collecte de données, c'est-à-dire dans différents scénarios (ville, autoroute, zone rurale, campus), météo (neige, pluie, soleil), heure (jour /nuit) ) et les conditions de circulation (piétons, cyclistes et voitures), les données ont été enregistrées à plusieurs reprises tout au long d'un parcours de 15 km.
Cet ensemble de données comprend des images et des nuages de points provenant de caméras et de capteurs lidar, ainsi que des GPS/INS de haute précision pour établir une correspondance entre les itinéraires. L'ensemble de données comprend des annotations de routes et d'objets, des occlusions locales et des cadres de délimitation 3D capturés avec des masques amodaux.
Les chemins répétés ouvrent de nouvelles directions de recherche pour la découverte de cibles, l'apprentissage continu et la détection d'anomalies.
Lien Ithaca365 : Un nouvel ensemble de données pour permettre une conduite autonome robuste via un nouveau processus de collecte de données
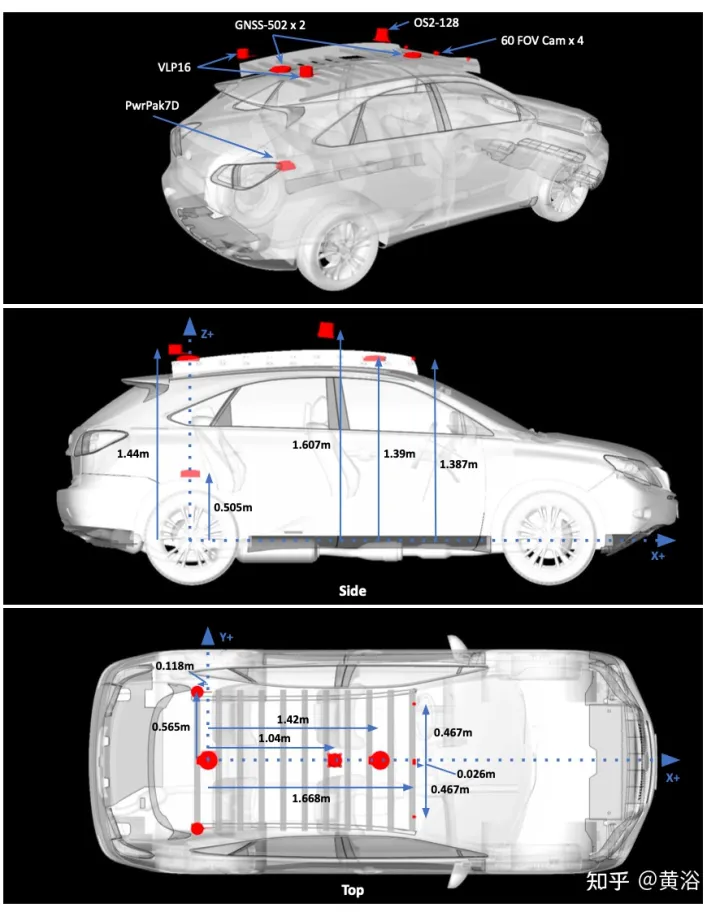
L'image est la configuration du capteur pour la collecte de données :
L'image a montre la feuille de route avec des captures à plusieurs endroits. Les déplacements étaient programmés pour collecter des données à différents moments de la journée, y compris la nuit. Enregistrez les fortes chutes de neige avant et après le déneigement de la route.
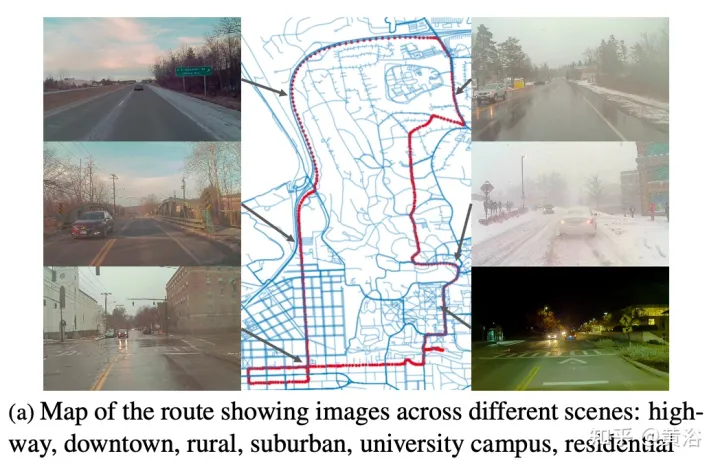
Une caractéristique clé de l'ensemble de données est que les mêmes emplacements peuvent être observés dans des conditions différentes ; un exemple est présenté dans la figure b.

La figure montre l'analyse transversale dans différentes conditions :
Développer un outil de marquage personnalisé pour obtenir des masques non modaux de routes et de cibles. Pour les étiquettes de route soumises à des conditions environnementales différentes, telles que des routes enneigées, utilisez des parcours répétés du même itinéraire. Plus précisément, la carte routière en nuage de points construite à partir des données d'attitude GPS et lidar convertit l'étiquette routière de « beau temps » en « mauvais temps ».
Les itinéraires/données sont divisés en 76 intervalles. Projetez le nuage de points dans BEV et étiquetez la route à l'aide de l'annotateur de polygone. Une fois la route marquée en BEV (générant une limite de route 2D), le polygone est décomposé en polygones plus petits de 150 m^2, en utilisant un seuil de 1,5 m de hauteur moyenne, et un ajustement plan est effectué sur les points du polygone. limite pour déterminer la hauteur de la route.
Ajustez un plan à ces points avec RANSAC et un régresseur ; puis calculez la hauteur de chaque point le long de la frontière en utilisant le plan de sol estimé. Projetez les points de la route dans l'image et créez un masque de profondeur pour obtenir l'étiquette non modale de la route. Faire correspondre les emplacements aux cartes marquées avec le GPS et optimiser les itinéraires avec ICP permet de projeter le plan de sol vers des emplacements spécifiques sur de nouveaux itinéraires de collecte.
Une vérification finale de la solution ICP en vérifiant que le masque de vérité terrain moyen projeté de l'étiquette routière est conforme à 80 % de mIOU avec tous les autres masques de vérité terrain au même endroit, sinon les données de localisation de la requête ne sont pas récupérées ;
Les cibles amodales sont étiquetées avec Scale AI pour six catégories de cibles de premier plan : voitures, bus, camions (y compris les marchandises, les camions de pompiers, les camionnettes, les ambulances), les piétons, les cyclistes et les motocyclistes.
Ce paradigme d'étiquetage comporte trois éléments principaux : d'abord identifier les instances visibles d'un objet, puis déduire des masques de segmentation d'instances occluses, et enfin étiqueter l'ordre d'occlusion de chaque objet. Le marquage est effectué sur la vue de la caméra avant la plus à gauche. Suit les mêmes normes que KINS ("Segmentation d'instance modale avec ensemble de données kins". CVPR, 2019).
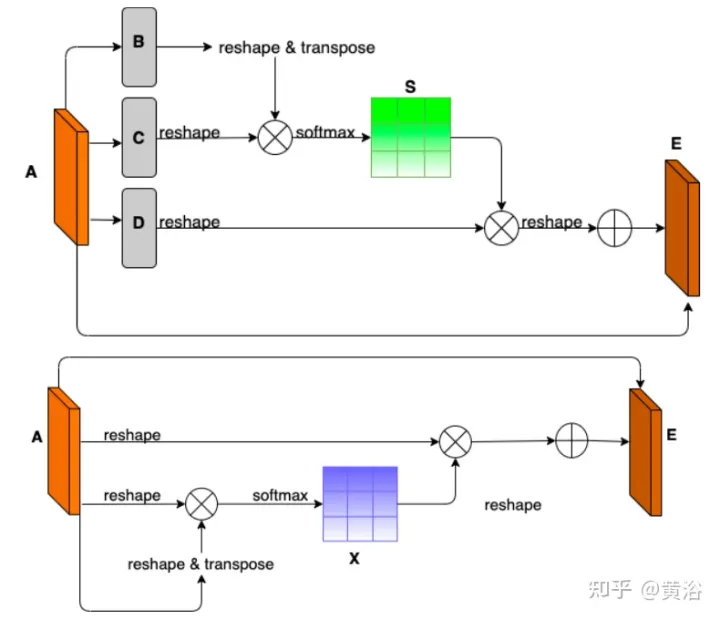
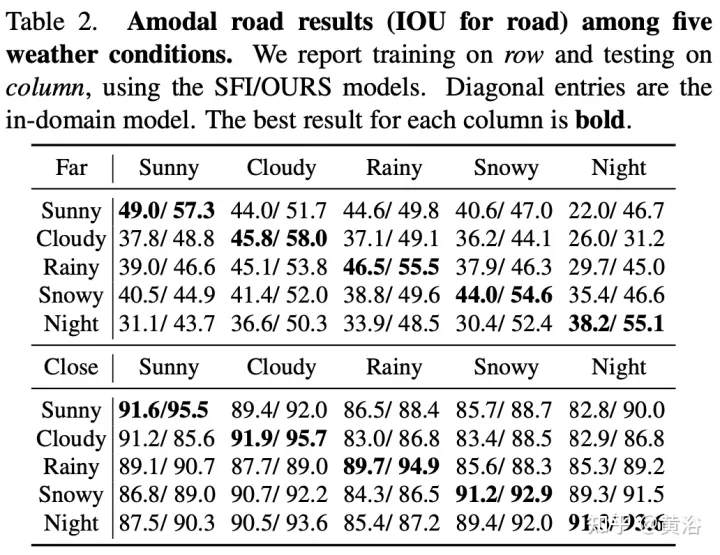
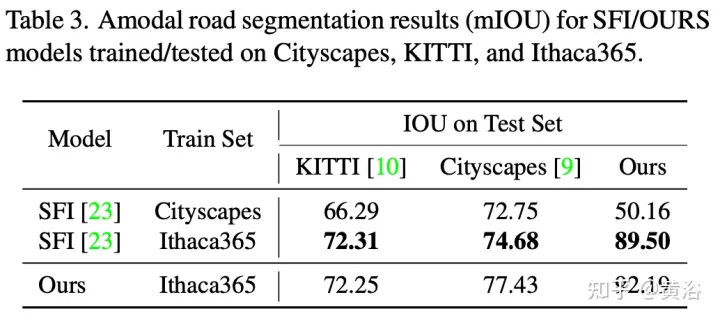
Pour démontrer la diversité environnementale et la qualité amodale de l'ensemble de données, deux réseaux de référence ont été formés et testés pour identifier les routes amodales au niveau du pixel, fonctionnant même lorsque les routes sont couvertes de neige ou de voitures. Le premier réseau de base est le Semantic Foreground Inpainting (SFI). La deuxième référence, comme le montre la figure, utilise les trois innovations suivantes pour améliorer SFI.
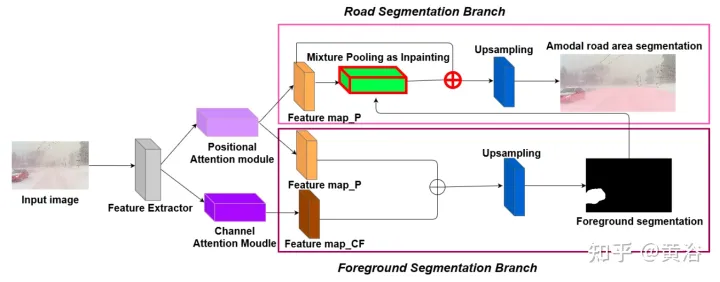
- Remarque sur la position et le canal : étant donné que la segmentation amodale déduit principalement ce qui est invisible, le contexte est un indice très important. DAN (« Dual attention network for scene segmentation », CVPR’2019) introduit deux innovations pour capturer deux arrière-plans différents. Le module d'attention de position (PAM) utilise les fonctionnalités des pixels pour se concentrer sur d'autres pixels de l'image, capturant ainsi le contexte d'autres parties de l'image. Le Channel Attention Module (CAM) utilise un mécanisme d'attention similaire pour regrouper efficacement les informations sur les canaux. Ici, ces deux modules sont appliqués sur l'extracteur de fonctionnalités du backbone. Combinaison de CAM et PAM pour une meilleure localisation des limites fines des masques. Le masque d'instance final de premier plan est obtenu grâce à une couche de suréchantillonnage.
- Regroupement hybride comme inpainting : le pooling maximum est utilisé comme opération d'inpainting pour remplacer les éléments de premier plan qui se chevauchent par des éléments d'arrière-plan à proximité afin de faciliter la restauration des éléments routiers non modaux. Cependant, comme les fonctionnalités d’arrière-plan sont généralement réparties de manière fluide, l’opération de pooling maximal est très sensible à tout bruit ajouté. En revanche, les opérations de mutualisation moyennes atténuent naturellement le bruit. À cette fin, le pooling moyen et le pooling maximum sont combinés pour l’application de correctifs, appelé Mixture Pooling.
- Opération Somme : avant la dernière couche de suréchantillonnage, les fonctionnalités du module de pooling hybride ne sont pas transmises directement, mais les liens résiduels de la sortie du module PAM sont inclus. En optimisant conjointement deux cartes de caractéristiques dans la branche de segmentation routière, le module PAM peut également apprendre les caractéristiques d'arrière-plan des zones occultées. Cela peut conduire à une récupération plus précise des fonctionnalités en arrière-plan.
L'image montre le schéma d'architecture de PAM et CAM :
Le pseudo-code de l'algorithme pour le patching par pooling hybride est le suivant :

Le code de formation et de test pour la segmentation routière non modale est le suivant suit : https://github.com/coolgrasshopper/amodal_road_segmentation
Les résultats expérimentaux sont les suivants :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Smart App Control sur Windows 11 : comment l'activer ou le désactiver
Jun 06, 2023 pm 11:10 PM
Smart App Control sur Windows 11 : comment l'activer ou le désactiver
Jun 06, 2023 pm 11:10 PM
Intelligent App Control est un outil très utile dans Windows 11 qui aide à protéger votre PC contre les applications non autorisées qui peuvent endommager vos données, telles que les ransomwares ou les logiciels espions. Cet article explique ce qu'est Smart App Control, comment il fonctionne et comment l'activer ou le désactiver dans Windows 11. Qu’est-ce que Smart App Control dans Windows 11 ? Smart App Control (SAC) est une nouvelle fonctionnalité de sécurité introduite dans la mise à jour Windows 1122H2. Il fonctionne avec Microsoft Defender ou un logiciel antivirus tiers pour bloquer les applications potentiellement inutiles susceptibles de ralentir votre appareil, d'afficher des publicités inattendues ou d'effectuer d'autres actions inattendues. Application intelligente
 Les traits du visage volent, ouvrent la bouche, regardent fixement et lèvent les sourcils. L'IA peut les imiter parfaitement, ce qui rend impossible la prévention des escroqueries vidéo.
Dec 14, 2023 pm 11:30 PM
Les traits du visage volent, ouvrent la bouche, regardent fixement et lèvent les sourcils. L'IA peut les imiter parfaitement, ce qui rend impossible la prévention des escroqueries vidéo.
Dec 14, 2023 pm 11:30 PM
Avec une capacité d'imitation de l'IA aussi puissante, il est vraiment impossible de l'empêcher. Le développement de l’IA a-t-il atteint ce niveau aujourd’hui ? Votre pied avant fait voler les traits de votre visage, et sur votre pied arrière, la même expression est reproduite. Regarder fixement, lever les sourcils, faire la moue, aussi exagérée que soit l'expression, tout est parfaitement imité. Augmentez la difficulté, haussez les sourcils, ouvrez plus grand les yeux, et même la forme de la bouche est tordue, et l'avatar du personnage virtuel peut parfaitement reproduire l'expression. Lorsque vous ajustez les paramètres à gauche, l'avatar virtuel à droite modifiera également ses mouvements en conséquence pour donner un gros plan de la bouche et des yeux. On ne peut pas dire que l'imitation soit exactement la même, seule l'expression est exactement la même. idem (extrême droite). La recherche provient d'institutions telles que l'Université technique de Munich, qui propose GaussianAvatars, qui
 MotionLM : technologie de modélisation de langage pour la prédiction de mouvement multi-agents
Oct 13, 2023 pm 12:09 PM
MotionLM : technologie de modélisation de langage pour la prédiction de mouvement multi-agents
Oct 13, 2023 pm 12:09 PM
Cet article est reproduit avec la permission du compte public Autonomous Driving Heart. Veuillez contacter la source pour la réimpression. Titre original : MotionLM : Multi-Agent Motion Forecasting as Language Modeling Lien vers l'article : https://arxiv.org/pdf/2309.16534.pdf Affiliation de l'auteur : Conférence Waymo : ICCV2023 Idée d'article : Pour la planification de la sécurité des véhicules autonomes, prédisez de manière fiable le comportement futur des agents routiers est cruciale. Cette étude représente les trajectoires continues sous forme de séquences de jetons de mouvement discrets et traite la prédiction de mouvement multi-agents comme une tâche de modélisation du langage. Le modèle que nous proposons, MotionLM, présente les avantages suivants :
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Savez-vous que les programmeurs seront en déclin dans quelques années ?
Nov 08, 2023 am 11:17 AM
Savez-vous que les programmeurs seront en déclin dans quelques années ?
Nov 08, 2023 am 11:17 AM
Le magazine "ComputerWorld" a écrit un article disant que "la programmation disparaîtra d'ici 1960" parce qu'IBM a développé un nouveau langage FORTRAN, qui permet aux ingénieurs d'écrire les formules mathématiques dont ils ont besoin, puis de les soumettre à l'ordinateur pour que la programmation se termine. Picture Quelques années plus tard, nous avons entendu un nouveau dicton : tout homme d'affaires peut utiliser des termes commerciaux pour décrire ses problèmes et dire à l'ordinateur quoi faire. Grâce à ce langage de programmation appelé COBOL, les entreprises n'ont plus besoin de programmeurs. Plus tard, il est dit qu'IBM a développé un nouveau langage de programmation appelé RPG qui permet aux employés de remplir des formulaires et de générer des rapports, de sorte que la plupart des besoins de programmation de l'entreprise puissent être satisfaits grâce à lui.
 Implémentation d'OpenAI CLIP sur des ensembles de données personnalisés
Sep 14, 2023 am 11:57 AM
Implémentation d'OpenAI CLIP sur des ensembles de données personnalisés
Sep 14, 2023 am 11:57 AM
En janvier 2021, OpenAI a annoncé deux nouveaux modèles : DALL-E et CLIP. Les deux modèles sont des modèles multimodaux qui relient le texte et les images d’une manière ou d’une autre. Le nom complet de CLIP est Contrastive Language-Image Pre-training (ContrastiveLanguage-ImagePre-training), qui est une méthode de pré-formation basée sur des paires texte-image contrastées. Pourquoi introduire CLIP ? Parce que le StableDiffusion actuellement populaire n'est pas un modèle unique, mais se compose de plusieurs modèles. L'un des composants clés est l'encodeur de texte, qui est utilisé pour encoder la saisie de texte de l'utilisateur. Cet encodeur de texte est l'encodeur de texte CL dans le modèle CLIP.
 Le robot humanoïde universel intelligent GR-1 Fourier est sur le point de commencer la prévente !
Sep 27, 2023 pm 08:41 PM
Le robot humanoïde universel intelligent GR-1 Fourier est sur le point de commencer la prévente !
Sep 27, 2023 pm 08:41 PM
Le robot humanoïde, qui mesure 1,65 mètre, pèse 55 kilogrammes et possède 44 degrés de liberté dans son corps, peut marcher rapidement, éviter les obstacles rapidement, monter et descendre régulièrement les pentes et résister aux chocs et aux interférences. Vous pouvez désormais le ramener chez vous. ! Le robot humanoïde universel GR-1 de Fourier Intelligence a commencé la prévente. Salle de conférence Robot Le robot humanoïde universel Fourier GR-1 de Fourier Intelligence est maintenant ouvert à la prévente. GR-1 a une configuration de tronc hautement bionique et un contrôle de mouvement anthropomorphique. Il a 44 degrés de liberté dans tout le corps. Il a la capacité de marcher, d'éviter les obstacles, de franchir des obstacles, de monter et de descendre des pentes, de résister aux interférences et de s'adapter. à différentes surfaces routières. C'est un système d'intelligence artificielle général. Page de prévente du site officiel : www.fftai.cn/order#FourierGR-1# Fourier Intelligence doit être réécrit.
 Quelles sont les méthodes efficaces et les méthodes de base communes pour la prédiction de trajectoires piétonnes ? Partage des meilleurs articles de conférence !
Oct 17, 2023 am 11:13 AM
Quelles sont les méthodes efficaces et les méthodes de base communes pour la prédiction de trajectoires piétonnes ? Partage des meilleurs articles de conférence !
Oct 17, 2023 am 11:13 AM
La prédiction de trajectoire a pris de l'ampleur au cours des deux dernières années, mais l'essentiel se concentre sur la direction de la prédiction de trajectoire des véhicules. Aujourd'hui, Autonomous Driving Heart partagera avec vous l'algorithme de prédiction de trajectoire des piétons sur NeurIPS - SHENet. les schémas de déplacement sont généralement, dans une certaine mesure, conformes à des règles limitées. Sur la base de cette hypothèse, SHENet prédit la trajectoire future d'une personne en apprenant des règles de scène implicites. L'article a été autorisé comme original par Autonomous Driving Heart ! La compréhension personnelle de l'auteur est qu'à l'heure actuelle, prédire la trajectoire future d'une personne reste un problème difficile en raison du caractère aléatoire et subjectif du mouvement humain. Cependant, les schémas de mouvement humain dans les scènes contraintes varient souvent en raison des contraintes de la scène (telles que les plans d'étage, les routes et les obstacles) et de l'interactivité d'humain à humain ou d'humain à objet.
