
 Périphériques technologiques
IA
Pour améliorer l'expérience de recherche Alipay, Ant et l'Université de Pékin utilisent un cadre de génération de texte d'apprentissage comparatif hiérarchique
Périphériques technologiques
IA
Pour améliorer l'expérience de recherche Alipay, Ant et l'Université de Pékin utilisent un cadre de génération de texte d'apprentissage comparatif hiérarchique
Pour améliorer l'expérience de recherche Alipay, Ant et l'Université de Pékin utilisent un cadre de génération de texte d'apprentissage comparatif hiérarchique

Les tâches de génération de texte sont généralement entraînées à l'aide du forçage de l'enseignant. Cette méthode de formation permet au modèle de ne voir que les échantillons positifs pendant le processus de formation. Cependant, il existe généralement certaines contraintes entre la cible de génération et l'entrée. Ces contraintes sont généralement reflétées par des éléments clés dans la phrase. Par exemple, dans la tâche de réécriture de requête, « commander McDonald's » ne peut pas être remplacé par « commander KFC Ceci ». joue un rôle dans L'élément clé de la retenue réside dans les mots-clés de la marque. En introduisant un apprentissage contrastif et en ajoutant des modèles d'échantillons négatifs au processus de génération, le modèle peut apprendre efficacement ces contraintes.
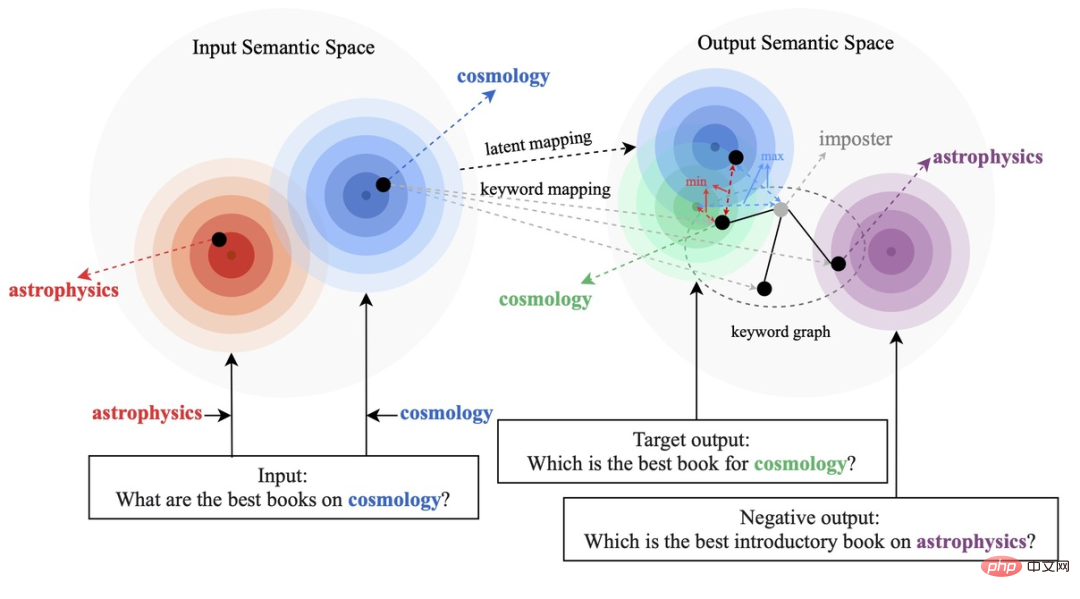
Les méthodes d'apprentissage contrastives existantes se concentrent principalement sur le niveau de la phrase entière [1][2], tout en ignorant les informations sur les entités granulaires des mots dans la phrase. L'exemple de la figure ci-dessous montre les mots clés de la phrase. Le sens important des mots. Pour une phrase d'entrée, si ses mots-clés sont remplacés (par exemple cosmologie->astrophysique), le sens de la phrase changera, et donc la position dans l'espace sémantique (représentée par la distribution) changera également. En tant qu'information la plus importante dans une phrase, les mots-clés correspondent à un point de la distribution sémantique, qui détermine dans une large mesure la position de la distribution de la phrase. Dans le même temps, dans certains cas, les objectifs d'apprentissage contrastés existants sont trop simples pour le modèle, ce qui fait que le modèle est incapable de véritablement apprendre les informations clés entre les exemples positifs et négatifs.
Sur cette base, des chercheurs de Ant Group, de l'Université de Pékin et d'autres institutions ont proposé une méthode de génération de contraste multi-granularité, conçu une structure de contraste hiérarchique, amélioré les informations à différents niveaux et amélioré l'apprentissage au niveau de la granularité des phrases. la sémantique globale améliore les informations locales importantes au niveau de la granularité des mots. Le document de recherche a été accepté pour l’ACL 2022.

Adresse papier : https://aclanthology.org/2022.acl-long.304.pdf
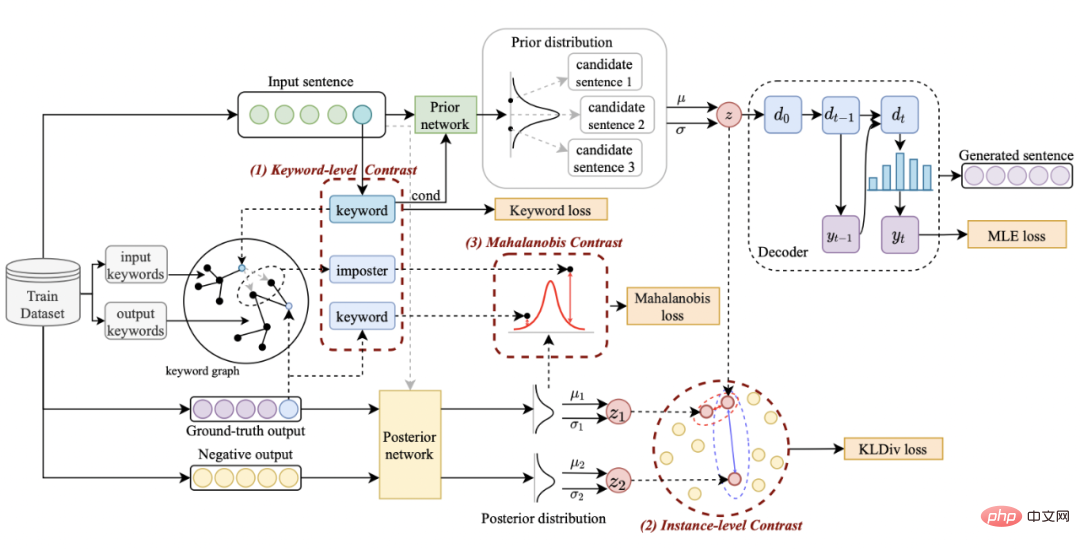
Méthode
Notre approche s'appuie sur classique Dans le cadre de génération de texte CVAE [3][4], chaque phrase peut être mappée à une distribution dans l'espace vectoriel, et les mots-clés de la phrase peuvent être considérés comme un point échantillonné à partir de cette distribution. D'une part, nous améliorons l'expression de la distribution des vecteurs spatiaux latents grâce à la comparaison de la granularité des phrases. D'autre part, nous améliorons l'expression de la granularité des points-clés grâce au graphe global des mots-clés construit. distribution des points-clés et des phrases. Contraste entre les niveaux de construction pour améliorer l'expression de l'information à deux granularités. La fonction de perte finale est obtenue en ajoutant trois pertes d'apprentissage contrastives différentes. Sensence Granular Comparative Learning
. Nous utilisons un réseau antérieur pour apprendre la distribution antérieure

, enregistrée comme
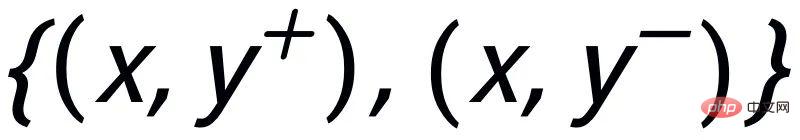
et apprendre la distribution postérieure approximative
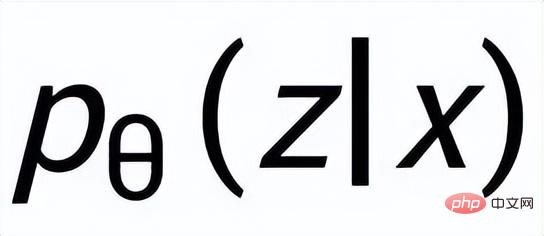 ;
;
et
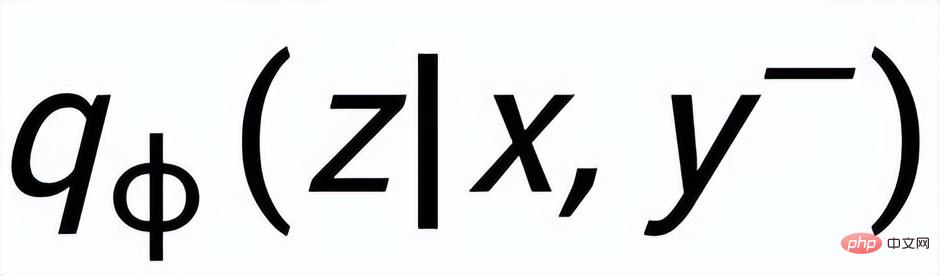
sont notés
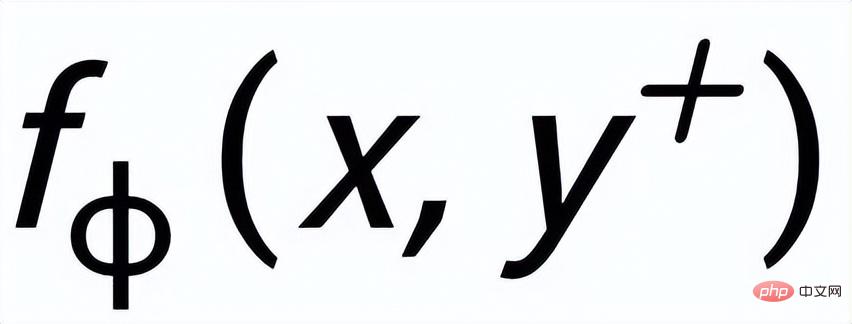
et respectivement . L'objectif de l'apprentissage comparatif granulaire des phrases est de réduire autant que possible la distance entre la distribution antérieure et la distribution postérieure positive, et en même temps, de maximiser la distance entre la distribution antérieure et la distribution postérieure négative. La fonction de perte correspondante est. comme suit :
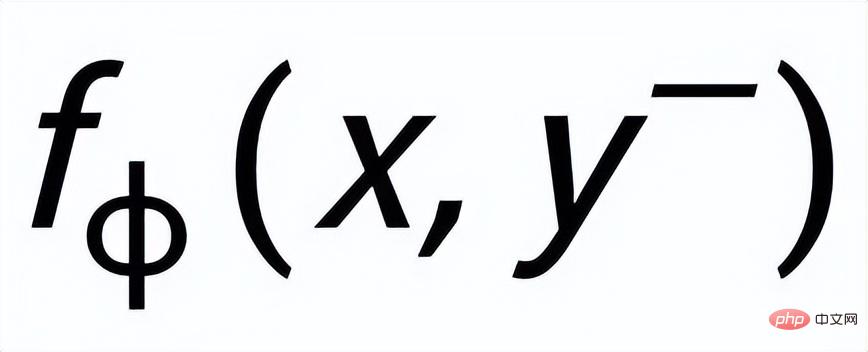
où est un échantillon positif ou un échantillon négatif, et est le coefficient de température, qui est utilisé pour représenter la mesure de distance. Ici, nous utilisons la divergence KL (divergence Kullback – Leibler) [5. ] pour mesurer la distance directe entre deux distributions.
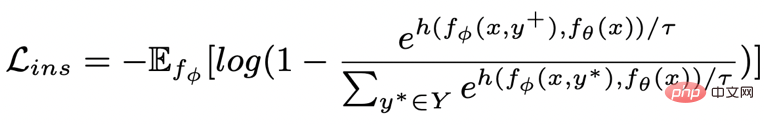
Apprentissage comparatif granulaire des mots clés
Réseau de mots clés
- L'apprentissage comparatif de la granularité des mots clés est utilisé pour que le modèle accorde plus d'attention aux mots clés dans la phrase Informations , nous atteignons cet objectif en construisant un graphe de mots-clés utilisant les relations positives et négatives correspondant au texte d'entrée et de sortie. Concrètement, en fonction d'une paire de phrases donnée
, on peut respectivement déterminer un mot-clé

et

( Pour la méthode d'extraction de mots clés, J'utilise l'algorithme TextRank classique [6]); pour une phrase

, il peut y avoir d'autres phrases avec les mêmes mots-clés

Ensemble, elles forment un ensemble
. 
, où chaque phrase
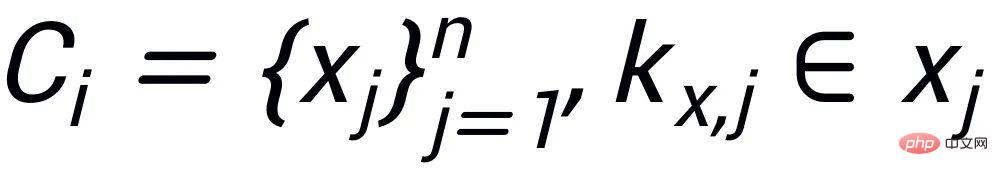
a une paire d'exemples de phrases de sortie positives et négatives

, ils ont différents A mot-clé positif
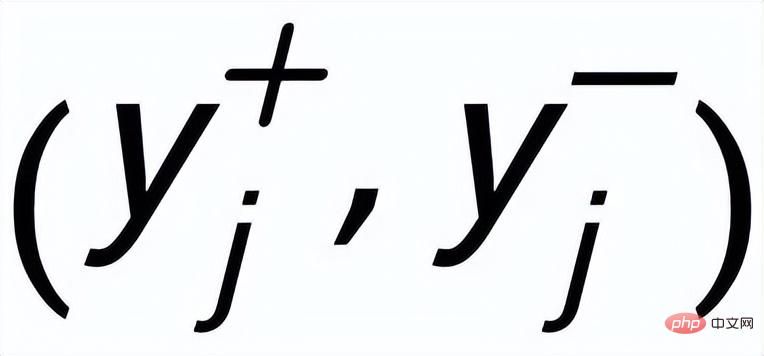
et exemples de mots clés à exclure . De cette façon, dans l'ensemble de la collection, pour toute phrase de sortie , on peut considérer que son mot-clé correspondant et chaque environnement (associé par des relations positives et négatives entre les phrases) , et il y a un avantage positif entre chaque environnement Côté négatif . Sur la base de ces nœuds de mots-clés et de leurs bords directs, nous pouvons construire un graphique de mots-clés Nous utilisons l'intégration BERT[7] pour chaque nœud Initialisez et utilisez une couche MLP pour apprendre la représentation de chaque arête . Nous mettons à jour de manière itérative les nœuds et les arêtes du réseau de mots-clés via une couche d'attention graphique (GAT) et une couche MLP. À chaque itération, nous mettons d'abord à jour la représentation des arêtes de la manière suivante : Ici . peut être ou . Puis en fonction des bords mis à jour , nous mettons à jour la représentation de chaque nœud via une couche d'attention graphique : Ici sont tous des paramètres apprenables, est le poids de l'attention. Afin d'éviter le problème du gradient de disparition, nous ajoutons une connexion résiduelle à pour obtenir la représentation des nœuds dans cette itération . Nous utilisons la représentation nodale de la dernière itération comme représentation du mot-clé, noté u. La comparaison de la granularité des mots-clés provient des mots-clés de la phrase d'entrée et un Node imposteur . Nous enregistrons le mot-clé extrait de l'échantillon positif de sortie de la phrase d'entrée comme , et son nœud voisin négatif dans le réseau de mots-clés ci-dessus est enregistré comme , puis , la perte d'apprentissage comparative de la granularité des mots clés est calculée comme suit : ici est utilisé pour désigner ou , h(·) est utilisé pour représenter la mesure de distance. Dans l'apprentissage comparatif de la granularité des mots clés, nous choisissons la similarité cosinus pour calculer la distance entre deux points. On peut noter que l'apprentissage contrastif ci-dessus de la granularité des phrases et de la granularité des mots-clés est mis en œuvre respectivement au niveau de la distribution et du point, de sorte qu'une comparaison indépendante des deux granularités sont possibles. L'effet d'amélioration est affaibli en raison de différences plus petites. À cet égard, nous construisons des associations comparatives entre différentes granularités basées sur la distance de Mahalanobis [8] entre points et distributions, de sorte que la distance entre le mot-clé de sortie cible et la distribution de la phrase soit aussi petite que possible, de sorte que la distance entre l'imposteur et la distribution est aussi petite que possible. Cela compense le défaut selon lequel le contraste peut disparaître en raison de la comparaison indépendante de chaque taille de particule. Plus précisément, l'apprentissage contrastif à distance Mahalanobis à granularité croisée espère réduire autant que possible la distance entre la distribution sémantique postérieure des phrases et , tout en augmentant la distance entre eux autant que possible. La distance entre lui et est la suivante :
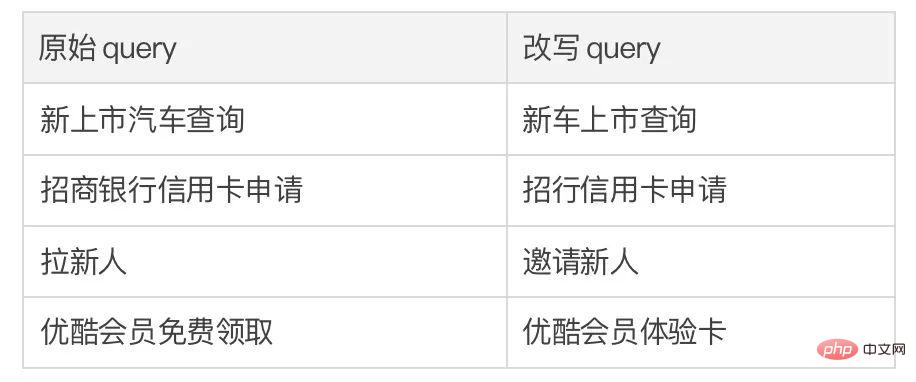
est également utilisé Référez-vous à ou , et h(·) est la distance de Mahalanobis. Nous avons effectué des analyses sur trois ensembles de données publics Douban (Dialogue) [9], QQP (Paraphrase) [10][11] et expériences de théories ont été menés sur (Storytelling) [12], et tous deux ont obtenu des résultats SOTA. Les références que nous comparons incluent des modèles génératifs traditionnels (par exemple CVAE[13], Seq2Seq[14], Transformer[15]), des méthodes basées sur des modèles pré-entraînés (par exemple Seq2Seq-DU[16], DialoGPT[17], BERT-GEN [7], T5[18]) et des méthodes basées sur l'apprentissage contrastif (par exemple Group-wise[9], T5-CLAPS[19]). Nous calculons le score BLEU[20] et la distance d'intégration BOW (extrema/moyenne/gourmande)[21] entre les paires de phrases comme indicateurs d'évaluation automatisés. Les résultats sont présentés dans la figure ci-dessous : Nous. L'évaluation manuelle est également utilisée sur l'ensemble de données QQP. Trois annotateurs ont respectivement annoté T5-CLAPS, DialoGPT, Seq2Seq-DU et les résultats générés par notre modèle. Les résultats sont présentés dans la figure ci-dessous : Nous avons mené des expériences d'analyse d'ablation pour savoir s'il fallait utiliser des mots-clés, s'il fallait utiliser des réseaux de mots-clés et s'il fallait utiliser la distribution de comparaison de distance de Mahalanobis. résultats finaux. rôle important, les résultats expérimentaux sont présentés dans la figure ci-dessous. Afin d'étudier le rôle de l'apprentissage contrastif à différents niveaux, nous avons visualisé les cas échantillonnés au hasard et effectué une réduction de dimensionnalité via t-sne[22] pour obtenir le photo suivante. On peut voir sur la figure que la représentation de la phrase d'entrée est proche de la représentation des mots-clés extraits, ce qui montre que les mots-clés, en tant qu'informations les plus importantes dans la phrase, déterminent généralement la position de la distribution sémantique. De plus, dans l’apprentissage contrastif, nous pouvons voir qu’après l’entraînement, la distribution des phrases d’entrée est plus proche des échantillons positifs et plus éloignée des échantillons négatifs, ce qui montre que l’apprentissage contrastif peut aider à corriger la distribution sémantique. Enfin, nous explorons l'impact de l'échantillonnage de différents mots-clés. Comme le montre le tableau ci-dessous, pour une question d'entrée, nous fournissons des mots-clés comme conditions pour contrôler la distribution sémantique via les méthodes d'extraction TextRank et de sélection aléatoire respectivement, et vérifions la qualité du texte généré. Les mots-clés constituent l'unité d'information la plus importante dans une phrase. Différents mots-clés conduiront à différentes distributions sémantiques et produiront différents tests. Plus il y a de mots-clés sélectionnés, plus les phrases générées sont précises. Parallèlement, les résultats générés par d'autres modèles sont également présentés dans le tableau ci-dessous. Dans cet article, nous proposons un mécanisme d'apprentissage contrastif hiérarchique multi-granularité, qui est plus que compétitif sur plusieurs ensembles de données générés par du texte. Le modèle de réécriture de requêtes basé sur ce travail a été mis en œuvre avec succès dans le scénario commercial réel de la recherche Alipay et a obtenu des résultats remarquables. Les services de recherche d'Alipay couvrent un large éventail de domaines et présentent des caractéristiques de domaine significatives. Il existe une énorme différence littérale entre l'expression de la requête de recherche de l'utilisateur et l'expression du service, ce qui rend difficile l'obtention de résultats idéaux en faisant correspondre directement des mots-clés (par exemple). Par exemple, l'utilisateur saisit la requête "Requête de voiture nouvellement lancée" ", incapable de rappeler le service "Requête de lancement de nouvelle voiture"), le but de la réécriture de la requête est de réécrire la requête saisie par l'utilisateur d'une manière plus proche de la expression de service tout en gardant l'intention de la requête inchangée, afin de mieux correspondre au service cible. Voici quelques exemples de reformulation : 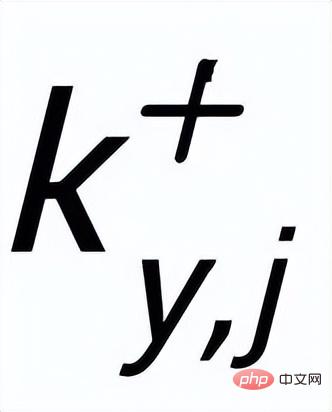



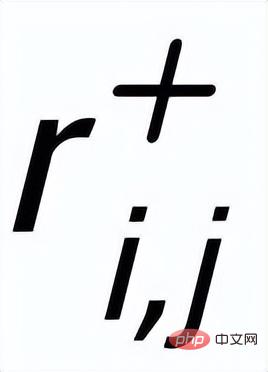




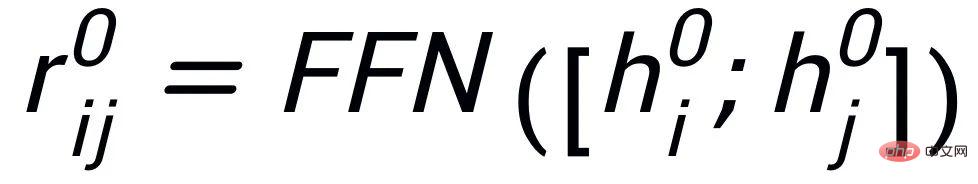
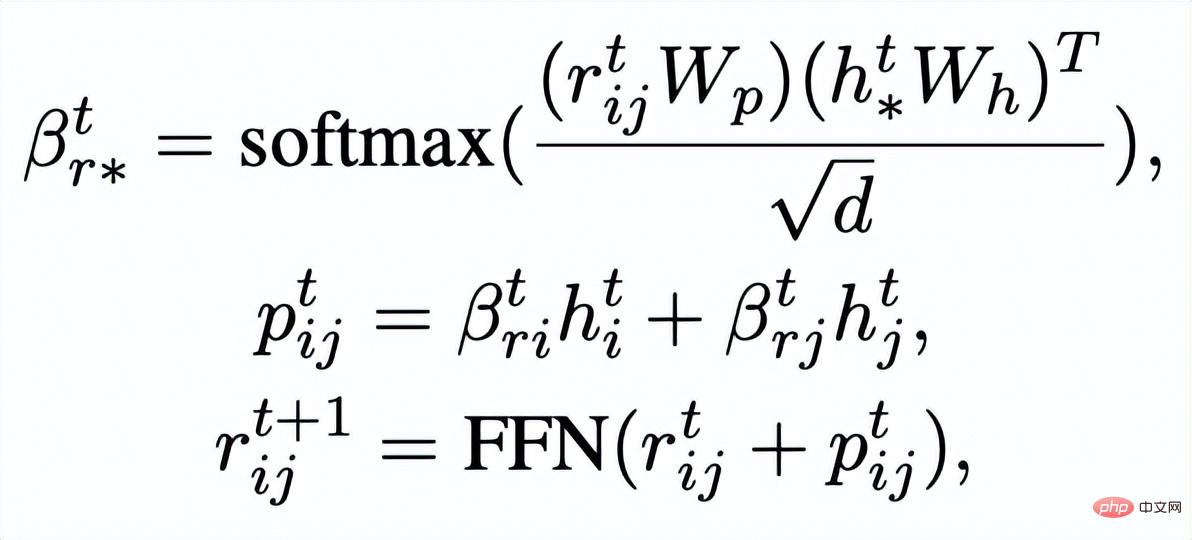




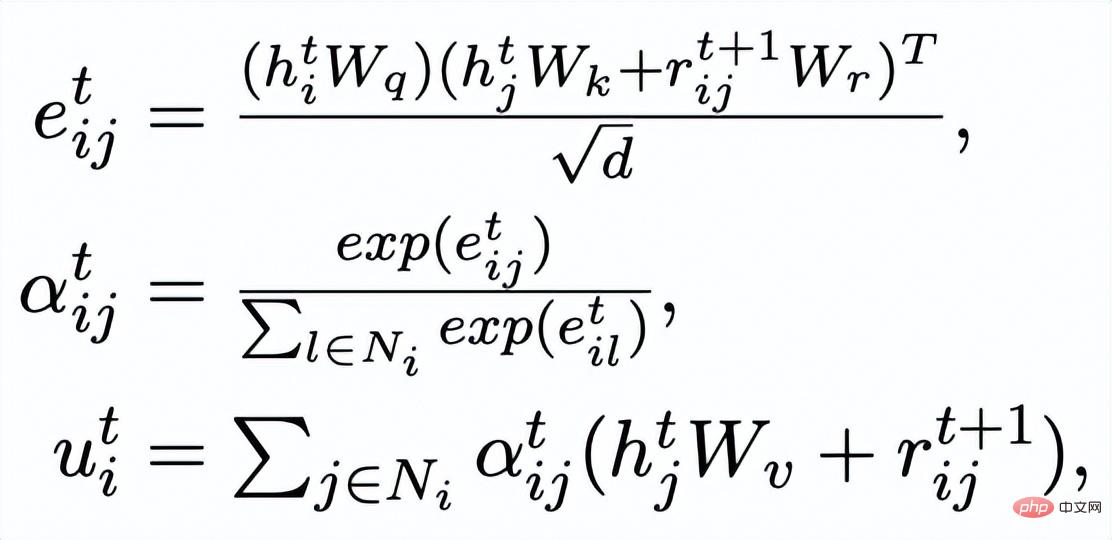
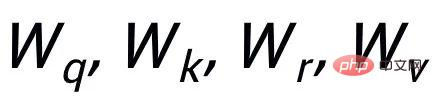







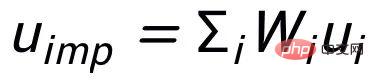
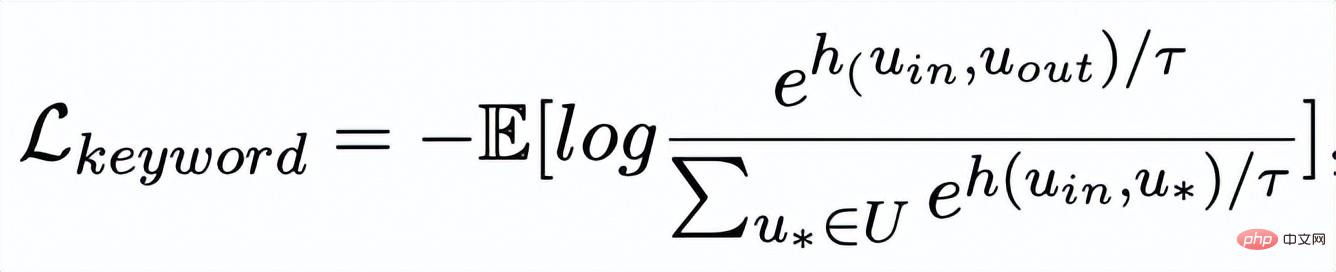



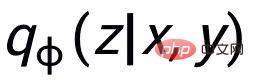


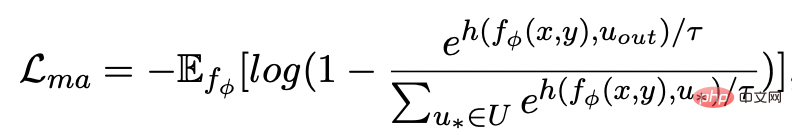



Expérimentation et analyse
Résultats expérimentaux
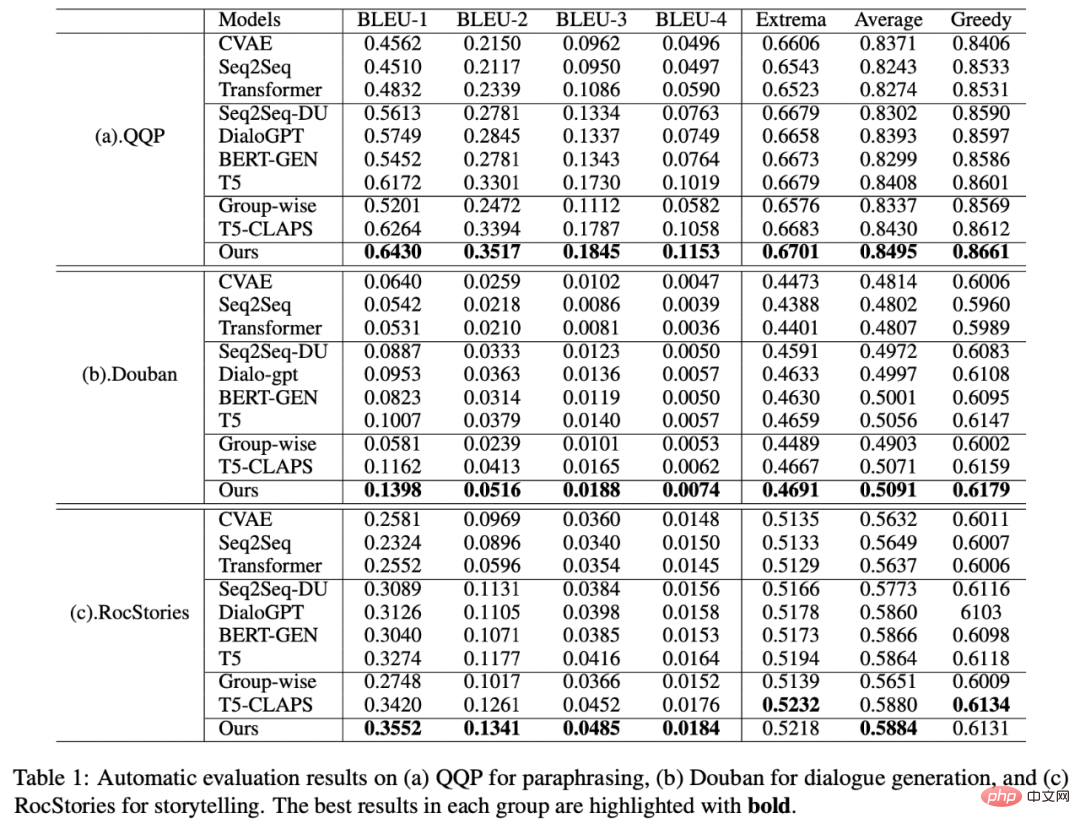
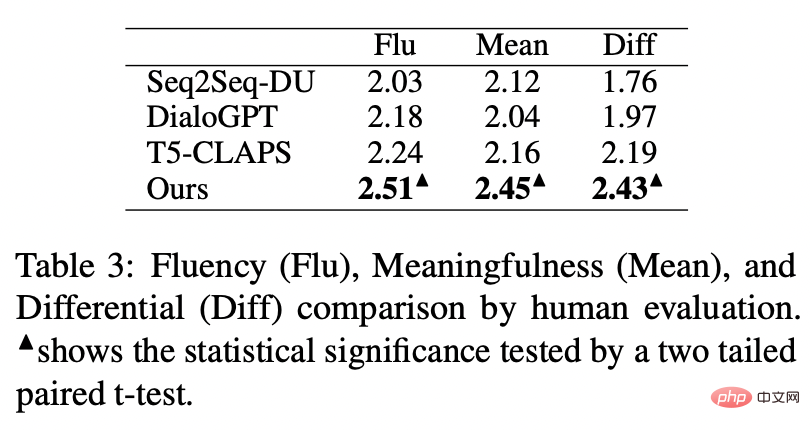
Analyse d'ablation
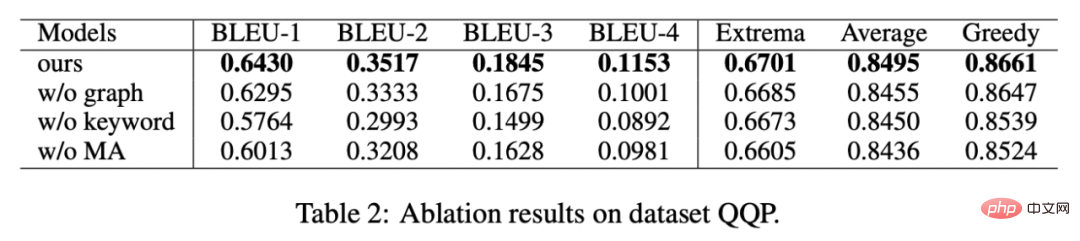
Analyse visuelle
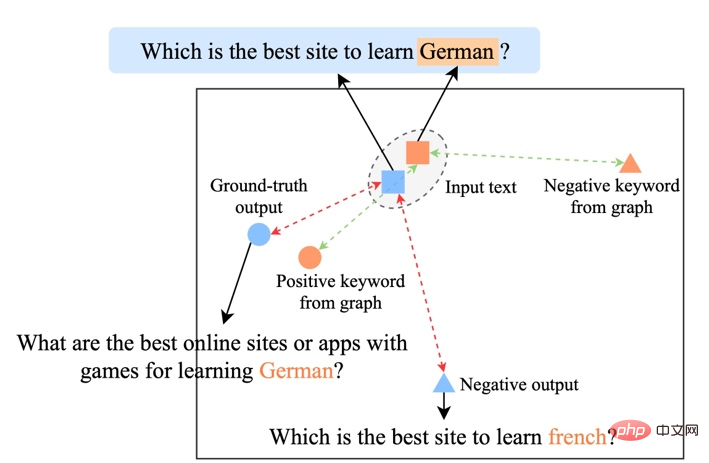
Analyse de l'importance des mots clés

Applications métiers
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment supprimer le contenu d'actualités et de tendances de la recherche Windows 11
Oct 16, 2023 pm 08:13 PM
Comment supprimer le contenu d'actualités et de tendances de la recherche Windows 11
Oct 16, 2023 pm 08:13 PM
Lorsque vous cliquez sur le champ de recherche dans Windows 11, l'interface de recherche se développe automatiquement. Il affiche une liste des programmes récents à gauche et du contenu Web à droite. Microsoft y affiche des actualités et du contenu tendance. Le chèque d'aujourd'hui fait la promotion de la nouvelle fonctionnalité de génération d'images DALL-E3 de Bing, de l'offre « Chat Dragons with Bing », de plus d'informations sur les dragons, des principales actualités de la section Web, des recommandations de jeux et de la section Recherche de tendances. La liste complète des éléments est indépendante de votre activité sur votre ordinateur. Bien que certains utilisateurs puissent apprécier la possibilité de consulter les actualités, tout cela est abondamment disponible ailleurs. D'autres peuvent directement ou indirectement le classer comme promotion ou même publicité. Microsoft utilise des interfaces pour promouvoir son propre contenu,
 Une plongée approfondie dans les modèles, les données et les frameworks : une revue exhaustive de 54 pages de grands modèles de langage efficaces
Jan 14, 2024 pm 07:48 PM
Une plongée approfondie dans les modèles, les données et les frameworks : une revue exhaustive de 54 pages de grands modèles de langage efficaces
Jan 14, 2024 pm 07:48 PM
Les modèles linguistiques à grande échelle (LLM) ont démontré des capacités convaincantes dans de nombreuses tâches importantes, notamment la compréhension du langage naturel, la génération de langages et le raisonnement complexe, et ont eu un impact profond sur la société. Cependant, ces capacités exceptionnelles nécessitent des ressources de formation importantes (illustrées dans l’image de gauche) et de longs temps d’inférence (illustrés dans l’image de droite). Les chercheurs doivent donc développer des moyens techniques efficaces pour résoudre leurs problèmes d’efficacité. De plus, comme on peut le voir sur le côté droit de la figure, certains LLM (LanguageModels) efficaces tels que Mistral-7B ont été utilisés avec succès dans la conception et le déploiement de LLM. Ces LLM efficaces peuvent réduire considérablement la mémoire d'inférence tout en conservant une précision similaire à celle du LLaMA1-33B
 Comment rechercher des utilisateurs à Xianyu
Feb 24, 2024 am 11:25 AM
Comment rechercher des utilisateurs à Xianyu
Feb 24, 2024 am 11:25 AM
Comment Xianyu recherche-t-il des utilisateurs ? Dans le logiciel Xianyu, nous pouvons trouver directement les utilisateurs avec lesquels nous souhaitons communiquer dans le logiciel. Mais je ne sais pas comment rechercher des utilisateurs. Visualisez-le simplement parmi les utilisateurs après la recherche. Vient ensuite l'introduction que l'éditeur propose aux utilisateurs sur la façon de rechercher des utilisateurs. Si vous êtes intéressé, venez jeter un œil ! Comment rechercher des utilisateurs dans Xianyu ? Réponse : Afficher les détails parmi les utilisateurs recherchés Introduction : 1. Entrez le logiciel et cliquez sur la zone de recherche. 2. Entrez le nom d'utilisateur et cliquez sur Rechercher. 3. Sélectionnez ensuite [Utilisateur] sous la zone de recherche pour trouver l'utilisateur correspondant.
 Comment utiliser la recherche avancée Baidu
Feb 22, 2024 am 11:09 AM
Comment utiliser la recherche avancée Baidu
Feb 22, 2024 am 11:09 AM
Comment utiliser la recherche avancée Baidu Le moteur de recherche Baidu est actuellement l'un des moteurs de recherche les plus utilisés en Chine. Il offre une multitude de fonctions de recherche, dont la recherche avancée. La recherche avancée peut aider les utilisateurs à rechercher les informations dont ils ont besoin avec plus de précision et à améliorer l'efficacité de la recherche. Alors, comment utiliser la recherche avancée Baidu ? La première étape consiste à ouvrir la page d’accueil du moteur de recherche Baidu. Tout d’abord, nous devons ouvrir le site officiel de Baidu, qui est www.baidu.com. C'est l'entrée de la recherche Baidu. Dans la deuxième étape, cliquez sur le bouton Recherche avancée. Sur le côté droit du champ de recherche Baidu, il y a
 La table WPS ne trouve pas les données que vous recherchez, veuillez vérifier l'emplacement de l'option de recherche
Mar 19, 2024 pm 10:13 PM
La table WPS ne trouve pas les données que vous recherchez, veuillez vérifier l'emplacement de l'option de recherche
Mar 19, 2024 pm 10:13 PM
À l'ère dominée par l'intelligence, les logiciels de bureautique sont également devenus populaires et les formulaires Wps sont adoptés par la majorité des employés de bureau en raison de leur flexibilité. Au travail, nous devons non seulement apprendre à créer des formulaires simples et à saisir du texte, mais également à maîtriser des compétences plus opérationnelles afin d'accomplir les tâches du travail réel. Les rapports contenant des données et l'utilisation de formulaires sont plus pratiques, clairs et précis. La leçon que nous vous apportons aujourd'hui est la suivante : la table WPS ne trouve pas les données que vous recherchez. Pourquoi veuillez vérifier l'emplacement de l'option de recherche ? 1. Sélectionnez d'abord le tableau Excel et double-cliquez pour l'ouvrir. Ensuite dans cette interface, sélectionnez toutes les cellules. 2. Ensuite, dans cette interface, cliquez sur l'option « Modifier » dans « Fichier » dans la barre d'outils supérieure. 3. Deuxièmement, dans cette interface, cliquez sur «
 Crushing H100, le GPU nouvelle génération de Nvidia se dévoile ! La première conception de module multipuce 3 nm, dévoilée en 2024
Sep 30, 2023 pm 12:49 PM
Crushing H100, le GPU nouvelle génération de Nvidia se dévoile ! La première conception de module multipuce 3 nm, dévoilée en 2024
Sep 30, 2023 pm 12:49 PM
Processus 3 nm, les performances dépassent le H100 ! Récemment, le média étranger DigiTimes a annoncé que Nvidia développait le GPU de nouvelle génération, le B100, dont le nom de code est "Blackwell". Il s'agirait d'un produit destiné aux applications d'intelligence artificielle (IA) et de calcul haute performance (HPC). , le B100 utilisera le processus de traitement 3 nm de TSMC, ainsi qu'une conception de module multi-puces (MCM) plus complexe, et apparaîtra au quatrième trimestre 2024. Pour Nvidia, qui monopolise plus de 80 % du marché des GPU d’intelligence artificielle, il peut utiliser le B100 pour frapper pendant que le fer est chaud et attaquer davantage des challengers comme AMD et Intel dans cette vague de déploiement d’IA. Selon les estimations de NVIDIA, d'ici 2027, la valeur de production de ce domaine devrait atteindre environ
 Comment rechercher des magasins sur mobile Taobao Comment rechercher des noms de magasins
Mar 13, 2024 am 11:00 AM
Comment rechercher des magasins sur mobile Taobao Comment rechercher des noms de magasins
Mar 13, 2024 am 11:00 AM
Le logiciel de l'application mobile Taobao propose de nombreux bons produits. Vous pouvez les acheter à tout moment et n'importe où, et tout est authentique. Il n'y a aucune opération compliquée, ce qui vous permet de faire des achats plus pratiques. Vous pouvez rechercher et acheter librement à votre guise. Les sections de produits des différentes catégories sont toutes ouvertes. Ajoutez votre adresse de livraison personnelle et votre numéro de contact pour permettre à l'entreprise de messagerie de vous contacter, et vérifiez les dernières tendances logistiques en temps réel. les utilisateurs l'utilisent pour la première fois. Si vous ne savez pas comment rechercher des produits, il vous suffit bien sûr de saisir des mots-clés dans la barre de recherche pour trouver tous les résultats des produits. Vous ne pouvez pas arrêter d'acheter librement. L'éditeur fournira des méthodes en ligne détaillées permettant aux utilisateurs mobiles de Taobao de rechercher des noms de magasins. 1. Ouvrez d'abord l'application Taobao sur votre téléphone mobile,
 La revue la plus complète des grands modèles multimodaux est ici ! 7 chercheurs Microsoft ont coopéré vigoureusement, 5 thèmes majeurs, 119 pages de document
Sep 25, 2023 pm 04:49 PM
La revue la plus complète des grands modèles multimodaux est ici ! 7 chercheurs Microsoft ont coopéré vigoureusement, 5 thèmes majeurs, 119 pages de document
Sep 25, 2023 pm 04:49 PM
La revue la plus complète des grands modèles multimodaux est ici ! Écrit par 7 chercheurs chinois de Microsoft, il compte 119 pages - il part de deux types d'orientations de recherche multimodales sur grands modèles qui ont été complétées et sont toujours à l'avant-garde, et résume de manière exhaustive cinq sujets de recherche spécifiques : la compréhension visuelle et la génération visuelle. L'agent multimodal grand modèle multimodal supporté par le modèle visuel unifié LLM se concentre sur un phénomène : le modèle de base multimodal est passé de spécialisé à universel. Ps. C'est pourquoi l'auteur a directement dessiné une image de Doraemon au début de l'article. Qui devrait lire cette critique (rapport) ? Dans les mots originaux de Microsoft : tant que vous souhaitez apprendre les connaissances de base et les derniers progrès des modèles de base multimodaux, que vous soyez un chercheur professionnel ou un étudiant, ce contenu est très approprié pour vous réunir.
