
 Périphériques technologiques
IA
L'apprentissage par renforcement profond s'attaque à la conduite autonome dans le monde réel
Périphériques technologiques
IA
L'apprentissage par renforcement profond s'attaque à la conduite autonome dans le monde réel
L'apprentissage par renforcement profond s'attaque à la conduite autonome dans le monde réel

L'article arXiv « Tackling Real-World Autonomous Driving using Deep Reinforcement Learning » a été mis en ligne le 5 juillet 2022. Les auteurs viennent de Vislab de l'Université de Parme en Italie et d'Ambarella (acquisition de Vislab).

Dans une chaîne de montage de conduite autonome typique, le système de régulation et de contrôle représente les deux composants les plus critiques, dans lesquels les données récupérées par le capteur et les données traitées par l'algorithme de perception sont utilisées pour obtenir une conduite autonome sûre et confortable. comportement. En particulier, le module de planification prédit le chemin que la voiture autonome doit suivre pour effectuer les actions de haut niveau correctes, tandis que le système de contrôle effectue une série d'actions de bas niveau, contrôlant la direction, l'accélérateur et le freinage.
Ce travail propose un planificateur Deep Reinforcement Learning (DRL)sans modèle pour entraîner un réseau neuronal à prédire l'accélération et l'angle de braquage, obtenant ainsi le résultat d'un algorithme de localisation et de perception pour les véhicules autonomes. Les données pilotent un seul module de le véhicule. En particulier, le système qui a été entièrement simulé et formé peut conduire en douceur et en toute sécurité dans des environnements sans obstacle simulés et réels (zone urbaine de Palma), prouvant que le système possède de bonnes capacités de généralisation et peut également conduire dans des environnements autres que les scénarios de formation. De plus, afin de déployer le système sur de vrais véhicules autonomes et de réduire l'écart entre les performances simulées et les performances réelles, les auteurs ont également développé un module représenté par un réseau neuronal miniature capable de reproduire le comportement de l'environnement réel lors d'une formation par simulation. . Comportement dynamique de la voiture.
Au cours des dernières décennies, d'énormes progrès ont été réalisés dans l'amélioration du niveau d'automatisation des véhicules, depuis des approches simples basées sur des règles jusqu'à la mise en œuvre de systèmes intelligents basés sur l'IA. Ces systèmes visent en particulier à remédier aux principales limites des approches basées sur des règles, à savoir le manque de négociation et d'interaction avec les autres usagers de la route et la mauvaise compréhension de la dynamique de la scène.
L'apprentissage par renforcement (RL) est largement utilisé pour résoudre des tâches qui utilisent des sorties discrètes de l'espace de contrôle, telles que Go, les jeux Atari ou les échecs, ainsi que la conduite autonome dans un espace de contrôle continu. En particulier, les algorithmes RL sont largement utilisés dans le domaine de la conduite autonome pour développer des systèmes de prise de décision et d'exécution de manœuvres, tels que les changements de voie actifs, le maintien de voie, les manœuvres de dépassement, le traitement des intersections et des ronds-points, etc.
Cet article utilise une version retardée de D-A3C, qui appartient à la famille des algorithmes dits Actor-Critics. Spécialement composé de deux entités différentes : Acteurs et Critiques. Le but de l'acteur est de sélectionner les actions que l'agent doit effectuer, tandis que les critiques estiment la fonction de valeur d'état, c'est-à-dire la qualité de l'état spécifique de l'agent. En d'autres termes, les acteurs sont des distributions de probabilité π(a|s; θπ) sur les actions (où θ sont des paramètres de réseau), et les critiques sont des fonctions de valeur d'état estimées v(st; θv) = E(Rt|st), où R est Rendements attendus.
La carte haute définition développée en interne implémente le simulateur de simulation ; un exemple de la scène est présenté dans la figure a, qui est une zone de carte partielle du véritable système de test de véhicules autonomes, tandis que la figure b montre la vue environnante du perception corporelle intelligente, correspondant à 50× La zone de 50 mètres est divisée en quatre canaux : les obstacles (Figure c), l'espace carrossable (Figure d), le chemin que l'agent doit suivre (Figure e) et la ligne d'arrêt (Figure f). La carte haute définition du simulateur permet de récupérer de multiples informations sur l'environnement extérieur, telles que l'emplacement ou le nombre de voies, les limites de vitesse sur route, etc.
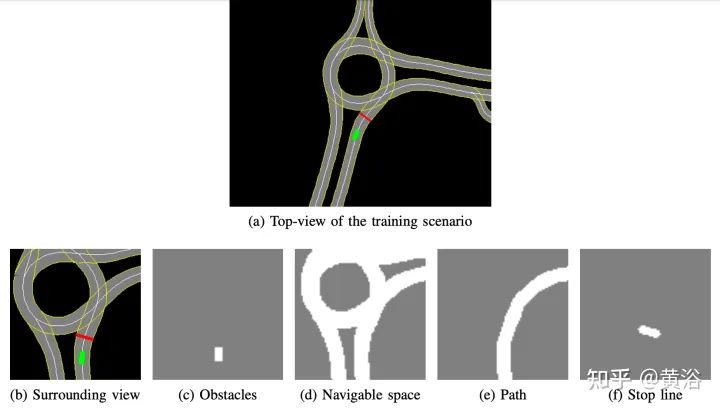
Concentrez-vous sur l'obtention d'un style de conduite fluide et sûr, de sorte que l'agent est formé à des scènes statiques, à l'exclusion des obstacles ou des autres usagers de la route, en apprenant à suivre des itinéraires et à respecter les limites de vitesse.
Utilisez le réseau neuronal comme indiqué sur la figure pour entraîner l'agent et prédire l'angle de braquage et l'accélération toutes les 100 millisecondes. Il est divisé en deux sous-modules : le premier sous-module permet de définir l'angle de braquage sa, et le deuxième sous-module permet de définir l'accélération acc. Les entrées de ces deux sous-modules sont représentées par 4 canaux (espace carrossable, chemin, obstacle et ligne d'arrêt), correspondant à la vue environnante de l'agent. Chaque canal d'entrée visuelle contient quatre images de 84 × 84 pixels pour fournir à l'agent un historique des états passés. Parallèlement à cette entrée visuelle, le réseau reçoit 5 paramètres scalaires, dont la vitesse cible (limite de vitesse sur route), la vitesse actuelle de l'agent, le rapport vitesse actuelle - vitesse cible et l'action finale liée à l'angle de braquage et à l'accélération.
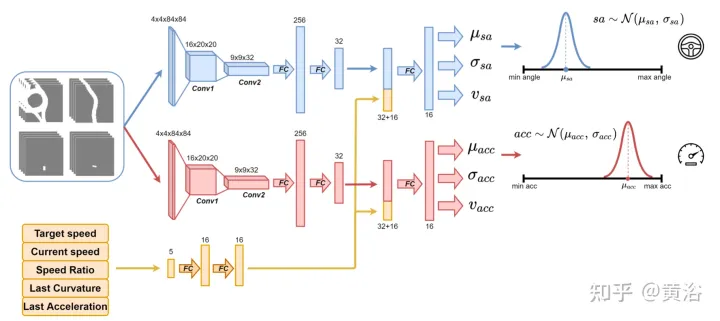
Afin d'assurer l'exploration, deux distributions gaussiennes sont utilisées pour échantillonner la sortie des deux sous-modules afin d'obtenir l'accélération relative (acc=N (μacc, σacc)) et l'angle de braquage (sa=N (μsa , σsa) ). Les écarts types σacc et σsa sont prédits et modulés par le réseau neuronal pendant la phase d'entraînement pour estimer l'incertitude du modèle. De plus, le réseau utilise deux fonctions de récompense différentes R-acc-t et R-sa-t, liées respectivement à l'accélération et à l'angle de braquage, pour générer des estimations de valeurs d'état correspondantes (vacc et vsa).
Le réseau de neurones est formé sur quatre scènes de la ville de Palma. Pour chaque scénario, plusieurs instances sont créées et les agents sont indépendants les uns des autres sur ces instances. Chaque agent suit le modèle cinématique du vélo, avec un angle de braquage de [-0,2, +0,2] et une accélération de [-2,0 m, +2,0 m]. Au début du segment, chaque agent commence à conduire à une vitesse aléatoire ([0,0, 8,0]) et suit son chemin prévu, en respectant les limitations de vitesse sur route. Les limites de vitesse sur route dans cette zone urbaine vont de 4 ms à 8,3 ms.
Enfin, puisqu'il n'y a aucun obstacle dans la scène d'entraînement, le clip peut se terminer dans l'un des états terminaux suivants :
- Objectif atteint : L'agent atteint la position cible finale.
- Conduite hors route : L'agent dépasse sa trajectoire prévue et prédit incorrectement l'angle de braquage.
- Time's Up : Le temps nécessaire pour terminer le fragment expire ; cela est principalement dû à des prévisions prudentes de l'accélération lors de la conduite en dessous de la limite de vitesse sur route.
Afin d'obtenir une stratégie permettant de conduire une voiture en douceur dans des environnements simulés et réels, la mise en forme des récompenses est cruciale pour obtenir le comportement souhaité. En particulier, deux fonctions de récompense différentes sont définies pour évaluer respectivement les deux actions : R-acc-t et R-sa-t sont respectivement liées à l'accélération et à l'angle de braquage, définies comme suit :
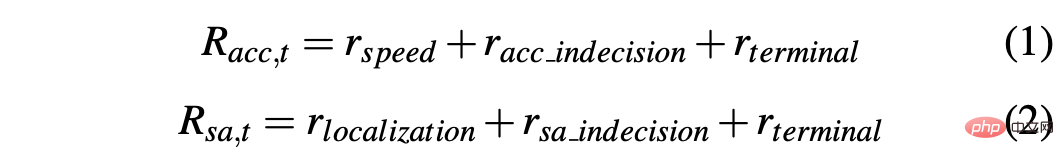
où
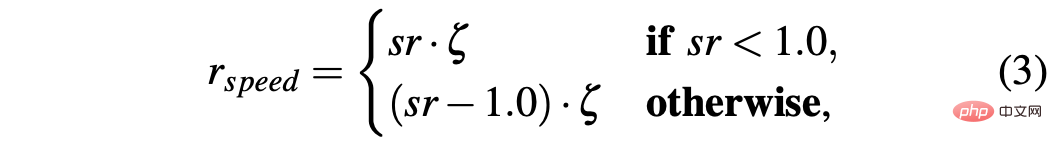
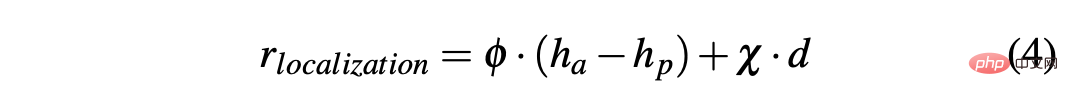
R-sa-t et R-acc-t ont tous deux un élément dans la formule pour pénaliser deux actions consécutives dont la différence d'accélération et d'angle de braquage est supérieure à un certain seuil δacc et δsa respectivement. En particulier, la différence entre deux accélérations consécutives est calculée comme suit : Δacc=|acc(t)−acc(t−1)|, tandis que rac_indecision est définie comme suit :
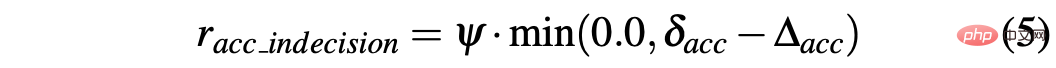
En revanche, les deux angles de braquage Le la différence entre les prédictions consécutives est calculée comme Δsa=|sa(t)−sa(t−1)|, tandis que rsa_indecision est définie comme suit :
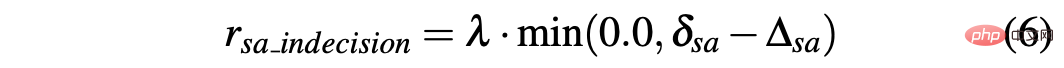
Enfin, R-acc-t et R-sa-t dépendent du Terminal états atteints par l'agent :
- Objectif atteint : l'agent atteint la position cible, donc le rterminal pour les deux récompenses est réglé sur +1,0
- Conduite hors route : l'agent s'écarte de sa trajectoire, principalement à cause de la prédiction ; de l'angle de braquage Pas précis. Par conséquent, attribuez un signal négatif de -1,0 à Rsa,t et un signal négatif de 0,0 à R-acc-t ;
- Le temps est écoulé : le temps disponible pour terminer le segment expire, principalement en raison du fait que la prédiction d'accélération de l'agent est trop longue. prudent donc, rterminal suppose −1,0 pour R-acc-t et 0,0 pour R-sa-t.
L'un des principaux problèmes associés aux simulateurs est la différence entre les données simulées et réelles, qui est causée par la difficulté de reproduire fidèlement des situations du monde réel dans le simulateur. Pour surmonter ce problème, un simulateur synthétique est utilisé pour simplifier l'entrée dans le réseau neuronal et réduire l'écart entre les données simulées et réelles. En effet, les informations contenues dans les 4 canaux (obstacles, espace de conduite, chemin et ligne d'arrêt) en entrée du réseau neuronal peuvent être facilement reproduites par des algorithmes de perception et de localisation et des cartes haute définition embarquées sur de vrais véhicules autonomes.
De plus, un autre problème lié à l'utilisation de simulateurs concerne la différence entre les deux manières dont un agent simulé exécute une action cible et une voiture autonome exécute cette commande. En fait, l’action cible calculée à l’instant t peut idéalement prendre effet immédiatement au même moment précis de la simulation. La différence est que cela ne se produit pas sur un véhicule réel, car la réalité est que de telles actions cibles seront exécutées avec une certaine dynamique, ce qui entraînera un retard d'exécution (t+δ). Par conséquent, il est nécessaire d’introduire de tels temps de réponse dans les simulations afin de former les agents sur de véritables voitures autonomes pour gérer de tels retards.
À cette fin, afin d'obtenir un comportement plus réaliste, l'agent est d'abord formé pour ajouter un filtre passe-bas au réseau neuronal que l'agent doit exécuter pour prédire l'action cible. Comme le montre la figure, la courbe bleue représente les temps de réponse idéaux et instantanés se produisant dans la simulation utilisant l'action cible (l'angle de braquage de son exemple). Ensuite, après introduction d’un filtre passe-bas, la courbe verte identifie le temps de réponse de l’agent simulé. En revanche, la courbe orange montre le comportement d’un véhicule autonome effectuant la même manœuvre de direction. Cependant, la figure montre que la différence de temps de réponse entre les véhicules simulés et réels est toujours d'actualité.
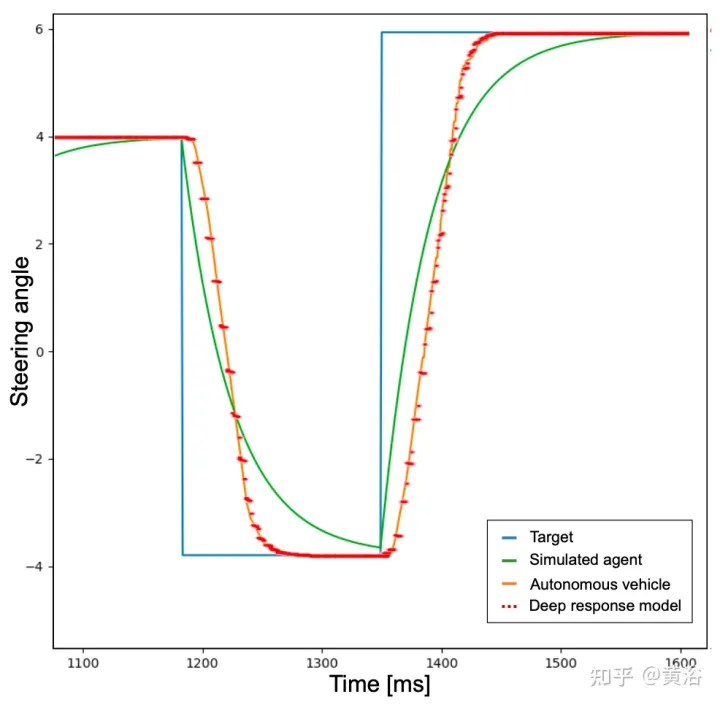
En fait, les points d'accélération et d'angle de braquage prédéfinis par le réseau neuronal ne sont pas des commandes réalisables et ne tiennent pas compte de certains facteurs, tels que l'inertie du système, le retard de l'actionneur et d'autres facteurs non idéaux. Par conséquent, afin de reproduire de la manière la plus réaliste possible la dynamique d'un véhicule réel, un modèle constitué d'un petit réseau neuronal composé de 3 couches entièrement connectées (réponse profonde) a été développé. Le graphique du comportement de réponse en profondeur est représenté par la ligne pointillée rouge dans la figure ci-dessus, et on peut remarquer qu'il est très similaire à la courbe orange représentant une vraie voiture autonome. Étant donné que la scène d'entraînement est dépourvue d'obstacles et de véhicules de circulation, le problème décrit est plus prononcé pour l'activité d'angle de braquage, mais la même idée a été appliquée à la sortie d'accélération.
Entraînez un modèle de réponse profonde à l'aide d'un ensemble de données collectées sur une voiture autonome, où les entrées correspondent aux commandes données au véhicule par le conducteur humain (pression de l'accélérateur et tours de volant) et les sorties correspondent à l'accélérateur du véhicule. , le freinage et le virage, qui peuvent être effectués à l'aide d'un GPS, d'un compteur kilométrique ou d'une autre mesure technique. De cette manière, l’intégration de tels modèles dans un simulateur permet d’obtenir un système plus évolutif qui reproduit le comportement des véhicules autonomes. Le module de réponse en profondeur est donc indispensable à la correction de l'angle de braquage, mais même de manière moins évidente, il est nécessaire à l'accélération, et cela deviendra bien visible avec l'introduction d'obstacles.
Deux stratégies différentes ont été testées sur des données réelles pour vérifier l'impact du modèle de réponse profonde sur le système. Vérifiez ensuite que le véhicule suit correctement le chemin et respecte les limites de vitesse dérivées de la carte HD. Enfin, il est prouvé que la pré-entraînement du réseau neuronal via l'Imitation Learning peut réduire considérablement la durée totale de l'entraînement.
La stratégie est la suivante :
- Stratégie 1 : Ne pas utiliser le modèle de réponse profonde pour l'entraînement, mais utiliser un filtre passe-bas pour simuler la réponse du véhicule réel à l'action cible.
- Stratégie 2 : Assurer une dynamique plus réaliste en introduisant un modèle de réponse profonde pour la formation.
Les tests effectués dans les simulations ont produit de bons résultats pour les deux stratégies. En fait, que ce soit dans une scène entraînée ou dans une zone de carte non entraînée, l'agent peut atteindre son objectif avec un comportement fluide et sûr 100 % du temps.
En testant la stratégie dans des scénarios réels, différents résultats ont été obtenus. La stratégie 1 ne peut pas gérer la dynamique du véhicule et effectue les actions prédites différemment de l'agent dans la simulation ; de cette manière, la stratégie 1 observera des états inattendus de ses prédictions, conduisant à un comportement bruyant sur le véhicule autonome et à des comportements inconfortables.
Ce comportement affecte également la fiabilité du système, et en fait, une assistance humaine est parfois nécessaire pour éviter que les voitures autonomes ne sortent de la route.
En revanche, dans tous les tests réels de voitures autonomes, la stratégie 2 ne nécessite jamais qu'un humain prenne le relais, connaissant la dynamique du véhicule et comment le système évoluera pour prédire les actions. Les seules situations qui nécessitent une intervention humaine sont l'évitement des autres usagers de la route ; cependant, ces situations ne sont pas considérées comme des échecs car les deux stratégies 1 et 2 sont entraînées dans des scénarios sans obstacle.
Pour mieux comprendre la différence entre la stratégie 1 et la stratégie 2, voici l'angle de braquage prédit par le réseau neuronal et la distance par rapport à la voie centrale dans une courte fenêtre de tests réels. On peut remarquer que les deux stratégies se comportent complètement différemment. La stratégie 1 (courbe bleue) est bruyante et peu sûre par rapport à la stratégie 2 (courbe rouge), ce qui prouve que le module de réponse profonde est important pour le déploiement sur des véhicules véritablement autonomes. .
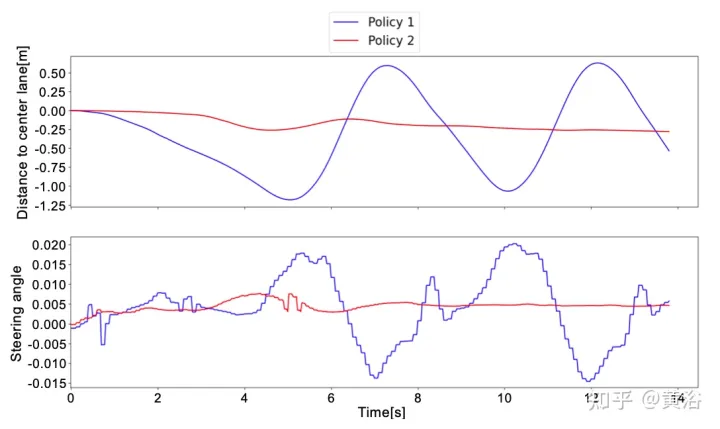
Pour surmonter les limites du RL, qui nécessite des millions de segments pour atteindre la solution optimale, un pré-entraînement est effectué via l'apprentissage par imitation (IL). De plus, même si la tendance en IL est de former de grands modèles, le même petit réseau neuronal (~ 1 million de paramètres) est utilisé, car l'idée est de continuer à former le système à l'aide du framework RL pour garantir plus de robustesse et de capacités de généralisation. De cette façon, l’utilisation des ressources matérielles n’est pas augmentée, ce qui est crucial compte tenu d’une éventuelle future formation multi-agents.
L'ensemble de données utilisé dans la phase de formation IL est généré par des agents simulés qui suivent une approche du mouvement basée sur des règles. En particulier, pour le virage, un pur algorithme de suivi de poursuite est utilisé, où l'agent vise à se déplacer le long d'un waypoint spécifique. Utilisez plutôt le modèle IDM pour contrôler l’accélération longitudinale de l’agent.
Pour créer l'ensemble de données, un agent basé sur des règles a été déplacé sur quatre scènes d'entraînement, enregistrant les paramètres scalaires et quatre entrées visuelles toutes les 100 millisecondes. Au lieu de cela, le résultat est donné par l’algorithme de poursuite pure et le modèle IDM.
Les deux contrôles horizontaux et verticaux correspondant à la sortie représentent simplement des tuples (μacc, μsa). Par conséquent, pendant la phase de formation IL, les valeurs de l'écart type (σacc, σsa) ne sont pas estimées, ni les fonctions de valeur (vacc, vsa). Ces fonctionnalités et le module de réponse en profondeur sont appris au cours de la phase de formation IL+RL.
Comme le montre la figure, il montre l'entraînement du même réseau neuronal à partir de la phase de pré-entraînement (courbe bleue, IL+RL), et le compare aux résultats RL (courbe rouge, RL pur) dans quatre cas . Même si la formation IL+RL nécessite moins de temps que la RL pure et que la tendance est plus stable, les deux méthodes obtiennent de bons taux de réussite (Figure a).
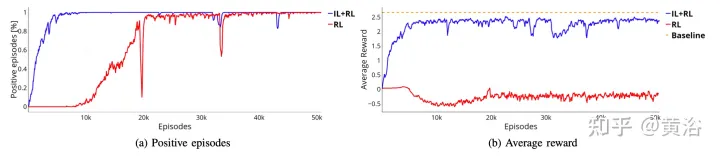
De plus, la courbe de récompense présentée dans la figure b prouve que la politique obtenue en utilisant l'approche RL pure (courbe rouge) n'atteint même pas la solution acceptable pour plus de temps de formation, alors que la politique IL+RL y parvient en quelques fragments Solution optimale (courbe bleue sur la figure b). Dans ce cas, la solution optimale est représentée par la ligne pointillée orange. Cette référence représente la récompense moyenne obtenue par un agent simulé exécutant 50 000 segments dans 4 scénarios. L'agent simulé suit les règles déterministes, qui sont les mêmes que celles utilisées pour collecter l'ensemble de données de pré-entraînement IL, c'est-à-dire que la règle de poursuite pure est utilisée pour la flexion et la règle IDM pour l'accélération longitudinale. L’écart entre les deux approches pourrait être encore plus prononcé, les systèmes d’entraînement étant capables d’effectuer des manœuvres plus complexes dans lesquelles une interaction intelligence-corps peut être requise.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Le premier article pilote et clé présente principalement plusieurs systèmes de coordonnées couramment utilisés dans la technologie de conduite autonome, et comment compléter la corrélation et la conversion entre eux, et enfin construire un modèle d'environnement unifié. L'objectif ici est de comprendre la conversion du véhicule en corps rigide de caméra (paramètres externes), la conversion de caméra en image (paramètres internes) et la conversion d'image en unité de pixel. La conversion de 3D en 2D aura une distorsion, une traduction, etc. Points clés : Le système de coordonnées du véhicule et le système de coordonnées du corps de la caméra doivent être réécrits : le système de coordonnées planes et le système de coordonnées des pixels Difficulté : la distorsion de l'image doit être prise en compte. La dé-distorsion et l'ajout de distorsion sont compensés sur le plan de l'image. 2. Introduction Il existe quatre systèmes de vision au total : système de coordonnées du plan de pixels (u, v), système de coordonnées d'image (x, y), système de coordonnées de caméra () et système de coordonnées mondiales (). Il existe une relation entre chaque système de coordonnées,
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 Problèmes de conception des fonctions de récompense dans l'apprentissage par renforcement
Oct 09, 2023 am 11:58 AM
Problèmes de conception des fonctions de récompense dans l'apprentissage par renforcement
Oct 09, 2023 am 11:58 AM
Problèmes de conception de fonctions de récompense dans l'apprentissage par renforcement Introduction L'apprentissage par renforcement est une méthode qui apprend des stratégies optimales grâce à l'interaction entre un agent et l'environnement. Dans l’apprentissage par renforcement, la conception de la fonction de récompense est cruciale pour l’effet d’apprentissage de l’agent. Cet article explorera les problèmes de conception des fonctions de récompense dans l'apprentissage par renforcement et fournira des exemples de code spécifiques. Le rôle de la fonction de récompense et de la fonction de récompense cible constituent une partie importante de l'apprentissage par renforcement et sont utilisés pour évaluer la valeur de récompense obtenue par l'agent dans un certain état. Sa conception aide à guider l'agent pour maximiser la fatigue à long terme en choisissant les actions optimales.
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
