
 Périphériques technologiques
IA
Classification d'images avec apprentissage en quelques prises de vue à l'aide de PyTorch
Périphériques technologiques
IA
Classification d'images avec apprentissage en quelques prises de vue à l'aide de PyTorch
Classification d'images avec apprentissage en quelques prises de vue à l'aide de PyTorch

Ces dernières années, les modèles basés sur l'apprentissage profond ont donné de bons résultats dans des tâches telles que la détection d'objets et la reconnaissance d'images. Sur des ensembles de données de classification d'images complexes comme ImageNet, qui contient 1 000 classifications d'objets différentes, certains modèles dépassent désormais les niveaux humains. Mais ces modèles s'appuient sur un processus de formation supervisé, ils sont considérablement affectés par la disponibilité de données de formation étiquetées, et les classes que les modèles sont capables de détecter sont limitées aux classes sur lesquelles ils ont été formés.
Comme il n'y a pas suffisamment d'images étiquetées pour toutes les classes pendant la formation, ces modèles peuvent être moins utiles dans des contextes réels. Et nous voulons que le modèle soit capable de reconnaître les classes qu'il n'a pas vues lors de l'entraînement, car il est presque impossible de s'entraîner sur des images de tous les objets potentiels. Le problème pour lequel nous apprendrons à partir de quelques échantillons est appelé apprentissage en quelques coups.
Qu'est-ce que l'apprentissage en quelques étapes ?

L'apprentissage en quelques étapes est un sous-domaine de l'apprentissage automatique. Cela implique de classer de nouvelles données avec seulement quelques échantillons de formation et données de supervision. Le modèle que nous avons créé fonctionne raisonnablement bien avec seulement un petit nombre d'échantillons d'apprentissage.
Considérez le scénario suivant : Dans le domaine médical, pour certaines maladies rares, il se peut qu'il n'y ait pas suffisamment d'images radiographiques pour la formation. Pour de tels scénarios, la création d’un classificateur d’apprentissage en quelques étapes est la solution parfaite.
Variation dans de petits échantillons
Généralement, les chercheurs ont identifié quatre types :
- N-Shot Learning (NSL)
- Few-Shot Learning (FSL)
- One-Shot Learning (OSL)
- Zero-Shot Learning (ZSL)
Quand on parle de FSL, on fait généralement référence à la classification N-way-K-Shot. N représente le nombre de classes et K représente le nombre d'échantillons à former dans chaque classe. Ainsi, N-Shot Learning est considéré comme un concept plus large que tous les autres concepts. On peut dire que Few-Shot, One-Shot et Zero-Shot sont des sous-domaines de NSL. Alors que l'apprentissage zéro-shot vise à classer les classes invisibles sans aucun exemple de formation.
Dans One-Shot Learning, il n'y a qu'un seul échantillon par classe. Few-Shot propose 2 à 5 échantillons par classe, ce qui signifie que Few-Shot est une version plus flexible de One-Shot Learning.
Méthode d'apprentissage sur petits échantillons
Généralement, deux méthodes doivent être envisagées lors de la résolution du problème d'apprentissage par quelques coups :
Approche au niveau des données (DLA)
Cette stratégie est très simple, s'il n'y a pas suffisamment de données pour créer un modèle solide et éviter les sous-ajustements et les surajustements, alors davantage de données doivent être ajoutées. Pour cette raison, de nombreux problèmes de FLS peuvent être résolus en exploitant davantage de données provenant d’un ensemble de données sous-jacentes plus vaste. Une caractéristique notable de l'ensemble de données de base est qu'il lui manque les classes qui constituent notre ensemble de support pour le défi Few-Shot. Par exemple, si nous souhaitons classer une certaine espèce d’oiseau, l’ensemble de données sous-jacent peut contenir des images de nombreux autres oiseaux.
Approche au niveau des paramètres (PLA)
Du point de vue du niveau des paramètres, les échantillons d'apprentissage par quelques tirs sont relativement faciles à surajuster car ils ont généralement de grands espaces de grande dimension. Restreindre l'espace des paramètres, utiliser la régularisation et utiliser une fonction de perte appropriée aideront à résoudre ce problème. Un petit nombre d'échantillons d'apprentissage seront utilisés par le modèle pour généraliser.
Les performances peuvent être améliorées en guidant le modèle dans un large espace de paramètres. Les méthodes d'optimisation normales peuvent ne pas produire de résultats précis en raison du manque de données d'entraînement.
Pour les raisons ci-dessus, entraîner notre modèle pour trouver le meilleur chemin à travers l'espace des paramètres produit les meilleurs résultats de prédiction. Cette approche est appelée méta-apprentissage.
Algorithme de classification d'images d'apprentissage pour petits échantillons
Il existe 4 méthodes courantes d'apprentissage pour petits échantillons :
Méta-apprentissage indépendant du modèle Méta-apprentissage indépendant du modèle
Méta-apprentissage basé sur les gradients (GBML) Le principe est la base MAML. En GBML, les méta-apprenants acquièrent une expérience préalable grâce à la formation du modèle de base et à l'apprentissage des fonctionnalités partagées dans toutes les représentations de tâches. Chaque fois qu'il y a une nouvelle tâche à apprendre, le méta-apprenant est affiné en utilisant son expérience existante et la quantité minimale de nouvelles données de formation fournies par la nouvelle tâche.
Généralement, si nous initialisons les paramètres de manière aléatoire et les mettons à jour plusieurs fois, l'algorithme ne convergera pas vers de bonnes performances. MAML tente de résoudre ce problème. MAML fournit une initialisation fiable de l'apprenant des métaparamètres avec seulement quelques étapes de gradient et sans surapprentissage, afin que de nouvelles tâches puissent être apprises de manière optimale et rapide.
Les étapes sont les suivantes :
- Le méta-apprenant crée sa propre copie C au début de chaque épisode,
- C est entraîné sur cet épisode (avec l'aide du modèle de base),
- C paires Prédictions sont effectués sur l'ensemble de requêtes,
- La perte calculée à partir de ces prédictions est utilisée pour mettre à jour C,
- Cela continue jusqu'à ce que l'entraînement sur tous les épisodes soit terminé.

Le plus gros avantage de cette technique est qu'elle est considérée comme indépendante du choix de l'algorithme de méta-apprentissage. Par conséquent, les méthodes MAML sont largement utilisées dans de nombreux algorithmes d’apprentissage automatique qui nécessitent une adaptation rapide, notamment dans les réseaux de neurones profonds.
Matching Networks
La première méthode d'apprentissage métrique créée pour résoudre le problème FSL est le Matching Network (MN).
Un grand ensemble de données de base est requis lors de l'utilisation de la méthode de réseau de correspondance pour résoudre le problème d'apprentissage en quelques coups. .
Après avoir divisé cet ensemble de données en plusieurs épisodes, pour chaque épisode, le réseau de correspondance effectue les opérations suivantes :
- Chaque image de l'ensemble de support et de l'ensemble de requêtes est transmise à un CNN qui génère des fonctionnalités pour elles. L'intégration de
- requête l'image est obtenue à l'aide du modèle formé sur l'ensemble de supports pour obtenir la distance cosinus des fonctionnalités intégrées, classées par softmax
- La perte d'entropie croisée des résultats de classification est rétropropagée via CNN pour mettre à jour le modèle d'intégration de fonctionnalités
Le réseau correspondant peut être utilisé de cette manière Apprenez à créer des intégrations d'images. MN est capable de classer les photos en utilisant cette méthode sans aucune connaissance préalable particulière des catégories. Il compare simplement plusieurs instances de la classe.
Étant donné que les catégories varient d'un épisode à l'autre, le réseau de correspondance calcule les attributs d'image (caractéristiques) qui sont importants pour la distinction des catégories. Lors de l'utilisation de la classification standard, l'algorithme sélectionne les caractéristiques uniques à chaque catégorie.
Réseaux prototypiques
Le réseau prototypique (PN) est similaire au réseau correspondant. Il améliore les performances de l'algorithme grâce à quelques changements subtils. PN obtient de meilleurs résultats que MN, mais leur processus de formation est essentiellement le même, il suffit de comparer certaines intégrations d'images de requête de l'ensemble de support, mais le réseau prototype propose des stratégies différentes.
Nous devons créer un prototype de la classe en PN : l'intégration de la classe créée en faisant la moyenne des intégrations des images dans la classe. Seuls ces prototypes de classe sont ensuite utilisés pour comparer les intégrations d’images de requête. Lorsqu'il est utilisé pour des problèmes d'apprentissage à échantillon unique, il est comparable aux réseaux d'appariement.
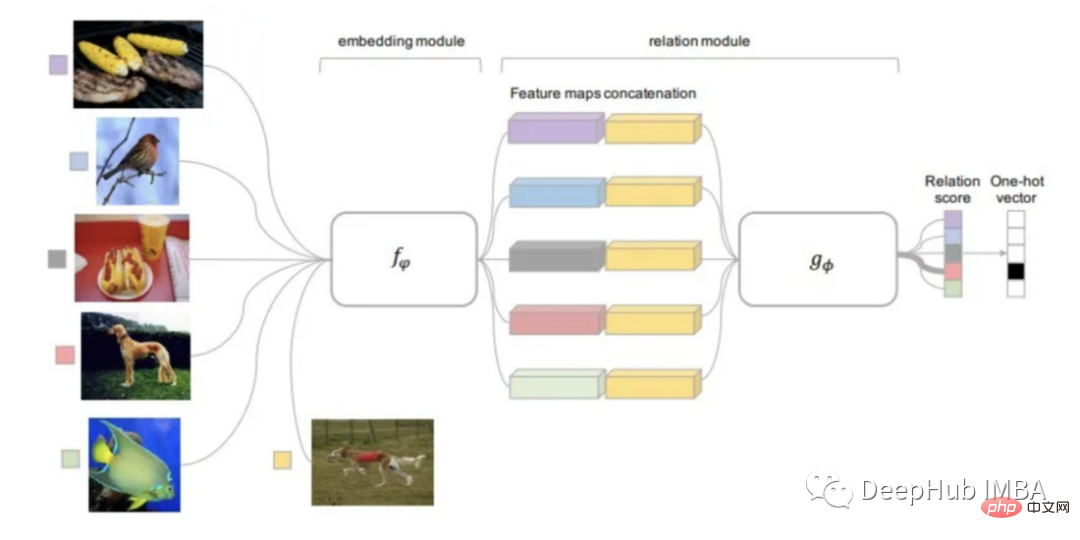
Réseau relationnel
Le réseau relationnel peut être considéré comme héritant des résultats de la recherche sur toutes les méthodes mentionnées ci-dessus. RN est basé sur les idées de PN mais contient des améliorations significatives de l'algorithme.
La fonction de distance utilisée par cette méthode est apprenable, plutôt que de la définir à l'avance comme les études précédentes. Le module de relation se trouve au-dessus du module d'intégration, qui est la partie qui calcule les intégrations et les prototypes de classe à partir de l'image d'entrée.
L'entrée du module de relation entraînable (fonction de distance) est l'intégration de l'image de requête avec le prototype de chaque classe, et la sortie est le score de relation de chaque correspondance de classe. Le score de relation est transmis via Softmax pour obtenir une prédiction.
Zero-shot learning à l'aide d'Open-AI Clip
CLIP (Contrastive Language-Image Pre-Training) est un réseau de neurones entraîné sur diverses paires (image, texte). Il peut prédire les fragments de texte les plus pertinents pour une image donnée sans être directement optimisé pour la tâche (similaire à la fonctionnalité zéro tir de GPT-2 et 3).
CLIP peut atteindre les performances du ResNet50 original sur ImageNet "zéro échantillon" et ne nécessite l'utilisation d'aucun exemple étiqueté. Il surmonte plusieurs défis majeurs en vision par ordinateur. Ci-dessous, nous utilisons Pytorch pour implémenter un modèle de classification simple.
Présentation du package
! pip install ftfy regex tqdm
! pip install git+https://github.com/openai/CLIP.gitimport numpy as np
import torch
from pkg_resources import packaging
print("Torch version:", torch.__version__)Chargement du modèle
import clipclip.available_models() # it will list the names of available CLIP modelsmodel, preprocess = clip.load("ViT-B/32")
model.cuda().eval()
input_resolution = model.visual.input_resolution
context_length = model.context_length
vocab_size = model.vocab_size
print("Model parameters:", f"{np.sum([int(np.prod(p.shape)) for p in model.parameters()]):,}")
print("Input resolution:", input_resolution)
print("Context length:", context_length)
print("Vocab size:", vocab_size)Prétraitement des images
Nous saisirons 8 exemples d'images et leurs descriptions textuelles dans le modèle et comparerons les similitudes entre les fonctionnalités correspondantes.
Le tokenizer n'est pas sensible à la casse et nous sommes libres de donner toute description textuelle appropriée.
import os
import skimage
import IPython.display
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
from collections import OrderedDict
import torch
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
# images in skimage to use and their textual descriptions
descriptions = {
"page": "a page of text about segmentation",
"chelsea": "a facial photo of a tabby cat",
"astronaut": "a portrait of an astronaut with the American flag",
"rocket": "a rocket standing on a launchpad",
"motorcycle_right": "a red motorcycle standing in a garage",
"camera": "a person looking at a camera on a tripod",
"horse": "a black-and-white silhouette of a horse",
"coffee": "a cup of coffee on a saucer"
}original_images = []
images = []
texts = []
plt.figure(figsize=(16, 5))
for filename in [filename for filename in os.listdir(skimage.data_dir) if filename.endswith(".png") or filename.endswith(".jpg")]:
name = os.path.splitext(filename)[0]
if name not in descriptions:
continue
image = Image.open(os.path.join(skimage.data_dir, filename)).convert("RGB")
plt.subplot(2, 4, len(images) + 1)
plt.imshow(image)
plt.title(f"{filename}n{descriptions[name]}")
plt.xticks([])
plt.yticks([])
original_images.append(image)
images.append(preprocess(image))
texts.append(descriptions[name])
plt.tight_layout()La visualisation des résultats est la suivante :

Nous normalisons les images, étiquetons chaque entrée de texte et exécutons la propagation avant du modèle pour obtenir les caractéristiques des images et du texte.
image_input = torch.tensor(np.stack(images)).cuda() text_tokens = clip.tokenize(["This is " + desc for desc in texts]).cuda() with torch.no_grad():
Nous normalisons les caractéristiques, calculons le produit scalaire de chaque paire et effectuons un calcul de similarité cosinus
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = text_features.cpu().numpy() @ image_features.cpu().numpy().T
count = len(descriptions)
plt.figure(figsize=(20, 14))
plt.imshow(similarity, vmin=0.1, vmax=0.3)
# plt.colorbar()
plt.yticks(range(count), texts, fontsize=18)
plt.xticks([])
for i, image in enumerate(original_images):
plt.imshow(image, extent=(i - 0.5, i + 0.5, -1.6, -0.6), origin="lower")
for x in range(similarity.shape[1]):
for y in range(similarity.shape[0]):
plt.text(x, y, f"{similarity[y, x]:.2f}", ha="center", va="center", size=12)
for side in ["left", "top", "right", "bottom"]:
plt.gca().spines[side].set_visible(False)
plt.xlim([-0.5, count - 0.5])
plt.ylim([count + 0.5, -2])
plt.title("Cosine similarity between text and image features", size=20)
Classification d'image à échantillon zéro
from torchvision.datasets import CIFAR100
cifar100 = CIFAR100(os.path.expanduser("~/.cache"), transform=preprocess, download=True)
text_descriptions = [f"This is a photo of a {label}" for label in cifar100.classes]
text_tokens = clip.tokenize(text_descriptions).cuda()
with torch.no_grad():
text_features = model.encode_text(text_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
top_probs, top_labels = text_probs.cpu().topk(5, dim=-1)
plt.figure(figsize=(16, 16))
for i, image in enumerate(original_images):
plt.subplot(4, 4, 2 * i + 1)
plt.imshow(image)
plt.axis("off")
plt.subplot(4, 4, 2 * i + 2)
y = np.arange(top_probs.shape[-1])
plt.grid()
plt.barh(y, top_probs[i])
plt.gca().invert_yaxis()
plt.gca().set_axisbelow(True)
plt.yticks(y, [cifar100.classes[index] for index in top_labels[i].numpy()])
plt.xlabel("probability")
plt.subplots_adjust(wspace=0.5)
plt.show()
Vous pouvez voir que l'effet de classification est toujours très bon OK
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Dans les domaines de l’apprentissage automatique et de la science des données, l’interprétabilité des modèles a toujours été au centre des préoccupations des chercheurs et des praticiens. Avec l'application généralisée de modèles complexes tels que l'apprentissage profond et les méthodes d'ensemble, la compréhension du processus décisionnel du modèle est devenue particulièrement importante. Explainable AI|XAI contribue à renforcer la confiance dans les modèles d'apprentissage automatique en augmentant la transparence du modèle. L'amélioration de la transparence des modèles peut être obtenue grâce à des méthodes telles que l'utilisation généralisée de plusieurs modèles complexes, ainsi que les processus décisionnels utilisés pour expliquer les modèles. Ces méthodes incluent l'analyse de l'importance des caractéristiques, l'estimation de l'intervalle de prédiction du modèle, les algorithmes d'interprétabilité locale, etc. L'analyse de l'importance des fonctionnalités peut expliquer le processus de prise de décision du modèle en évaluant le degré d'influence du modèle sur les fonctionnalités d'entrée. Estimation de l’intervalle de prédiction du modèle
 Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
En termes simples, un modèle d’apprentissage automatique est une fonction mathématique qui mappe les données d’entrée à une sortie prédite. Plus précisément, un modèle d'apprentissage automatique est une fonction mathématique qui ajuste les paramètres du modèle en apprenant à partir des données d'entraînement afin de minimiser l'erreur entre la sortie prédite et la véritable étiquette. Il existe de nombreux modèles dans l'apprentissage automatique, tels que les modèles de régression logistique, les modèles d'arbre de décision, les modèles de machines à vecteurs de support, etc. Chaque modèle a ses types de données et ses types de problèmes applicables. Dans le même temps, il existe de nombreux points communs entre les différents modèles, ou il existe une voie cachée pour l’évolution du modèle. En prenant comme exemple le perceptron connexionniste, en augmentant le nombre de couches cachées du perceptron, nous pouvons le transformer en un réseau neuronal profond. Si une fonction noyau est ajoutée au perceptron, elle peut être convertie en SVM. celui-ci
 Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Cet article présentera comment identifier efficacement le surajustement et le sous-apprentissage dans les modèles d'apprentissage automatique grâce à des courbes d'apprentissage. Sous-ajustement et surajustement 1. Surajustement Si un modèle est surentraîné sur les données de sorte qu'il en tire du bruit, alors on dit que le modèle est en surajustement. Un modèle surajusté apprend chaque exemple si parfaitement qu'il classera mal un exemple inédit/inédit. Pour un modèle surajusté, nous obtiendrons un score d'ensemble d'entraînement parfait/presque parfait et un score d'ensemble/test de validation épouvantable. Légèrement modifié : "Cause du surajustement : utilisez un modèle complexe pour résoudre un problème simple et extraire le bruit des données. Parce qu'un petit ensemble de données en tant qu'ensemble d'entraînement peut ne pas représenter la représentation correcte de toutes les données."
 L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
Dans les années 1950, l’intelligence artificielle (IA) est née. C’est à ce moment-là que les chercheurs ont découvert que les machines pouvaient effectuer des tâches similaires à celles des humains, comme penser. Plus tard, dans les années 1960, le Département américain de la Défense a financé l’intelligence artificielle et créé des laboratoires pour poursuivre son développement. Les chercheurs trouvent des applications à l’intelligence artificielle dans de nombreux domaines, comme l’exploration spatiale et la survie dans des environnements extrêmes. L'exploration spatiale est l'étude de l'univers, qui couvre l'ensemble de l'univers au-delà de la terre. L’espace est classé comme environnement extrême car ses conditions sont différentes de celles de la Terre. Pour survivre dans l’espace, de nombreux facteurs doivent être pris en compte et des précautions doivent être prises. Les scientifiques et les chercheurs pensent qu'explorer l'espace et comprendre l'état actuel de tout peut aider à comprendre le fonctionnement de l'univers et à se préparer à d'éventuelles crises environnementales.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
