
 Périphériques technologiques
IA
Apprentissage automatique en libre-service basé sur des bases de données intelligentes
Périphériques technologiques
IA
Apprentissage automatique en libre-service basé sur des bases de données intelligentes
Apprentissage automatique en libre-service basé sur des bases de données intelligentes


Traducteur | Zhang Yi
Critique | Liang Ce Sun Shujuan
1 Comment devenir un IDO ?
IDO (organisation axée sur la perspicacité) fait référence à une organisation axée sur la perspicacité (orientée vers l'information). Pour devenir un IDO, vous avez d'abord besoin de données et d'outils pour exploiter et analyser les données ; deuxièmement, d'un analyste de données ou d'un data scientist possédant l'expérience appropriée et enfin, vous devez trouver une technologie ou une méthode pour mettre en œuvre une prise de décision fondée sur la connaissance ; processus dans toute l’entreprise.
Le Machine Learning est une technologie qui peut maximiser les avantages des données. Le processus ML utilise d'abord les données pour entraîner un modèle de prédiction, puis résout les problèmes liés aux données une fois la formation réussie. Parmi eux, les réseaux de neurones artificiels constituent la technologie la plus efficace, et leur conception découle de notre compréhension actuelle du fonctionnement du cerveau humain. Compte tenu des vastes ressources informatiques dont disposent actuellement les gens, cela peut produire des modèles incroyables entraînés sur d’énormes quantités de données.
Les entreprises peuvent utiliser divers logiciels et scripts en libre-service pour effectuer différentes tâches afin d'éviter les erreurs humaines. De même, vous pouvez prendre des décisions basées sur des données pour éviter les erreurs humaines.
2. Pourquoi les entreprises tardent-elles à adopter l'intelligence artificielle ?
Seules quelques entreprises utilisent l'intelligence artificielle ou l'apprentissage automatique pour traiter les données. Le US Census Bureau a déclaré qu’en 2020, moins de 10 % des entreprises américaines avaient adopté l’apprentissage automatique (principalement de grandes entreprises).
Les obstacles à l'adoption du ML comprennent :
- L'IA a encore beaucoup de travail à faire avant de pouvoir remplacer les humains. La première est que de nombreuses entreprises manquent de professionnels et n’en ont pas les moyens. Les data scientists sont très appréciés dans ce domaine, mais ils sont aussi les plus chers à embaucher.
- Manque de données disponibles, sécurité des données et mise en œuvre fastidieuse d'algorithmes de ML.
- Il est difficile pour les entreprises de créer un environnement dans lequel les données et leurs avantages peuvent être pleinement utilisés. Cet environnement nécessite des outils, des processus et des stratégies pertinents.
3. Seuls les outils de ML automatique (AutoML) ne suffisent pas pour promouvoir l'apprentissage automatique
Bien que la plateforme de ML automatique ait un bel avenir, sa couverture est encore assez limitée. Dans le même temps, il n'est pas clair si elle est automatique. ML pourrait bientôt remplacer les data scientists. Cette déclaration suscite également une controverse.
Si vous souhaitez déployer avec succès le machine learning en libre-service dans votre entreprise, les outils AutoML sont en effet cruciaux, mais les processus, méthodes et stratégies doivent également être pris en compte. Les plateformes AutoML ne sont que des outils, et la plupart des experts en ML estiment que cela ne suffit pas.
4. Décomposer le processus d'apprentissage automatique

Tout processus de ML commence par des données. Il est généralement admis que la préparation des données est la partie la plus importante du processus de ML et que la partie modélisation n'est qu'une partie du pipeline global de données, tout en étant simplifiée grâce aux outils AutoML. Le flux de travail complet nécessite encore beaucoup de travail pour transformer les données et les alimenter dans le modèle. La préparation et la transformation des données peuvent être parmi les parties les plus chronophages et les plus désagréables du travail.
De plus, les données commerciales utilisées pour entraîner les modèles ML sont également mises à jour régulièrement. Par conséquent, cela oblige les entreprises à créer des pipelines ETL complexes capables de maîtriser des outils et des processus complexes. Garantir la continuité et la nature en temps réel du processus de ML est également une tâche difficile.
5. Intégrer le ML aux applications
Supposons maintenant que nous avons construit le modèle ML et que nous devions ensuite le déployer. L'approche de déploiement classique le traite comme un composant de couche application, comme indiqué ci-dessous :
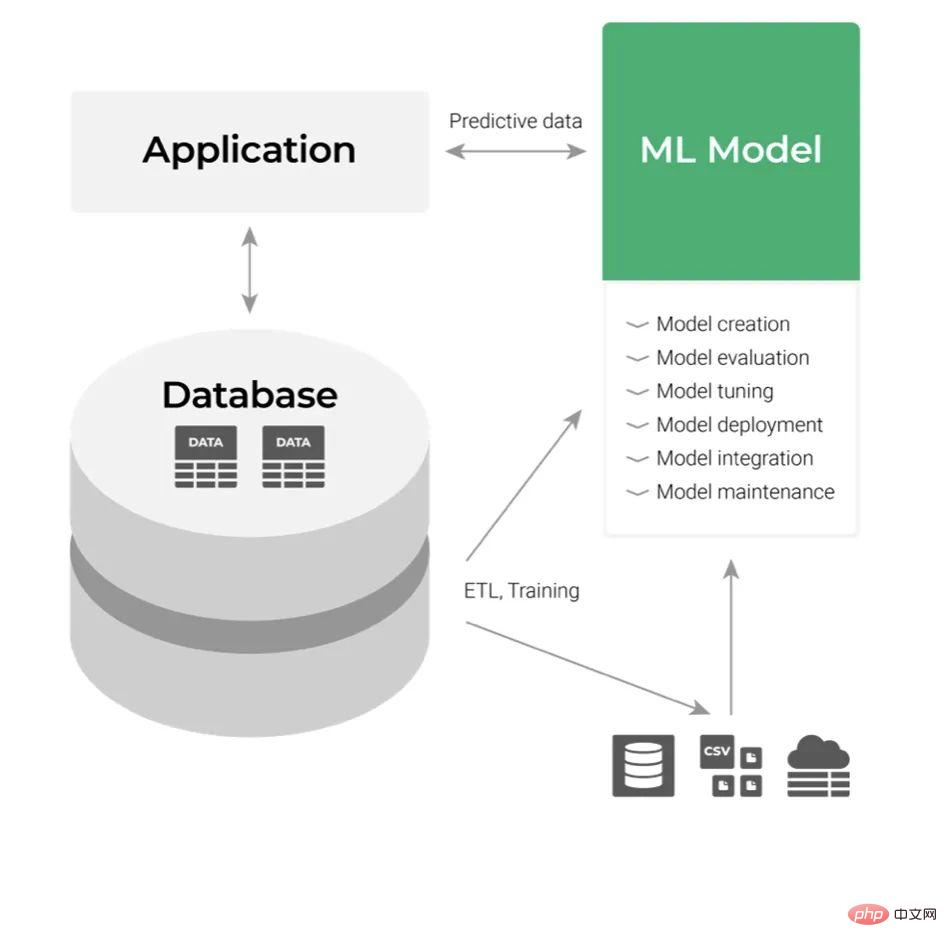
Son entrée est les données et la sortie est la prédiction que nous obtenons. Consommez la sortie des modèles ML en intégrant les API de ces applications. Tout cela semble facile du point de vue du développeur, mais pas quand on pense au processus. Dans une grande organisation, toute intégration et maintenance avec des applications métier peut s’avérer assez fastidieuse. Même si l'entreprise maîtrise la technologie, toute demande de modification du code doit passer par un processus d'examen et de test spécifique à plusieurs niveaux de départements. Cela affecte négativement la flexibilité et augmente la complexité du flux de travail global.
S'il y a suffisamment de flexibilité pour tester divers concepts et idées, la prise de décision basée sur le ML sera beaucoup plus facile et les gens préféreront donc les produits dotés de capacités en libre-service.
6. Apprentissage automatique en libre-service/base de données intelligente ?
Comme nous l'avons vu ci-dessus, les données sont au cœur du processus de ML, les outils de ML existants prennent les données et renvoient des prédictions, et ces prédictions se présentent également sous la forme de données.
Vient maintenant la question :
- Pourquoi faisons-nous du ML une application autonome et implémentons-nous une intégration complexe entre les modèles, les applications et les bases de données de ML ?
- Pourquoi ne pas faire du ML une fonctionnalité de base de la base de données Quoi ?
- Pourquoi ne pas faire du ML ? modèles disponibles via une syntaxe de base de données standard comme SQL ?
Analysons les problèmes ci-dessus et leurs défis pour trouver des solutions de ML.
Défi n°1 : Intégration de données complexes et pipelines ETL
Maintenir l'intégration de données complexes et les pipelines ETL entre les modèles ML et les bases de données est l'un des plus grands défis auxquels sont confrontés les processus ML.
SQL est un excellent outil de manipulation de données, nous pouvons donc résoudre ce problème en introduisant des modèles ML dans la couche de données. En d’autres termes, le modèle ML apprendra dans la base de données et renverra des prédictions.
Défi n°2 : Intégration de modèles ML avec des applications
L'intégration de modèles ML avec des applications métier via des API est un autre défi à relever.
Les applications métiers et les outils BI sont étroitement couplés aux bases de données. Par conséquent, si l'outil AutoML devient partie intégrante de la base de données, nous pouvons utiliser la syntaxe SQL standard pour effectuer des prédictions. Ensuite, l'intégration d'API entre les modèles ML et les applications métier n'est plus nécessaire car les modèles résident dans la base de données.
Solution : Intégrer AutoML dans la base de données
L'intégration des outils AutoML dans la base de données apporte de nombreux avantages, tels que :
- Quiconque travaille avec des données et comprend SQL (analyste de données ou scientifique des données) peut profiter de la puissance de l'apprentissage automatique.
- Les développeurs de logiciels peuvent intégrer plus efficacement le ML dans les outils et applications métier.
- Aucune intégration complexe requise entre les données et les modèles, et entre les modèles et les applications métier.
De cette façon, le diagramme d'intégration relativement complexe ci-dessus change comme suit :
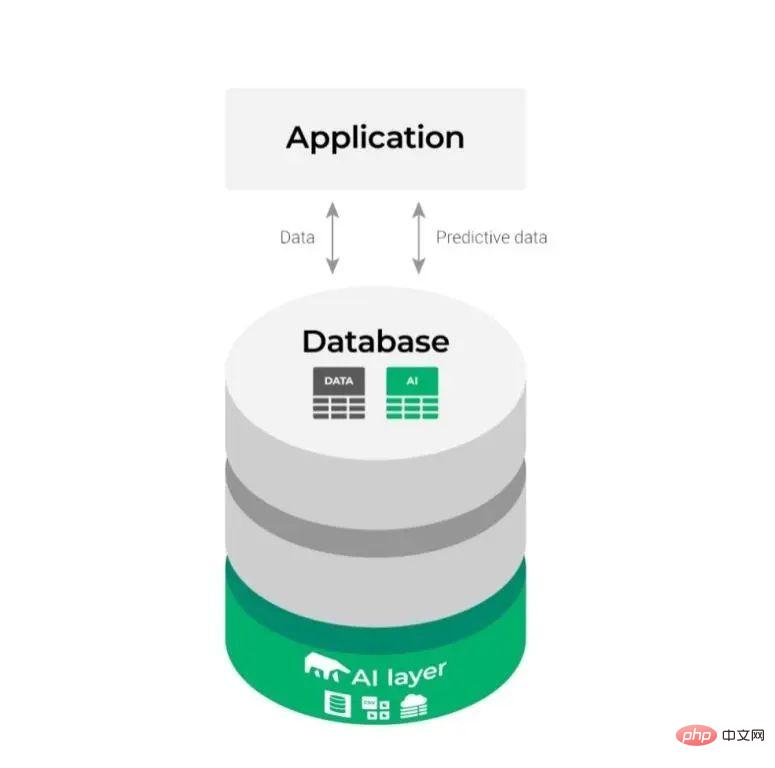
Il semble plus simple et rend le processus de ML plus fluide et plus efficace.
7. Comment implémenter le ML en libre-service en utilisant des modèles comme tables de base de données virtuelles
La prochaine étape pour trouver la solution consiste à la mettre en œuvre.
Pour cela, nous utilisons une structure appelée AI Tables. Il apporte l'apprentissage automatique à la plateforme de données sous forme de tables virtuelles. Elle peut être créée comme n'importe quelle autre table de base de données, puis exposée aux applications, aux outils de BI et aux clients de base de données. Nous faisons des prédictions en interrogeant simplement les données.
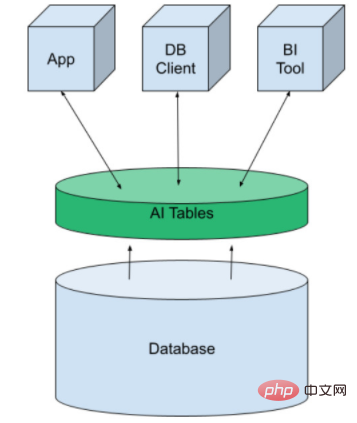
AI Tables a été initialement développé par MindsDB et est disponible sous forme de service open source ou cloud géré. Ils intègrent des bases de données SQL et NoSQL traditionnelles telles que Kafka et Redis.
8. Utilisation des tables AI
Le concept des tables AI nous permet d'effectuer le processus ML dans la base de données afin que toutes les étapes du processus ML (c'est-à-dire la préparation des données, la formation du modèle et la prédiction) puissent être effectuées via la base de données.
- Formation des tables AI
Tout d'abord, les utilisateurs doivent créer une table AI en fonction de leurs propres besoins, qui est similaire à un modèle d'apprentissage automatique et contient des fonctionnalités équivalentes aux colonnes de la table source, puis le reste est complété par ; les tâches de modélisation en libre-service du moteur AutoML. Des exemples seront donnés plus tard.
- Faites des prédictions
Une fois l'AI Table créée, elle est prête à être utilisée sans autre déploiement. Pour faire des prédictions, exécutez simplement une requête SQL standard sur la table AI.
Vous pouvez faire des prédictions une par une ou par lots. Les tables AI peuvent gérer de nombreuses tâches complexes d'apprentissage automatique, telles que les séries temporelles multivariées, la détection d'anomalies, etc.
9.AI Tables Exemple de travail
Pour les détaillants, s'assurer que les produits sont en stock au bon moment est une tâche complexe. Lorsque la demande augmente, l’offre augmente. Sur la base de ces données et de l'apprentissage automatique, nous pouvons prédire la quantité de stock qu'un produit donné devrait avoir un jour donné, ce qui générera plus de revenus pour les détaillants.
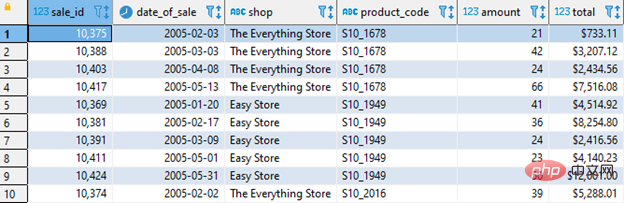
Vous devez d'abord suivre les informations suivantes et créer un tableau AI :
- Date de vente du produit (date_of_sale)
- Produit vendu en magasin (boutique)
- Produit vendu spécifique (code_produit)
- Quantité du produit vendu (montant)
Comme le montre la figure ci-dessous :
(1) Formation des tables AI
Pour créer et entraîner des tables AI, vous devez d'abord autoriser MindsDB à accéder aux données. Pour des instructions détaillées, veuillez vous référer à la documentation MindsDB.
Les tables AI sont comme des modèles ML et nécessitent des données historiques pour les entraîner.
Ce qui suit utilise une simple commande SQL pour entraîner une AITable :

Analysons cette requête :
- Utilisez l'instruction CREATE PREDICTOR dans MindsDB.
- Définissez la base de données source en fonction des données historiques.
- Entraînez la table AI en fonction de la table de données historiques (historical_table) et les colonnes sélectionnées (column_1 et column_2) sont des fonctionnalités utilisées pour la prédiction.
- AutoML termine automatiquement les tâches de modélisation restantes.
- MindsDB identifiera le type de données de chaque colonne, le normalisera et l'encodera, puis construira et entraînera le modèle ML.
En même temps, vous pouvez voir l'exactitude et la confiance globales de chaque prédiction et estimer quelles colonnes (caractéristiques) sont les plus importantes pour le résultat.
Dans les bases de données, nous devons souvent gérer des tâches impliquant des données de séries chronologiques multivariées avec une cardinalité élevée. En utilisant les méthodes traditionnelles, des efforts considérables sont nécessaires pour créer de tels modèles ML. Nous devons regrouper les données et les trier en fonction d'un champ de données d'heure, de date ou d'horodatage donné.
Par exemple, nous prédisons le nombre de marteaux vendus dans une quincaillerie. Eh bien, les données sont regroupées par magasin et par produit, et des prédictions sont faites pour chaque combinaison différente de magasin et de produit. Cela nous amène au problème de la création d'un modèle de série chronologique pour chaque groupe.
Cela semble être un projet énorme, mais MindsDB fournit une méthode pour créer un modèle ML unique à l'aide de l'instruction GROUP BY pour former simultanément des données de séries chronologiques multivariées. Voyons comment procéder en utilisant une seule commande SQL :

Le prédicteur stock_forecaster a été créé pour prédire combien d'articles un magasin particulier vendra à l'avenir. Les données sont triées par date de vente et regroupées par magasin. Nous pouvons donc prédire le montant des ventes pour chaque magasin.
(2) Prédiction par lots
En joignant la table de données de ventes avec le prédicteur à l'aide de la requête ci-dessous, l'opération JOIN ajoute la quantité prédite aux enregistrements, afin que nous puissions obtenir des prédictions par lots pour plusieurs enregistrements à la fois.

Pour en savoir plus sur l'analyse et la visualisation des prédictions dans les outils BI, consultez cet article.
(3) Application pratique
Les approches traditionnelles traitent les modèles ML comme des applications indépendantes, nécessitant la maintenance des pipelines ETL vers la base de données et l'intégration d'API aux applications métier. Bien que les outils AutoML rendent la partie modélisation simple et directe, la gestion du flux de travail ML complet nécessite toujours des experts expérimentés. En fait, la base de données est déjà l'outil préféré pour la préparation des données, il est donc plus logique d'introduire le ML dans la base de données plutôt que d'introduire des données dans le ML. Étant donné que les outils AutoML résident dans la base de données, la construction AI Tables de MindsDB fournit aux praticiens des données AutoML en libre-service et rationalise les flux de travail d'apprentissage automatique.
Lien original : https://dzone.com/articles/self-service-machine-learning-with-intelligent-dat
Introduction au traducteur
Zhang Yi, rédacteur de la communauté 51CTO, ingénieur intermédiaire. Recherche principalement la mise en œuvre d'algorithmes d'intelligence artificielle et d'applications de scénarios, possède une compréhension et une maîtrise des algorithmes d'apprentissage automatique et des algorithmes de contrôle automatique, et continuera de prêter attention aux tendances de développement de la technologie de l'intelligence artificielle au pays et à l'étranger, en particulier l'application de l'intelligence artificielle. technologie d’intelligence dans les voitures connectées intelligentes et les maisons intelligentes. Mise en œuvre spécifique et applications dans d’autres domaines.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
 Apprentissage automatique en C++ : un guide pour la mise en œuvre d'algorithmes d'apprentissage automatique courants en C++
Jun 03, 2024 pm 07:33 PM
Apprentissage automatique en C++ : un guide pour la mise en œuvre d'algorithmes d'apprentissage automatique courants en C++
Jun 03, 2024 pm 07:33 PM
En C++, la mise en œuvre d'algorithmes d'apprentissage automatique comprend : Régression linéaire : utilisée pour prédire des variables continues. Les étapes comprennent le chargement des données, le calcul des poids et des biais, la mise à jour des paramètres et la prédiction. Régression logistique : utilisée pour prédire des variables discrètes. Le processus est similaire à la régression linéaire, mais utilise la fonction sigmoïde pour la prédiction. Machine à vecteurs de support : un puissant algorithme de classification et de régression qui implique le calcul de vecteurs de support et la prédiction d'étiquettes.
 iOS 18 ajoute une nouvelle fonction d'album 'Récupéré' pour récupérer les photos perdues ou endommagées
Jul 18, 2024 am 05:48 AM
iOS 18 ajoute une nouvelle fonction d'album 'Récupéré' pour récupérer les photos perdues ou endommagées
Jul 18, 2024 am 05:48 AM
Les dernières versions d'Apple des systèmes iOS18, iPadOS18 et macOS Sequoia ont ajouté une fonctionnalité importante à l'application Photos, conçue pour aider les utilisateurs à récupérer facilement des photos et des vidéos perdues ou endommagées pour diverses raisons. La nouvelle fonctionnalité introduit un album appelé "Récupéré" dans la section Outils de l'application Photos qui apparaîtra automatiquement lorsqu'un utilisateur a des photos ou des vidéos sur son appareil qui ne font pas partie de sa photothèque. L'émergence de l'album « Récupéré » offre une solution aux photos et vidéos perdues en raison d'une corruption de la base de données, d'une application d'appareil photo qui n'enregistre pas correctement dans la photothèque ou d'une application tierce gérant la photothèque. Les utilisateurs n'ont besoin que de quelques étapes simples
 Tutoriel détaillé sur l'établissement d'une connexion à une base de données à l'aide de MySQLi en PHP
Jun 04, 2024 pm 01:42 PM
Tutoriel détaillé sur l'établissement d'une connexion à une base de données à l'aide de MySQLi en PHP
Jun 04, 2024 pm 01:42 PM
Comment utiliser MySQLi pour établir une connexion à une base de données en PHP : Inclure l'extension MySQLi (require_once) Créer une fonction de connexion (functionconnect_to_db) Appeler la fonction de connexion ($conn=connect_to_db()) Exécuter une requête ($result=$conn->query()) Fermer connexion ( $conn->close())
 Comment gérer les erreurs de connexion à la base de données en PHP
Jun 05, 2024 pm 02:16 PM
Comment gérer les erreurs de connexion à la base de données en PHP
Jun 05, 2024 pm 02:16 PM
Pour gérer les erreurs de connexion à la base de données en PHP, vous pouvez utiliser les étapes suivantes : Utilisez mysqli_connect_errno() pour obtenir le code d'erreur. Utilisez mysqli_connect_error() pour obtenir le message d'erreur. En capturant et en enregistrant ces messages d'erreur, les problèmes de connexion à la base de données peuvent être facilement identifiés et résolus, garantissant ainsi le bon fonctionnement de votre application.
 Applications d'apprentissage automatique Golang : création d'algorithmes intelligents et de solutions basées sur les données
Jun 02, 2024 pm 06:46 PM
Applications d'apprentissage automatique Golang : création d'algorithmes intelligents et de solutions basées sur les données
Jun 02, 2024 pm 06:46 PM
Utilisez l'apprentissage automatique dans Golang pour développer des algorithmes intelligents et des solutions basées sur les données : installez la bibliothèque Gonum pour les algorithmes et utilitaires d'apprentissage automatique. Régression linéaire utilisant le modèle LinearRegression de Gonum, un algorithme d'apprentissage supervisé. Entraînez le modèle à l'aide de données d'entraînement, qui contiennent des variables d'entrée et des variables cibles. Prédisez les prix de l’immobilier en fonction de nouvelles caractéristiques, à partir desquelles le modèle extraira une relation linéaire.
