
 Périphériques technologiques
IA
GitHub open source 130+Stars : vous apprenez étape par étape à reproduire l'algorithme de détection de cible basé sur la série PPYOLO
Périphériques technologiques
IA
GitHub open source 130+Stars : vous apprenez étape par étape à reproduire l'algorithme de détection de cible basé sur la série PPYOLO
GitHub open source 130+Stars : vous apprenez étape par étape à reproduire l'algorithme de détection de cible basé sur la série PPYOLO

La détection d'objets est une tâche fondamentale dans le domaine de la vision par ordinateur. Comment pouvons-nous y parvenir sans un bon Model Zoo ?
Aujourd'hui, je vais vous présenter une bibliothèque de modèles d'algorithmes de détection de cible simple et facile à utiliser, miemiedetection. Elle a actuellement gagné plus de 130 étoiles sur GitHub
Lien de code : https://github.com/miemie2013/miemiedetection.
miemiedetection Il s'agit d'une bibliothèque de détection personnelle développée sur la base de YOLOX et prend également en charge des algorithmes tels que PPYOLO, PPYOLOv2, PPYOLOE et FCOS.
Grâce à l'excellente architecture de YOLOX, la vitesse d'entraînement de l'algorithme en détection de miémie est très rapide et la lecture des données n'est plus le goulot d'étranglement de la vitesse d'entraînement.
Le cadre d'apprentissage profond utilisé dans le développement de code est pyTorch, qui implémente la convolution déformable DCNv2, Matrix NMS et d'autres opérateurs difficiles, et prend en charge la carte unique mono-machine, la multi-carte mono-machine et la multi-carte multi-machine. modes de formation (le mode de formation multi-cartes est recommandé en utilisant le système Linux), prend en charge les systèmes Windows et Linux.
Et comme miemiedetection est une bibliothèque de détection qui ne nécessite pas d'installation, les utilisateurs peuvent directement modifier son code pour modifier la logique d'exécution, il est donc également facile d'ajouter de nouveaux algorithmes à la bibliothèque.
L'auteur a déclaré que davantage de supports d'algorithmes (et de vêtements pour femmes) seront ajoutés à l'avenir.

La réplication de l'algorithme est garantie
La chose la plus importante est que le taux de précision soit fondamentalement le même que celui d'origine.
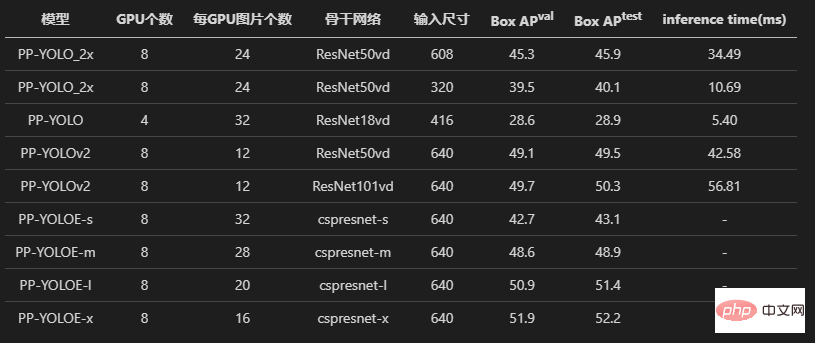
Regardons d'abord les trois modèles de PPYOLO, PPYOLOv2 et PPYOLOE. L'auteur a tous subi des expériences sur l'alignement des pertes et l'alignement des gradients.
Afin de préserver les preuves, vous pouvez également voir les parties commentées de lecture et d'écriture *.npz dans le code source, qui sont tous des codes restants de l'expérience d'alignement.
Et l'auteur a également enregistré en détail le processus d'alignement des performances. Pour les novices, suivre ce chemin est aussi un bon processus d'apprentissage !
Tous les journaux d'entraînement sont également enregistrés et sauvegardés dans l'entrepôt, ce qui suffit à prouver l'exactitude de la reproduction de la série d'algorithmes PPYOLO !
Les résultats finaux de la formation montrent que l'algorithme PPYOLO reproduit a la même perte et le même gradient que l'entrepôt d'origine.
De plus, l'auteur a également essayé d'utiliser l'ensemble de données d'origine de l'entrepôt et du transfert de détection de miémie voc2012, et a également obtenu la même précision (en utilisant les mêmes hyperparamètres).
Identique à l'implémentation originale, utilisant le même taux d'apprentissage, la même stratégie de décroissance du taux d'apprentissage warm_piecewisedecay (utilisée par PPYOLO et PPYOLOv2) et warm_cosinedecay (utilisée par PPYOLOE), la même moyenne mobile exponentielle EMA, le même prétraitement des données méthode, Avec le même paramètre d'atténuation du poids L2, la même perte, le même gradient et le même modèle pré-entraîné, l'apprentissage par transfert a atteint la même précision.
Nous avons fait suffisamment d'expériences et effectué de nombreux tests pour garantir que tout le monde vive une expérience merveilleuse !
No 998, no 98, cliquez simplement sur l'étoile et emportez chez vous tous les algorithmes de détection de cible gratuitement !
Téléchargement et conversion du modèle
Si vous souhaitez parcourir le modèle, les paramètres sont très importants. L'auteur fournit le fichier de poids pth converti avant l'entraînement, qui peut être téléchargé directement via Baidu Netdisk.
Lien : https://pan.baidu.com/s/1ehEqnNYKb9Nz0XNeqAcwDw
Code d'extraction : qe3i
Ou suivez les étapes ci-dessous pour l'obtenir :
Première étape, téléchargez le fichier de poids , projet Exécutez dans le répertoire racine (c'est-à-dire téléchargez le fichier, les utilisateurs de Windows peuvent utiliser Thunder ou un navigateur pour télécharger le lien derrière wget. Afin de montrer la beauté, seul ppyoloe_crn_l_300e_coco est utilisé comme exemple) :

Notez que les modèles avec les mots pré-entraînés Il s'agit d'un réseau fédérateur pré-entraîné sur ImageNet, PPYOLOv2 et PPYOLOE chargent ces poids pour entraîner l'ensemble de données COCO. Les autres sont des modèles pré-entraînés sur COCO.
La deuxième étape, convertir les poids, exécuter dans le répertoire racine du projet :

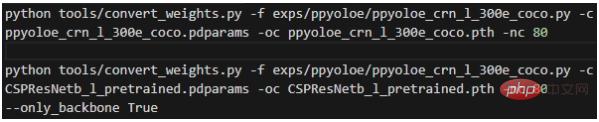
La signification de chaque paramètre est :
- -f représente le fichier de configuration utilisé ;
- -c représente le fichier de poids source lu
- -oc représente la sortie ; (enregistré) fichier de poids pytorch ;
- -nc représente le nombre de catégories de l'ensemble de données
- --only_backbone Lorsque True, cela signifie uniquement convertir le poids du réseau principal ; Après l'exécution, le fichier de poids *.pth converti sera obtenu dans le répertoire racine du projet.
Tutoriel pas à pas
Dans les commandes suivantes, la plupart d'entre elles utiliseront le fichier de configuration du modèle, il est donc nécessaire d'expliquer le fichier de configuration en détail au début.mmdet.exp.base_exp.BaseExp est la classe de base du fichier de configuration. C'est une classe abstraite qui déclare un tas de méthodes abstraites, telles que get_model() indiquant comment obtenir le modèle, get_data_loader() indiquant comment obtenir. le chargeur de données formé, get_optimizer( ) indique comment obtenir l'optimiseur et ainsi de suite.
mmdet.exp.datasets.coco_base.COCOBaseExp est la configuration de l'ensemble de données et hérite de BaseExp. Il donne uniquement la configuration de l'ensemble de données. Cet entrepôt ne prend en charge que la formation d'ensembles de données au format d'annotation COCO !
Les ensembles de données dans d'autres formats d'annotation doivent être convertis au format d'annotation COCO avant la formation (si trop de formats d'annotation sont pris en charge, la charge de travail sera trop importante). Les ensembles de données personnalisés peuvent être convertis au format d'étiquette COCO via miemieLabels. Toutes les classes de configuration des algorithmes de détection hériteront de COCOBaseExp, ce qui signifie que tous les algorithmes de détection partagent la même configuration d'ensemble de données. Les éléments de configuration de
COCOBaseExp sont :
Parmi eux, 
- self.num_classes représente le nombre de catégories de l'ensemble de données
- self.data_dir représente le nombre ; des catégories du répertoire racine de l'ensemble de données ;
- self.cls_names représente le chemin du fichier de nom de catégorie de l'ensemble de données. Il s'agit d'un fichier txt et une ligne représente un nom de catégorie. S'il s'agit d'un ensemble de données personnalisé, vous devez créer un nouveau fichier txt et modifier le nom de la catégorie, puis modifier self.cls_names pour y pointer
- self.ann_folder représente le répertoire racine du fichier d'annotation de ; l'ensemble de données et doit être situé dans le répertoire self.data_dir
- self.train_ann représente le nom du fichier d'annotation de l'ensemble de formation de l'ensemble de données, qui doit être situé dans le répertoire self.ann_folder ;
- self.val_ann représente l'annotation de l'ensemble de vérification de l'ensemble de données. Le nom du fichier doit être situé dans le répertoire self.ann_folder- self.train_image_folder représente le nom du dossier image de l'ensemble d'entraînement ; ensemble de données et doit être situé dans le répertoire self.data_dir ;
- self.val_image_folder représente le nom du dossier d'image de l'ensemble de validation de l'ensemble de données, qui doit être situé dans le répertoire self.data_dir ;
Pour l'ensemble de données VOC 2012, vous devez modifier la configuration de l'ensemble de données pour :
De plus, vous pouvez également modifier la configuration de self.num_classes et self.data_dir dans le sous-classe comme dans exps/ppyoloe/ppyoloe_crn_l_voc2012.py, de sorte que la configuration de COCOBaseExp sera écrasée (invalide).

Enfin, l'emplacement de placement de l'ensemble de données COCO, de l'ensemble de données VOC2012 et de ce projet devrait être comme ceci :
Le répertoire racine de l'ensemble de données et miemiedetection-master sont du même répertoire de niveau . Personnellement, je ne recommande pas de mettre l'ensemble de données dans miemiedetection-master, sinon PyCharm sera énorme une fois ouvert. De plus, lorsque plusieurs projets (tels que mmdetection, PaddleDetection, AdelaiDet) partagent des ensembles de données, vous pouvez définir le chemin de l'ensemble de données et le projet ; le nom n'a pas d'importance.
exp.ppyolo.ppyolo_r50vd_2x.Exp est la classe de configuration finale du modèle Resnet50Vd de l'algorithme PPYOLO, qui hérite de PPYOLO_Method_Exp ;
Tout d'abord, si les données d'entrée sont une image, exécutez-la dans le répertoire racine du projet : La signification de chaque paramètre est : - -f signifie ce qui est utilisé Fichier de configuration ; - -c représente le fichier de poids lu ; - --path représente le chemin de l'image - --conf représente le seuil de score, uniquement Dessinez une boîte de prédiction supérieure à celui-ci ; seuil ; - --tsize représente la résolution de redimensionnement de l'image à --tsize pendant la prédiction Une fois la prédiction terminée, la console imprimera le chemin de sauvegarde de l'image résultante, les utilisateurs peuvent ouvrir et voir le. Si vous utilisez un modèle enregistré dans un ensemble de données d'entraînement personnalisé pour la prédiction, modifiez simplement -c le chemin de votre modèle. Si vous prédisez toutes les images d'un dossier, exécutez-le dans le répertoire racine du projet : Changez --path par le chemin du dossier d'images correspondant. Si vous lisez l'ensemble de données COCO de formation du réseau fédérateur de pré-formation ImageNet, exécutez-le dans le répertoire racine du projet : Une commande démarre directement le huit- formation aux cartes. Bien sûr, le principe est que vous disposez réellement d'un superordinateur autonome à 8 cartes. La signification de chaque paramètre est : -f représente le fichier de configuration utilisé ; -d représente le nombre de cartes graphiques -b représente le lot lors de l'entraînement Taille (pour toutes les cartes) ; -eb représente la taille du lot lors de l'évaluation (pour toutes les cartes) ; -c représente le fichier de poids lu --fp16, Entraînement automatique de précision mixte ; --num_machines, le nombre de machines, il est recommandé de s'entraîner avec plusieurs cartes sur une seule machine --le CV indique s'il s'agit d'un entraînement de récupération Entraînement d'un ensemble de données personnalisé Prenez l'ensemble de données VOC2012 ci-dessus comme exemple. Pour le modèle ppyolo_r50vd, s'il s'agit de 1 machine et 1 carte, entrez la commande suivante pour démarrer l'entraînement :
S'il s'agit de 2 machines et 2 cartes, soit 1 carte sur chaque machine, saisissez la commande suivante sur la machine 0 :
S'il s'agit de 1 machine et de 2 cartes, entrez la commande suivante pour démarrer l'entraînement :
Lors de l'apprentissage par transfert, il a la même précision et vitesse de convergence que PaddleDetection. Les journaux d'entraînement des deux se trouvent dans le dossier train_ppyolo_in_voc2012. S'il s'agit du modèle ppyoloe_l, entrez la commande suivante sur une seule machine pour démarrer l'entraînement (gel du réseau fédérateur)
Évaluation Le résultat de l'exécution dans le répertoire racine du projet est : Il y a une légère perte de précision après la conversion des poids, d'environ 0,4 %. Prédiction

Ensemble de données de formation COCO2017

Lecture recommandée ; Utilisez des poids pré-entraînés COCO pour l’entraînement car la convergence est rapide.
 Si l'entraînement est interrompu pour certains. raison, vous souhaitez lire. Pour reprendre l'entraînement d'un modèle précédemment enregistré, modifiez simplement -c le chemin vers lequel vous souhaitez lire le modèle et ajoutez le paramètre --resume.
Si l'entraînement est interrompu pour certains. raison, vous souhaitez lire. Pour reprendre l'entraînement d'un modèle précédemment enregistré, modifiez simplement -c le chemin vers lequel vous souhaitez lire le modèle et ajoutez le paramètre --resume.  et saisissez la commande suivante sur la machine 1 :
et saisissez la commande suivante sur la machine 1 :  Remplacez simplement le 192.168.0.107 dans les deux commandes ci-dessus par l'adresse IP LAN de la machine 0.
Remplacez simplement le 192.168.0.107 dans les deux commandes ci-dessus par l'adresse IP LAN de la machine 0. 
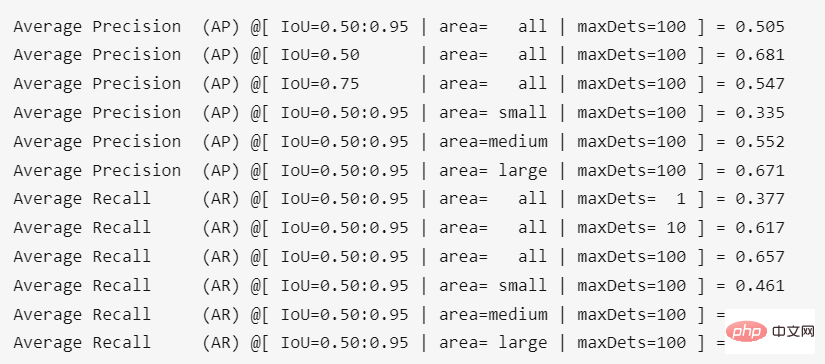
 Transférez l'ensemble de données d'apprentissage VOC2012, l'AP mesuré de ppyolo_r50vd_2x (0,50:0,95) peut atteindre 0,59+, AP (0,50) peut atteindre 0,82+, AP (petit) peut atteindre 0,18+. Qu'il s'agisse d'une seule carte ou de plusieurs cartes, ce résultat peut être obtenu.
Transférez l'ensemble de données d'apprentissage VOC2012, l'AP mesuré de ppyolo_r50vd_2x (0,50:0,95) peut atteindre 0,59+, AP (0,50) peut atteindre 0,82+, AP (petit) peut atteindre 0,18+. Qu'il s'agisse d'une seule carte ou de plusieurs cartes, ce résultat peut être obtenu.  Transférer l'ensemble de données d'apprentissage VOC2012, l'AP mesuré de ppyoloe_l (0,50 : 0,95 ) peut atteindre 0,66 +, AP (0,50) peut atteindre 0,85+, AP (petit) peut atteindre 0,28+.
Transférer l'ensemble de données d'apprentissage VOC2012, l'AP mesuré de ppyoloe_l (0,50 : 0,95 ) peut atteindre 0,66 +, AP (0,50) peut atteindre 0,85+, AP (petit) peut atteindre 0,28+. les commandes et paramètres spécifiques sont les suivants.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Dix outils d'annotation de texte gratuits open source recommandés
Mar 26, 2024 pm 08:20 PM
Dix outils d'annotation de texte gratuits open source recommandés
Mar 26, 2024 pm 08:20 PM
L'annotation de texte est le travail d'étiquettes ou de balises correspondant à un contenu spécifique dans le texte. Son objectif principal est d’apporter des informations complémentaires au texte pour une analyse et un traitement plus approfondis, notamment dans le domaine de l’intelligence artificielle. L'annotation de texte est cruciale pour les tâches d'apprentissage automatique supervisées dans les applications d'intelligence artificielle. Il est utilisé pour entraîner des modèles d'IA afin de mieux comprendre les informations textuelles en langage naturel et d'améliorer les performances de tâches telles que la classification de texte, l'analyse des sentiments et la traduction linguistique. Grâce à l'annotation de texte, nous pouvons apprendre aux modèles d'IA à reconnaître les entités dans le texte, à comprendre le contexte et à faire des prédictions précises lorsque de nouvelles données similaires apparaissent. Cet article recommande principalement de meilleurs outils d'annotation de texte open source. 1.LabelStudiohttps://github.com/Hu
 15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
L'annotation d'images est le processus consistant à associer des étiquettes ou des informations descriptives à des images pour donner une signification et une explication plus profondes au contenu de l'image. Ce processus est essentiel à l’apprentissage automatique, qui permet d’entraîner les modèles de vision à identifier plus précisément les éléments individuels des images. En ajoutant des annotations aux images, l'ordinateur peut comprendre la sémantique et le contexte derrière les images, améliorant ainsi la capacité de comprendre et d'analyser le contenu de l'image. L'annotation d'images a un large éventail d'applications, couvrant de nombreux domaines, tels que la vision par ordinateur, le traitement du langage naturel et les modèles de vision graphique. Elle a un large éventail d'applications, telles que l'assistance aux véhicules pour identifier les obstacles sur la route, en aidant à la détection. et le diagnostic des maladies grâce à la reconnaissance d'images médicales. Cet article recommande principalement de meilleurs outils d'annotation d'images open source et gratuits. 1.Makesens
 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Recommandé : Excellent projet de détection et de reconnaissance des visages open source JS
Apr 03, 2024 am 11:55 AM
Recommandé : Excellent projet de détection et de reconnaissance des visages open source JS
Apr 03, 2024 am 11:55 AM
La technologie de détection et de reconnaissance des visages est déjà une technologie relativement mature et largement utilisée. Actuellement, le langage d'application Internet le plus utilisé est JS. La mise en œuvre de la détection et de la reconnaissance faciale sur le front-end Web présente des avantages et des inconvénients par rapport à la reconnaissance faciale back-end. Les avantages incluent la réduction de l'interaction réseau et de la reconnaissance en temps réel, ce qui réduit considérablement le temps d'attente des utilisateurs et améliore l'expérience utilisateur. Les inconvénients sont les suivants : il est limité par la taille du modèle et la précision est également limitée ; Comment utiliser js pour implémenter la détection de visage sur le web ? Afin de mettre en œuvre la reconnaissance faciale sur le Web, vous devez être familier avec les langages et technologies de programmation associés, tels que JavaScript, HTML, CSS, WebRTC, etc. Dans le même temps, vous devez également maîtriser les technologies pertinentes de vision par ordinateur et d’intelligence artificielle. Il convient de noter qu'en raison de la conception du côté Web
 Le document multimodal Alibaba 7B comprenant le grand modèle remporte le nouveau SOTA
Apr 02, 2024 am 11:31 AM
Le document multimodal Alibaba 7B comprenant le grand modèle remporte le nouveau SOTA
Apr 02, 2024 am 11:31 AM
Nouveau SOTA pour des capacités de compréhension de documents multimodaux ! L'équipe Alibaba mPLUG a publié le dernier travail open source mPLUG-DocOwl1.5, qui propose une série de solutions pour relever les quatre défis majeurs que sont la reconnaissance de texte d'image haute résolution, la compréhension générale de la structure des documents, le suivi des instructions et l'introduction de connaissances externes. Sans plus tarder, examinons d’abord les effets. Reconnaissance et conversion en un clic de graphiques aux structures complexes au format Markdown : Des graphiques de différents styles sont disponibles : Une reconnaissance et un positionnement de texte plus détaillés peuvent également être facilement traités : Des explications détaillées sur la compréhension du document peuvent également être données : Vous savez, « Compréhension du document " est actuellement un scénario important pour la mise en œuvre de grands modèles linguistiques. Il existe de nombreux produits sur le marché pour aider à la lecture de documents. Certains d'entre eux utilisent principalement des systèmes OCR pour la reconnaissance de texte et coopèrent avec LLM pour le traitement de texte.
 Fraichement publié! Un modèle open source pour générer des images de style anime en un seul clic
Apr 08, 2024 pm 06:01 PM
Fraichement publié! Un modèle open source pour générer des images de style anime en un seul clic
Apr 08, 2024 pm 06:01 PM
Permettez-moi de vous présenter le dernier projet open source AIGC-AnimagineXL3.1. Ce projet est la dernière itération du modèle texte-image sur le thème de l'anime, visant à offrir aux utilisateurs une expérience de génération d'images d'anime plus optimisée et plus puissante. Dans AnimagineXL3.1, l'équipe de développement s'est concentrée sur l'optimisation de plusieurs aspects clés pour garantir que le modèle atteigne de nouveaux sommets en termes de performances et de fonctionnalités. Premièrement, ils ont élargi les données d’entraînement pour inclure non seulement les données des personnages du jeu des versions précédentes, mais également les données de nombreuses autres séries animées bien connues dans l’ensemble d’entraînement. Cette décision enrichit la base de connaissances du modèle, lui permettant de mieux comprendre les différents styles et personnages d'anime. AnimagineXL3.1 introduit un nouvel ensemble de balises et d'esthétiques spéciales
 Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Le FP8 et la précision de quantification inférieure en virgule flottante ne sont plus le « brevet » du H100 ! Lao Huang voulait que tout le monde utilise INT8/INT4, et l'équipe Microsoft DeepSpeed a commencé à exécuter FP6 sur A100 sans le soutien officiel de NVIDIA. Les résultats des tests montrent que la quantification FP6 de la nouvelle méthode TC-FPx sur A100 est proche ou parfois plus rapide que celle de INT4, et a une précision supérieure à celle de cette dernière. En plus de cela, il existe également une prise en charge de bout en bout des grands modèles, qui ont été open source et intégrés dans des cadres d'inférence d'apprentissage profond tels que DeepSpeed. Ce résultat a également un effet immédiat sur l'accélération des grands modèles : dans ce cadre, en utilisant une seule carte pour exécuter Llama, le débit est 2,65 fois supérieur à celui des cartes doubles. un
