
 Périphériques technologiques
IA
Voyager sans obstacles est plus sûr ! Les résultats de la recherche de ByteDance ont remporté le championnat du concours CVPR2022 AVA
Périphériques technologiques
IA
Voyager sans obstacles est plus sûr ! Les résultats de la recherche de ByteDance ont remporté le championnat du concours CVPR2022 AVA
Voyager sans obstacles est plus sûr ! Les résultats de la recherche de ByteDance ont remporté le championnat du concours CVPR2022 AVA

Récemment, les résultats de divers concours CVPR2022 ont été annoncés. L'équipe de la plateforme d'IA de création intelligente de ByteDance "Byte-IC-AutoML" a remporté le défi de segmentation d'instance basé sur des données synthétiques (Accessibility Vision and Autonomy Challenge (ci-après dénommé AVA)). , s'appuyant sur le cadre de transformateurs parallèles pré-entraînés (PPT) auto-développé, s'est démarqué et est devenu le vainqueur de la seule piste du concours.
Adresse papier:https://www.php.cn/link/ede529dfcbb2907e9760eea0875cdd12
Ce concours AVA est parrainé par l'Université de Boston. Organisé conjointement avec Université Carnegie Mellon.
Le concours génère un ensemble de données de segmentation d'instances synthétiques via un moteur de rendu contenant des échantillons de données de systèmes autonomes interagissant avec des piétons handicapés. L'objectif du concours est de fournir des benchmarks et des méthodes de détection d'objets et de segmentation d'instances pour les personnes et les objets liés à l'accessibilité.

Visualisation des jeux de données
Analyse des difficultés de la concurrence
- Problème de généralisation des domaines : Les ensembles de données de ce concours sont tous des images, des domaines de données et des images naturelles synthétisées par des moteurs de rendu . Il existe des différences significatives ;
- Problème de longue traîne/peu d'échantillons : les données ont une distribution à longue traîne, par exemple, les catégories « Béquilles » et « Fauteuil roulant » sont moins nombreuses dans l'ensemble de données, et l'effet de segmentation est plus faible. pire ;
- Robustesse de la segmentation Problème : L'effet de segmentation de certaines catégories est très faible. Le mAP de segmentation d'instance est 30 inférieur au mAP de segmentation de détection de cible
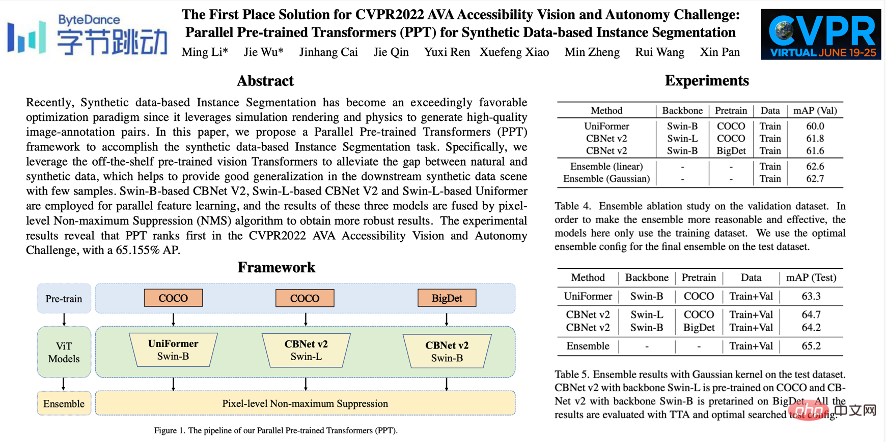
Byte-IC-. L'équipe AutoML a proposé un cadre de transformateurs parallèles pré-entraînés (PPT) à compléter. Le cadre se compose principalement de trois modules : 1) Transformateurs pré-entraînés parallèles à grande échelle ; 2) Amélioration des données de copier-coller d'équilibre ; 3) Suppression non maximale au niveau des pixels et fusion de modèles ; formation Transformers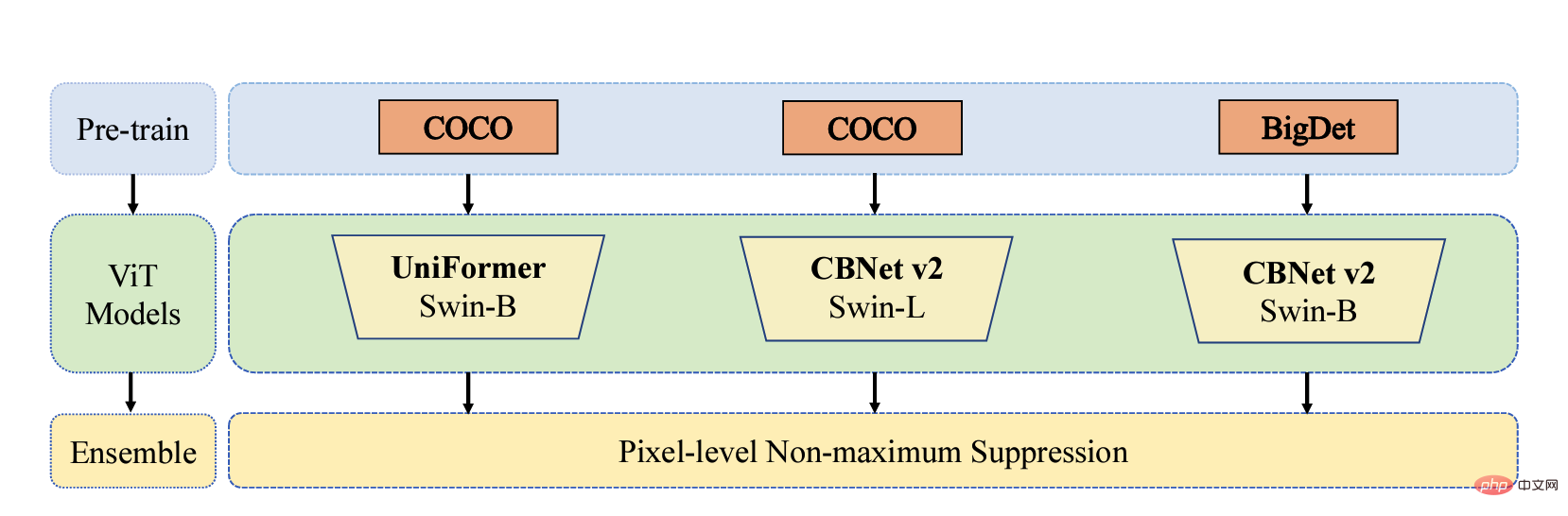
De nombreux articles récents de pré-formation ont montré que les modèles pré-entraînés sur des ensembles de données à grande échelle peuvent bien se généraliser à différents scénarios en aval. Par conséquent, l'équipe utilise les ensembles de données COCO et
BigDetectionpour pré-entraîner d'abord le modèle, ce qui peut atténuer davantage l'écart de champ entre les données naturelles et les données synthétiques, afin qu'il puisse utiliser moins de données dans les données synthétiques en aval. Scénarios de données. Exemples pour une formation rapide. Au niveau du modèle, considérant que les Vision Transformers n'ont pas le biais inductif de CNN et peuvent bénéficier des avantages de la pré-formation, l'équipe utilise
UniFormeret CBNetV2. UniFormer unifie la convolution et l'attention personnelle, résout simultanément les deux problèmes majeurs de redondance locale et de dépendance globale et permet un apprentissage efficace des fonctionnalités. L'architecture CBNetV2 concatène plusieurs paquets de base identiques connectés de manière composite pour créer des détecteurs hautes performances. Les extracteurs de fonctionnalités de base du modèle sont tous Swin Transformer. Plusieurs transformateurs pré-entraînés à grande échelle sont disposés en parallèle, et les résultats de sortie sont intégrés et appris pour produire le résultat final. carte des différentes méthodes sur l'ensemble de données de validation
Augmentation des données par copier-coller d'équilibre 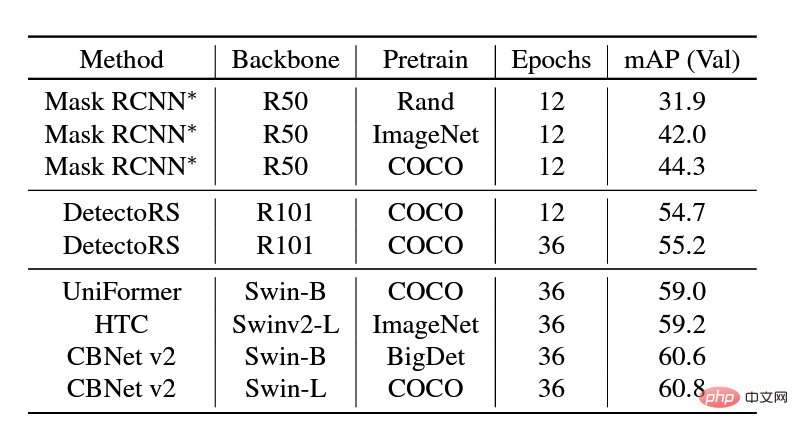
La technique de copier-coller fournit des résultats impressionnants pour les modèles de segmentation d'instance en collant aléatoirement des objets, en particulier pour un ensemble de données sous un distribution à longue traîne. Cependant, cette méthode augmente uniformément les échantillons de toutes les catégories et ne parvient pas à atténuer fondamentalement le problème de longue traîne de la répartition des catégories. Par conséquent, l’équipe a proposé la méthode d’amélioration des données Balance Copier-Coller. L'équilibre copier-coller échantillonne de manière adaptative les catégories en fonction du nombre effectif de catégories, améliore la qualité globale de l'échantillon, atténue les problèmes de petit nombre d'échantillons et de distribution à longue traîne, et améliore finalement considérablement le mAP du modèle dans la segmentation des instances.
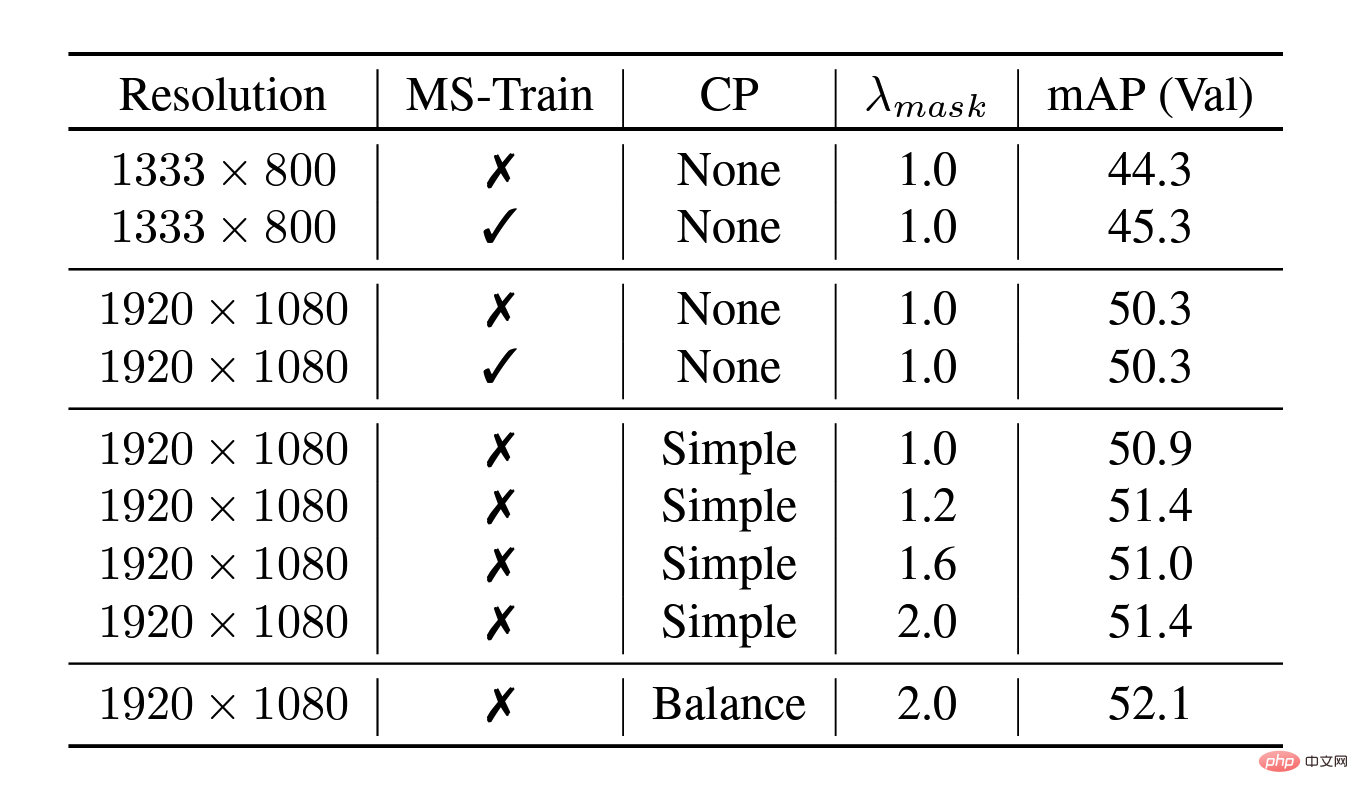
Améliorations apportées par la technologie d'amélioration des données Balance Copier-Coller
Suppression non maximale au niveau des pixels et fusion de modèles
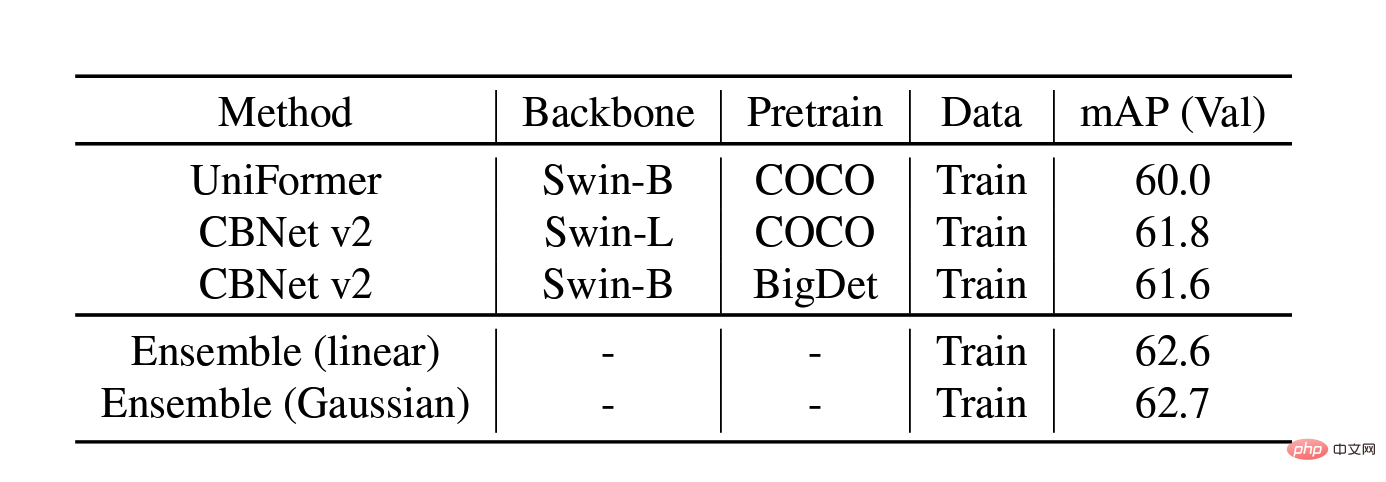
Expérience d'ablation par fusion de modèles sur l'ensemble de validation
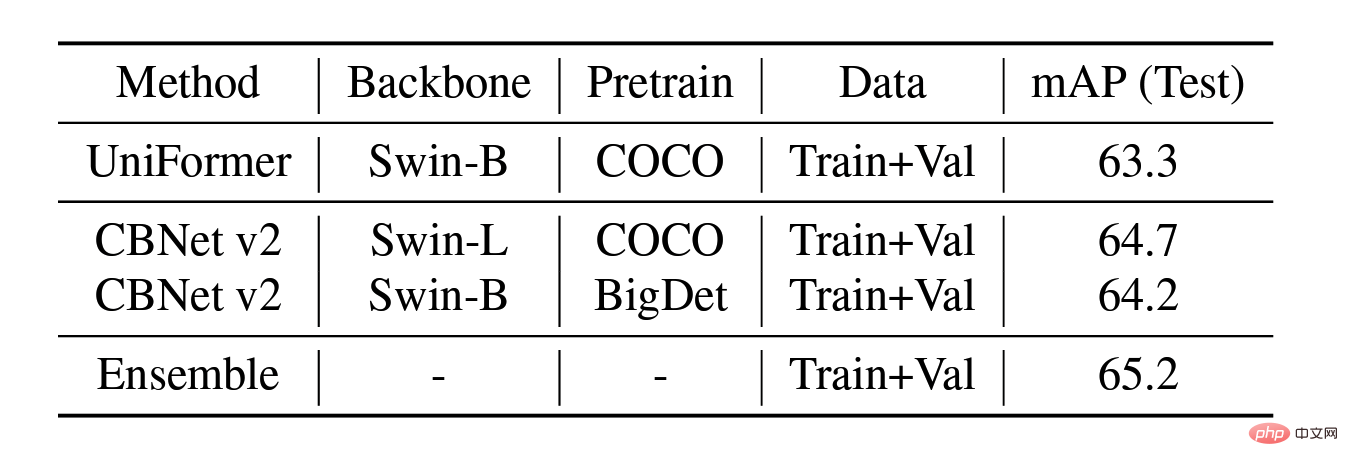
Expérience d'ablation par fusion de modèles sur l'ensemble de test
Actuellement, les ensembles de données urbaines et de circulation sont des scènes plus générales, ne contenant que les transports normaux et les piétons. L'ensemble de données manque d'informations sur les personnes handicapées et les personnes à mobilité réduite. catégories de leurs dispositifs auxiliaires, ces personnes et objets ne peuvent pas être détectés par le modèle de détection obtenu à partir des ensembles de données existants actuels.
Cette solution technique de l'équipe Byte-IC-AutoML de ByteDance est largement utilisée dans la conduite autonome actuelle et dans la compréhension des scènes de rue : le modèle obtenu grâce à ces données synthétiques peut identifier les « fauteuils roulants » et les « personnes en fauteuil roulant ». Les « personnes » et les « personnes avec des béquilles » peuvent non seulement classer les personnes/objets plus précisément, mais également éviter les erreurs d'appréciation qui conduisent à des malentendus sur la scène. De plus, grâce à cette méthode de synthèse des données, des données de catégories relativement rares dans le monde réel peuvent être construites, formant ainsi un modèle de détection de cible plus polyvalent et plus complet.
Intelligent Creation est l'institut de recherche en technologie d'innovation multimédia de ByteDance et un fournisseur de services complet. Couvrant la vision par ordinateur, le graphisme, la voix, la prise de vue et le montage, les effets spéciaux, les clients, les plateformes d'IA, l'ingénierie des serveurs et d'autres domaines techniques, une boucle fermée d'algorithmes-ingénierie-systèmes-produits de pointe a été mise en œuvre au sein du département, dans le but d'utiliser multiple De cette manière, nous fournissons aux secteurs d'activité internes de l'entreprise et aux clients coopératifs externes la compréhension du contenu, la création de contenu, l'expérience interactive, les capacités de consommation et les solutions industrielles les plus avancées du secteur. Les capacités techniques de l'équipe sont mises à la disposition du monde extérieur grâce au Volcano Engine.
Volcano Engine est une plate-forme de services cloud appartenant à ByteDance. Elle ouvre les méthodes de croissance, les capacités techniques et les outils accumulés lors du développement rapide de ByteDance à des sociétés externes, fournissant une base cloud, une distribution de vidéos et de contenu, du big data, des services tels que Comme l’intelligence artificielle, le développement, l’exploitation et la maintenance aident les entreprises à atteindre une croissance soutenue lors des mises à niveau numériques.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Tan Dai, président de Volcano Engine, a déclaré que les entreprises qui souhaitent bien mettre en œuvre de grands modèles sont confrontées à trois défis clés : l'effet de modèle, le coût d'inférence et la difficulté de mise en œuvre : elles doivent disposer d'un bon support de base de grands modèles pour résoudre des problèmes complexes, et elles doivent également avoir une inférence à faible coût. Les services permettent d'utiliser largement de grands modèles, et davantage d'outils, de plates-formes et d'applications sont nécessaires pour aider les entreprises à mettre en œuvre des scénarios. ——Tan Dai, président de Huoshan Engine 01. Le grand modèle de pouf fait ses débuts et est largement utilisé. Le polissage de l'effet de modèle est le défi le plus critique pour la mise en œuvre de l'IA. Tan Dai a souligné que ce n'est que grâce à une utilisation intensive qu'un bon modèle peut être poli. Actuellement, le modèle Doubao traite 120 milliards de jetons de texte et génère 30 millions d'images chaque jour. Afin d'aider les entreprises à mettre en œuvre des scénarios de modèles à grande échelle, le modèle à grande échelle beanbao développé indépendamment par ByteDance sera lancé à travers le volcan.
 L'effet marketing a été grandement amélioré, c'est ainsi que la création vidéo AIGC doit être utilisée
Jun 25, 2024 am 12:01 AM
L'effet marketing a été grandement amélioré, c'est ainsi que la création vidéo AIGC doit être utilisée
Jun 25, 2024 am 12:01 AM
Après plus d'un an de développement, AIGC est progressivement passé de la génération de dialogues textuels et d'images à la génération de vidéos. Il y a quatre mois, la naissance de Sora a provoqué un remaniement dans le domaine de la génération vidéo et a vigoureusement promu la portée et la profondeur des applications d'AIGC dans le domaine de la création vidéo. A l’heure où tout le monde parle de grands modèles, d’un côté on est surpris par le choc visuel apporté par la génération vidéo, de l’autre on est confronté à la difficulté de mise en œuvre. Il est vrai que les grands modèles sont encore dans une période de rodage, depuis la recherche et le développement technologique jusqu'à la pratique des applications, et qu'ils doivent encore être ajustés en fonction de scénarios commerciaux réels, mais la distance entre l'idéal et la réalité se réduit progressivement. Le marketing, en tant que scénario de mise en œuvre important de la technologie de l’intelligence artificielle, est devenu une direction dans laquelle de nombreuses entreprises et praticiens souhaitent faire des percées. Une fois que vous maîtriserez les méthodes appropriées, le processus créatif des vidéos marketing sera
 Comment explorer et visualiser les données ML pour la détection d'objets dans les images
Feb 16, 2024 am 11:33 AM
Comment explorer et visualiser les données ML pour la détection d'objets dans les images
Feb 16, 2024 am 11:33 AM
Ces dernières années, les gens ont acquis une meilleure compréhension de l’importance d’une compréhension approfondie des données d’apprentissage automatique (ML-data). Cependant, étant donné que la détection de grands ensembles de données nécessite généralement un investissement humain et matériel important, son application généralisée dans le domaine de la vision par ordinateur nécessite encore des développements supplémentaires. Habituellement, dans la détection d'objets (un sous-ensemble de la vision par ordinateur), les objets dans l'image sont positionnés en définissant des cadres de délimitation. Non seulement l'objet peut être identifié, mais le contexte, la taille et la relation entre l'objet et les autres éléments de la scène peuvent également être identifiés. également être compris. Dans le même temps, une compréhension globale de la répartition des classes, de la diversité des tailles d'objets et des environnements communs dans lesquels les classes apparaissent aidera également à découvrir des modèles d'erreur dans le modèle de formation lors de l'évaluation et du débogage,
 Explication détaillée du modèle de pré-formation d'apprentissage profond en Python
Jun 11, 2023 am 08:12 AM
Explication détaillée du modèle de pré-formation d'apprentissage profond en Python
Jun 11, 2023 am 08:12 AM
Avec le développement de l'intelligence artificielle et de l'apprentissage profond, les modèles de pré-formation sont devenus une technologie populaire dans le traitement du langage naturel (NLP), la vision par ordinateur (CV), la reconnaissance vocale et d'autres domaines. En tant que l'un des langages de programmation les plus populaires à l'heure actuelle, Python joue naturellement un rôle important dans l'application de modèles pré-entraînés. Cet article se concentrera sur le modèle de pré-formation d'apprentissage profond en Python, y compris sa définition, ses types, ses applications et comment utiliser le modèle de pré-formation. Qu'est-ce qu'un modèle pré-entraîné ? La principale difficulté des modèles d’apprentissage profond est d’analyser un grand nombre de données de haute qualité.
 La force technique de Huoshan Voice TTS a été certifiée par le Centre national d'inspection et de quarantaine, avec un score MOS aussi élevé que 4,64.
Apr 12, 2023 am 10:40 AM
La force technique de Huoshan Voice TTS a été certifiée par le Centre national d'inspection et de quarantaine, avec un score MOS aussi élevé que 4,64.
Apr 12, 2023 am 10:40 AM
Récemment, le produit de synthèse vocale Volcano Engine a obtenu le certificat d'inspection et de test amélioré de synthèse vocale délivré par le Centre national d'inspection et de test de la qualité des produits de reconnaissance vocale et d'image (ci-après dénommé le « Centre national d'inspection de l'IA »). exigences de base et exigences étendues de la synthèse vocale. Le niveau le plus élevé du Centre national d'inspection de l'IA. Cette évaluation est menée à partir des dimensions du chinois mandarin, des multi-dialectes, des multi-langues, des langues mixtes, des multitimbraux et de la personnalisation. L'équipe de support technique du produit, l'équipe Volcano Voice, fournit une riche bibliothèque sonore. Le score MOS du timbre est le plus élevé. Il atteint 4,64 points, ce qui constitue le niveau le plus élevé de l'industrie. En tant que première et unique agence nationale d'inspection et de test de la qualité des produits vocaux et images dans le domaine de l'intelligence artificielle dans le système d'inspection de la qualité de mon pays, le Centre national d'inspection de l'IA s'est engagé à promouvoir l'intelligence artificielle.
 En vous concentrant sur une expérience personnalisée, la fidélisation des utilisateurs dépend entièrement de l'AIGC ?
Jul 15, 2024 pm 06:48 PM
En vous concentrant sur une expérience personnalisée, la fidélisation des utilisateurs dépend entièrement de l'AIGC ?
Jul 15, 2024 pm 06:48 PM
1. Avant d’acheter un produit, les consommateurs rechercheront et parcourront les avis sur les produits sur les réseaux sociaux. Il devient donc de plus en plus important pour les entreprises de commercialiser leurs produits sur les plateformes sociales. Le but du marketing est de : Promouvoir la vente de produits Établir une image de marque Améliorer la notoriété de la marque Attirer et fidéliser les clients Améliorer à terme la rentabilité de l'entreprise Le grand modèle possède d'excellentes capacités de compréhension et de génération et peut fournir aux utilisateurs des informations personnalisées en parcourant et en analysant recommandations sur le contenu des données utilisateur. Dans le quatrième numéro de « AIGC Experience School », deux invités discuteront en profondeur du rôle de la technologie AIGC dans l'amélioration du « taux de conversion marketing ». Heure de diffusion en direct : 10 juillet, de 19h00 à 19h45 Sujet de diffusion en direct : Pour fidéliser les utilisateurs, comment l'AIGC améliore-t-elle le taux de conversion grâce à la personnalisation ? Le quatrième épisode du programme a invité deux importants
 Une exploration approfondie de la mise en œuvre de la technologie de pré-formation non supervisée et de « l'optimisation des algorithmes + l'innovation technique » de Huoshan Voice
Apr 08, 2023 pm 12:44 PM
Une exploration approfondie de la mise en œuvre de la technologie de pré-formation non supervisée et de « l'optimisation des algorithmes + l'innovation technique » de Huoshan Voice
Apr 08, 2023 pm 12:44 PM
Depuis longtemps, Volcano Engine propose des solutions de sous-titres vidéo intelligentes basées sur la technologie de reconnaissance vocale pour les plateformes vidéo populaires. Pour faire simple, il s'agit d'une fonction qui utilise la technologie IA pour convertir automatiquement les voix et les paroles de la vidéo en texte pour aider à la création vidéo. Cependant, avec la croissance rapide du nombre d’utilisateurs de la plateforme et la nécessité de langues plus riches et plus diversifiées, la technologie d’apprentissage supervisé traditionnellement utilisée atteint de plus en plus son goulot d’étranglement, ce qui met l’équipe en difficulté. Comme nous le savons tous, l'apprentissage supervisé traditionnel s'appuiera fortement sur des données supervisées annotées manuellement, en particulier dans l'optimisation continue des grands langages et le démarrage à froid des petits langages. En prenant comme exemple les principales langues telles que le chinois, le mandarin et l'anglais, bien que la plate-forme vidéo fournisse suffisamment de données vocales pour les scénarios commerciaux, une fois que les données supervisées auront atteint une certaine échelle, elles continueront à
 Reconnaissance d'intention de requête basée sur l'amélioration des connaissances et un grand modèle pré-entraîné
May 19, 2023 pm 02:01 PM
Reconnaissance d'intention de requête basée sur l'amélioration des connaissances et un grand modèle pré-entraîné
May 19, 2023 pm 02:01 PM
1. Introduction générale La numérisation des entreprises est un sujet brûlant ces dernières années. Elle fait référence à l'utilisation de technologies numériques de nouvelle génération telles que l'intelligence artificielle, le big data et le cloud computing pour changer le modèle économique des entreprises, favorisant ainsi une nouvelle croissance de leur activité. . La numérisation des entreprises comprend généralement la numérisation des opérations commerciales et la numérisation de la gestion de l'entreprise. Ce partage introduit principalement la numérisation au niveau de la gestion de l'entreprise. La numérisation de l’information, en termes simples, signifie lire, écrire, stocker et transmettre des informations de manière numérique. Des anciens documents papier aux documents électroniques actuels et aux documents collaboratifs en ligne, la numérisation des informations est devenue la nouvelle norme dans les bureaux d'aujourd'hui. Actuellement, Alibaba utilise DingTalk Documents et Yuque Documents pour la collaboration commerciale, et le nombre de documents en ligne a atteint plus de 20 millions. De plus, de nombreuses entreprises
