
 Périphériques technologiques
IA
Utiliser l'apprentissage automatique pour reconstruire des visages dans des vidéos
Périphériques technologiques
IA
Utiliser l'apprentissage automatique pour reconstruire des visages dans des vidéos
Utiliser l'apprentissage automatique pour reconstruire des visages dans des vidéos

Traducteur | Cui Hao
Critique | Sun Shujuan
Ouverture
Une recherche collaborative en Chine et au Royaume-Uni a mis au point une nouvelle méthode pour remodeler les visages dans les vidéos. Cette technologie peut agrandir et réduire la structure du visage avec une grande cohérence et sans aucune trace de coupe artificielle.
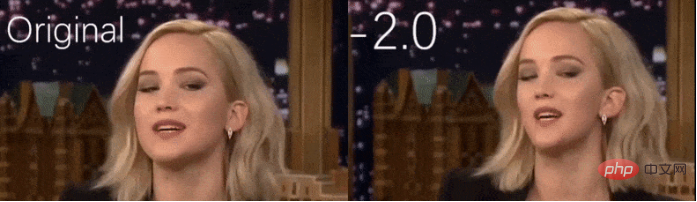
En général, cette transformation de la structure du visage est obtenue grâce à des méthodes CGI traditionnelles, qui reposent sur des procédures détaillées et coûteuses de capping de mouvement, de gréage et de texturation pour reconstruire complètement le visage.
Différent des méthodes traditionnelles, le CGI de la nouvelle technologie est intégré dans le pipeline neuronal en tant que paramètre pour les informations faciales 3D et sert de base au flux de travail d'apprentissage automatique.
L'auteur souligne :
« Notre objectif est d'utiliser des visages naturels du monde réel comme base pour déformer et modifier les contours de leur visage afin de générer des vidéos de reconstruction de portrait de haute qualité [résultats]. utilisé pour les applications d'effets visuels telles que l'embellissement du visage et l'exagération du visage
Bien que les techniques de distorsion faciale 2D soient disponibles pour les consommateurs depuis l'avènement de Photoshop (et ont donné naissance à une sous-culture de distorsions faciales et de dysmorphie corporelle pour la vidéo sans utilisation). CGI est encore une technologie difficile

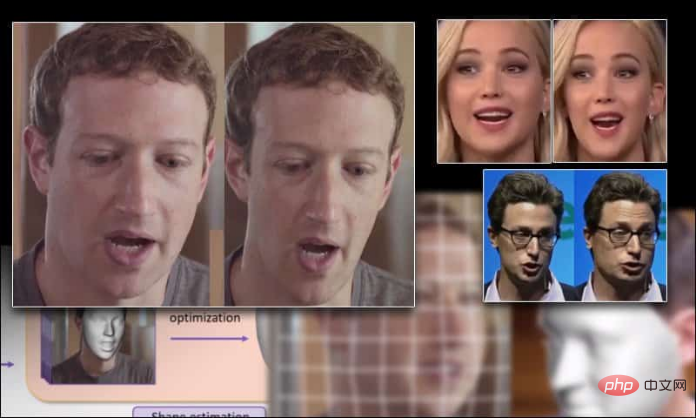
La taille du visage de Mark Zuckerberg s'est agrandie et réduite en raison des nouvelles technologies
Actuellement, le remodelage du corps est un sujet brûlant dans le domaine de la vision, principalement en raison de son potentiel dans la mode. le commerce électronique, comme faire paraître les gens plus grands et avec une ossature plus diversifiée, mais il reste encore quelques défis
Encore une fois, de manière convaincante, changer la forme des visages dans la vidéo a été au cœur du travail des chercheurs, bien que. la mise en œuvre de la technologie a été entravée par le traitement humain et d'autres limitations. Le nouveau produit migre ainsi les capacités précédemment étudiées des extensions statiques vers la sortie vidéo dynamique.
Le nouveau système est formé sur un ordinateur de bureau équipé d'AMD Ryzen 9 3950X et de 32 Go de mémoire. , et utilise l'algorithme de flux optique d'OpenCV pour générer des cartes de mouvement et les lisser via le framework StructureFlow (FAN) pour le composant d'estimation des caractéristiques, également utilisé dans le package de composants deepfakes populaire travaillant avec Ceres Solver pour résoudre les problèmes d'optimisation du visage
; 
Exemple d'utilisation du nouveau système pour agrandir les visages
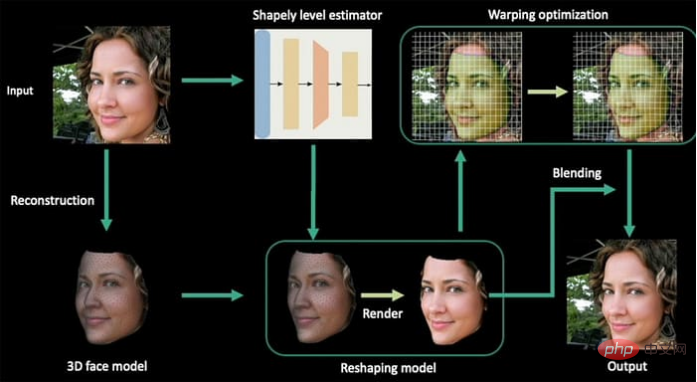
Le titre de cet article est Remodelage paramétrique des portraits dans les vidéos, et son auteur est trois chercheurs de l'Université du Zhejiang et un de l'Université de Bath. Dans le nouveau système, les vidéos sont extraites en séquences d'images, en construisant d'abord un modèle de base pour le visage, puis en concaténant les images suivantes représentatives, construisant ainsi des paramètres de personnalité cohérents dans toute la direction de l'image (c'est-à-dire la direction de l'image vidéo).
Processus architectural du système de déformation du visage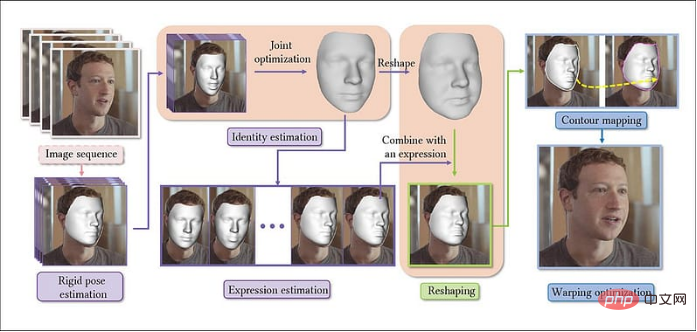 Ensuite, selon l'expression de calcul, les paramètres de mise en forme mis en œuvre par régression linéaire sont générés. Ensuite, une cartographie 2D des contours du visage est construite grâce à la fonction de distance signée (SDF. ) avant et après le remodelage du visage. Enfin, la vidéo de sortie est soumise à une optimisation de la déformation pour la reconnaissance du contenu.
Ensuite, selon l'expression de calcul, les paramètres de mise en forme mis en œuvre par régression linéaire sont générés. Ensuite, une cartographie 2D des contours du visage est construite grâce à la fonction de distance signée (SDF. ) avant et après le remodelage du visage. Enfin, la vidéo de sortie est soumise à une optimisation de la déformation pour la reconnaissance du contenu.
Ce processus utilise le modèle de visage 3D morphable (3DMM) est un outil auxiliaire de synthèse de visage neuronal et basé sur GAN qui convient également. systèmes de détection de deepfake
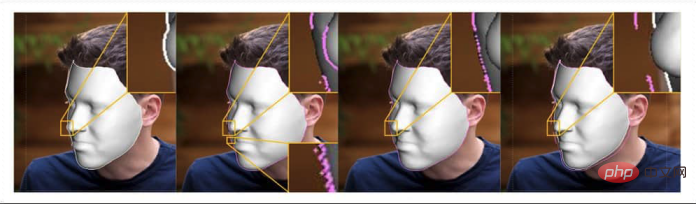
Exemples du modèle de visage morphable 3D (3DMM) — — Surfaces prototypes paramétriques utilisées dans de nouveaux projets. En haut à gauche, application iconique sur surface 3DMM. En haut à droite, sommets du maillage 3D de l'isomap. Le coin inférieur gauche montre l'ajustement des caractéristiques ; l'image inférieure du milieu, l'isomap de la texture du visage extraite et le coin inférieur droit, l'ajustement et la forme finaux;
Le flux de travail du nouveau système prendra en compte les situations d'occlusion, par exemple lorsqu'un objet s'éloigne de la vue. C’est également l’un des plus grands défis des logiciels deepfake, car les repères FAN peuvent à peine rendre compte de ces situations et leur qualité de traduction a tendance à se dégrader à mesure que les visages sont évités ou masqués.
Le nouveau système évite les problèmes ci-dessus en définissant une « énergie de contour » qui correspond aux limites des faces 3D (3DMM) et des faces 2D (définies par les repères FAN).
Optimisation
Le scénario d'application de ce système est la déformation en temps réel, telle que les changements de forme du visage en temps réel dans les filtres des chats vidéo. Actuellement, les frameworks ne peuvent pas y parvenir, donc fournir les ressources informatiques nécessaires pour permettre une déformation « en temps réel » devient un défi important.
Selon l'hypothèse de l'article, la latence de chaque opération d'image d'une vidéo à 24 ips dans le pipeline par rapport au matériau par seconde est de 16,344 secondes. Dans le même temps, pour l'estimation des caractéristiques et la déformation faciale 3D, elle est également accompagnée de. un coup (321 millisecondes et 160 millisecondes respectivement) milliseconde).
En conséquence, l’optimisation a réalisé des progrès clés dans la réduction de la latence. Étant donné qu'une optimisation conjointe sur toutes les trames augmenterait considérablement la surcharge du système et que l'optimisation du style d'initialisation (en supposant des caractéristiques de locuteur cohérentes dans l'ensemble) pourrait conduire à des anomalies, les auteurs ont adopté un mode clairsemé pour calculer les coefficients à des intervalles réalistes des trames échantillonnées.
Ensuite, une optimisation conjointe est effectuée sur ce sous-ensemble de cadres, ce qui entraîne un processus de reconstruction plus simple.
Surfaces faciales
La technologie de morphing utilisée dans ce projet est une adaptation de l'ouvrage de l'auteur de 2020 Deep Shapely Portraits (DSP).
Deep Shapely Portraits, soumission 2020 à ACM Multimedia. L'article a été dirigé par des chercheurs du laboratoire commun Tencent et Game and Intelligent Graphics Innovation Technology de l'Université du Zhejiang. Les auteurs ont observé que « nous avons étendu cette méthode du remodelage d'une seule image au remodelage d'une séquence d'images entière
Test
Le. Le document note qu’il n’existe pas de données historiques comparables pour évaluer la nouvelle approche. Par conséquent, les auteurs ont comparé leurs images de sortie vidéo incurvées avec une sortie DSP statique.
 Test du nouveau système contre des images statiques de Deep Shapely Portraits
Test du nouveau système contre des images statiques de Deep Shapely Portraits
Les auteurs soulignent que la méthode DSP souffre d'artefacts dus à l'utilisation d'un mappage clairsemé - le nouveau framework résout ce problème grâce à un mappage dense. En outre, l'article affirme que les vidéos produites par DSP manquent de fluidité et de cohérence visuelle.
L'auteur souligne :
« Les résultats montrent que notre méthode peut générer de manière stable et cohérente des vidéos de portraits remodelées, tandis que les méthodes basées sur l'image peuvent facilement conduire à des artefacts de scintillement évidents (traces de modifications artificielles). »
Introduction de l'auteur traduit
Cui Hao, rédacteur de la communauté 51CTO, architecte senior, a 18 ans d'expérience en développement logiciel et en architecture, et 10 ans d'expérience en architecture distribuée. Anciennement expert technique chez HP. Il est prêt à partager et a écrit de nombreux articles techniques populaires avec plus de 600 000 lectures. Auteur de "Principes et pratique de l'architecture distribuée".
Titre original :Restructuring Faces in Videos With Machine Learning, auteur : Martin Anderson
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Dans les domaines de l’apprentissage automatique et de la science des données, l’interprétabilité des modèles a toujours été au centre des préoccupations des chercheurs et des praticiens. Avec l'application généralisée de modèles complexes tels que l'apprentissage profond et les méthodes d'ensemble, la compréhension du processus décisionnel du modèle est devenue particulièrement importante. Explainable AI|XAI contribue à renforcer la confiance dans les modèles d'apprentissage automatique en augmentant la transparence du modèle. L'amélioration de la transparence des modèles peut être obtenue grâce à des méthodes telles que l'utilisation généralisée de plusieurs modèles complexes, ainsi que les processus décisionnels utilisés pour expliquer les modèles. Ces méthodes incluent l'analyse de l'importance des caractéristiques, l'estimation de l'intervalle de prédiction du modèle, les algorithmes d'interprétabilité locale, etc. L'analyse de l'importance des fonctionnalités peut expliquer le processus de prise de décision du modèle en évaluant le degré d'influence du modèle sur les fonctionnalités d'entrée. Estimation de l’intervalle de prédiction du modèle
 Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
En termes simples, un modèle d’apprentissage automatique est une fonction mathématique qui mappe les données d’entrée à une sortie prédite. Plus précisément, un modèle d'apprentissage automatique est une fonction mathématique qui ajuste les paramètres du modèle en apprenant à partir des données d'entraînement afin de minimiser l'erreur entre la sortie prédite et la véritable étiquette. Il existe de nombreux modèles dans l'apprentissage automatique, tels que les modèles de régression logistique, les modèles d'arbre de décision, les modèles de machines à vecteurs de support, etc. Chaque modèle a ses types de données et ses types de problèmes applicables. Dans le même temps, il existe de nombreux points communs entre les différents modèles, ou il existe une voie cachée pour l’évolution du modèle. En prenant comme exemple le perceptron connexionniste, en augmentant le nombre de couches cachées du perceptron, nous pouvons le transformer en un réseau neuronal profond. Si une fonction noyau est ajoutée au perceptron, elle peut être convertie en SVM. celui-ci
 Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Cet article présentera comment identifier efficacement le surajustement et le sous-apprentissage dans les modèles d'apprentissage automatique grâce à des courbes d'apprentissage. Sous-ajustement et surajustement 1. Surajustement Si un modèle est surentraîné sur les données de sorte qu'il en tire du bruit, alors on dit que le modèle est en surajustement. Un modèle surajusté apprend chaque exemple si parfaitement qu'il classera mal un exemple inédit/inédit. Pour un modèle surajusté, nous obtiendrons un score d'ensemble d'entraînement parfait/presque parfait et un score d'ensemble/test de validation épouvantable. Légèrement modifié : "Cause du surajustement : utilisez un modèle complexe pour résoudre un problème simple et extraire le bruit des données. Parce qu'un petit ensemble de données en tant qu'ensemble d'entraînement peut ne pas représenter la représentation correcte de toutes les données."
 L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
Dans les années 1950, l’intelligence artificielle (IA) est née. C’est à ce moment-là que les chercheurs ont découvert que les machines pouvaient effectuer des tâches similaires à celles des humains, comme penser. Plus tard, dans les années 1960, le Département américain de la Défense a financé l’intelligence artificielle et créé des laboratoires pour poursuivre son développement. Les chercheurs trouvent des applications à l’intelligence artificielle dans de nombreux domaines, comme l’exploration spatiale et la survie dans des environnements extrêmes. L'exploration spatiale est l'étude de l'univers, qui couvre l'ensemble de l'univers au-delà de la terre. L’espace est classé comme environnement extrême car ses conditions sont différentes de celles de la Terre. Pour survivre dans l’espace, de nombreux facteurs doivent être pris en compte et des précautions doivent être prises. Les scientifiques et les chercheurs pensent qu'explorer l'espace et comprendre l'état actuel de tout peut aider à comprendre le fonctionnement de l'univers et à se préparer à d'éventuelles crises environnementales.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
MetaFAIR s'est associé à Harvard pour fournir un nouveau cadre de recherche permettant d'optimiser le biais de données généré lors de l'apprentissage automatique à grande échelle. On sait que la formation de grands modèles de langage prend souvent des mois et utilise des centaines, voire des milliers de GPU. En prenant comme exemple le modèle LLaMA270B, sa formation nécessite un total de 1 720 320 heures GPU. La formation de grands modèles présente des défis systémiques uniques en raison de l’ampleur et de la complexité de ces charges de travail. Récemment, de nombreuses institutions ont signalé une instabilité dans le processus de formation lors de la formation des modèles d'IA générative SOTA. Elles apparaissent généralement sous la forme de pics de pertes. Par exemple, le modèle PaLM de Google a connu jusqu'à 20 pics de pertes au cours du processus de formation. Le biais numérique est à l'origine de cette imprécision de la formation,
