
 Périphériques technologiques
IA
La dernière architecture profonde pour la détection de cibles a la moitié des paramètres et est 3 fois plus rapide +
Périphériques technologiques
IA
La dernière architecture profonde pour la détection de cibles a la moitié des paramètres et est 3 fois plus rapide +
La dernière architecture profonde pour la détection de cibles a la moitié des paramètres et est 3 fois plus rapide +

Brève introduction
Les auteurs de la recherche proposent Matrix Net (xNet), une nouvelle architecture profonde pour la détection d'objets. Les xNets mappent des objets de différentes dimensions et proportions dans des couches de réseau, où les objets sont presque uniformes en taille et en proportion au sein de la couche. Par conséquent, les xNets fournissent une architecture prenant en compte la taille et les proportions. Les chercheurs utilisent xNets pour améliorer la détection de cibles basée sur des points clés. La nouvelle architecture atteint une efficacité temporelle plus élevée que tout autre détecteur à tir unique, avec 47,8 mAP sur l'ensemble de données MS COCO, tout en utilisant la moitié des paramètres et en étant 3 fois plus rapide à former que le meilleur cadre suivant.
Affichage simple des résultats

Comme le montre la figure ci-dessus, les paramètres et l'efficacité de xNet sont bien supérieurs à ceux des autres modèles. Parmi eux, FSAF a le meilleur effet parmi les détecteurs basés sur une ancre, surpassant le RetinaNet classique. Le modèle proposé par les chercheurs surpasse toutes les autres architectures mono-coup avec un nombre similaire de paramètres.
Contexte et situation actuelle
La détection d'objets est l'une des tâches les plus étudiées en vision par ordinateur, avec de nombreuses applications à d'autres tâches de vision telles que le suivi d'objets, la segmentation d'instances et le sous-titrage d'images. Les structures de détection d'objets peuvent être divisées en deux catégories : détecteur à un coup et détecteur à deux étages. Les détecteurs à deux étages utilisent un réseau de proposition de région pour trouver un nombre fixe d'objets candidats, puis utilisent un second réseau pour prédire le score de chaque candidat et améliorer son cadre de délimitation.
Algorithmes courants en deux étapes

Les détecteurs à un coup peuvent également être divisés en deux catégories : les détecteurs basés sur des ancres et les détecteurs basés sur des points clés. Les détecteurs basés sur des ancres contiennent de nombreuses boîtes englobantes d'ancres, puis prédisent le décalage et la classe de chaque modèle. L'architecture basée sur l'ancre la plus célèbre est RetinaNet, qui propose une fonction de perte focale pour aider à corriger le déséquilibre de classe des boîtes englobantes d'ancre. Le détecteur basé sur une ancre le plus performant est le FSAF. FSAF intègre des sorties basées sur une ancre avec des têtes de sortie sans ancre pour améliorer encore les performances.
D'autre part, le détecteur basé sur les points clés prédit la carte thermique pour les coins supérieur gauche et inférieur droit et les fait correspondre à l'aide de l'intégration de fonctionnalités. Le détecteur original basé sur les points clés est CornerNet, qui utilise une couche de regroupement de coeners spéciale pour détecter avec précision des objets de différentes tailles. Depuis, Centerne a grandement amélioré l’architecture CornerNet en prédisant les centres et les coins des objets.
Matrix Nets
La figure ci-dessous montre les réseaux matriciels (xNets), qui utilisent des matrices hiérarchiques pour modéliser des cibles de différentes tailles et rapports transversaux de cluster, où chaque entrée i, j dans la matrice représente une couche li, j, la le sous-échantillonnage de la largeur de la couche l1,1 dans le coin supérieur gauche de la matrice est de 2 ^ (i-1), et la hauteur est sous-échantillonnée de 2 ^ (j-1). Les couches diagonales sont des couches carrées de différentes tailles, équivalentes à un FPN, tandis que les couches hors diagonale sont des couches rectangulaires (ceci est unique aux xNets). La couche l1,1 est la plus grande couche. La largeur de la couche est réduite de moitié pour chaque pas vers la droite et la hauteur est réduite de moitié pour chaque pas vers la droite.

Par exemple, la couche l3,4 fait la moitié de la largeur de la couche l3,3. Les calques diagonaux modélisent les objets dont les proportions sont proches du carré, tandis que les calques non diagonaux modélisent les objets dont les proportions ne sont pas proches du carré. Calques proches du coin supérieur droit ou inférieur gauche des objets du modèle matriciel avec des proportions extrêmement élevées ou faibles. De telles cibles sont très rares, elles peuvent donc être élaguées pour améliorer l’efficacité.
1, Génération de couches
La couche matricielle de génération est une étape critique car elle affecte le nombre de paramètres du modèle. Plus il y a de paramètres, plus l’expression du modèle est forte et plus le problème d’optimisation est difficile. Les chercheurs choisissent donc d’introduire le moins de nouveaux paramètres possible. Les couches diagonales peuvent être obtenues à partir de différentes étapes du squelette ou à l'aide d'un cadre pyramidal de fonctionnalités. La couche triangulaire supérieure est obtenue en appliquant une série de convolutions partagées 3x3 avec une foulée de 1x2 sur la couche diagonale. De même, la couche inférieure gauche est obtenue en utilisant une convolution partagée 3x3 avec une foulée de 2x1. Les paramètres sont partagés entre toutes les convolutions de sous-échantillonnage afin de minimiser le nombre de nouveaux paramètres.
2. Plage de couches
Chaque couche de la matrice modélise une cible avec une certaine largeur et hauteur, nous devons donc définir la plage de largeur et de hauteur attribuée à la cible pour chaque couche de la matrice. La plage doit refléter le champ récepteur du vecteur de caractéristiques de la couche matricielle. Chaque pas vers la droite dans la matrice double effectivement le champ récepteur dans la dimension horizontale, et chaque pas double le champ récepteur dans la dimension verticale. Ainsi, à mesure que nous nous déplaçons vers la droite ou vers le bas dans la matrice, la plage de largeur ou de hauteur doit doubler. Une fois la plage de la première couche l1,1 définie, nous pouvons utiliser les règles ci-dessus pour générer des plages pour le reste de la couche matricielle.
3. Avantages des Matrix Nets
Le principal avantage des Matrix Nets est qu'ils permettent aux noyaux de convolution carrés de collecter avec précision des informations sur différents rapports d'aspect. Dans les modèles de détection d'objets traditionnels, tels que RetinaNet, un noyau de convolution carrée est requis pour générer différents rapports d'aspect et échelles. Ceci est contre-intuitif car différents aspects du cadre de délimitation nécessitent des arrière-plans différents. Dans Matrix Nets, étant donné que le contexte de chaque couche matricielle change, le même noyau de convolution carrée peut être utilisé pour des cadres de délimitation de différentes échelles et rapports d'aspect.
Étant donné que la taille cible est presque uniforme au sein de sa couche désignée, la plage dynamique de largeur et de hauteur est plus petite par rapport à d'autres architectures (telles que FPN). Par conséquent, régresser la hauteur et la largeur de la cible deviendra un problème d’optimisation plus simple. Enfin, Matrix Nets peut être utilisé comme n'importe quelle architecture de détection d'objets, détecteur basé sur des ancres ou des points clés, à un ou deux coups.
Les Matrix Nets sont utilisés pour la détection basée sur les points clés
Lorsque CornerNet a été proposé, il devait remplacer la détection basée sur l'ancre. Il utilisait une paire de coins (coin supérieur gauche et coin inférieur droit) pour. Prédire les boîtes englobantes. Pour chaque coin, CornerNet prédit les cartes thermiques, les décalages et les intégrations. 
L'image ci-dessus est le cadre de détection de cible basé sur des points clés - KP-xNet, qui contient 4 étapes.
- (a-b) : L'épine dorsale de xNet est utilisée
- (c) : Le sous-réseau de sortie partagé est utilisé, et pour chaque couche matricielle, la carte thermique et le décalage du coin supérieur gauche et inférieur droit ; les coins sont des quantités prédites et effectuez une prédiction du point central sur ceux-ci dans le calque cible ;
- (d) : utilisez la prédiction du point central pour faire correspondre les coins du même calque, puis combinez la sortie de tous les calques avec des valeurs non douces ; suppression maximale pour obtenir le résultat final.
Résultats expérimentaux
Le tableau suivant montre les résultats sur l'ensemble de données MS COCO :

Les chercheurs ont également comparé le modèle nouvellement proposé avec d'autres modèles sur différents squelettes en fonction du nombre de paramètres. Dans la première figure, nous constatons que KP-xNet surpasse toutes les autres structures à tous les niveaux de paramètres. Les chercheurs pensent que cela est dû au fait que KP-xNet utilise une architecture prenant en compte l'échelle et les proportions.
Adresse papier : https://arxiv.org/pdf/1908.04646.pdf
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



![Comment utiliser l'effet de profondeur sur iPhone [2023]](https://img.php.cn/upload/article/000/465/014/169410031113297.png?x-oss-process=image/resize,m_fill,h_207,w_330) Comment utiliser l'effet de profondeur sur iPhone [2023]
Sep 07, 2023 pm 11:25 PM
Comment utiliser l'effet de profondeur sur iPhone [2023]
Sep 07, 2023 pm 11:25 PM
S'il y a une chose que vous pouvez distinguer comme différente sur un iPhone, c'est le nombre d'options de personnalisation dont vous disposez lorsque vous gérez l'écran de verrouillage de votre iPhone. Parmi les options, il y a la fonction d'effets de profondeur, qui donne l'impression que votre fond d'écran interagit avec le widget horloge de l'écran de verrouillage. Nous vous expliquerons l'effet de profondeur, quand et où vous pouvez l'appliquer et comment l'utiliser sur votre iPhone. Quel est l’effet de profondeur sur iPhone ? Lorsque vous ajoutez un fond d'écran avec différents éléments, l'iPhone le divise en plusieurs couches de profondeur. Pour ce faire, iOS utilise un moteur neuronal intégré pour détecter les informations de profondeur dans les fonds d'écran, séparant ainsi le sujet sur lequel vous souhaitez mettre au point des autres éléments de l'arrière-plan sélectionné. Cela créera un effet sympa où le personnage principal du fond d'écran
 Analyse comparative des architectures de deep learning
May 17, 2023 pm 04:34 PM
Analyse comparative des architectures de deep learning
May 17, 2023 pm 04:34 PM
Le concept d'apprentissage profond est né de la recherche sur les réseaux de neurones artificiels. Un perceptron multicouche contenant plusieurs couches cachées est une structure d'apprentissage profond. L'apprentissage profond combine des fonctionnalités de bas niveau pour former des représentations de haut niveau plus abstraites afin de caractériser des catégories ou des caractéristiques de données. Il est capable de découvrir des représentations de fonctionnalités distribuées de données. L'apprentissage profond est un type d'apprentissage automatique, et l'apprentissage automatique est le seul moyen d'atteindre l'intelligence artificielle. Alors, quelles sont les différences entre les différentes architectures de systèmes d’apprentissage profond ? 1. Réseau entièrement connecté (FCN) Un réseau entièrement connecté (FCN) se compose d'une série de couches entièrement connectées, chaque neurone de chaque couche étant connecté à chaque neurone d'une autre couche. Son principal avantage est qu'il est « indépendant de la structure », c'est-à-dire qu'aucune hypothèse particulière concernant l'entrée n'est requise. Bien que cette agnostique structurelle rende la
 Annotation de cadre de délimitation redondant multi-grille pour une détection précise des objets
Jun 01, 2024 pm 09:46 PM
Annotation de cadre de délimitation redondant multi-grille pour une détection précise des objets
Jun 01, 2024 pm 09:46 PM
1. Introduction Actuellement, les principaux détecteurs d'objets sont des réseaux à deux étages ou à un étage basés sur le réseau de classificateurs de base réutilisé du Deep CNN. YOLOv3 est l'un de ces détecteurs à un étage de pointe bien connus qui reçoit une image d'entrée et la divise en une matrice de grille de taille égale. Les cellules de grille avec des centres cibles sont chargées de détecter des cibles spécifiques. Ce que je partage aujourd'hui est une nouvelle méthode mathématique qui alloue plusieurs grilles à chaque cible pour obtenir une prédiction précise et précise du cadre de délimitation. Les chercheurs ont également proposé une amélioration efficace des données par copier-coller hors ligne pour la détection des cibles. La méthode nouvellement proposée surpasse considérablement certains détecteurs d’objets de pointe actuels et promet de meilleures performances. 2. Le réseau de détection de cibles en arrière-plan est conçu pour utiliser
 Nouveau SOTA pour la détection de cibles : YOLOv9 sort et la nouvelle architecture redonne vie à la convolution traditionnelle
Feb 23, 2024 pm 12:49 PM
Nouveau SOTA pour la détection de cibles : YOLOv9 sort et la nouvelle architecture redonne vie à la convolution traditionnelle
Feb 23, 2024 pm 12:49 PM
Dans le domaine de la détection de cibles, YOLOv9 continue de progresser dans le processus de mise en œuvre en adoptant de nouvelles architectures et méthodes, il améliore efficacement l'utilisation des paramètres de la convolution traditionnelle, ce qui rend ses performances bien supérieures à celles des produits de la génération précédente. Plus d'un an après la sortie officielle de YOLOv8 en janvier 2023, YOLOv9 est enfin là ! Depuis que Joseph Redmon, Ali Farhadi et d’autres ont proposé le modèle YOLO de première génération en 2015, les chercheurs dans le domaine de la détection de cibles l’ont mis à jour et itéré à plusieurs reprises. YOLO est un système de prédiction basé sur des informations globales d'images et les performances de son modèle sont continuellement améliorées. En améliorant continuellement les algorithmes et les technologies, les chercheurs ont obtenu des résultats remarquables, rendant YOLO de plus en plus puissant dans les tâches de détection de cibles.
 Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.
Jun 14, 2023 pm 01:43 PM
Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.
Jun 14, 2023 pm 01:43 PM
Il y a quelque temps, un tweet soulignant l'incohérence entre le schéma d'architecture du Transformer et le code de l'article de l'équipe Google Brain "AttentionIsAllYouNeed" a déclenché de nombreuses discussions. Certains pensent que la découverte de Sebastian était une erreur involontaire, mais elle est aussi surprenante. Après tout, compte tenu de la popularité du document Transformer, cette incohérence aurait dû être mentionnée mille fois. Sebastian Raschka a déclaré en réponse aux commentaires des internautes que le code « le plus original » était effectivement cohérent avec le schéma d'architecture, mais que la version du code soumise en 2017 a été modifiée, mais que le schéma d'architecture n'a pas été mis à jour en même temps. C’est aussi la cause profonde des discussions « incohérentes ».
 Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Les modèles d'apprentissage profond pour les tâches de vision (telles que la classification d'images) sont généralement formés de bout en bout avec des données provenant d'un seul domaine visuel (telles que des images naturelles ou des images générées par ordinateur). Généralement, une application qui effectue des tâches de vision pour plusieurs domaines doit créer plusieurs modèles pour chaque domaine distinct et les former indépendamment. Les données ne sont pas partagées entre différents domaines. Lors de l'inférence, chaque modèle gérera un domaine spécifique. Même s'ils sont orientés vers des domaines différents, certaines caractéristiques des premières couches entre ces modèles sont similaires, de sorte que la formation conjointe de ces modèles est plus efficace. Cela réduit la latence et la consommation d'énergie, ainsi que le coût de la mémoire lié au stockage de chaque paramètre du modèle. Cette approche est appelée apprentissage multidomaine (MDL). De plus, les modèles MDL peuvent également surpasser les modèles simples.
 Quelle est l'architecture et le principe de fonctionnement de Spring Data JPA ?
Apr 17, 2024 pm 02:48 PM
Quelle est l'architecture et le principe de fonctionnement de Spring Data JPA ?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA est basé sur l'architecture JPA et interagit avec la base de données via le mappage, l'ORM et la gestion des transactions. Son référentiel fournit des opérations CRUD et les requêtes dérivées simplifient l'accès à la base de données. De plus, il utilise le chargement paresseux pour récupérer les données uniquement lorsque cela est nécessaire, améliorant ainsi les performances.
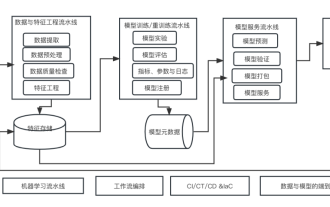 Dix éléments de l'architecture du système d'apprentissage automatique
Apr 13, 2023 pm 11:37 PM
Dix éléments de l'architecture du système d'apprentissage automatique
Apr 13, 2023 pm 11:37 PM
Nous vivons une ère d’autonomisation de l’IA, et l’apprentissage automatique est un moyen technique important pour y parvenir. Alors, existe-t-il une architecture universelle de système d’apprentissage automatique ? Dans le champ cognitif des programmeurs expérimentés, tout n'est rien, notamment pour l'architecture système. Cependant, il est possible de créer une architecture de système d'apprentissage automatique évolutive et fiable si elle est applicable à la plupart des systèmes ou cas d'utilisation basés sur l'apprentissage automatique. Du point de vue du cycle de vie du machine learning, cette architecture dite universelle couvre les étapes clés du machine learning, du développement de modèles de machine learning au déploiement de systèmes de formation et de systèmes de services dans des environnements de production. Nous pouvons essayer de décrire une telle architecture de système d’apprentissage automatique à partir des dimensions de 10 éléments. 1.
