
 Périphériques technologiques
IA
ViP3D : prédiction visuelle de trajectoire de bout en bout via une requête d'agent 3D
Périphériques technologiques
IA
ViP3D : prédiction visuelle de trajectoire de bout en bout via une requête d'agent 3D
ViP3D : prédiction visuelle de trajectoire de bout en bout via une requête d'agent 3D

Article arXiv "ViP3D : End-to-end Visual Trajectory Prediction via 3D Agent Queries", mis en ligne le 2 août 22, produit conjointement par l'Université Tsinghua, Shanghai (Yao) Qizhi Research Institute, CMU, Fudan, Li Auto et MIT, etc. Travail.

Le pipeline de conduite autonome existant sépare le module de perception du module de prédiction. Les deux modules communiquent via des fonctionnalités sélectionnées manuellement telles que des boîtes d'agents et des trajectoires comme interfaces. Du fait de cette séparation, le module de prédiction ne reçoit que des informations partielles du module de perception. Pire encore, les erreurs du module de perception peuvent se propager et s'accumuler, affectant négativement les résultats de prédiction.
Ce travail propose ViP3D, un pipeline de prédiction de trajectoire visuelle qui utilise les riches informations de la vidéo originale pour prédire la trajectoire future de l'agent dans la scène. ViP3D utilise une requête d'agent clairsemée tout au long du pipeline, ce qui la rend entièrement différenciable et interprétable. De plus, un nouvel indice d'évaluation pour la tâche de prédiction de trajectoire visuelle de bout en bout est proposé, End-to-end Prediction Accuracy (EPA, End-to-end Prediction Accuracy), qui prend en compte de manière globale la précision de la perception et de la prédiction. tout en améliorant la précision des prédictions, les trajectoires sont évaluées par rapport aux trajectoires de vérité terrain.
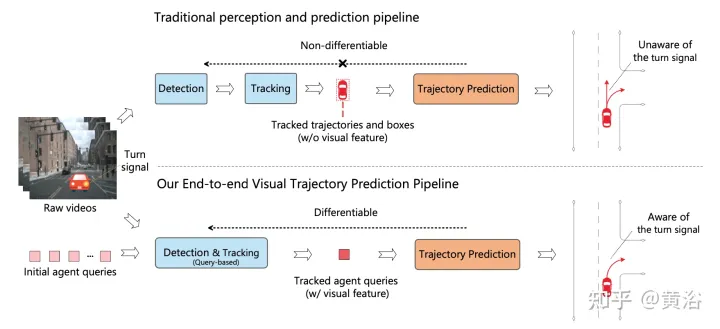
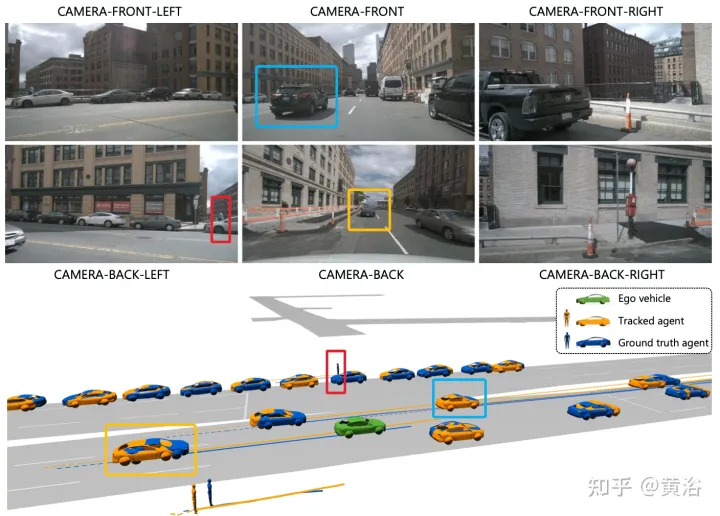
L'image montre la comparaison entre le pipeline en cascade multi-étapes traditionnel et ViP3D : le pipeline traditionnel implique plusieurs modules non différenciables, tels que la détection, le suivi et la prédiction. ViP3D prend la vidéo multi-vues en entrée et génère des trajectoires prédites dans un de bout en bout. Utilisation efficace des informations visuelles, telles que les clignotants des véhicules.
ViP3D vise à résoudre le problème de prédiction de trajectoire des vidéos originales de bout en bout. Plus précisément, grâce à des vidéos multi-vues et des cartes haute définition, ViP3D prédit les trajectoires futures de tous les agents de la scène.
Le processus global de ViP3D est illustré dans la figure : Tout d'abord, le tracker basé sur des requêtes traite les vidéos multi-vues des caméras environnantes pour obtenir la requête de l'agent suivi avec des fonctionnalités visuelles. Les fonctionnalités visuelles de la requête d'agent capturent la dynamique de mouvement et les caractéristiques visuelles des agents, ainsi que les relations entre les agents. Après cela, le prédicteur de trajectoire prend la requête de l'agent de suivi en entrée, l'associe aux caractéristiques de la carte HD et génère finalement la trajectoire prédite.
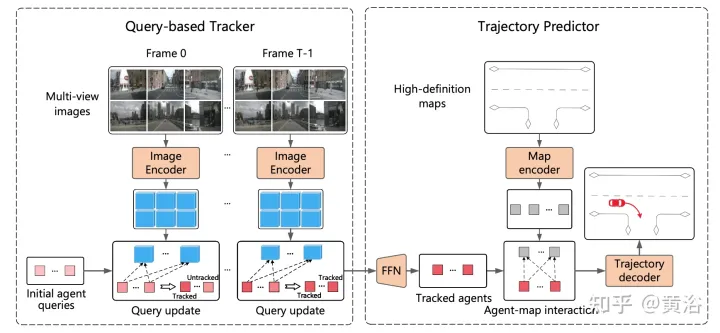
Le tracker basé sur des requêtes extrait les caractéristiques visuelles de la vidéo brute de la caméra surround. Plus précisément, pour chaque image, les caractéristiques de l'image sont extraites selon DETR3D. Pour l'agrégation des fonctionnalités du domaine temporel, un tracker basé sur des requêtes est conçu selon MOTR («Motr: End-to-end multiple-object tracking with transformer». arXiv 2105.03247, 2021), comprenant deux étapes clés : mise à jour des fonctionnalités de requête et supervision des requêtes. La requête de l'agent sera mise à jour au fil du temps pour modéliser la dynamique de mouvement de l'agent.
La plupart des méthodes de prédiction de trajectoire existantes peuvent être divisées en trois parties : l'encodage d'agent, l'encodage de carte et le décodage de trajectoire. Après un suivi basé sur des requêtes, la requête de l'agent suivi est obtenue, qui peut être considérée comme les caractéristiques de l'agent obtenues grâce au codage de l'agent. Par conséquent, les tâches restantes sont le codage de la carte et le décodage de la trajectoire.
Représentez les agents de prédiction et de vérité sous la forme d'ensembles non ordonnés Sˆ et S respectivement, où chaque agent est représenté par les coordonnées d'agent du pas de temps actuel et de K trajectoires futures possibles. Pour chaque type d'agent c, calculez la précision de la prédiction entre Scˆ et Sc. Le coût entre l'agent de prédiction et le véritable agent est défini comme :

L'EPA entre Scˆ et Sc est défini comme :

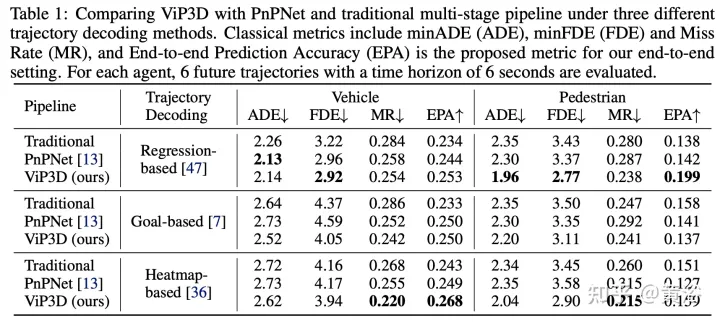
Les résultats expérimentaux sont les suivants :
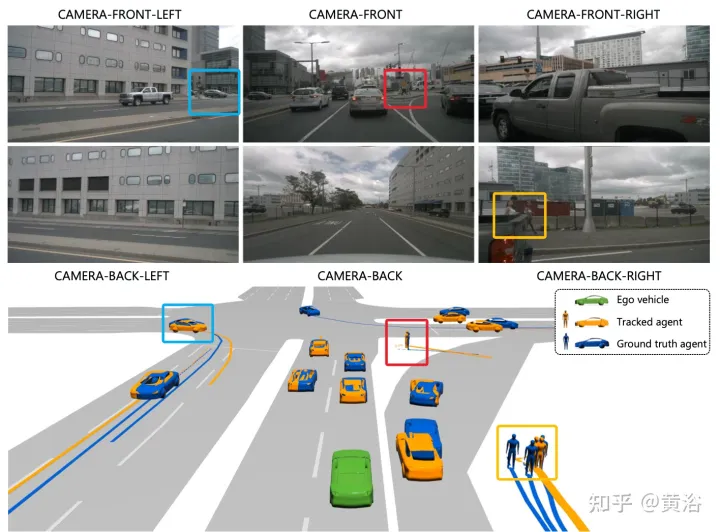
Remarque : Ce rendu cible est bien réalisé.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Les traits du visage volent, ouvrent la bouche, regardent fixement et lèvent les sourcils. L'IA peut les imiter parfaitement, ce qui rend impossible la prévention des escroqueries vidéo.
Dec 14, 2023 pm 11:30 PM
Les traits du visage volent, ouvrent la bouche, regardent fixement et lèvent les sourcils. L'IA peut les imiter parfaitement, ce qui rend impossible la prévention des escroqueries vidéo.
Dec 14, 2023 pm 11:30 PM
Avec une capacité d'imitation de l'IA aussi puissante, il est vraiment impossible de l'empêcher. Le développement de l’IA a-t-il atteint ce niveau aujourd’hui ? Votre pied avant fait voler les traits de votre visage, et sur votre pied arrière, la même expression est reproduite. Regarder fixement, lever les sourcils, faire la moue, aussi exagérée que soit l'expression, tout est parfaitement imité. Augmentez la difficulté, haussez les sourcils, ouvrez plus grand les yeux, et même la forme de la bouche est tordue, et l'avatar du personnage virtuel peut parfaitement reproduire l'expression. Lorsque vous ajustez les paramètres à gauche, l'avatar virtuel à droite modifiera également ses mouvements en conséquence pour donner un gros plan de la bouche et des yeux. On ne peut pas dire que l'imitation soit exactement la même, seule l'expression est exactement la même. idem (extrême droite). La recherche provient d'institutions telles que l'Université technique de Munich, qui propose GaussianAvatars, qui
 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Lien du projet écrit devant : https://nianticlabs.github.io/mickey/ Étant donné deux images, la pose de la caméra entre elles peut être estimée en établissant la correspondance entre les images. En règle générale, ces correspondances sont 2D à 2D et nos poses estimées sont à échelle indéterminée. Certaines applications, telles que la réalité augmentée instantanée, à tout moment et en tout lieu, nécessitent une estimation de pose des métriques d'échelle, elles s'appuient donc sur des estimateurs de profondeur externes pour récupérer l'échelle. Cet article propose MicKey, un processus de correspondance de points clés capable de prédire les correspondances métriques dans l'espace d'une caméra 3D. En apprenant la correspondance des coordonnées 3D entre les images, nous sommes en mesure de déduire des métriques relatives.
 MotionLM : technologie de modélisation de langage pour la prédiction de mouvement multi-agents
Oct 13, 2023 pm 12:09 PM
MotionLM : technologie de modélisation de langage pour la prédiction de mouvement multi-agents
Oct 13, 2023 pm 12:09 PM
Cet article est reproduit avec la permission du compte public Autonomous Driving Heart. Veuillez contacter la source pour la réimpression. Titre original : MotionLM : Multi-Agent Motion Forecasting as Language Modeling Lien vers l'article : https://arxiv.org/pdf/2309.16534.pdf Affiliation de l'auteur : Conférence Waymo : ICCV2023 Idée d'article : Pour la planification de la sécurité des véhicules autonomes, prédisez de manière fiable le comportement futur des agents routiers est cruciale. Cette étude représente les trajectoires continues sous forme de séquences de jetons de mouvement discrets et traite la prédiction de mouvement multi-agents comme une tâche de modélisation du langage. Le modèle que nous proposons, MotionLM, présente les avantages suivants :
 Le LLM est terminé ! OmniDrive : Intégration de la perception 3D et de la planification du raisonnement (la dernière version de NVIDIA)
May 09, 2024 pm 04:55 PM
Le LLM est terminé ! OmniDrive : Intégration de la perception 3D et de la planification du raisonnement (la dernière version de NVIDIA)
May 09, 2024 pm 04:55 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : cet article est dédié à la résolution des principaux défis des grands modèles de langage multimodaux (MLLM) actuels dans les applications de conduite autonome, c'est-à-dire le problème de l'extension des MLLM de la compréhension 2D à l'espace 3D. Cette expansion est particulièrement importante car les véhicules autonomes (VA) doivent prendre des décisions précises concernant les environnements 3D. La compréhension spatiale 3D est essentielle pour les véhicules utilitaires car elle a un impact direct sur la capacité du véhicule à prendre des décisions éclairées, à prédire les états futurs et à interagir en toute sécurité avec l’environnement. Les modèles de langage multimodaux actuels (tels que LLaVA-1.5) ne peuvent souvent gérer que des entrées d'images de résolution inférieure (par exemple) en raison des limitations de résolution de l'encodeur visuel et des limitations de la longueur de la séquence LLM. Cependant, les applications de conduite autonome nécessitent
 Apprentissage des connaissances sur l'occupation intermodale : RadOcc utilisant la technologie de distillation assistée par rendu
Jan 25, 2024 am 11:36 AM
Apprentissage des connaissances sur l'occupation intermodale : RadOcc utilisant la technologie de distillation assistée par rendu
Jan 25, 2024 am 11:36 AM
Titre original : Radocc : LearningCross-ModalityOccupancyKnowledgethroughRenderingAssistedDistillation Lien vers l'article : https://arxiv.org/pdf/2312.11829.pdf Unité auteur : FNii, CUHK-ShenzhenSSE, CUHK-Shenzhen Conférence du laboratoire Huawei Noah's Ark : AAAI2024 Idée d'article : la prédiction d'occupation 3D est une tâche émergente qui vise à estimer l'état d'occupation et la sémantique de scènes 3D à l'aide d'images multi-vues. Cependant, en raison du manque d’a priori géométriques, les scénarios basés sur des images
