
 Périphériques technologiques
IA
VectorFlow : combiner des images et des vecteurs pour la prévision de l'occupation du trafic et des flux
Périphériques technologiques
IA
VectorFlow : combiner des images et des vecteurs pour la prévision de l'occupation du trafic et des flux
VectorFlow : combiner des images et des vecteurs pour la prévision de l'occupation du trafic et des flux

Article arXiv « VectorFlow : Combining Images and Vectors for Traffic Occupancy and Flow Prediction », 9 août 2022, travaillant à l'Université Tsinghua.

Prédire le comportement futur des agents routiers est une tâche clé de la conduite autonome. Bien que les modèles existants aient connu un grand succès dans la prédiction du comportement futur des agents, prédire efficacement le comportement coordonné de plusieurs agents reste un défi. Récemment, quelqu'un a proposé la représentation champs de flux d'occupation (OFF) pour représenter l'état futur commun des agents routiers grâce à une combinaison de grilles d'occupation et de flux, soutenant des prédictions conjointement cohérentes.
Ce travail propose un nouveau prédicteur de champs de flux d'occupation, un encodeur d'image qui apprend les caractéristiques des images de trafic rastérisées et un encodeur vectoriel qui capture la trajectoire continue des agents et les informations sur l'état de la carte. Les deux sont combinés pour générer des prédictions précises d'occupation et de flux. Les deux fonctionnalités d'encodage sont fusionnées par plusieurs modules d'attention avant de générer la prédiction finale. Le modèle s'est classé troisième dans le défi Waymo Open Dataset Occupancy and Flow Prediction Challenge et a obtenu les meilleures performances dans la tâche de prédiction d'occupation et de débit occluse. La représentation
OFF ("Occupancy Flow Fields for Motion Forecasting in Autonomous Driving", arXiv 2203.03875, 3, 2022) est une grille spatio-temporelle dans laquelle chaque cellule de la grille comprend i) la probabilité qu'un agent occupe la cellule et ii) Représente le flux de mouvement de l'agent occupant l'unité. Il offre une meilleure efficacité et évolutivité car la complexité informatique de la prévision des champs de flux d'occupation est indépendante du nombre d'agents routiers dans la scène.
Comme le montre l’image, le diagramme du cadre OFF. La structure du codeur est la suivante. La première étape reçoit les trois types de points d'entrée et les traite avec des encodeurs inspirés de PointPillars. Les feux de circulation et les points routiers sont placés directement sur la grille. Le codage d'état de l'agent à chaque pas de temps d'entrée t consiste à échantillonner uniformément une grille de points de taille fixe à partir de chaque boîte BEV d'agent et à combiner ces points avec les attributs d'état d'agent pertinents (y compris le codage à chaud du temps t ) placés sur la grille. Chaque pilier génère une intégration pour tous les points qu'il contient. La structure du décodeur est la suivante. Le deuxième niveau reçoit chaque pilier intégré en entrée et génère des prévisions d'occupation et de débit par cellule de grille. Le réseau de décodeurs est basé sur EfficientNet, utilisant EfficientNet comme épine dorsale pour traiter chaque intégration de pilier afin d'obtenir des cartes de fonctionnalités (P2,... P7), où Pi est sous-échantillonné 2^i à partir de l'entrée. Le réseau BiFPN est ensuite utilisé pour fusionner ces fonctionnalités multi-échelles de manière bidirectionnelle. Ensuite, la carte de caractéristiques P2 à la plus haute résolution est utilisée pour régresser les prédictions d'occupation et de flux pour toutes les classes d'agents K à tous les pas de temps. Plus précisément, le décodeur génère un vecteur pour chaque cellule de la grille tout en prédisant l'occupation et le flux.
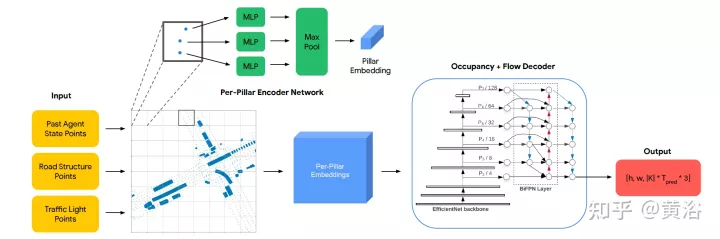
Pour cet article, le paramétrage du problème suivant est effectué : étant donné l'historique d'une seconde de l'agent de circulation dans la scène et le contexte de la scène, tel que les coordonnées de la carte, l'objectif est de prédire i) l'occupation future observée, ii) le taux d'occupation d'occlusion futur, et iii) le flux futur de tous les véhicules à 8 points de cheminement dans le futur dans un scénario où chaque point de cheminement couvre un intervalle de 1 seconde.
Traitez l'entrée dans une image pixellisée et un ensemble de vecteurs. Pour obtenir l'image, une grille rastérisée est créée à chaque pas de temps dans le passé par rapport aux coordonnées locales de la voiture autonome (SDC), compte tenu de la trajectoire de l'agent d'observation et des données cartographiques. Pour obtenir une entrée vectorisée cohérente avec l'image rastérisée, les mêmes transformations sont suivies, en faisant pivoter et en déplaçant l'agent d'entrée et les coordonnées de la carte par rapport à la vue locale du SDC.
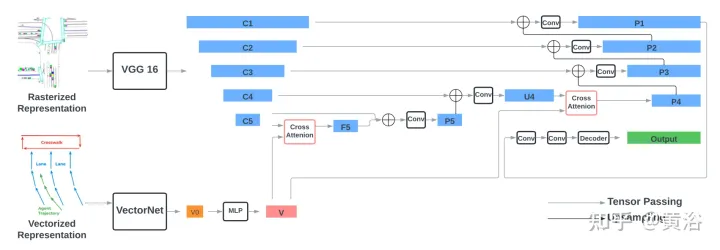
L'encodeur se compose de deux parties : le modèle VGG-16 qui encode la représentation rastérisée et le modèle VectorNe qui encode la représentation vectorisée. Les caractéristiques vectorisées sont fusionnées avec les caractéristiques des deux dernières étapes de VGG-16 via le module d'attention croisée. Grâce au réseau de type FPN, les fonctionnalités fusionnées sont suréchantillonnées à la résolution d'origine et utilisées comme fonctionnalités rastérisées en entrée. Le
Decoder est une seule couche convolutive 2D qui mappe la sortie de l'encodeur à une prédiction des champs de flux d'occupation, qui consiste en une série de 8 cartes de grille représentant les prédictions d'occupation et de flux pour chaque pas de temps au cours des 8 prochaines secondes.
Comme le montre l'image :
Utilisez le modèle VGG-16 standard de torchvision comme encodeur de rastérisation et suivez la mise en œuvre de VectorNet (codehttps://github.com/Tsinghua-MARS-Lab/DenseTNT) . L'entrée dans VectorNet consiste en i) un ensemble de vecteurs d'éléments routiers de forme B×Nr×9, où B est la taille du lot, Nr=10000 est le nombre maximum de vecteurs d'éléments routiers, et la dernière dimension 9 représente chaque vecteur et l'ID du vecteur La position (x, y) et la direction (cosθ, sinθ) des deux points finaux ii) un ensemble de vecteurs d'agent de forme B×1280×9, comprenant des vecteurs pouvant contenir jusqu'à 128 agents dans la scène, où chaque agent Avec 10 vecteurs à partir de la position d'observation.
Suivez VectorNet, exécutez d'abord la carte locale en fonction de l'ID de chaque élément de trafic, puis exécutez la carte globale sur toutes les entités locales pour obtenir des entités vectorisées de forme B×128×N, où N est le nombre total d'éléments de trafic , y compris les éléments routiers et l'intelligence. La taille de l'élément est encore augmentée quatre fois via la couche MLP pour obtenir l'élément vectoriel final V, dont la forme est B × 512 × N, et sa taille d'élément est cohérente avec la taille du canal de l'élément d'image.
Les caractéristiques de sortie de chaque niveau de VGG sont représentées par {C1, C2, C3, C4, C5}, par rapport à l'image d'entrée et 512 dimensions cachées, les foulées sont de {1, 2, 4, 8, 16} pixels . La caractéristique vectorisée V est fusionnée avec la caractéristique d'image rastérisée C5 de forme B×512×16×16 via le module d'attention croisée pour obtenir F5 de même forme. L'élément de requête de l'attention croisée est la caractéristique d'image C5, qui est aplatie en une forme B × 512 × 256 avec 256 jetons, et les éléments Clé et Valeur sont la caractéristique vectorisée V avec N jetons.
Connectez ensuite F5 et C5 sur la dimension du canal, et passez à travers deux couches convolutives 3×3 pour obtenir P5 de forme B×512×16×16. P5 est suréchantillonné via le module de suréchantillonnage 2×2 de style FPN et connecté à C4 (B×512×32x32) pour générer U4 avec la même forme que C4. Un autre cycle de fusion est ensuite effectué entre V et U4, en suivant la même procédure, y compris une attention croisée, pour obtenir P4 (B × 512 × 32 × 32). Enfin, P4 est progressivement suréchantillonné par le réseau de style FPN et connecté à {C3, C2, C1} pour générer EP1 avec une forme de B×512×256×256. Passez P1 à travers deux couches convolutives 3 × 3 pour obtenir la caractéristique de sortie finale avec une forme de B × 128 × 256.
Le décodeur est une seule couche convolutive 2D avec une taille de canal d'entrée de 128 et une taille de canal de sortie de 32 (8 waypoints × 4 dimensions de sortie).
Les résultats sont les suivants :
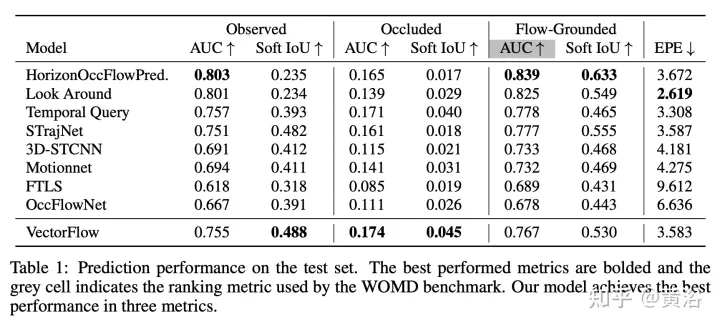
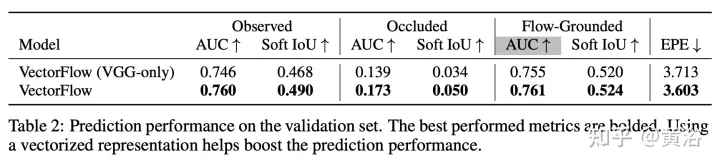
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Smart App Control sur Windows 11 : comment l'activer ou le désactiver
Jun 06, 2023 pm 11:10 PM
Smart App Control sur Windows 11 : comment l'activer ou le désactiver
Jun 06, 2023 pm 11:10 PM
Intelligent App Control est un outil très utile dans Windows 11 qui aide à protéger votre PC contre les applications non autorisées qui peuvent endommager vos données, telles que les ransomwares ou les logiciels espions. Cet article explique ce qu'est Smart App Control, comment il fonctionne et comment l'activer ou le désactiver dans Windows 11. Qu’est-ce que Smart App Control dans Windows 11 ? Smart App Control (SAC) est une nouvelle fonctionnalité de sécurité introduite dans la mise à jour Windows 1122H2. Il fonctionne avec Microsoft Defender ou un logiciel antivirus tiers pour bloquer les applications potentiellement inutiles susceptibles de ralentir votre appareil, d'afficher des publicités inattendues ou d'effectuer d'autres actions inattendues. Application intelligente
 Les traits du visage volent, ouvrent la bouche, regardent fixement et lèvent les sourcils. L'IA peut les imiter parfaitement, ce qui rend impossible la prévention des escroqueries vidéo.
Dec 14, 2023 pm 11:30 PM
Les traits du visage volent, ouvrent la bouche, regardent fixement et lèvent les sourcils. L'IA peut les imiter parfaitement, ce qui rend impossible la prévention des escroqueries vidéo.
Dec 14, 2023 pm 11:30 PM
Avec une capacité d'imitation de l'IA aussi puissante, il est vraiment impossible de l'empêcher. Le développement de l’IA a-t-il atteint ce niveau aujourd’hui ? Votre pied avant fait voler les traits de votre visage, et sur votre pied arrière, la même expression est reproduite. Regarder fixement, lever les sourcils, faire la moue, aussi exagérée que soit l'expression, tout est parfaitement imité. Augmentez la difficulté, haussez les sourcils, ouvrez plus grand les yeux, et même la forme de la bouche est tordue, et l'avatar du personnage virtuel peut parfaitement reproduire l'expression. Lorsque vous ajustez les paramètres à gauche, l'avatar virtuel à droite modifiera également ses mouvements en conséquence pour donner un gros plan de la bouche et des yeux. On ne peut pas dire que l'imitation soit exactement la même, seule l'expression est exactement la même. idem (extrême droite). La recherche provient d'institutions telles que l'Université technique de Munich, qui propose GaussianAvatars, qui
 MotionLM : technologie de modélisation de langage pour la prédiction de mouvement multi-agents
Oct 13, 2023 pm 12:09 PM
MotionLM : technologie de modélisation de langage pour la prédiction de mouvement multi-agents
Oct 13, 2023 pm 12:09 PM
Cet article est reproduit avec la permission du compte public Autonomous Driving Heart. Veuillez contacter la source pour la réimpression. Titre original : MotionLM : Multi-Agent Motion Forecasting as Language Modeling Lien vers l'article : https://arxiv.org/pdf/2309.16534.pdf Affiliation de l'auteur : Conférence Waymo : ICCV2023 Idée d'article : Pour la planification de la sécurité des véhicules autonomes, prédisez de manière fiable le comportement futur des agents routiers est cruciale. Cette étude représente les trajectoires continues sous forme de séquences de jetons de mouvement discrets et traite la prédiction de mouvement multi-agents comme une tâche de modélisation du langage. Le modèle que nous proposons, MotionLM, présente les avantages suivants :
 Savez-vous que les programmeurs seront en déclin dans quelques années ?
Nov 08, 2023 am 11:17 AM
Savez-vous que les programmeurs seront en déclin dans quelques années ?
Nov 08, 2023 am 11:17 AM
Le magazine "ComputerWorld" a écrit un article disant que "la programmation disparaîtra d'ici 1960" parce qu'IBM a développé un nouveau langage FORTRAN, qui permet aux ingénieurs d'écrire les formules mathématiques dont ils ont besoin, puis de les soumettre à l'ordinateur pour que la programmation se termine. Picture Quelques années plus tard, nous avons entendu un nouveau dicton : tout homme d'affaires peut utiliser des termes commerciaux pour décrire ses problèmes et dire à l'ordinateur quoi faire. Grâce à ce langage de programmation appelé COBOL, les entreprises n'ont plus besoin de programmeurs. Plus tard, il est dit qu'IBM a développé un nouveau langage de programmation appelé RPG qui permet aux employés de remplir des formulaires et de générer des rapports, de sorte que la plupart des besoins de programmation de l'entreprise puissent être satisfaits grâce à lui.
 Le robot humanoïde universel intelligent GR-1 Fourier est sur le point de commencer la prévente !
Sep 27, 2023 pm 08:41 PM
Le robot humanoïde universel intelligent GR-1 Fourier est sur le point de commencer la prévente !
Sep 27, 2023 pm 08:41 PM
Le robot humanoïde, qui mesure 1,65 mètre, pèse 55 kilogrammes et possède 44 degrés de liberté dans son corps, peut marcher rapidement, éviter les obstacles rapidement, monter et descendre régulièrement les pentes et résister aux chocs et aux interférences. Vous pouvez désormais le ramener chez vous. ! Le robot humanoïde universel GR-1 de Fourier Intelligence a commencé la prévente. Salle de conférence Robot Le robot humanoïde universel Fourier GR-1 de Fourier Intelligence est maintenant ouvert à la prévente. GR-1 a une configuration de tronc hautement bionique et un contrôle de mouvement anthropomorphique. Il a 44 degrés de liberté dans tout le corps. Il a la capacité de marcher, d'éviter les obstacles, de franchir des obstacles, de monter et de descendre des pentes, de résister aux interférences et de s'adapter. à différentes surfaces routières. C'est un système d'intelligence artificielle général. Page de prévente du site officiel : www.fftai.cn/order#FourierGR-1# Fourier Intelligence doit être réécrit.
 Huawei lancera le système de détection Xuanji dans le domaine des appareils portables intelligents, capable d'évaluer l'état émotionnel de l'utilisateur en fonction de la fréquence cardiaque
Aug 29, 2024 pm 03:30 PM
Huawei lancera le système de détection Xuanji dans le domaine des appareils portables intelligents, capable d'évaluer l'état émotionnel de l'utilisateur en fonction de la fréquence cardiaque
Aug 29, 2024 pm 03:30 PM
Récemment, Huawei a annoncé qu'il lancerait en septembre un nouveau produit portable intelligent équipé du système de détection Xuanji, qui devrait être la dernière montre intelligente de Huawei. Ce nouveau produit intégrera des fonctions avancées de surveillance de la santé émotionnelle. Le système de perception Xuanji fournit aux utilisateurs une évaluation complète de la santé avec ses six caractéristiques : précision, exhaustivité, rapidité, flexibilité, ouverture et évolutivité. Le système utilise un module de super-détection et optimise la technologie d'architecture de chemin optique multicanal, ce qui améliore considérablement la précision de surveillance des indicateurs de base tels que la fréquence cardiaque, l'oxygène dans le sang et la fréquence respiratoire. En outre, le système de détection Xuanji a également élargi la recherche sur les états émotionnels sur la base des données de fréquence cardiaque. Il ne se limite pas aux indicateurs physiologiques, mais peut également évaluer l'état émotionnel et le niveau de stress de l'utilisateur. Il prend en charge la surveillance de plus de 60 sports. indicateurs de santé, couvrant les domaines cardiovasculaire, respiratoire, neurologique, endocrinien,
 Quelles sont les méthodes efficaces et les méthodes de base communes pour la prédiction de trajectoires piétonnes ? Partage des meilleurs articles de conférence !
Oct 17, 2023 am 11:13 AM
Quelles sont les méthodes efficaces et les méthodes de base communes pour la prédiction de trajectoires piétonnes ? Partage des meilleurs articles de conférence !
Oct 17, 2023 am 11:13 AM
La prédiction de trajectoire a pris de l'ampleur au cours des deux dernières années, mais l'essentiel se concentre sur la direction de la prédiction de trajectoire des véhicules. Aujourd'hui, Autonomous Driving Heart partagera avec vous l'algorithme de prédiction de trajectoire des piétons sur NeurIPS - SHENet. les schémas de déplacement sont généralement, dans une certaine mesure, conformes à des règles limitées. Sur la base de cette hypothèse, SHENet prédit la trajectoire future d'une personne en apprenant des règles de scène implicites. L'article a été autorisé comme original par Autonomous Driving Heart ! La compréhension personnelle de l'auteur est qu'à l'heure actuelle, prédire la trajectoire future d'une personne reste un problème difficile en raison du caractère aléatoire et subjectif du mouvement humain. Cependant, les schémas de mouvement humain dans les scènes contraintes varient souvent en raison des contraintes de la scène (telles que les plans d'étage, les routes et les obstacles) et de l'interactivité d'humain à humain ou d'humain à objet.
 Lisez le châssis de skateboard de voiture intelligente dans un article
May 24, 2023 pm 12:01 PM
Lisez le châssis de skateboard de voiture intelligente dans un article
May 24, 2023 pm 12:01 PM
01 Qu'est-ce qu'un châssis de skateboard ? Le soi-disant châssis de skateboard intègre à l'avance la batterie, le système d'entraînement électrique, la suspension, les freins et d'autres composants sur le châssis pour réaliser la séparation et le découplage de la carrosserie et du châssis. Grâce à ce type de plateforme, les constructeurs automobiles peuvent réduire considérablement les coûts initiaux de R&D et de tests, tout en répondant rapidement à la demande du marché pour créer différents modèles. Surtout à l'ère de la conduite sans conducteur, la disposition de la voiture n'est plus centrée sur la conduite, mais se concentrera sur les attributs d'espace. Le châssis de type skateboard peut offrir plus de possibilités pour le développement de l'habitacle supérieur. Comme le montre l'image ci-dessus, bien sûr, lorsque nous regardons le châssis du skateboard, nous ne devrions pas nous laisser encadrer par la première impression de "Oh, c'est un corps non porteur" lorsque nous y arrivons. Il n’y avait pas de voitures électriques à l’époque, donc pas de batteries valant des centaines de kilogrammes, pas de système de direction électrique capable d’éliminer la colonne de direction, ni de système de freinage électrique.
