
 Périphériques technologiques
IA
ST-P3 : Méthode de vision d'apprentissage de caractéristiques spatio-temporelles de bout en bout pour la conduite autonome
Périphériques technologiques
IA
ST-P3 : Méthode de vision d'apprentissage de caractéristiques spatio-temporelles de bout en bout pour la conduite autonome
ST-P3 : Méthode de vision d'apprentissage de caractéristiques spatio-temporelles de bout en bout pour la conduite autonome

Article arXiv "ST-P3 : End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning", 22 juillet, auteur de l'Université Jiao Tong de Shanghai, du laboratoire d'IA de Shanghai, de l'Université de Californie à San Diego et recherche de Pékin de JD hôpital .com.

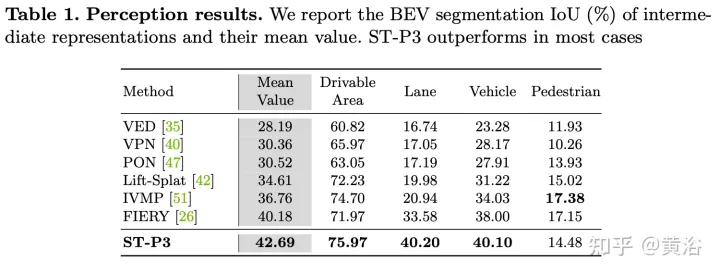
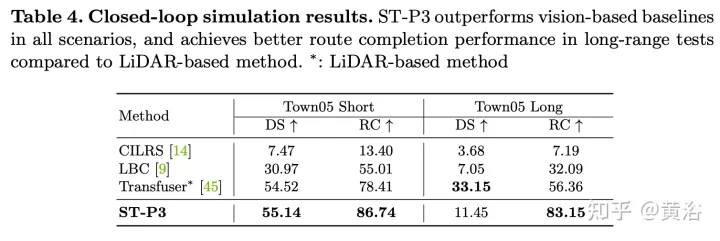
Proposer un schéma d'apprentissage de caractéristiques spatio-temporelles pouvant fournir simultanément un ensemble de caractéristiques plus représentatives pour les tâches de perception, de prédiction et de planification, appelé ST-P3. Plus précisément, une technique d'accumulation alignée égocentrique est proposée pour conserver les informations géométriques dans l'espace 3D avant de détecter la conversion BEV ; l'auteur conçoit un modèle à double voie pour que les changements de mouvement passés soient pris en compte pour les prédictions futures ; une unité de raffinement est introduite pour compenser la reconnaissance prévue des éléments visuels. Le code source, le modèle et les détails du protocole sont open source https://github.com/OpenPerceptionX/ST-P3.
Méthode LSS pionnière pour extraire des caractéristiques de perspective de caméras multi-vues via la profondeur. on estime qu'il sera mis à niveau vers la 3D et intégré dans l'espace BEV. Conversion de fonctionnalités entre deux vues, dont la prédiction de la profondeur latente est cruciale.
La mise à niveau des informations planes bidimensionnelles vers trois dimensions nécessite des dimensions supplémentaires, c'est-à-dire une profondeur adaptée aux tâches de conduite autonome géométriques tridimensionnelles. Pour améliorer encore la représentation des fonctionnalités, il est naturel d'incorporer des informations temporelles dans le cadre puisque la plupart des scènes sont chargées de sources vidéo.
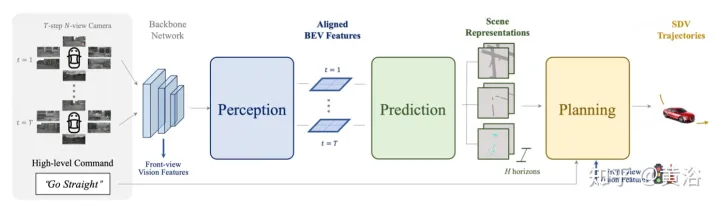
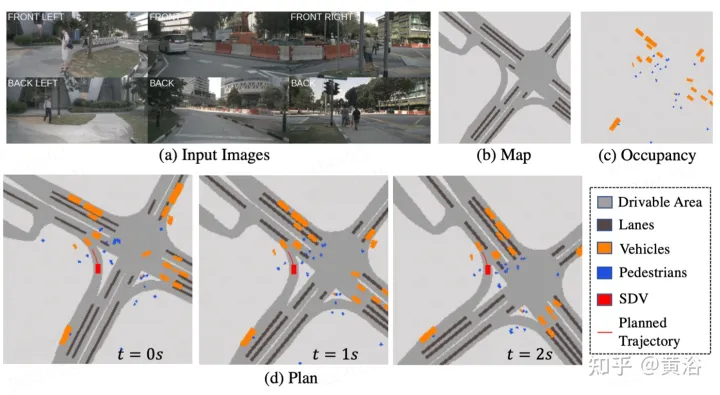
Comme décrit dans la figureST-P3Cadre général : plus précisément, étant donné un ensemble de vidéos de caméra environnantes, saisissez-les dans l'épine dorsale pour générer des fonctionnalités de vue de face préliminaires. Effectue une estimation de profondeur auxiliaire pour convertir les entités 2D en espace 3D. Le schéma d'accumulation d'alignement autocentré aligne d'abord les entités passées sur le système de coordonnées de la vue actuelle. Les caractéristiques actuelles et passées sont ensuite agrégées dans un espace tridimensionnel, préservant les informations géométriques avant de les convertir en représentation BEV. En plus du modèle de domaine temporel de prédiction couramment utilisé, les performances sont encore améliorées en construisant un deuxième chemin pour expliquer les changements de mouvement passés. Cette modélisation à double chemin garantit une représentation plus forte des caractéristiques pour déduire de futurs résultats sémantiques. Afin d'atteindre l'objectif ultime de la planification de trajectoire, la connaissance préalable des premières fonctionnalités du réseau est intégrée. Un module de raffinement a été conçu pour générer la trajectoire finale à l'aide de commandes de haut niveau en l'absence de cartes HD.
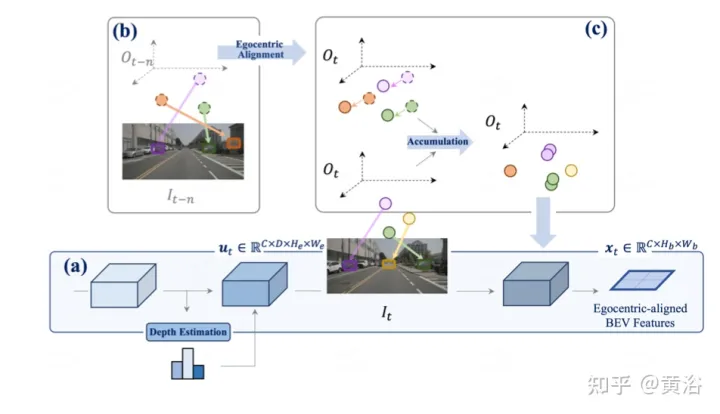
perception. (a) Utiliser l'estimation de la profondeur pour transformer les caractéristiques de l'horodatage actuel en 3D et les fusionner dans les caractéristiques BEV après l'alignement (b-c) Aligner les caractéristiques 3D de l'image précédente avec la vue de l'image actuelle et fusionner avec tous les états passés et actuels ; amélioration de la représentation des fonctionnalités.
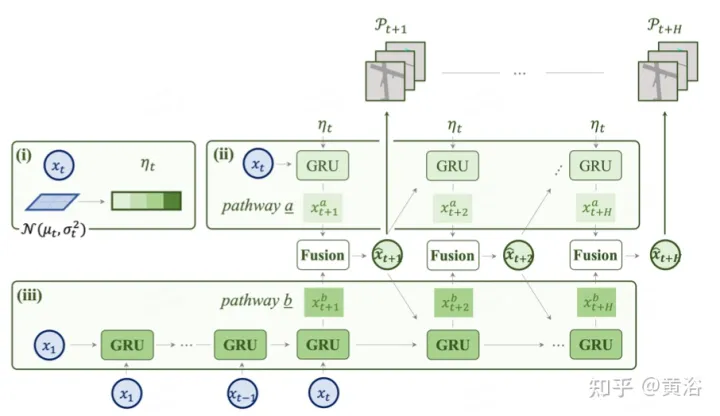
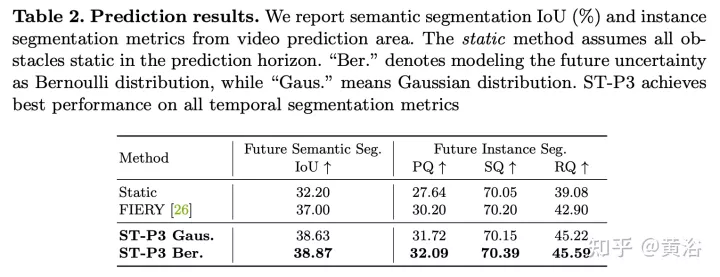
prédiction : (i) le code latent est la distribution de la carte des caractéristiques (ii iii) de manière à combiner la distribution de l'incertitude, indiquant le futur multi ; -modalité, et le chemin b apprend des changements passés, ce qui aide les informations du chemin a à compenser.
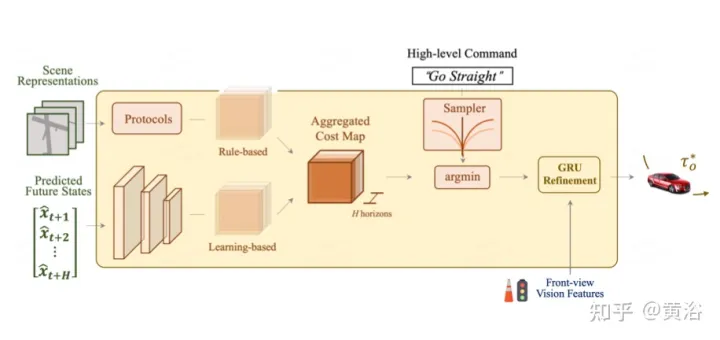
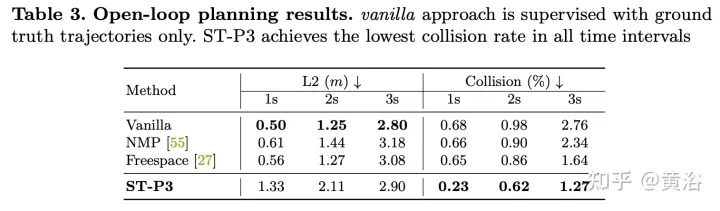
planification : le diagramme des coûts globaux comprend deux sous-coûts. Les trajectoires à coût minimum sont redéfinies davantage à l'aide de fonctionnalités prospectives pour regrouper les informations basées sur la vision provenant des entrées de caméra.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Mar 06, 2024 pm 05:34 PM
Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Mar 06, 2024 pm 05:34 PM
L'article de StableDiffusion3 est enfin là ! Ce modèle est sorti il y a deux semaines et utilise la même architecture DiT (DiffusionTransformer) que Sora. Il a fait beaucoup de bruit dès sa sortie. Par rapport à la version précédente, la qualité des images générées par StableDiffusion3 a été considérablement améliorée. Il prend désormais en charge les invites multithèmes, et l'effet d'écriture de texte a également été amélioré et les caractères tronqués n'apparaissent plus. StabilityAI a souligné que StableDiffusion3 est une série de modèles avec des tailles de paramètres allant de 800M à 8B. Cette plage de paramètres signifie que le modèle peut être exécuté directement sur de nombreux appareils portables, réduisant ainsi considérablement l'utilisation de l'IA.
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
