
 Périphériques technologiques
IA
Réseau de perception pour l'estimation de la profondeur, de l'attitude et de la route dans des scénarios de conduite communs
Périphériques technologiques
IA
Réseau de perception pour l'estimation de la profondeur, de l'attitude et de la route dans des scénarios de conduite communs
Réseau de perception pour l'estimation de la profondeur, de l'attitude et de la route dans des scénarios de conduite communs

L'article d'arXiv « JPerceiver : Joint Perception Network for Depth, Pose and Layout Estimation in Driving Scenes », mis en ligne le 22 juillet, rend compte des travaux du professeur Tao Dacheng de l'Université de Sydney, en Australie, et du Beijing JD Research Institute.

L'estimation de la profondeur, l'odométrie visuelle (VO) et l'estimation de la disposition des scènes en vue à vol d'oiseau (BEV) sont trois tâches clés pour la perception des scènes de conduite, qui constituent la base de la planification des mouvements et de la navigation dans la conduite autonome. Bien que complémentaires, ils se concentrent généralement sur des tâches distinctes et abordent rarement les trois simultanément.
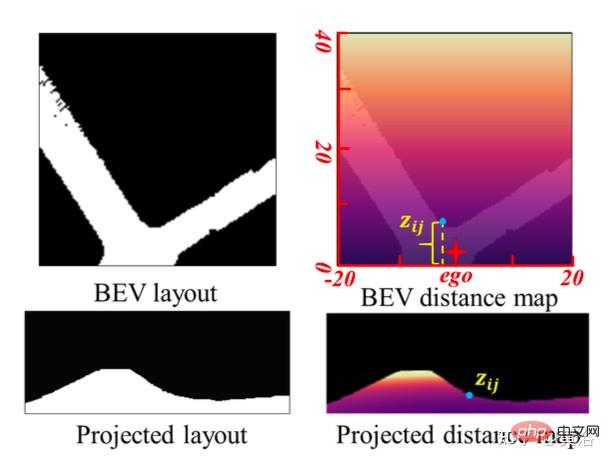
Une approche simple consiste à le faire indépendamment de manière séquentielle ou parallèle, mais il y a trois inconvénients, à savoir 1) les résultats de profondeur et de VO sont affectés par le problème d'ambiguïté d'échelle inhérent 2) la disposition BEV est généralement estimée séparément pour la route et ; véhicule, tout en ignorant la relation explicite de superposition-sous-couche ; 3) Bien que la carte de profondeur soit un indice géométrique utile pour déduire la disposition de la scène, la disposition BEV est en fait prédite directement à partir de l'image de face sans utiliser aucune information relative à la profondeur.
Cet article propose un cadre de perception commun JPerceiver pour résoudre ces problèmes et estimer simultanément la profondeur perçue à l'échelle, la disposition VO et BEV à partir de séquences vidéo monoculaires. Utilisez la transformation géométrique à vue croisée (CGT) pour propager l'échelle absolue du tracé de la route à la profondeur et à la VO sur la base d'une perte d'échelle soigneusement conçue. Dans le même temps, un module cross-view and cross-modal transfer (CCT) est conçu pour utiliser des indices de profondeur pour raisonner sur la disposition des routes et des véhicules grâce à des mécanismes d'attention.
JPerceiver est formé à une méthode d'apprentissage multitâche de bout en bout, dans laquelle les modules de perte d'échelle CGT et CCT favorisent le transfert de connaissances entre les tâches et facilitent l'apprentissage des fonctionnalités pour chaque tâche. Le code et le modèle peuvent être téléchargéshttps://github.com/sunnyHelen/JPerceiver.
Comme le montre la figure, JPerceiver se compose de trois réseaux : profondeur, attitude et tracé de la route , qui sont tous basés sur une architecture codeur-décodeur. Le réseau de profondeur vise à prédire la carte de profondeur Dt de la trame courante It, où chaque valeur de profondeur représente la distance entre un point 3D et la caméra. Le but du réseau de poses est de prédire la transformation de pose Tt→t+m entre la trame courante It et sa trame adjacente It+m. L'objectif du réseau routier est d'estimer le tracé BEV Lt du cadre actuel, c'est-à-dire l'occupation sémantique des routes et des véhicules dans le plan cartésien vu de dessus. Les trois réseaux sont optimisés conjointement lors de la formation.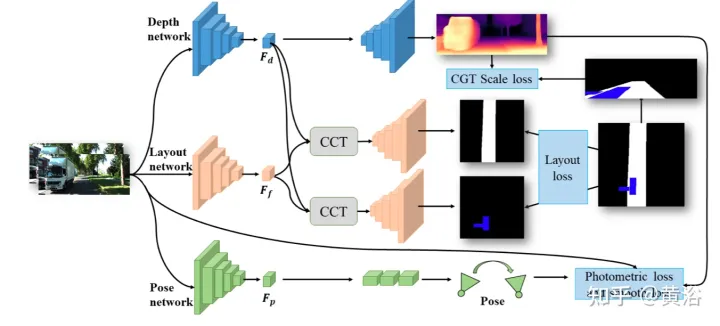
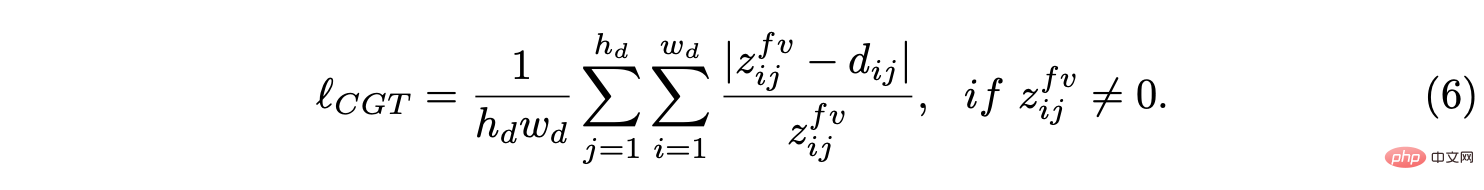
CCT- CV et CCT-CM du module cross-view et du module cross-modal.
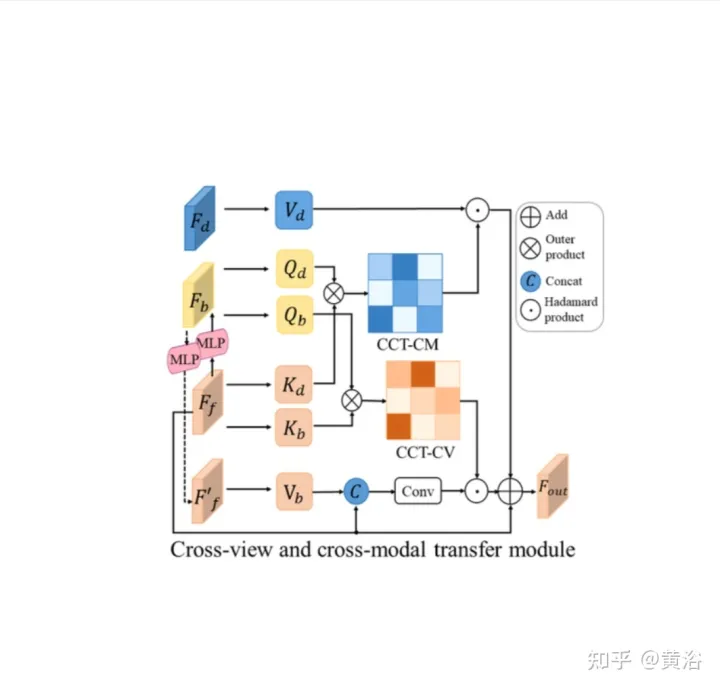
En CCT, Ff et Fd sont extraits par l'encodeur de la branche perceptuelle correspondante, tandis que Fb est obtenu par une projection de vue MLP pour convertir Ff en BEV, et une perte de cycle contrainte par le même MLP pour le reconvertir en Ff′.
Dans CCT-CV, le mécanisme d'attention croisée est utilisé pour découvrir la correspondance géométrique entre la vue avant et les caractéristiques BEV, puis guide le raffinement des informations de vue avant et prépare l'inférence BEV. Afin d'utiliser pleinement les fonctionnalités d'image de vue avant, Fb et Ff sont projetés sur des correctifs : Qbi et Kbi, respectivement en tant que requête et clé.
En plus d'utiliser les fonctionnalités de vue avant, CCT-CM est également déployé pour imposer des informations géométriques 3D à partir de Fd. Puisque Fd est extrait de l’image de vue avant, il est raisonnable d’utiliser Ff comme pont pour réduire l’écart intermodal et apprendre la correspondance entre Fd et Fb. Fd joue le rôle de valeur, obtenant ainsi de précieuses informations géométriques 3D liées aux informations BEV et améliorant encore la précision de l'estimation du tracé routier.
Dans le processus d'exploration d'un cadre d'apprentissage commun pour prédire simultanément différentes dispositions, il existe de grandes différences dans les caractéristiques et la distribution des différentes catégories sémantiques. Pour les fonctionnalités, le tracé de la route dans les scénarios de conduite doit généralement être connecté, tandis que les différentes cibles de véhicules doivent être segmentées.
Pour la distribution, plus de scènes de routes droites sont observées que de scènes de virage, ce qui est raisonnable dans des ensembles de données réels. Cette différence et ce déséquilibre augmentent la difficulté de l'apprentissage de la disposition BEV, en particulier la prédiction conjointe de différentes catégories, car une simple perte d'entropie croisée (CE) ou une perte L1 échoue dans ce cas. Plusieurs pertes de segmentation, notamment la perte CE basée sur la distribution, la perte IoU basée sur la région et la perte de limite, sont combinées en une perte hybride pour prédire la disposition de chaque catégorie.
Les résultats expérimentaux sont les suivants :
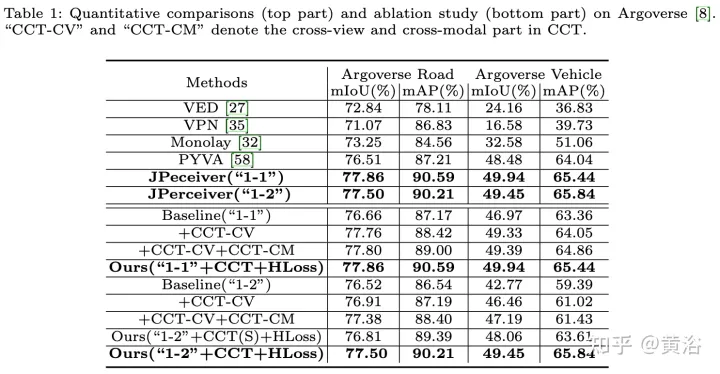
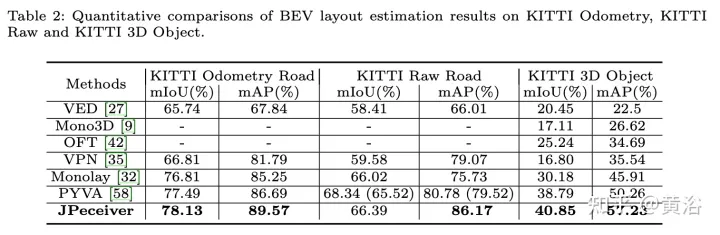
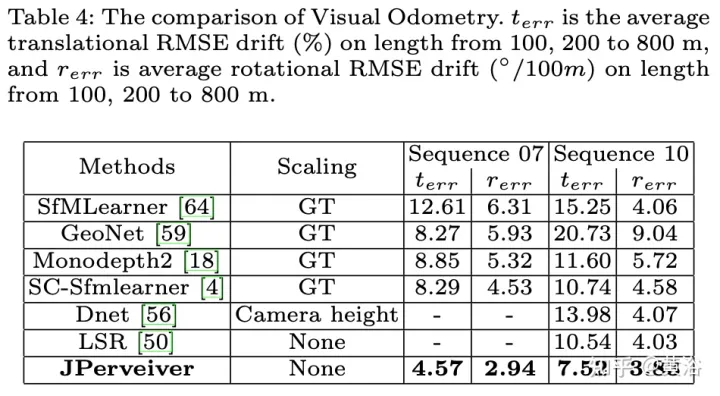
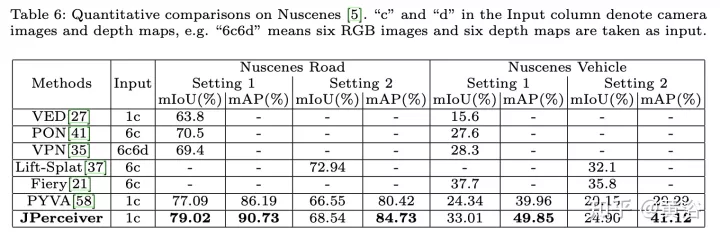
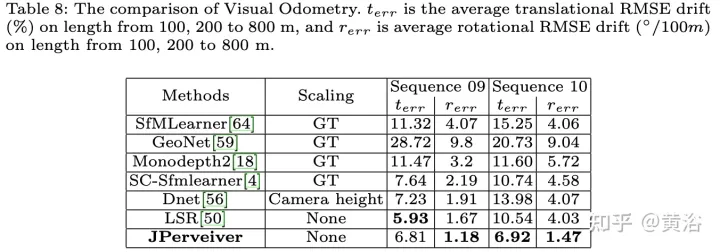
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Le premier article pilote et clé présente principalement plusieurs systèmes de coordonnées couramment utilisés dans la technologie de conduite autonome, et comment compléter la corrélation et la conversion entre eux, et enfin construire un modèle d'environnement unifié. L'objectif ici est de comprendre la conversion du véhicule en corps rigide de caméra (paramètres externes), la conversion de caméra en image (paramètres internes) et la conversion d'image en unité de pixel. La conversion de 3D en 2D aura une distorsion, une traduction, etc. Points clés : Le système de coordonnées du véhicule et le système de coordonnées du corps de la caméra doivent être réécrits : le système de coordonnées planes et le système de coordonnées des pixels Difficulté : la distorsion de l'image doit être prise en compte. La dé-distorsion et l'ajout de distorsion sont compensés sur le plan de l'image. 2. Introduction Il existe quatre systèmes de vision au total : système de coordonnées du plan de pixels (u, v), système de coordonnées d'image (x, y), système de coordonnées de caméra () et système de coordonnées mondiales (). Il existe une relation entre chaque système de coordonnées,
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
