
 Périphériques technologiques
IA
Graph-DETR3D : repenser les régions qui se chevauchent dans la détection d'objets 3D multi-vues
Périphériques technologiques
IA
Graph-DETR3D : repenser les régions qui se chevauchent dans la détection d'objets 3D multi-vues
Graph-DETR3D : repenser les régions qui se chevauchent dans la détection d'objets 3D multi-vues

Article arXiv "Graph-DETR3D: Rethinking Overlapping Regions for Multi-View 3D Object Detection", 22 juin, travaux de l'Université des sciences et technologies de Chine, de l'Institut de technologie de Harbin et de SenseTime.

La détection d'objets 3D à partir de plusieurs vues d'images est une tâche fondamentale mais difficile dans la compréhension des scènes visuelles. En raison de son faible coût et de sa grande efficacité, la détection d’objets 3D multi-vues offre de larges perspectives d’application. Cependant, en raison du manque d’informations sur la profondeur, il est extrêmement difficile de détecter avec précision des objets par perspective dans un espace 3D. Récemment, DETR3D a introduit un nouveau paradigme de requête 3D-2D pour agréger des images multi-vues pour la détection d'objets 3D et a atteint des performances de pointe.
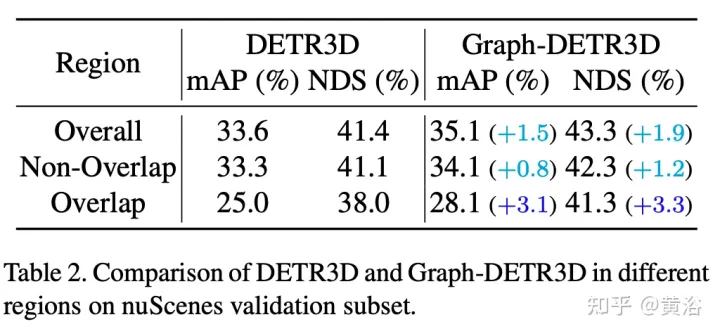
Grâce à des expériences guidées intensives, cet article quantifie les cibles situées dans différentes régions et constate que les « instances tronquées » (c'est-à-dire les régions limites de chaque image) sont le principal goulot d'étranglement entravant les performances de DETR3D. Malgré la fusion de plusieurs fonctionnalités de deux vues adjacentes dans des régions qui se chevauchent, DETR3D souffre toujours d'une agrégation de fonctionnalités insuffisante et manque donc l'opportunité d'améliorer pleinement les performances de détection.
Pour résoudre ce problème, Graph-DETR3D est proposé pour agréger automatiquement les informations d'image multi-vues grâce à l'apprentissage de la structure graphique (GSL). Une carte 3D dynamique est construite entre chaque requête cible et une carte de fonctionnalités 2D pour améliorer la représentation cible, en particulier dans les régions limites. De plus, Graph-DETR3D bénéficie d'une nouvelle stratégie de formation multi-échelle invariante en profondeur, qui maintient la cohérence de la profondeur visuelle en mettant simultanément à l'échelle la taille de l'image et la profondeur cible.
Graph-DETR3D diffère sur deux points, comme le montre la figure : (1) module d'agrégation de fonctionnalités de graphe dynamique (2) stratégie de formation multi-échelle invariante en profondeur ; Il suit la structure de base de DETR3D et se compose de trois composants : un encodeur d'image, un décodeur de transformateur et une tête de prédiction de cible. Étant donné un ensemble d'images I = {I1, I2,…, IK} (capturées par N caméras péri-vue), Graph-DETR3D vise à prédire l'emplacement et la catégorie de la boîte englobante d'intérêt. Tout d’abord, utilisez un encodeur d’image (comprenant ResNet et FPN) pour transformer ces images en un ensemble de fonctionnalités F relativement L au niveau de la carte. Ensuite, un graphique 3D dynamique est construit pour agréger de manière approfondie les informations 2D via le module d'agrégation de fonctionnalités de graphique dynamique (DGFA) afin d'optimiser la représentation de la requête cible. Enfin, la requête cible améliorée est utilisée pour générer la prédiction finale.
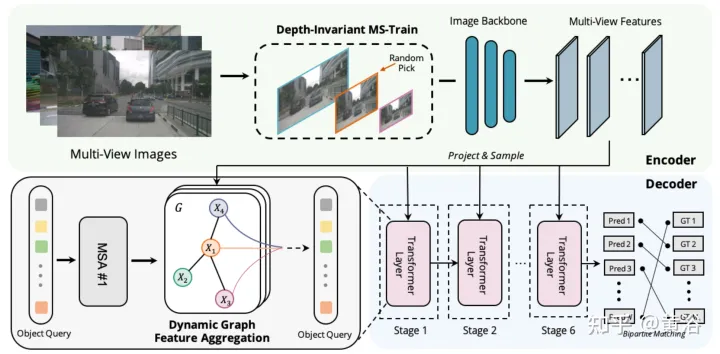
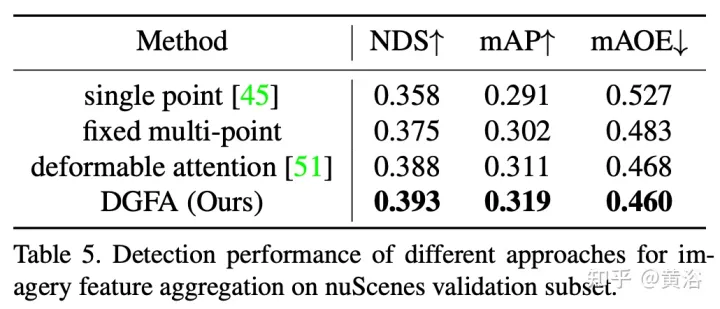
La figure montre le processus d'agrégation de caractéristiques de graphique dynamique (DFGA) : construisez d'abord un graphique 3D apprenable pour chaque requête cible, puis échantillonnez les caractéristiques du plan d'image 2D. Enfin, la représentation de la requête cible est améliorée grâce à des connexions graphiques. Ce schéma de propagation de messages interconnectés prend en charge le raffinement itératif de la construction de la structure graphique et l'amélioration des fonctionnalités.
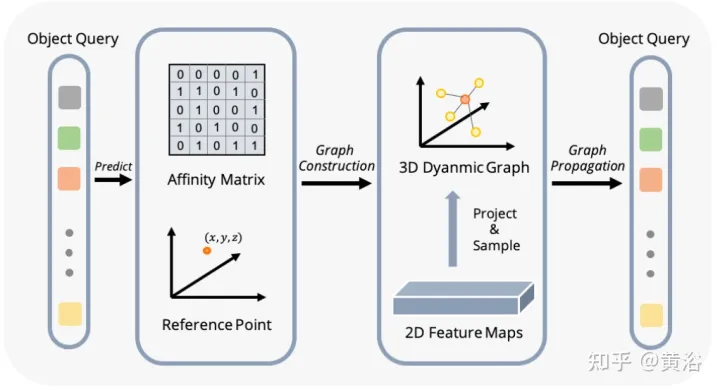
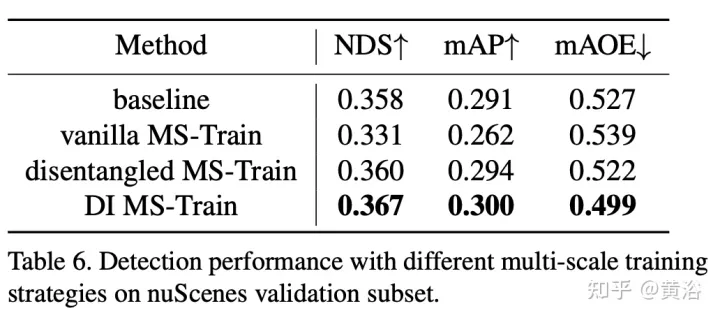
La formation multi-échelle est une stratégie d'augmentation des données couramment utilisée dans les tâches de détection d'objets 2D et 3D, qui s'est avérée être une inférence efficace et peu coûteuse. Cependant, il apparaît rarement dans les méthodes d’inspection 3D basées sur la vision. La prise en compte de différentes tailles d'image d'entrée peut améliorer la robustesse du modèle, tout en ajustant la taille de l'image et en modifiant les paramètres internes de la caméra pour mettre en œuvre une stratégie de formation multi-échelle commune.
Un phénomène intéressant est que la performance finale chute fortement. En analysant soigneusement les données d'entrée, nous avons découvert que le simple redimensionnement de l'image conduit à un problème d'ambiguïté de perspective : lorsque la cible est redimensionnée à une échelle plus grande/plus petite, ses propriétés absolues (c'est-à-dire la taille de la cible, la distance à l'ego) point) ne changez pas.
À titre d'exemple concret, la figure montre ce problème ambigu : bien que la position 3D absolue de la zone sélectionnée en (a) et (b) soit la même, le nombre de pixels de l'image est différent. Les réseaux de prédiction de profondeur ont tendance à estimer la profondeur en fonction de la zone occupée de l'image. Par conséquent, ce modèle d'entraînement dans la figure peut confondre le modèle de prédiction de profondeur et détériorer davantage les performances finales.

Recalculez la profondeur du point de vue des pixels pour cela. Le pseudo code de l'algorithme est le suivant :

Voici l'opération de décodage :

La taille de pixel recalculée est :
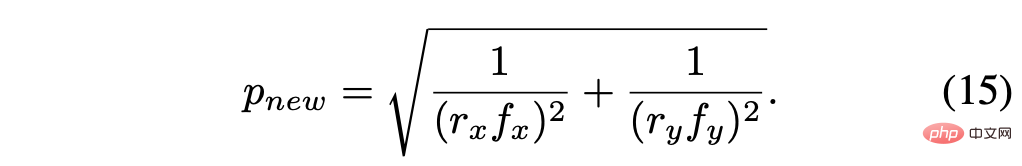
En supposant le facteur d'échelle r = rx = ry, alors le le résultat simplifié est :
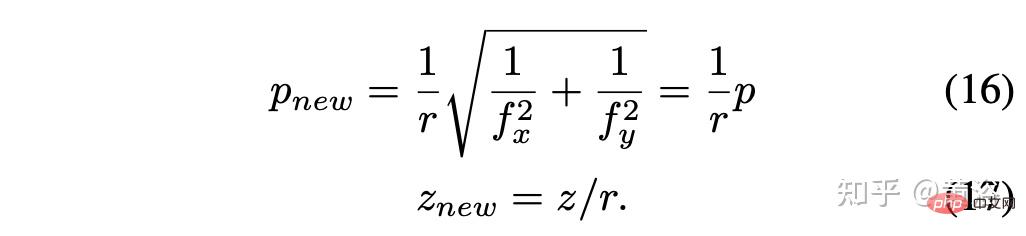
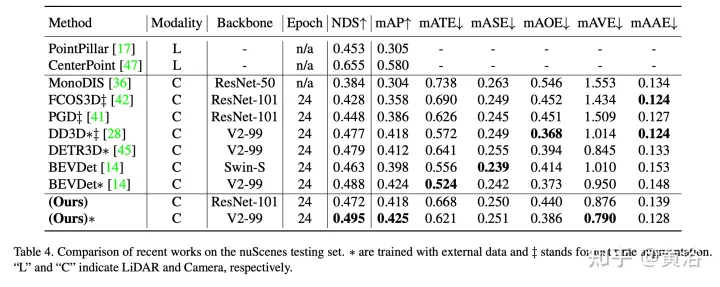
Les résultats expérimentaux sont les suivants :
Remarque : DI = Depth-Invariant
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Mar 06, 2024 pm 05:34 PM
Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Mar 06, 2024 pm 05:34 PM
L'article de StableDiffusion3 est enfin là ! Ce modèle est sorti il y a deux semaines et utilise la même architecture DiT (DiffusionTransformer) que Sora. Il a fait beaucoup de bruit dès sa sortie. Par rapport à la version précédente, la qualité des images générées par StableDiffusion3 a été considérablement améliorée. Il prend désormais en charge les invites multithèmes, et l'effet d'écriture de texte a également été amélioré et les caractères tronqués n'apparaissent plus. StabilityAI a souligné que StableDiffusion3 est une série de modèles avec des tailles de paramètres allant de 800M à 8B. Cette plage de paramètres signifie que le modèle peut être exécuté directement sur de nombreux appareils portables, réduisant ainsi considérablement l'utilisation de l'IA.
 Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Le premier article pilote et clé présente principalement plusieurs systèmes de coordonnées couramment utilisés dans la technologie de conduite autonome, et comment compléter la corrélation et la conversion entre eux, et enfin construire un modèle d'environnement unifié. L'objectif ici est de comprendre la conversion du véhicule en corps rigide de caméra (paramètres externes), la conversion de caméra en image (paramètres internes) et la conversion d'image en unité de pixel. La conversion de 3D en 2D aura une distorsion, une traduction, etc. Points clés : Le système de coordonnées du véhicule et le système de coordonnées du corps de la caméra doivent être réécrits : le système de coordonnées planes et le système de coordonnées des pixels Difficulté : la distorsion de l'image doit être prise en compte. La dé-distorsion et l'ajout de distorsion sont compensés sur le plan de l'image. 2. Introduction Il existe quatre systèmes de vision au total : système de coordonnées du plan de pixels (u, v), système de coordonnées d'image (x, y), système de coordonnées de caméra () et système de coordonnées mondiales (). Il existe une relation entre chaque système de coordonnées,
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 Annotation de cadre de délimitation redondant multi-grille pour une détection précise des objets
Jun 01, 2024 pm 09:46 PM
Annotation de cadre de délimitation redondant multi-grille pour une détection précise des objets
Jun 01, 2024 pm 09:46 PM
1. Introduction Actuellement, les principaux détecteurs d'objets sont des réseaux à deux étages ou à un étage basés sur le réseau de classificateurs de base réutilisé du Deep CNN. YOLOv3 est l'un de ces détecteurs à un étage de pointe bien connus qui reçoit une image d'entrée et la divise en une matrice de grille de taille égale. Les cellules de grille avec des centres cibles sont chargées de détecter des cibles spécifiques. Ce que je partage aujourd'hui est une nouvelle méthode mathématique qui alloue plusieurs grilles à chaque cible pour obtenir une prédiction précise et précise du cadre de délimitation. Les chercheurs ont également proposé une amélioration efficace des données par copier-coller hors ligne pour la détection des cibles. La méthode nouvellement proposée surpasse considérablement certains détecteurs d’objets de pointe actuels et promet de meilleures performances. 2. Le réseau de détection de cibles en arrière-plan est conçu pour utiliser
 Nouveau SOTA pour la détection de cibles : YOLOv9 sort et la nouvelle architecture redonne vie à la convolution traditionnelle
Feb 23, 2024 pm 12:49 PM
Nouveau SOTA pour la détection de cibles : YOLOv9 sort et la nouvelle architecture redonne vie à la convolution traditionnelle
Feb 23, 2024 pm 12:49 PM
Dans le domaine de la détection de cibles, YOLOv9 continue de progresser dans le processus de mise en œuvre en adoptant de nouvelles architectures et méthodes, il améliore efficacement l'utilisation des paramètres de la convolution traditionnelle, ce qui rend ses performances bien supérieures à celles des produits de la génération précédente. Plus d'un an après la sortie officielle de YOLOv8 en janvier 2023, YOLOv9 est enfin là ! Depuis que Joseph Redmon, Ali Farhadi et d’autres ont proposé le modèle YOLO de première génération en 2015, les chercheurs dans le domaine de la détection de cibles l’ont mis à jour et itéré à plusieurs reprises. YOLO est un système de prédiction basé sur des informations globales d'images et les performances de son modèle sont continuellement améliorées. En améliorant continuellement les algorithmes et les technologies, les chercheurs ont obtenu des résultats remarquables, rendant YOLO de plus en plus puissant dans les tâches de détection de cibles.
 DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
Cet article explore le problème de la détection précise d'objets sous différents angles de vue (tels que la perspective et la vue à vol d'oiseau) dans la conduite autonome, en particulier comment transformer efficacement les caractéristiques de l'espace en perspective (PV) en vue à vol d'oiseau (BEV). implémenté via le module Visual Transformation (VT). Les méthodes existantes sont globalement divisées en deux stratégies : la conversion 2D en 3D et la conversion 3D en 2D. Les méthodes 2D vers 3D améliorent les caractéristiques 2D denses en prédisant les probabilités de profondeur, mais l'incertitude inhérente aux prévisions de profondeur, en particulier dans les régions éloignées, peut introduire des inexactitudes. Alors que les méthodes 3D vers 2D utilisent généralement des requêtes 3D pour échantillonner des fonctionnalités 2D et apprendre les poids d'attention de la correspondance entre les fonctionnalités 3D et 2D via un transformateur, ce qui augmente le temps de calcul et de déploiement.
 Le premier modèle mondial de génération de vidéos de scènes de conduite autonomes multi-vues DrivingDiffusion : nouvelles idées pour les données et la simulation BEV
Oct 23, 2023 am 11:13 AM
Le premier modèle mondial de génération de vidéos de scènes de conduite autonomes multi-vues DrivingDiffusion : nouvelles idées pour les données et la simulation BEV
Oct 23, 2023 am 11:13 AM
Quelques réflexions personnelles de l'auteur Dans le domaine de la conduite autonome, avec le développement de sous-tâches/solutions de bout en bout basées sur BEV, les données d'entraînement multi-vues de haute qualité et la construction de scènes de simulation correspondantes sont devenues de plus en plus importantes. En réponse aux problèmes des tâches actuelles, la « haute qualité » peut être divisée en trois aspects : des scénarios à longue traîne dans différentes dimensions : comme les véhicules à courte portée dans les données sur les obstacles et les angles de cap précis lors du découpage des voitures, et les données sur les lignes de voie. . Scènes telles que des courbes avec des courbures différentes ou des rampes/fusions/fusions difficiles à capturer. Celles-ci reposent souvent sur de grandes quantités de données collectées et sur des stratégies complexes d’exploration de données, qui sont coûteuses. Valeur réelle 3D - image hautement cohérente : l'acquisition actuelle des données BEV est souvent affectée par des erreurs d'installation/calibrage du capteur, des cartes de haute précision et l'algorithme de reconstruction lui-même. cela m'a amené à
 GSLAM | Une architecture générale et un benchmark
Oct 20, 2023 am 11:37 AM
GSLAM | Une architecture générale et un benchmark
Oct 20, 2023 am 11:37 AM
J'ai soudainement découvert un article vieux de 19 ans GSLAM : A General SLAM Framework and Benchmark open source code : https://github.com/zdzhaoyong/GSLAM Accédez directement au texte intégral et ressentez la qualité de ce travail ~ 1 Technologie SLAM abstraite a remporté de nombreux succès récemment et a attiré de nombreuses entreprises de haute technologie. Cependant, la question de savoir comment s'interfacer avec les algorithmes existants ou émergents pour effectuer efficacement des analyses comparatives en termes de vitesse, de robustesse et de portabilité reste une question. Dans cet article, une nouvelle plateforme SLAM appelée GSLAM est proposée, qui fournit non seulement des capacités d'évaluation, mais fournit également aux chercheurs un moyen utile de développer rapidement leurs propres systèmes SLAM.
