

Actuellement, l'application à grande échelle de l'intelligence artificielle dans les entreprises rencontre de nombreuses difficultés, telles que : de longs cycles de déploiement de R&D, des résultats inférieurs aux attentes et des difficultés à faire correspondre les données et les modèles. C’est dans ce contexte que les MLOps sont nés. MLOps apparaît comme une technologie clé pour aider à faire évoluer l’apprentissage automatique dans l’entreprise.
Il y a quelques jours, la AISummit Global Artificial Intelligence Technology Conference organisée par 51CTO s'est tenue avec succès. Lors de la session « Meilleures pratiques MLOps » organisée lors de la conférence, Tan Zhongyi, vice-président de l'Open Atomic Foundation TOC, Lu Mian, architecte système du quatrième paradigme, Wu Guanlin, chercheur en intelligence artificielle chez NetEase Cloud Music, Centre de développement de logiciels de la Banque industrielle et commerciale de Chine Big Data et L'intelligence artificielle Huang Bing, directeur adjoint du laboratoire, a prononcé son propre discours d'ouverture et a discuté du combat réel des MLOps autour de sujets d'actualité tels que le cycle d'opération de R&D, la formation continue et la surveillance continue, la version et la lignée du modèle, la cohérence des données en ligne et hors ligne. et une fourniture efficace de données.
Andrew NG a exprimé à plusieurs reprises que l'IA est passée d'une approche centrée sur le modèle à une approche centrée sur les données, et que les données constituent le plus grand défi pour la mise en œuvre de l'IA. Comment garantir une fourniture de données de haute qualité est une question clé. Pour résoudre ce problème, nous devons utiliser la pratique du MLOps pour aider l'IA à être mise en œuvre rapidement, facilement et de manière rentable.
Alors, quels problèmes MLOps résout-il ? Comment évaluer la maturité d’un projet MLOps ? Tan Zhongyi, vice-président de l'Open Atomic Foundation TOC et membre du LF AI & Data TAC, a prononcé un discours d'ouverture « Du modèle centré au centre données - MLOps aide l'IA à être mise en œuvre rapidement, facilement et de manière rentable », qui a été introduit dans détail.
Tan Zhongyi a d'abord partagé le point de vue d'un groupe de scientifiques et d'analystes de l'industrie. Andrew NG estime que l'amélioration de la qualité des données peut améliorer l'efficacité de la mise en œuvre de l'IA plus que l'amélioration des algorithmes de modèle. Selon lui, la tâche la plus importante du MLOps est de toujours maintenir un approvisionnement en données de haute qualité à toutes les étapes du cycle de vie de l'apprentissage automatique.
Pour parvenir à une mise en œuvre à grande échelle de l'IA, les MLOps doivent être développés. Quant à ce qu'est exactement MLOps, il n'y a pas de consensus dans l'industrie. Il a donné sa propre explication : il s'agit de « l'intégration continue, le déploiement continu, la formation continue et la surveillance continue du code + du modèle + des données ».
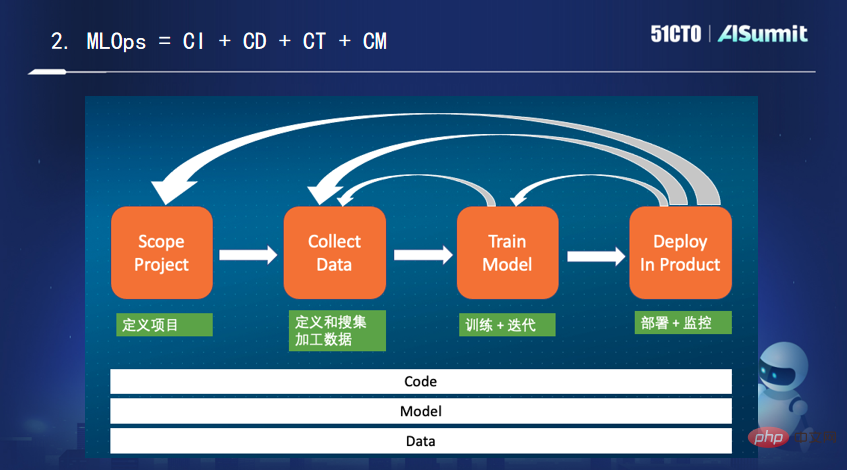
Ensuite, Tan Zhongyi s'est concentré sur l'introduction des caractéristiques de Feature Store, une plate-forme unique dans le domaine de l'apprentissage automatique, ainsi que des produits de plate-forme de fonctionnalités grand public actuellement sur le marché.
Enfin, Tan Zhongyi a brièvement développé le modèle de maturité MLOps. Il a mentionné que Microsoft Azure a divisé le modèle mature MLOps en plusieurs niveaux (0, 1, 2, 3, 4) en fonction du degré d'automatisation de l'ensemble du processus d'apprentissage automatique, où 0 signifie aucune automatisation et 123 signifie automatisation partielle, 4. est un haut degré d’automatisation.
Dans de nombreux scénarios d'apprentissage automatique, nous sommes confrontés à la nécessité d'un calcul de fonctionnalités en temps réel. Des scripts de fonctionnalités développés hors ligne par des data scientists aux calculs de fonctionnalités en ligne et en temps réel, le coût de mise en œuvre de l'IA est très élevé.
En réponse à ce problème, Lu Mian, architecte système 4Paradigm, équipe de bases de données et chef d'équipe de calcul haute performance, a souligné dans son discours d'ouverture « Base de données d'apprentissage automatique Open Source OpenMLDB : une fonctionnalité cohérente au niveau de la production en ligne et hors ligne ». Plate-forme" Cet article explique comment OpenMLDB atteint l'objectif de lancer immédiatement le développement de fonctionnalités d'apprentissage automatique et comment garantir la précision et l'efficacité des calculs de fonctionnalités.
Lu Mian a souligné qu'avec les progrès de la mise en œuvre de l'ingénierie de l'intelligence artificielle, dans le processus d'ingénierie des fonctionnalités, la vérification de la cohérence en ligne a entraîné des coûts de mise en œuvre élevés. OpenMLDB fournit une solution open source à faible coût. Elle résout non seulement le problème principal - la cohérence de l'apprentissage automatique en ligne et hors ligne, résout le problème de l'exactitude, mais réalise également un calcul de fonctionnalités en temps réel au niveau de la milliseconde. C’est sa valeur fondamentale.
Selon Lu Mian, la société indonésienne de paiement en ligne Akulaku est la première entreprise communautaire utilisateur après qu'OpenMLDB soit open source. Ils ont intégré OpenMLDB dans leur architecture informatique intelligente. Dans la réalité, Akulaku traite en moyenne près d'un milliard de données de commande par jour. Après avoir utilisé OpenMLDB, son délai de traitement des données n'est que de 4 millisecondes, ce qui répond pleinement aux besoins de son entreprise.
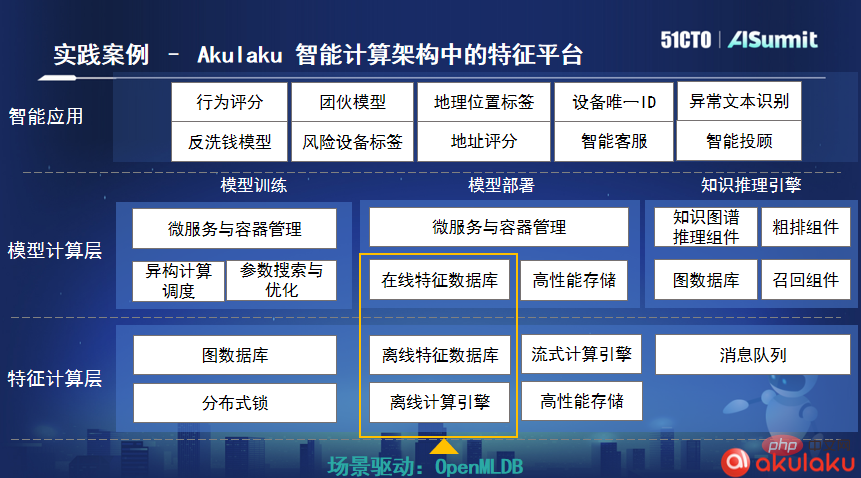
En vous appuyant sur les données massives, les algorithmes précis et les systèmes en temps réel de NetEase Cloud Music pour servir plusieurs scénarios de distribution et de commercialisation de contenu, tout en répondant aux exigences d'efficacité de modélisation élevée et de faible seuils d'utilisation, mais aussi une série d'activités d'ingénierie algorithmique telles que des effets de modèle significatifs. Pour cette raison, l'équipe d'ingénierie des algorithmes musicaux de NetEase Cloud a commencé la mise en œuvre pratique d'une plate-forme d'apprentissage automatique de bout en bout en collaboration avec le secteur de la musique.
Wu Guanlin, chercheur en intelligence artificielle et directeur technique de NetEase Cloud Music, a prononcé un discours d'ouverture « Pratique technique de la plate-forme de fonctionnalités NetEase Cloud Music ». En partant du contexte commercial de la musique cloud, il a expliqué le plan de mise en œuvre en temps réel de. le modèle, combiné avec le Feature Store pour en discuter davantage avec les participants. L'auteur a partagé ses réflexions.
Wu Guanlin a mentionné que dans la construction de projets d'algorithmes de modèles de musique cloud, il existe trois principaux problèmes : un faible niveau de temps réel, une faible efficacité de modélisation et des capacités de modèle limitées causées par des incohérences en ligne et hors ligne. En réponse à ces problèmes, ils sont partis du modèle en temps réel et ont construit la plate-forme Feature Store correspondante dans le cadre du modèle couvrant l'entreprise en temps réel.
Wu Guanlin a présenté qu'ils avaient d'abord exploré le modèle en temps réel dans des scénarios de diffusion en direct et obtenu certains résultats. En termes d'ingénierie, un lien complet a également été exploré et certaines constructions d'ingénierie de base ont été mises en œuvre. Cependant, le modèle en temps réel se concentre sur le réglage fin des scénarios en temps réel, mais plus de 80 % des scénarios sont des modèles hors ligne. Dans le processus de modélisation full-link, chaque développeur de scénario part de l'origine des données, ce qui entraîne des problèmes tels qu'un long cycle de modélisation, des effets imprévisibles et un seuil de développement élevé pour les novices. Si l'on considère le cycle en ligne d'un modèle, 80 % du temps est lié aux données, dont les fonctionnalités représentent jusqu'à 50 %. Ils ont commencé à précipiter la plateforme de fonctionnalités Feature Store.
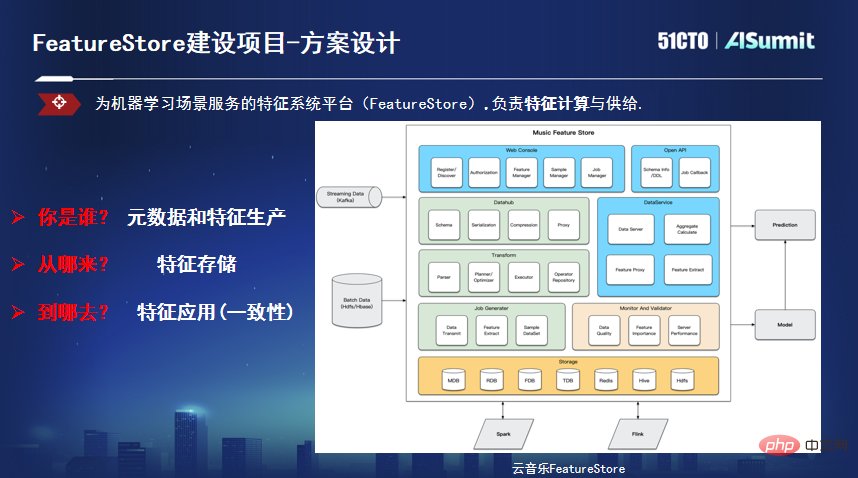
Feature Store résout principalement trois problèmes : premièrement, définir les métadonnées, unifier le lignage des fonctionnalités, le calcul et le processus push, et réaliser un lien de production de fonctionnalités efficace basé sur l'intégration par lots et par flux, deuxièmement, cibler les caractéristiques de ; fonctionnalités Effectuer une transformation pour résoudre le problème du stockage des fonctionnalités et fournir différents types de moteurs de stockage en fonction des différences de latence et de débit des scénarios d'utilisation réels. Troisièmement, résoudre le problème de cohérence des fonctionnalités, lire les données dans un format spécifié à partir d'un format unifié ; API et utilisez-la comme entrée automatique dans le modèle d'apprentissage, utilisée pour l'inférence, la formation, etc.
Huang Bing, directeur adjoint du laboratoire Big Data et intelligence artificielle du Centre de développement de logiciels de la Banque industrielle et commerciale de Chine, a souligné dans son discours d'ouverture « Construire une nouvelle infrastructure d'intelligence artificielle pour le développement innovant de la finance intelligente" La pratique MLOps de l'ICBC couvre le processus de construction et la pratique technique du système de gestion du cycle de vie complet du développement de modèles, de la livraison de modèles, de la gestion des modèles et de l'exploitation itérative des modèles.
La raison pour laquelle MLOps est nécessaire est que derrière le développement rapide de l'intelligence artificielle, de nombreuses « dettes techniques de l'IA » existantes ou potentielles ne peuvent être ignorées. Huang Bing estime que le concept de MLOps peut résoudre ces dettes techniques. « Si DevOps est un outil pour résoudre le problème de la dette technique des systèmes logiciels et que DataOps est la clé pour résoudre le problème de la dette technique des actifs de données, alors MLOps, qui est la solution. née du concept DevOps, est une machine de traitement. " Apprenez le remède à votre problème de dette technique. "
Dans le processus de construction, l'expérience pratique MLOps de l'ICBC peut être résumée en quatre points : consolider la « fondation » des capacités publiques, construire un centre de données au niveau de l'entreprise et réaliser la précipitation et le partage des données ; les seuils d'application et la construction de chaînes d'assemblage de modélisation et de services pertinentes forment un modèle de R&D d'assemblage basé sur des processus et des éléments de base, établissent une « méthode » pour l'accumulation et le partage des actifs d'IA afin de minimiser le coût de construction de l'IA et constituent la clé d'un écologie partagée et co-construite ; former des opérations de modèle La « technique » de l'itération consiste à établir un système d'exploitation de modèle piloté par les données et la valeur commerciale, qui constitue la base d'une itération continue et d'une évaluation quantitative de la qualité du modèle.
À la fin du discours, Huang Bing a formulé deux points de vue : Premièrement, les MLOps doivent être plus sûrs et plus conformes. À l'avenir, le développement de l'entreprise nécessitera de nombreux modèles pour parvenir à une prise de décision intelligente basée sur les données, ce qui entraînera davantage d'exigences au niveau de l'entreprise liées au développement, à l'exploitation et à la maintenance des modèles, au contrôle des autorisations, à la confidentialité des données, à la sécurité et à l'audit ; Deuxièmement, les MLOps doivent être combinés avec d'autres opérations. Résoudre le problème de la dette technique est un processus complexe. Les solutions DevOps, les solutions DataOps et les solutions MLOps doivent être coordonnées et interconnectées pour s'autonomiser mutuellement afin de tirer pleinement parti de tous les avantages des trois et d'obtenir l'effet « 1+1+ ». 1>3".
Selon les prévisions d'IDC, 60 % des entreprises utiliseront MLOps pour mettre en œuvre des flux de travail d'apprentissage automatique d'ici 2024. L'analyste d'IDC Sriram Subramanian a commenté un jour : "MLOps réduit la vitesse du modèle à des semaines, parfois même à des jours, tout comme l'utilisation de DevOps pour accélérer le temps moyen de création d'une application. C'est pourquoi vous avez besoin de MLOps
."Actuellement, nous sommes à un point d’inflexion d’expansion rapide de l’intelligence artificielle. En adoptant MLOps, les entreprises peuvent créer davantage de modèles, innover plus rapidement et promouvoir la mise en œuvre de l’IA plus rapidement et de manière plus rentable. Des milliers d’industries constatent et vérifient que le MLOps est en train de devenir un catalyseur de l’ampleur de l’IA d’entreprise. Pour un contenu plus passionnant, veuillez cliquez pour voir.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment utiliser le stockage cloud
Comment utiliser le stockage cloud
 Comment insérer une vidéo en HTML
Comment insérer une vidéo en HTML
 Quels sont les cycles de vie de vue3
Quels sont les cycles de vie de vue3
 attributusage
attributusage
 Que signifie STO dans la blockchain ?
Que signifie STO dans la blockchain ?
 Quelle monnaie est l'u-coin ?
Quelle monnaie est l'u-coin ?
 La différence entre une demande d'obtention et une demande de publication
La différence entre une demande d'obtention et une demande de publication
 La différence entre Win7 32 bits et 64 bits
La différence entre Win7 32 bits et 64 bits








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



