
 Périphériques technologiques
IA
Meituan se classe premier dans la petite liste d'apprentissage FewCLUE ! Apprentissage rapide + pratique d'auto-formation
Périphériques technologiques
IA
Meituan se classe premier dans la petite liste d'apprentissage FewCLUE ! Apprentissage rapide + pratique d'auto-formation
Meituan se classe premier dans la petite liste d'apprentissage FewCLUE ! Apprentissage rapide + pratique d'auto-formation

Auteur : Luo Ying, Xu Jun, Xie Rui, etc.
1 Aperçu
CLUE (Chinese Language Understanding Evaluation)[1] est une liste d'évaluation faisant autorité de la compréhension de la langue chinoise, y compris la classification des textes, l'inter -la relation entre les phrases, la compréhension de la lecture et de nombreuses autres sous-tâches d'analyse sémantique et de compréhension sémantique ont eu un grand impact sur le monde universitaire et l'industrie.

Figure 1 Liste FewCLUE (au 18/04/2022)
FewCLUE[2,3] est une sous-liste de CLUE spécialement utilisée pour l'évaluation de l'apprentissage de petits échantillons de chinois. les capacités de généralisation universelles et puissantes du modèle linguistique pré-entraîné, explorent le meilleur modèle pour l'apprentissage par petits échantillons et sa pratique en chinois. Certains des ensembles de données de FewCLUE ne contiennent que plus d'une centaine d'échantillons étiquetés, qui peuvent mesurer les performances de généralisation du modèle avec très peu d'échantillons étiquetés. Après sa publication, il a attiré l'attention de NetEase, WeChat AI, Alibaba, IDEA Research Institute et. Inspur Artificial Intelligence Research L’institut et de nombreuses autres entreprises et instituts de recherche ont participé. Il n'y a pas si longtemps, le modèle d'apprentissage sur petits échantillons FSL++ de l'équipe de compréhension sémantique du centre PNL du département de recherche et de PNL de Meituan a remporté la première place sur la liste FewCLUE grâce à ses performances supérieures, atteignant le niveau SOTA.
2 Introduction à la méthode
Bien que les modèles de pré-entraînement à grande échelle obtiennent de très bons résultats dans diverses tâches majeures, ils nécessitent toujours beaucoup de données étiquetées pour des tâches spécifiques. Les différentes activités de Meituan disposent d'une multitude de scénarios NLP, qui nécessitent souvent des coûts d'étiquetage manuel élevés. Dans les premiers stades du développement commercial ou lorsque de nouveaux besoins commerciaux doivent être lancés rapidement, les échantillons étiquetés seront souvent insuffisants. La méthode de formation en deep learning utilisant le traditionnel Pretrain (pré-formation) + Fine-Tune (mise au point fine). ) ne peut souvent pas atteindre l'objectif requis. Il devient donc très nécessaire d'étudier le problème de formation du modèle dans de petits exemples de scénarios.
Cet article propose un ensemble de programmes de formation conjoints grand modèle + petit échantillon FSL++, qui combine des stratégies d'optimisation de modèle telles que l'optimisation de la structure du modèle, la pré-formation à grande échelle, l'amélioration des échantillons, l'apprentissage d'ensemble et l'auto-formation, et enfin atteint le niveau faisant autorité dans la compréhension de la langue chinoise La liste FewCLUE sous le critère d'évaluation a obtenu d'excellents résultats et ses performances dépassent les niveaux humains sur certaines tâches, tandis que sur certaines tâches (telles que CLUEWSC) il y a encore place à l'amélioration.
Après la sortie de FewCLUE, NetEase Fuxi a utilisé le modèle EET auto-développé[4], et a amélioré la compréhension sémantique du modèle grâce à une formation secondaire, puis a ajouté des modèles pour l'apprentissage multitâche de l'IDEA Research Institute ; Modèle Erlangshen[ 5]Utilisez une technologie de pré-formation plus avancée pour former de grands modèles basés sur le modèle BERT et utilisez le modèle de langage masqué (MLM) avec une stratégie de masque dynamique comme tâche auxiliaire dans le processus de réglage fin des tâches en aval. Ces méthodes utilisent toutes Prompt Learning comme structure de tâche de base. Par rapport à ces grands modèles auto-développés, notre méthode ajoute principalement des stratégies d'optimisation de modèle telles que l'amélioration des échantillons, l'apprentissage d'ensemble et l'auto-apprentissage basé sur le cadre Prompt Learning, ce qui améliore considérablement. Améliorez les performances des tâches et la robustesse du modèle. Dans le même temps, cette méthode peut être appliquée à divers modèles de pré-formation, ce qui la rend plus flexible et plus pratique.
La structure globale du modèle de FSL++ est présentée dans la figure 2 ci-dessous. L'ensemble de données FewCLUE fournit 160 données étiquetées et près de 20 000 données non étiquetées pour chaque tâche. Dans cette pratique FewCLUE, nous avons d'abord construit un apprentissage rapide multi-modèles au cours de l'étape de réglage fin et utilisé des stratégies d'amélioration telles que la formation contradictoire, l'apprentissage contrastif et le mélange pour les données étiquetées. Étant donné que ces stratégies d'amélioration des données utilisent des principes d'amélioration différents, on peut considérer que les différences entre ces modèles sont relativement importantes et donneront de meilleurs résultats après un apprentissage intégré. Par conséquent, après avoir utilisé la stratégie d'amélioration des données pour la formation, nous disposons de plusieurs modèles faiblement supervisés et utilisons ces modèles faiblement supervisés pour prédire sur des données non étiquetées afin d'obtenir la distribution pseudo-étiquette des données non étiquetées. Après cela, nous intégrons plusieurs distributions de pseudo-étiquettes de données non étiquetées prédites par différents modèles d'amélioration des données pour obtenir une distribution totale de pseudo-étiquettes de données non étiquetées, puis reconstruisons l'apprentissage rapide multi-modèles et utilisons à nouveau les données. Améliorez la stratégie et choisissez la stratégie optimale. Actuellement, notre expérience n’effectue qu’une seule itération, et nous pouvons également tenter plusieurs itérations. Cependant, à mesure que le nombre d’itérations augmente, l’amélioration ne sera plus évidente.

Figure 2 Cadre du modèle FSL++
2.1 Pré-formation améliorée
Le modèle de langage pré-entraîné est formé sur un énorme corpus non étiqueté. Par exemple, RoBERTa[6] est formé sur plus de 160 Go de texte, notamment des encyclopédies, des articles de presse, des œuvres littéraires et du contenu Web. Les représentations apprises par ces modèles permettent d'obtenir d'excellentes performances sur des tâches impliquant des ensembles de données de différentes tailles provenant de plusieurs sources. Le modèle
FSL++ utilise le modèle RoBERTa-large comme modèle de base et adopte le pré-entraînement adaptatif au domaine (DAPT)[7]la méthode de pré-entraînement et le pré-entraînement adaptatif aux tâches (TAPT) qui intègre la connaissance du domaine )[7]. DAPT vise à ajouter une grande quantité de texte non étiqueté sur le terrain pour continuer à entraîner le modèle de langage basé sur le modèle pré-entraîné, puis à l'affiner sur l'ensemble de données de la tâche spécifiée.
Poursuivre la pré-formation sur le domaine de texte cible peut améliorer les performances du modèle de langage, notamment sur les tâches en aval liées au domaine de texte cible. De plus, plus la corrélation entre le texte de pré-formation et le domaine de tâches est élevée, plus l'amélioration est importante. Dans cette pratique, nous avons finalement utilisé le modèle RoBERTa Large pré-entraîné sur CLUE Vocab[8], qui contient 100G de programmes de divertissement, de sport, de santé, d'affaires internationales, de films, de célébrités et d'autres domaines. TAPT fait référence à l'ajout d'une petite quantité de corpus non étiqueté directement lié à la tâche sur la base du modèle pré-entraîné pour la pré-formation. Pour la tâche TAPT, les données de pré-entraînement que nous avons choisi d'utiliser sont les données non étiquetées fournies par la liste FewCLUE pour chaque tâche.
De plus, dans la pratique des tâches de relation inter-phrases, telles que la tâche d'inférence en langue naturelle chinoise OCNLI, la tâche de correspondance de texte court de dialogue chinois BUSTM, nous utilisons d'autres tâches de relation inter-phrases telles que l'ensemble de données d'inférence en langue naturelle chinoise. Les paramètres du modèle pré-entraînés sur l'ensemble de données de similarité de texte court chinois LCQMC sont utilisés comme paramètres initiaux. Par rapport à l'utilisation directe du modèle d'origine pour accomplir la tâche, cela peut également améliorer l'effet dans une certaine mesure.
2.2 Structure du modèle
FewCLUE contient une variété de formulaires de tâches et nous avons sélectionné une structure de modèle appropriée pour chaque tâche. Les mots de catégorie des tâches de classification de texte et de compréhension en lecture automatique (MRC) contiennent eux-mêmes des informations, ils sont donc plus adaptés pour être modélisés sous la forme d'un modèle de langage masqué (MLM) tandis que la tâche de relation inter-phrases détermine ; la corrélation entre deux phrases, plus similaire au formulaire de tâche Next Sentence Prediction (NSP)[9]. Par conséquent, nous choisissons le modèle PET[10] pour les tâches de classification et les tâches de compréhension en lecture, et le modèle EFL[11] pour les tâches de relations inter-phrases. La méthode EFL peut construire des échantillons négatifs grâce à un échantillonnage global et apprendre de manière plus robuste. dispositif de classement.
2.2.1 Prompt Learning
L'objectif principal de Prompt Learning est de minimiser l'écart entre l'objectif de pré-formation et l'objectif de réglage fin en aval. Les tâches de pré-formation généralement existantes incluent des fonctions de perte MLM, mais les tâches en aval n'utilisent pas MLM, mais introduisent de nouveaux classificateurs, provoquant des incohérences entre les tâches de pré-formation et les tâches en aval. Prompt Learning n'introduit pas de classificateurs supplémentaires ou d'autres paramètres, mais transforme la tâche en un formulaire MLM en épissant des modèles (Template, qui assemble des fragments de langage pour les données d'entrée ) et un mappage de mots d'étiquette (Verbalizer, qui est pour chaque étiquette Trouvez le mots correspondants dans le vocabulaire pour définir l'objectif de prédiction pour la tâche MLM), afin que le modèle puisse être utilisé dans des tâches en aval avec un petit nombre d'échantillons.
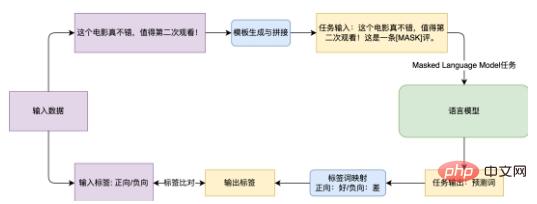
 Figure 3 Organigramme de la méthode d'apprentissage rapide pour effectuer la tâche d'analyse des sentiments
Figure 3 Organigramme de la méthode d'apprentissage rapide pour effectuer la tâche d'analyse des sentiments
Prenons comme exemple la tâche d'analyse des sentiments d'évaluation du commerce électronique EPRSTMT présentée dans la figure 3. Étant donné le texte "Ce film est vraiment bon, il vaut la peine de le regarder une deuxième fois!", la classification de texte traditionnelle consiste à connecter le classificateur à la partie Embedding dans la partie CLS et à le mapper à la classification 0-1 (0 : négatif , 1 : Positif ). Cette méthode nécessite la formation d’un nouveau classificateur dans des scénarios sur petits échantillons, et il est difficile d’obtenir de bons résultats. La méthode basée sur Prompt Learning consiste à créer un modèle « Ceci est un commentaire [MASK] », puis à associer le modèle avec le texte original. Pendant la formation, le modèle de langage prédit le mot à la position [MASK], puis le mappe. vers la catégorie correspondante. Up (bon : positif, mauvais : négatif).
En raison du manque de données suffisantes, il est parfois difficile de déterminer les modèles et les mappages de mots-clés les plus performants. Par conséquent, la conception d’un mappage de mots multi-modèles et multi-étiquettes peut également être adoptée. En concevant plusieurs modèles, le résultat final adopte l'intégration des résultats de plusieurs modèles, ou la conception d'un mappage de mots de balise un à plusieurs afin qu'une balise corresponde à plusieurs mots. Semblable à l'exemple ci-dessus, la combinaison de modèles suivante peut être conçue (à gauche : plusieurs modèles pour la même phrase, à droite : mappage multi-étiquettes).

Figure 4 Cartographie multi-modèles et multi-étiquettes PET
Exemple de tâche

Tableau 1 Construction de modèles PET dans l'ensemble de données FewCLUE
2.2.2 EFL
Le modèle EFL assemble deux phrases ensemble, en utilisant l'intégration à la position [CLS] de la couche de sortie suivie d'un classificateur pour compléter la prédiction. Au cours du processus de formation d'EFL, en plus des échantillons de l'ensemble de formation, des échantillons négatifs sont également construits. Au cours du processus de formation, des phrases dans d'autres données sont sélectionnées au hasard en tant qu'échantillons négatifs dans chaque lot, et l'amélioration des données est effectuée par construction de négatifs. des échantillons. Bien que le modèle EFL doive former un nouveau classificateur, il existe actuellement de nombreux ensembles de données publics d'implication de texte/relations inter-phrases, tels que CMNLI, LCQMC, etc., qui peuvent être appris en continu sur ces échantillons (continue-train) , puis Les paramètres appris sont transférés au scénario de petit échantillon et affinés davantage à l'aide de l'ensemble de données de tâche de FewCLUE. Exemples de tâches Dans le domaine de la PNL, le but de l’augmentation des données est d’étendre les données textuelles sans modifier la sémantique. Les principales méthodes incluent le simple remplacement de texte, l'utilisation de modèles de langage pour générer des phrases similaires, etc. Nous avons essayé des méthodes telles que l'EDA pour développer les données de texte, mais une modification d'un mot peut inverser le sens de la phrase entière et le remplacement le texte contient beaucoup de bruit. Il est donc difficile de générer suffisamment de données augmentées avec de simples changements d'échantillons de règles. Cependant, l'amélioration de l'intégration n'opère plus sur l'entrée, mais opère au niveau de l'intégration. La robustesse du modèle peut être améliorée en ajoutant une perturbation ou une interpolation à l'intégration.
Par conséquent, dans cette pratique, nous effectuons principalement l'amélioration de l'intégration. Les stratégies d'amélioration des données que nous utilisons incluent Mixup[12], Manifold-Mixup[13]
, l'entraînement contradictoire (Adversarial training, AT )
)
et l'apprentissage contrastif R-drop [15].
[15].
 Tableau 3 Brève description de la stratégie d'amélioration des données
Tableau 3 Brève description de la stratégie d'amélioration des données
Mixup peut améliorer la capacité de généralisation du modèle en effectuant une transformation linéaire simple sur les données d'entrée pour construire de nouveaux échantillons combinés et des étiquettes combinées. Sur diverses tâches supervisées ou semi-supervisées, l'utilisation de Mixup peut grandement améliorer la capacité de généralisation du modèle. La méthode Mixup peut être considérée comme une opération de régularisation, qui nécessite que les fonctionnalités combinées générées par le modèle au niveau des fonctionnalités satisfassent à des contraintes linéaires, et utilise cette contrainte pour régulariser le modèle. Intuitivement, lorsque l'entrée du modèle est une combinaison linéaire des deux autres entrées, sa sortie est également une combinaison linéaire de la sortie obtenue après que les deux données sont entrées séparément dans le modèle. En fait, le modèle doit être approximatif. un système linéaire.
Manifold Mixup généralise l'opération Mixup ci-dessus aux fonctionnalités. Étant donné que les entités possèdent des informations sémantiques d’ordre supérieur, l’interpolation sur leurs dimensions peut produire des échantillons plus significatifs. Dans les modèles similaires à BERT[9] et RoBERTa[6], le nombre de couches k est sélectionné au hasard et une interpolation Mixup est effectuée sur la représentation des caractéristiques de cette couche. L'interpolation du Mixup ordinaire se produit dans la partie Embedding de la couche de sortie, et Manifold Mixup équivaut à ajouter cette série d'opérations d'interpolation à une couche aléatoire de la structure Transformers à l'intérieur du modèle de langage.
La formation contradictoire améliore considérablement la perte de modèle en ajoutant de petites perturbations aux échantillons d'entrée. La formation contradictoire consiste à former un modèle capable d'identifier efficacement les échantillons originaux et les échantillons contradictoires. Le principe de base est de construire des échantillons contradictoires en ajoutant des perturbations et de les transmettre au modèle pour la formation, améliorant ainsi la robustesse du modèle face à des échantillons contradictoires, et en même temps améliorant les performances et les capacités de généralisation du modèle. Les exemples contradictoires doivent avoir deux caractéristiques, à savoir :
- Par rapport à l'entrée d'origine, la perturbation ajoutée est infime.
- peut faire commettre des erreurs au modèle. L'entraînement contradictoire a deux fonctions, à savoir améliorer la robustesse du modèle contre les attaques malveillantes et améliorer la capacité de généralisation du modèle.
R-Drop effectue Dropout deux fois sur la même phrase et force les probabilités de sortie des différents sous-modèles générés par Dropout à être cohérentes. Bien que l’introduction de Dropout fonctionne bien, elle peut entraîner des problèmes d’incohérence dans les processus de formation et d’inférence. Afin d'atténuer l'incohérence de ce processus d'inférence de formation, R-Drop régularise Dropout, ajoute des restrictions sur la distribution des données de sortie dans la sortie générée par les deux sous-modèles et introduit la perte de divergence KL de la mesure de la distribution des données, de sorte que la perte de divergence KL au sein du lot. Les deux distributions de données générées par le même échantillon doivent être aussi proches que possible et avoir une cohérence de distribution. Plus précisément, pour chaque échantillon d'apprentissage, R-Drop minimise la divergence KL entre les probabilités de sortie des sous-modèles générés par différents abandons. En tant qu'idée d'entraînement, R-Drop peut être utilisé dans la plupart des entraînements supervisés ou semi-supervisés et est très polyvalent.
Les trois stratégies d'amélioration des données que nous utilisons, Mixup consiste à effectuer des changements linéaires entre deux échantillons dans la couche de sortie. L'intégration du modèle de langage et de la couche de sortie d'une couche aléatoire de Transformers à l'intérieur du modèle de langage, et la formation contradictoire consiste à augmenter le nombre d'échantillons de minuscules perturbations, tandis que l'apprentissage contrastif consiste à effectuer deux abandons sur la même phrase pour former une paire d'échantillons positive, puis à utiliser la divergence KL pour limiter la cohérence des deux sous-modèles. Les trois stratégies améliorent la généralisation du modèle en effectuant certaines opérations d'intégration. Les modèles obtenus grâce à différentes stratégies ont des préférences différentes, ce qui fournit des conditions pour la prochaine étape de l'apprentissage d'ensemble.
2.4 Apprentissage d'ensemble et auto-formation
L'apprentissage d'ensemble peut combiner plusieurs modèles faiblement supervisés afin d'obtenir un modèle fortement supervisé meilleur et plus complet. L'idée sous-jacente de l'apprentissage d'ensemble est que même si un classificateur faible fait une mauvaise prédiction, d'autres classificateurs faibles peuvent corriger l'erreur. Si les différences entre les modèles à combiner sont significatives, l’apprentissage d’ensemble produira généralement un meilleur résultat.
L'auto-formation utilise une petite quantité de données étiquetées et une grande quantité de données non étiquetées pour entraîner conjointement le modèle, en utilisant d'abord le classificateur entraîné pour prédire les étiquettes de toutes les données non étiquetées, puis en sélectionnant les étiquettes avec une plus grande confiance comme Données pseudo-étiquettes, les données pseudo-étiquetées sont combinées avec des données d'entraînement étiquetées par l'homme pour recycler le classificateur.
Ensemble learning + auto-formation est une solution qui peut utiliser plusieurs modèles et données non étiquetées. Parmi elles, les étapes générales de l'apprentissage d'ensemble sont les suivantes : former plusieurs modèles différents faiblement supervisés, utiliser chaque modèle pour prédire la distribution de probabilité d'étiquette de données non étiquetées, calculer la somme pondérée de la distribution de probabilité d'étiquette et obtenir la distribution de probabilité de pseudo-étiquette de données non étiquetées. données. . L'auto-formation fait référence à la formation d'un modèle pour combiner d'autres modèles. Les étapes générales sont les suivantes : former plusieurs modèles d'enseignant, le modèle d'étudiant apprend la prédiction douce d'échantillons à haute confiance dans la distribution de probabilité de pseudo-étiquette et le modèle d'étudiant sert de modèle. dernier apprenant fort.
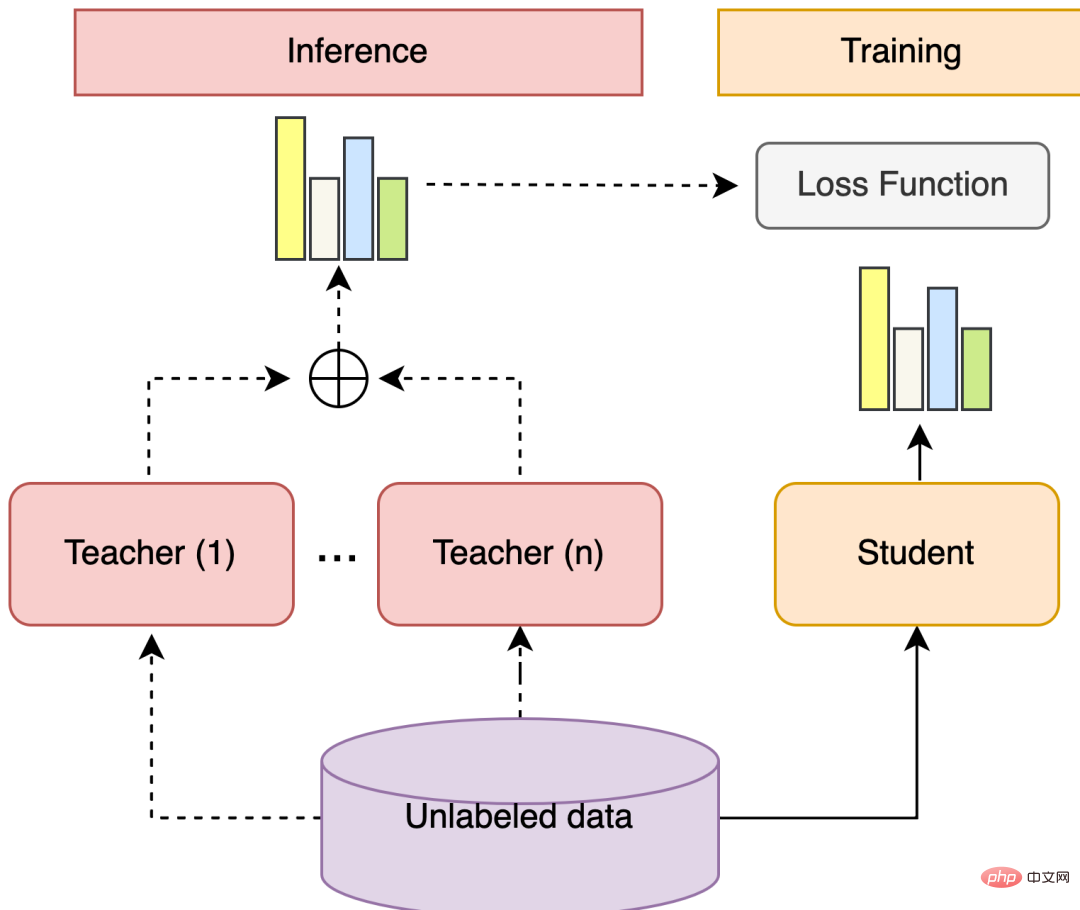
 Figure 5 Structure d'apprentissage intégré + auto-formation
Figure 5 Structure d'apprentissage intégré + auto-formation
Dans cette pratique FewCLUE, nous construisons d'abord un apprentissage rapide multi-modèles au cours de l'étape de réglage fin, et utilisons la formation contradictoire et la comparaison sur des données étiquetées Apprentissage, mixup et autres stratégies d’amélioration. Étant donné que ces stratégies d'amélioration des données utilisent des principes d'amélioration différents, on peut considérer que les différences entre ces modèles sont relativement importantes et donneront de meilleurs résultats après un apprentissage intégré.
Après une formation utilisant la stratégie d'augmentation des données, nous disposons de plusieurs modèles faiblement supervisés et utilisons ces modèles faiblement supervisés pour prédire sur des données non étiquetées afin d'obtenir la distribution pseudo-étiquette des données non étiquetées. Après cela, nous intégrons plusieurs distributions pseudo-étiquettes de données non étiquetées prédites par différents modèles d'augmentation de données pour obtenir une distribution pseudo-étiquette totale de données non étiquetées. Dans le processus de sélection des données de pseudo-étiquette, nous ne sélectionnerons pas nécessairement l'échantillon avec la confiance la plus élevée, car si la confiance donnée par chaque modèle d'augmentation des données est très élevée, cela signifie que cet échantillon peut être un échantillon facile à apprendre. et n'a pas nécessairement une grande valeur.
Nous combinons les niveaux de confiance donnés par plusieurs modèles d'amélioration des données et essayons de sélectionner des échantillons avec des niveaux de confiance plus élevés mais qui ne sont pas faciles à apprendre (Par exemple, les prédictions de plusieurs modèles ne sont pas toutes cohérentes). Ensuite, l'apprentissage rapide multi-modèles est reconstruit à l'aide de l'ensemble de données étiquetées et de données pseudo-étiquetées, la stratégie d'augmentation des données est à nouveau utilisée et la meilleure stratégie est sélectionnée. À l'heure actuelle, notre expérience n'effectue qu'une seule itération, et nous pouvons également essayer plusieurs itérations. Cependant, à mesure que le nombre d'itérations augmente, l'amélioration diminuera et ne sera plus significative.
3 Résultats expérimentaux
3.1 Introduction à l'ensemble de données
La liste FewCLUE propose 9 tâches, dont 4 tâches de classification de texte, 2 tâches de relations inter-phrases et 3 tâches de compréhension écrite. Les tâches de classification de texte comprennent l'analyse des sentiments d'évaluation du commerce électronique, la classification de documents scientifiques, la classification d'actualités et les tâches de classification de sujets de description d'applications. Il est principalement classé en deux classifications de texte court, multi-classification de texte court et multi-classification de texte long. Certaines tâches comportent de nombreuses catégories, plus de 100 catégories, et il existe un problème de déséquilibre des catégories. Les tâches de relations inter-phrases comprennent le raisonnement en langage naturel et les tâches de correspondance de textes courts. Les tâches de compréhension écrite comprennent des tâches de compréhension écrite d'expressions idiomatiques, de remplissage sélectif des blancs, de jugement sommaire, d'identification de mots clés et de désambiguïsation des pronoms. Chaque tâche fournit environ 160 éléments de données étiquetées et environ 20 000 éléments de données non étiquetées. Étant donné que la tâche de classification de textes longs comporte de nombreuses catégories et est trop difficile, elle fournit également davantage de données étiquetées. Les données détaillées de la tâche sont présentées dans le tableau 4 :

Tableau 4 Introduction à la tâche de l'ensemble de données FewCLUE
3.2 Comparaison expérimentale
Le tableau 5 montre la comparaison des résultats expérimentaux avec différents modèles et quantités de paramètres. Dans l'expérience RoBERTa Base, l'utilisation du modèle PET/EFL dépassera de 2 à 28 PP le résultat du modèle Fine-Tune direct traditionnel. Sur la base du modèle PET/EFL, afin d'explorer l'effet du grand modèle dans des scénarios de petits échantillons, nous avons mené des expériences sur RoBERTa Large. Par rapport à RoBERTa Base, le grand modèle peut améliorer le modèle de 0,5 à 13 PP ; mieux utiliser les connaissances du domaine, nous avons en outre mené des expériences sur le modèle RoBERTa Large Clue qui a été pré-entraîné sur l'ensemble de données CLUE, et le grand modèle intégrant la connaissance du domaine a encore amélioré les résultats de 0,1 à 9 pp. Sur cette base, dans des expériences ultérieures, nous mènerons des expériences sur RoBERTa Large Clue.

Tableau 5 Comparaison des résultats expérimentaux de différents modèles et quantités de paramètres (la police rouge en gras indique les meilleurs résultats)
Le tableau 6 montre les résultats expérimentaux de l'amélioration des données et de l'apprentissage d'ensemble sur le modèle PET/EFL. On peut constater que même si la stratégie d'amélioration des données est utilisée sur un grand modèle, le modèle peut apporter une amélioration de 0,8 à 9 PP, et après un apprentissage et une auto-formation davantage intégrés, les performances du modèle continueront de s'améliorer de 0,4 à 4 PP.

Tableau 6 Modèle de base + amélioration des données + résultats expérimentaux d'apprentissage d'ensemble (la police rouge en gras indique le meilleur résultat)
Dans l'étape d'apprentissage d'ensemble + auto-formation, nous avons essayé plusieurs stratégies de sélection :
- Sélectionnez l'échantillon avec la confiance la plus élevée. L'amélioration apportée par cette stratégie se situe dans la limite de 1PP. La plupart des échantillons de pseudo-étiquettes avec la confiance la plus élevée sont des échantillons qui sont cohérents dans les prédictions de plusieurs modèles et ont une confiance relativement élevée. Les échantillons de partie sont relativement faciles à apprendre et les avantages de l'incorporation de ces échantillons sont limités.
- Sélectionnez des échantillons avec une confiance et une controverse élevées (Il existe au moins un modèle qui est incohérent avec les résultats de prédiction d'autres modèles, mais la confiance globale de plusieurs modèles dépasse le seuil 1), cette stratégie évite les Des échantillons faciles à apprendre, et en définissant des seuils pour éviter d'introduire trop de données sales, peuvent entraîner une amélioration de 0-3PP
- Intégrez les deux stratégies ci-dessus, si les résultats de prédiction de plusieurs modèles pour un échantillon ; sont cohérents, nous sélectionnons des échantillons avec un niveau de confiance inférieur au seuil 2 ; pour les cas où au moins un modèle est incohérent avec les résultats de prédiction d'autres modèles, nous sélectionnons des échantillons avec un niveau de confiance supérieur au seuil 3 ; Cette méthode sélectionne simultanément des échantillons avec une plus grande confiance pour garantir la crédibilité du résultat, et sélectionne des échantillons plus controversés pour garantir que les échantillons de pseudo-étiquette sélectionnés ont une plus grande difficulté d'apprentissage, ce qui peut apporter une amélioration de 0,4 à 4 PP.
4 Application d'une stratégie d'apprentissage sur petits échantillons dans les scénarios Meituan
Dans diverses entreprises de Meituan, il existe de riches scénarios PNL. Certaines tâches peuvent être classées comme tâches de classification de texte et tâches de relations inter-phrases, comme mentionné ci-dessus. Un exemple de stratégie d'apprentissage a été appliqué à divers scénarios de Meituan-Dianping, et il est prévu de former de meilleurs modèles lorsque les ressources de données sont rares. En outre, la stratégie d'apprentissage sur petits échantillons a été largement utilisée dans diverses capacités d'algorithme NLP de la plate-forme interne de traitement du langage naturel (NLP) de Meituan. Elle a été mise en œuvre dans de nombreux scénarios commerciaux et les ingénieurs internes de Meituan peuvent utiliser cette plate-forme. pour découvrir les capacités liées au centre PNL.
Tâche de classification de texte
Catégorie de sujets de beauté médicale : Les notes sur Meituan et Dianping sont divisées en 8 catégories par sujet : chasse à la curiosité, exploration des magasins, évaluation, cas réels, processus de traitement, et évitement des pièges, comparaison des effets, vulgarisation scientifique. Lorsque l'utilisateur clique sur un certain sujet, le contenu de la note correspondante est renvoyé et le partage d'expérience est partagé sur la page d'encyclopédie et la page de plan de la chaîne de beauté médicale de Meituan et de l'application Dianping. La précision de l'apprentissage sur de petits échantillons utilisant 2 989 données de formation. augmenté de 1,8 PP, atteignant 89,24 %.
Identification de la stratégie : Exploitation des stratégies de voyage à partir de l'UGC et des notes, fournissant une fourniture de contenu de stratégies de voyage, appliquées au module de stratégie sous la recherche de points pittoresques, le contenu rappelé est constitué de notes décrivant des stratégies de voyage, un petit échantillon d'apprentissage et l'utilisation de 384 éléments La précision des données d'entraînement a augmenté de 2PP, atteignant 87 %.
Classification des textes Xuecheng : Xuecheng (Base de connaissances interne de Meituan) contient une grande quantité de textes d'utilisateurs. Après introduction, les textes sont divisés en 17 catégories. Les modèles ont été formés sur 700 éléments de données. L'apprentissage par exemple améliore la précision du modèle de 2,5 PP par rapport au modèle existant, atteignant 84 %.
Sélection de projets : La disposition mixte actuelle des avis sur la page de liste d'avis de LE Life Services/Beauty et d'autres entreprises ne permet pas aux utilisateurs de trouver rapidement des informations de prise de décision, des balises de classification plus structurées sont donc nécessaires pour répondre aux besoins des utilisateurs. , apprentissage sur petits échantillons Dans ces deux entreprises, le taux de précision utilisant 300 à 500 éléments de données a atteint plus de 95 % (Plusieurs ensembles de données ont augmenté respectivement de 1,5 à 4PP).
Tâche de relation inter-phrases
Marquage d'efficacité de beauté médicale : Rappel du contenu des notes de Meituan et Dianping par efficacité. Les types d'efficacité sont : hydratant, blanchissant, amincissant le visage, élimination des rides, etc. , en ligne sur la page de la chaîne de beauté médicale, il existe 110 types d'efficacité qui doivent être notés. L'apprentissage par petits échantillons n'a utilisé que 2909 données de formation pour atteindre une précision de 91,88 % ( augmentée de 2,8 PP).
Marquage de marque de beauté médicale : Les entreprises de marque en amont ont des demandes en matière de promotion de la marque et de marketing de leurs produits, et le marketing de contenu est l'une des méthodes de marketing courantes et efficaces actuelles. Le marquage de la marque consiste à rappeler les notes détaillant la marque pour chaque marque, telles que « Européenne » et « Shuweike ». Il y a 103 marques au total qui ont été mises en ligne dans le Medical Beauty Brand Hall. Seuls 1 676 éléments de formation sont nécessaires pour un petit échantillon. apprentissage. Le taux d'exactitude des données a atteint 88,59% (augmenté de 2,9PP).
5 Résumé
Dans cette soumission de liste, nous avons construit un modèle de compréhension sémantique basé sur RoBERTa et une pré-formation améliorée, un modèle PET/EFL, une amélioration des données et un apprentissage et une auto-formation intégrés. modèle. Ce modèle peut effectuer la classification de textes, les tâches de raisonnement sur les relations inter-phrases et plusieurs tâches de compréhension écrite.
En participant à cette tâche d'évaluation, nous avons une compréhension plus approfondie des algorithmes et de la recherche dans le domaine de la compréhension du langage naturel dans de petits échantillons de scénarios. Nous avons également utilisé cela pour effectuer un test approfondi des capacités de mise en œuvre de la langue chinoise. algorithmes de pointe, jetant les bases d'un développement ultérieur dans le futur. La recherche d'algorithmes et la mise en œuvre d'algorithmes ont jeté les bases. De plus, les scénarios de tâches de cet ensemble de données sont très similaires aux scénarios commerciaux de Meituan Search et du département NLP. De nombreuses stratégies de ce modèle sont également directement appliquées dans l'entreprise réelle et responsabilisent directement l'entreprise.
6 Les auteurs de cet article
Luo Ying, Xu Jun, Xie Rui et Wu Wei sont tous du Meituan Search et du département PNL/Centre PNL.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 Comment obtenir le comptoir à emporter Meituan
Apr 08, 2024 pm 03:41 PM
Comment obtenir le comptoir à emporter Meituan
Apr 08, 2024 pm 03:41 PM
1. Lorsque le livreur place le repas dans le placard, il informera le client de récupérer le repas par SMS, appel téléphonique ou message Meituan. 2. Les clients peuvent scanner le code QR sur l'armoire alimentaire via WeChat ou Meituan APP pour accéder à l'applet de l'armoire alimentaire intelligente. 3. Entrez le code de retrait ou utilisez la fonction « ouverture de l'armoire en un clic » pour ouvrir facilement la porte de l'armoire et sortir les plats à emporter.
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Comment récupérer le mot de passe de paiement oublié de Meituan_Comment récupérer le mot de passe de paiement oublié de Meituan
Mar 28, 2024 pm 03:29 PM
Comment récupérer le mot de passe de paiement oublié de Meituan_Comment récupérer le mot de passe de paiement oublié de Meituan
Mar 28, 2024 pm 03:29 PM
1. Tout d'abord, nous entrons dans le logiciel Meituan, recherchons les paramètres sur la page Mon menu et cliquons pour accéder aux paramètres. 2. Ensuite, nous trouvons les paramètres de paiement sur la page des paramètres et cliquons pour entrer les paramètres de paiement. 3. Entrez dans le centre de paiement, recherchez le paramètre de mot de passe de paiement et cliquez pour saisir le paramètre de mot de passe de paiement. 4. Dans la page de configuration du mot de passe de paiement, recherchez la récupération du mot de passe de paiement et cliquez pour accéder à l'option de la page. 5. Entrez les informations du mot de passe de paiement que vous souhaitez récupérer, cliquez sur Vérifier et vous pourrez récupérer le mot de passe de paiement après l'avoir transmis.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
