
 Périphériques technologiques
IA
Créez des modèles d'apprentissage automatique avec PySpark ML
Périphériques technologiques
IA
Créez des modèles d'apprentissage automatique avec PySpark ML
Créez des modèles d'apprentissage automatique avec PySpark ML

Spark est un framework open source conçu pour les requêtes interactives, l'apprentissage automatique et les charges de travail en temps réel, et PySpark est une bibliothèque pour Python utilisant Spark.
PySpark est un excellent langage pour effectuer une analyse exploratoire des données à grande échelle, créer des pipelines d'apprentissage automatique et créer des ETL pour les plates-formes de données. Si vous êtes déjà familier avec des bibliothèques comme Python et Pandas, PySpark est un excellent langage pour apprendre et créer des analyses et des pipelines plus évolutifs.
Le but de cet article est de montrer comment créer un modèle d'apprentissage automatique à l'aide de PySpark.
Conda crée un environnement virtuel python
conda gère presque tous les outils et packages tiers en tant que packages, même python et conda eux-mêmes. Anaconda est une collection packagée, préinstallée avec conda, une certaine version de python, divers packages, etc.
1. Installez Anaconda.
Ouvrez la ligne de commande et entrez conda -V pour vérifier s'il est installé et la version actuelle de conda.
Installez la version par défaut de Python via Anaconda 3.6 correspond à Anaconda3-5.2, et python 3.7 après 5.3.
(https://repo.anaconda.com/archive/)
2.Commandes couramment utilisées dans conda
1) Vérifiez quels packages sont installés
conda list
2) Vérifiez quels environnements virtuels existent actuellement
conda env list <br>conda info -e
3) Cochez Mettre à jour le conda
conda update conda
3 actuel. Python crée un environnement virtuel
conda create -n your_env_name python=x.x
La commande anaconda crée un environnement virtuel avec la version python x.x et nomme your_env_name. Votre fichier_env_name se trouve sous le fichier envs dans le répertoire d'installation d'Anaconda.
4. Activez ou changez d'environnement virtuel
Ouvrez la ligne de commande et entrez python --version pour vérifier la version actuelle de Python.
Linux:source activate your_env_nam<br>Windows: activate your_env_name
5. Installez des packages supplémentaires dans l'environnement virtuel
conda install -n your_env_name [package]
6 Fermez l'environnement virtuel
(c'est-à-dire quittez l'environnement actuel et revenez à la version python par défaut dans l'environnement PATH)
deactivate env_name<br># 或者`activate root`切回root环境<br>Linux下:source deactivate
7. environnement
conda remove -n your_env_name --all
8. Supprimer un certain package dans l'horloge de l'environnement
conda remove --name $your_env_name$package_name
9. Configurer un miroir domestique
Le serveur de http://Anaconda.org est à l'étranger Lors de l'installation de plusieurs packages, la vitesse de téléchargement de conda est souvent. très lent. La source miroir Tsinghua TUNA a le miroir de l'entrepôt Anaconda, ajoutez-le simplement à la configuration conda :
# 添加Anaconda的TUNA镜像<br>conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/<br><br># 设置搜索时显示通道地址<br>conda config --set show_channel_urls yes
10 Restaurer le miroir par défaut
conda config --remove-key channels
Installer PySpark
Le processus d'installation de PySpark est aussi simple que les autres packages python ( comme Pandas, Numpy, scikit-learn).
Une chose importante est de vous assurer d’abord que Java est installé sur votre machine. Vous pouvez ensuite exécuter PySpark sur votre notebook jupyter.

Exploration des données
Nous utilisons l'ensemble de données sur le diabète, qui est associé à l'Institut national du diabète et des maladies digestives et rénales. L'objectif de la classification est de prédire si un patient est diabétique (oui/non).
from pyspark.sql import SparkSession<br>spark = SparkSession.builder.appName('ml-diabetes').getOrCreate()<br>df = spark.read.csv('diabetes.csv', header = True, inferSchema = True)<br>df.printSchema()L'ensemble de données se compose de plusieurs variables prédictives médicales et d'une variable cible Résultat. Les variables prédictives incluent le nombre de grossesses de la patiente, l'IMC, les niveaux d'insuline, l'âge, etc.
- Grossesses : nombre de grossesses
- Glucose : concentration de glucose dans le sang obtenue lors du test oral de tolérance au glucose dans les 2 heures
- Pression artérielle : tension artérielle diastolique (mm Hg)
- Épaisseur de la peau : épaisseur du pli cutané du triceps (mm)
- Insuline : 2 heures Insuline sérique (mu U/ml)
- IMC : indice de masse corporelle (unité de poids kg/(unité de taille m)²)
- diabespedigreefonction : fonction du spectre du diabète
- Âge : âge (année)
- Résultat : variable de classe ( 0 ou 1)
- Variables d'entrée : glucose, tension artérielle, IMC, âge, grossesse, insuline, épaisseur de la peau, fonction du spectre du diabète.
- Variable de sortie : Résultat.
Regardez les cinq premières observations. Les dataframes Pandas sont plus jolies que Spark DataFrame.show().
import pandas as pd<br>pd.DataFrame(df.take(5), <br> columns=df.columns).transpose()
Dans PySpark, vous pouvez afficher des données à l'aide du DataFrame toPandas() de Pandas.
df.toPandas()

Vérifiez que la classe est complètement équilibrée !
df.groupby('Outcome').count().toPandas()
Statistiques descriptives
numeric_features = [t[0] for t in df.dtypes if t[1] == 'int']<br>df.select(numeric_features)<br>.describe()<br>.toPandas()<br>.transpose()
Corrélation entre les variables indépendantes
from pandas.plotting import scatter_matrix<br>numeric_data = df.select(numeric_features).toPandas()<br><br>axs = scatter_matrix(numeric_data, figsize=(8, 8));<br><br># Rotate axis labels and remove axis ticks<br>n = len(numeric_data.columns)<br>for i in range(n):<br>v = axs[i, 0]<br>v.yaxis.label.set_rotation(0)<br>v.yaxis.label.set_ha('right')<br>v.set_yticks(())<br>h = axs[n-1, i]<br>h.xaxis.label.set_rotation(90)<br>h.set_xticks(())
Préparation des données et ingénierie des fonctionnalités
Dans cette partie, nous supprimerons les colonnes inutiles et remplirons les valeurs manquantes. Enfin, les fonctionnalités sont sélectionnées pour le modèle d'apprentissage automatique. Ces fonctions seront divisées en deux parties : la formation et les tests.
Gestion des données manquantes
from pyspark.sql.functions import isnull, when, count, col<br>df.select([count(when(isnull(c), c)).alias(c)<br> for c in df.columns]).show()
Cet ensemble de données est génial, il n'y a aucune valeur manquante.
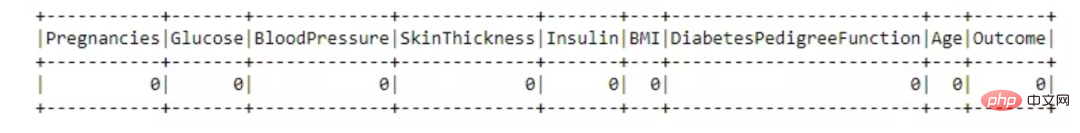
不必要的列丢弃
dataset = dataset.drop('SkinThickness')<br>dataset = dataset.drop('Insulin')<br>dataset = dataset.drop('DiabetesPedigreeFunction')<br>dataset = dataset.drop('Pregnancies')<br><br>dataset.show()
特征转换为向量
VectorAssembler —— 将多列合并为向量列的特征转换器。
# 用VectorAssembler合并所有特性<br>required_features = ['Glucose',<br>'BloodPressure',<br>'BMI',<br>'Age']<br><br>from pyspark.ml.feature import VectorAssembler<br><br>assembler = VectorAssembler(<br>inputCols=required_features, <br>outputCol='features')<br><br>transformed_data = assembler.transform(dataset)<br>transformed_data.show()
现在特征转换为向量已完成。
训练和测试拆分
将数据随机分成训练集和测试集,并设置可重复性的种子。
(training_data, test_data) = transformed_data.randomSplit([0.8,0.2], seed =2020)<br>print("训练数据集总数: " + str(training_data.count()))<br>print("测试数据集总数: " + str(test_data.count()))训练数据集总数:620<br>测试数据集数量:148
机器学习模型构建
随机森林分类器
随机森林是一种监督学习算法,用于分类和回归。但是,它主要用于分类问题。众所周知,森林是由树木组成的,树木越多,森林越茂盛。类似地,随机森林算法在数据样本上创建决策树,然后从每个样本中获取预测,最后通过投票选择最佳解决方案。这是一种比单个决策树更好的集成方法,因为它通过对结果进行平均来减少过拟合。
from pyspark.ml.classification import RandomForestClassifier<br><br>rf = RandomForestClassifier(labelCol='Outcome', <br>featuresCol='features',<br>maxDepth=5)<br>model = rf.fit(training_data)<br>rf_predictions = model.transform(test_data)
评估随机森林分类器模型
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome', metricName = 'accuracy')<br>print('Random Forest classifier Accuracy:', multi_evaluator.evaluate(rf_predictions))Random Forest classifier Accuracy:0.79452
决策树分类器
决策树被广泛使用,因为它们易于解释、处理分类特征、扩展到多类分类设置、不需要特征缩放,并且能够捕获非线性和特征交互。
from pyspark.ml.classification import DecisionTreeClassifier<br><br>dt = DecisionTreeClassifier(featuresCol = 'features',<br>labelCol = 'Outcome',<br>maxDepth = 3)<br>dtModel = dt.fit(training_data)<br>dt_predictions = dtModel.transform(test_data)<br>dt_predictions.select('Glucose', 'BloodPressure', <br>'BMI', 'Age', 'Outcome').show(10)评估决策树模型
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome', <br>metricName = 'accuracy')<br>print('Decision Tree Accuracy:', <br>multi_evaluator.evaluate(dt_predictions))Decision Tree Accuracy: 0.78767
逻辑回归模型
逻辑回归是在因变量是二分(二元)时进行的适当回归分析。与所有回归分析一样,逻辑回归是一种预测分析。逻辑回归用于描述数据并解释一个因二元变量与一个或多个名义、序数、区间或比率水平自变量之间的关系。当因变量(目标)是分类时,使用逻辑回归。
from pyspark.ml.classification import LogisticRegression<br><br>lr = LogisticRegression(featuresCol = 'features', <br>labelCol = 'Outcome', <br>maxIter=10)<br>lrModel = lr.fit(training_data)<br>lr_predictions = lrModel.transform(test_data)
评估我们的逻辑回归模型。
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome',<br>metricName = 'accuracy')<br>print('Logistic Regression Accuracy:', <br>multi_evaluator.evaluate(lr_predictions))Logistic Regression Accuracy:0.78767
梯度提升树分类器模型
梯度提升是一种用于回归和分类问题的机器学习技术,它以弱预测模型(通常是决策树)的集合形式生成预测模型。
from pyspark.ml.classification import GBTClassifier<br>gb = GBTClassifier(<br>labelCol = 'Outcome', <br>featuresCol = 'features')<br>gbModel = gb.fit(training_data)<br>gb_predictions = gbModel.transform(test_data)
评估我们的梯度提升树分类器。
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome',<br>metricName = 'accuracy')<br>print('Gradient-boosted Trees Accuracy:',<br>multi_evaluator.evaluate(gb_predictions))Gradient-boosted Trees Accuracy:0.80137
结论
PySpark 是一种非常适合数据科学家学习的语言,因为它支持可扩展的分析和 ML 管道。如果您已经熟悉 Python 和 Pandas,那么您的大部分知识都可以应用于 Spark。总而言之,我们已经学习了如何使用 PySpark 构建机器学习应用程序。我们尝试了三种算法,梯度提升在我们的数据集上表现最好。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Dans les domaines de l’apprentissage automatique et de la science des données, l’interprétabilité des modèles a toujours été au centre des préoccupations des chercheurs et des praticiens. Avec l'application généralisée de modèles complexes tels que l'apprentissage profond et les méthodes d'ensemble, la compréhension du processus décisionnel du modèle est devenue particulièrement importante. Explainable AI|XAI contribue à renforcer la confiance dans les modèles d'apprentissage automatique en augmentant la transparence du modèle. L'amélioration de la transparence des modèles peut être obtenue grâce à des méthodes telles que l'utilisation généralisée de plusieurs modèles complexes, ainsi que les processus décisionnels utilisés pour expliquer les modèles. Ces méthodes incluent l'analyse de l'importance des caractéristiques, l'estimation de l'intervalle de prédiction du modèle, les algorithmes d'interprétabilité locale, etc. L'analyse de l'importance des fonctionnalités peut expliquer le processus de prise de décision du modèle en évaluant le degré d'influence du modèle sur les fonctionnalités d'entrée. Estimation de l’intervalle de prédiction du modèle
 Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Cet article présentera comment identifier efficacement le surajustement et le sous-apprentissage dans les modèles d'apprentissage automatique grâce à des courbes d'apprentissage. Sous-ajustement et surajustement 1. Surajustement Si un modèle est surentraîné sur les données de sorte qu'il en tire du bruit, alors on dit que le modèle est en surajustement. Un modèle surajusté apprend chaque exemple si parfaitement qu'il classera mal un exemple inédit/inédit. Pour un modèle surajusté, nous obtiendrons un score d'ensemble d'entraînement parfait/presque parfait et un score d'ensemble/test de validation épouvantable. Légèrement modifié : "Cause du surajustement : utilisez un modèle complexe pour résoudre un problème simple et extraire le bruit des données. Parce qu'un petit ensemble de données en tant qu'ensemble d'entraînement peut ne pas représenter la représentation correcte de toutes les données."
 Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
En termes simples, un modèle d’apprentissage automatique est une fonction mathématique qui mappe les données d’entrée à une sortie prédite. Plus précisément, un modèle d'apprentissage automatique est une fonction mathématique qui ajuste les paramètres du modèle en apprenant à partir des données d'entraînement afin de minimiser l'erreur entre la sortie prédite et la véritable étiquette. Il existe de nombreux modèles dans l'apprentissage automatique, tels que les modèles de régression logistique, les modèles d'arbre de décision, les modèles de machines à vecteurs de support, etc. Chaque modèle a ses types de données et ses types de problèmes applicables. Dans le même temps, il existe de nombreux points communs entre les différents modèles, ou il existe une voie cachée pour l’évolution du modèle. En prenant comme exemple le perceptron connexionniste, en augmentant le nombre de couches cachées du perceptron, nous pouvons le transformer en un réseau neuronal profond. Si une fonction noyau est ajoutée au perceptron, elle peut être convertie en SVM. celui-ci
 L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
Dans les années 1950, l’intelligence artificielle (IA) est née. C’est à ce moment-là que les chercheurs ont découvert que les machines pouvaient effectuer des tâches similaires à celles des humains, comme penser. Plus tard, dans les années 1960, le Département américain de la Défense a financé l’intelligence artificielle et créé des laboratoires pour poursuivre son développement. Les chercheurs trouvent des applications à l’intelligence artificielle dans de nombreux domaines, comme l’exploration spatiale et la survie dans des environnements extrêmes. L'exploration spatiale est l'étude de l'univers, qui couvre l'ensemble de l'univers au-delà de la terre. L’espace est classé comme environnement extrême car ses conditions sont différentes de celles de la Terre. Pour survivre dans l’espace, de nombreux facteurs doivent être pris en compte et des précautions doivent être prises. Les scientifiques et les chercheurs pensent qu'explorer l'espace et comprendre l'état actuel de tout peut aider à comprendre le fonctionnement de l'univers et à se préparer à d'éventuelles crises environnementales.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
MetaFAIR s'est associé à Harvard pour fournir un nouveau cadre de recherche permettant d'optimiser le biais de données généré lors de l'apprentissage automatique à grande échelle. On sait que la formation de grands modèles de langage prend souvent des mois et utilise des centaines, voire des milliers de GPU. En prenant comme exemple le modèle LLaMA270B, sa formation nécessite un total de 1 720 320 heures GPU. La formation de grands modèles présente des défis systémiques uniques en raison de l’ampleur et de la complexité de ces charges de travail. Récemment, de nombreuses institutions ont signalé une instabilité dans le processus de formation lors de la formation des modèles d'IA générative SOTA. Elles apparaissent généralement sous la forme de pics de pertes. Par exemple, le modèle PaLM de Google a connu jusqu'à 20 pics de pertes au cours du processus de formation. Le biais numérique est à l'origine de cette imprécision de la formation,
