
 Périphériques technologiques
IA
Un moyen simple de traiter de grands ensembles de données d'apprentissage automatique en Python
Périphériques technologiques
IA
Un moyen simple de traiter de grands ensembles de données d'apprentissage automatique en Python
Un moyen simple de traiter de grands ensembles de données d'apprentissage automatique en Python

Public cible pour cet article :
- Les personnes qui souhaitent effectuer des opérations Pandas/NumPy sur de grands ensembles de données.
- Les personnes souhaitant utiliser Python pour effectuer des tâches d'apprentissage automatique sur le Big Data.

Cet article utilisera des fichiers au format .csv pour démontrer diverses opérations de python, ainsi que d'autres formats tels que des tableaux, des fichiers texte, etc.
Pourquoi ne pouvons-nous pas utiliser des pandas pour de grands ensembles de données d'apprentissage automatique ?
Nous savons que Pandas utilise la mémoire de l'ordinateur (RAM) pour charger votre ensemble de données d'apprentissage automatique, mais si votre ordinateur dispose de 8 Go de mémoire (RAM), pourquoi les pandas ne peuvent-ils toujours pas charger un ensemble de données de 2 Go ? La raison en est que le chargement d'un fichier de 2 Go à l'aide de Pandas nécessite non seulement 2 Go de RAM, mais plus de mémoire, car la mémoire totale requise dépend de la taille de l'ensemble de données et des opérations que vous effectuerez sur cet ensemble de données.
Voici une comparaison rapide des ensembles de données de différentes tailles chargés dans la mémoire de l'ordinateur :
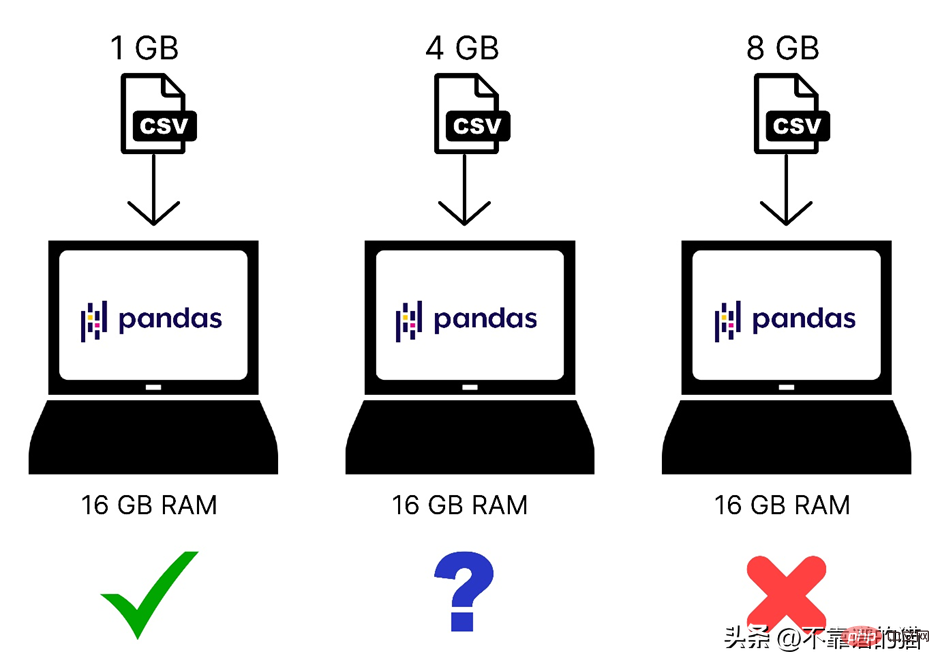
De plus, Pandas n'utilise qu'un seul cœur du système d'exploitation, ce qui ralentit le traitement. En d’autres termes, nous pouvons dire que pandas ne prend pas en charge le parallélisme (divisant un problème en tâches plus petites).
Supposons que l'ordinateur dispose de 4 cœurs. La figure suivante montre le nombre de cœurs utilisés par les pandas lors du chargement d'un fichier CSV :
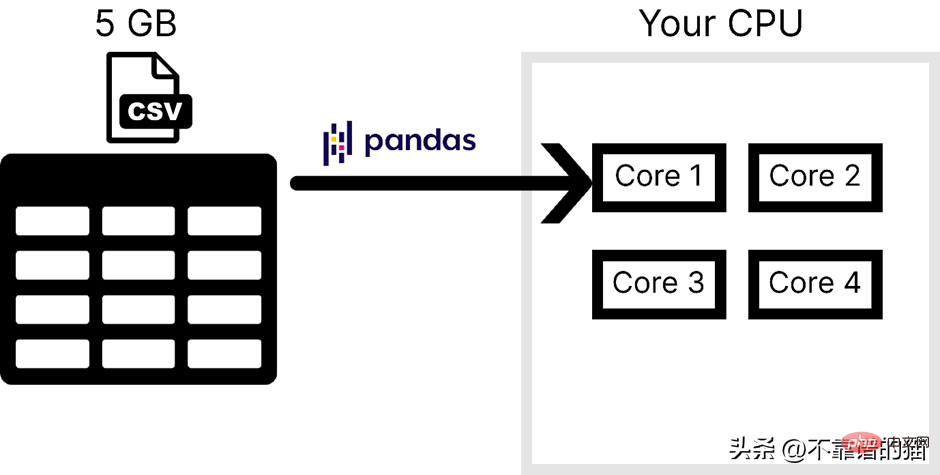
Les principales raisons pour lesquelles les pandas ne sont généralement pas utilisés pour traiter de grands ensembles de données d'apprentissage automatique sont les suivantes : suit : l’un est l’utilisation de la mémoire de l’ordinateur et le second est le manque de parallélisme. Dans NumPy et Scikit-learn, le même problème se pose pour les grands ensembles de données.
Pour résoudre ces deux problèmes, vous pouvez utiliser une bibliothèque python appelée Dask, qui nous permet d'effectuer diverses opérations telles que pandas, NumPy et ML sur de grands ensembles de données.
Comment fonctionne Dask ?
Dask charge votre ensemble de données dans des partitions, tandis que pandas charge généralement l'intégralité de l'ensemble de données d'apprentissage automatique sous forme de trame de données. Dans Dask, chaque partition d'un ensemble de données est considérée comme une trame de données pandas.
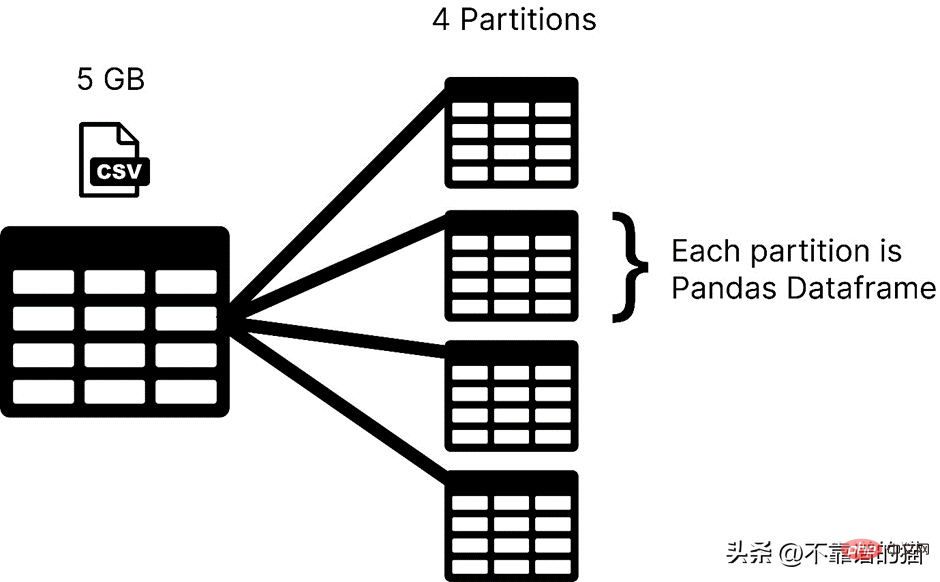
Dask charge une partition à la fois, vous n'avez donc pas à vous soucier des erreurs d'allocation de mémoire.
Voici une comparaison de l'utilisation de dask pour charger des ensembles de données d'apprentissage automatique de différentes tailles dans la mémoire de l'ordinateur :
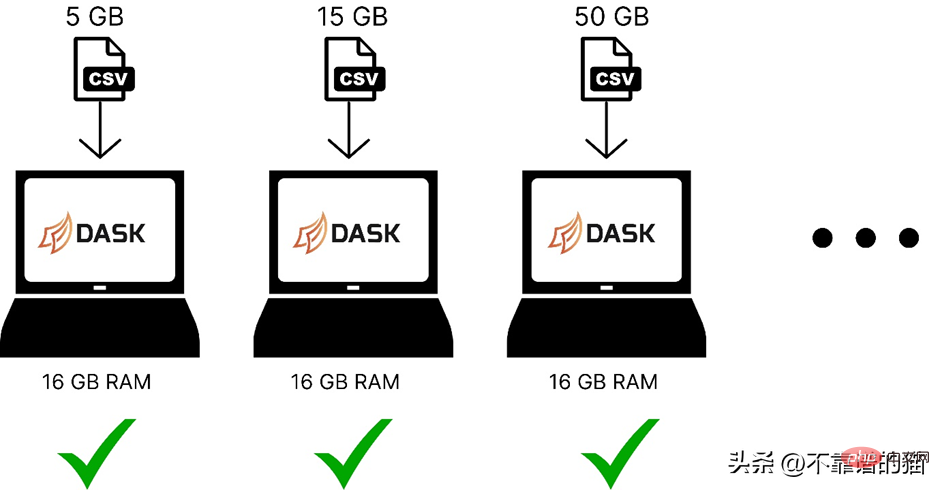
Dask résout le problème du parallélisme car il divise les données en plusieurs partitions, en utilisant un noyau distinct, qui effectue les calculs. sur l'ensemble de données plus rapidement.
En supposant que l'ordinateur ait 4 cœurs, voici comment dask charge un fichier csv de 5 Go :
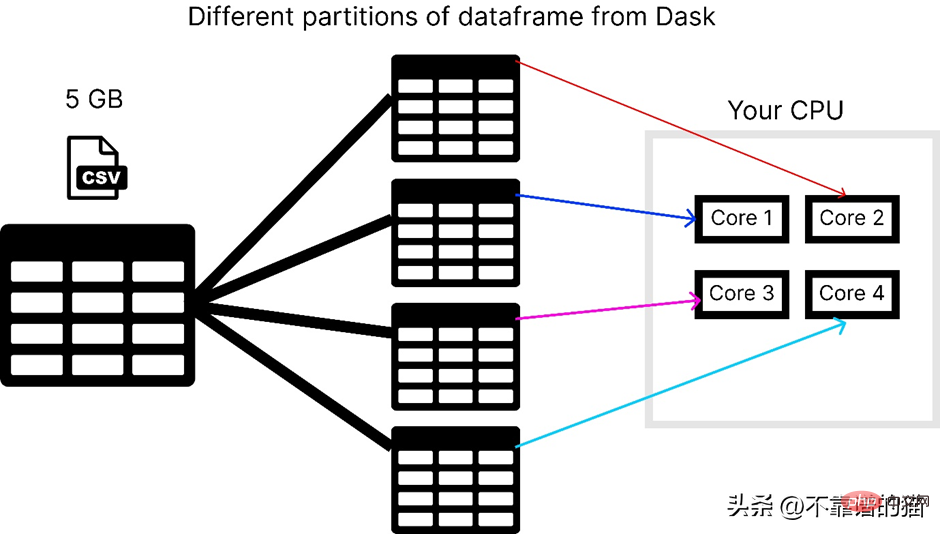
Pour utiliser la bibliothèque dask, vous pouvez l'installer à l'aide de la commande suivante :
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span>
Dask possède plusieurs modules comme dask. array, dask.dataframe et dask.distributed ne fonctionneront que si vous avez installé respectivement les bibliothèques correspondantes (telles que NumPy, pandas et Tornado).
Comment utiliser dask pour traiter des fichiers CSV volumineux ?
dask.dataframe est utilisé pour gérer de gros fichiers csv, j'ai d'abord essayé d'importer un ensemble de données de 8 Go à l'aide de pandas.
<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">import</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pandas</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">as</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pd</span><br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">df</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pd</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">read_csv</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">“data</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">csv”</span>)
Il a généré une erreur d'allocation de mémoire dans mon ordinateur portable de 16 Go de RAM.
Maintenant, essayez d'importer les mêmes données de 8 Go en utilisant dask.dataframe
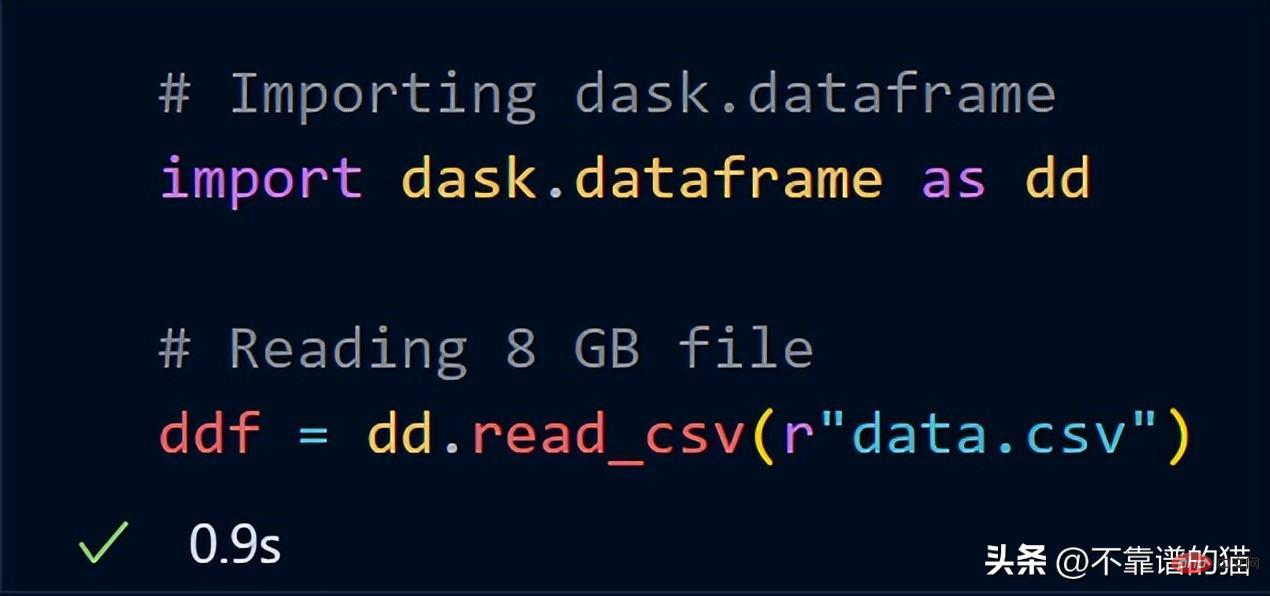
dask n'a pris qu'une seconde pour charger l'intégralité du fichier de 8 Go dans la variable ddf.
Voyons le résultat de la variable ddf.
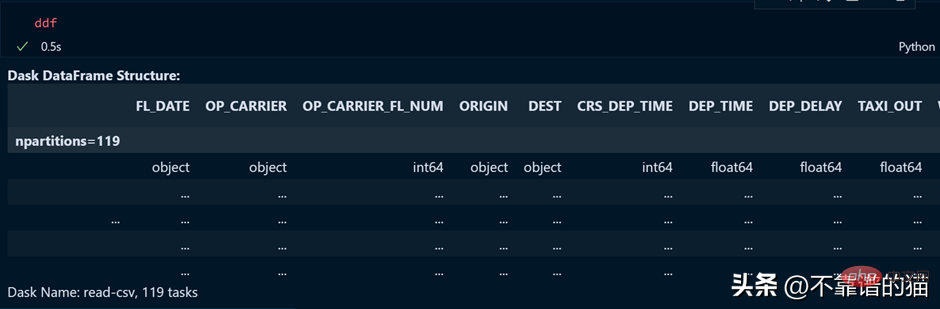
Comme vous pouvez le constater, le temps d'exécution est de 0,5 seconde, et il est montré ici qu'il a été divisé en 119 partitions.
Vous pouvez également vérifier le nombre de partitions de votre dataframe en utilisant :
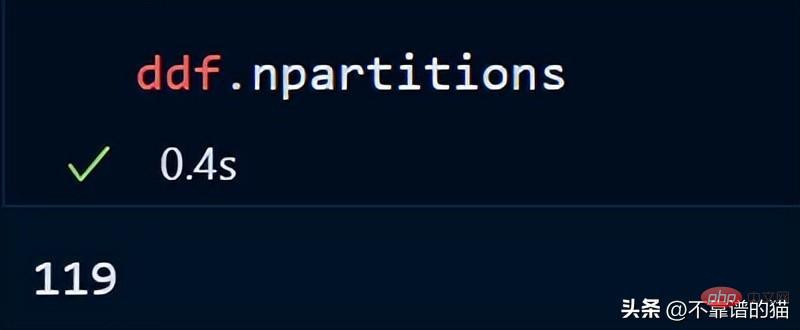
Par défaut, dask a chargé mon fichier CSV de 8 Go dans 119 partitions (chaque taille de partition est de 64 Mo), ceci est basé sur ce qui est disponible. effectué en fonction de la mémoire physique et du nombre de cœurs de l'ordinateur.
Peut également spécifier mon propre nombre de partitions en utilisant le paramètre Blocksize lors du chargement du fichier CSV.
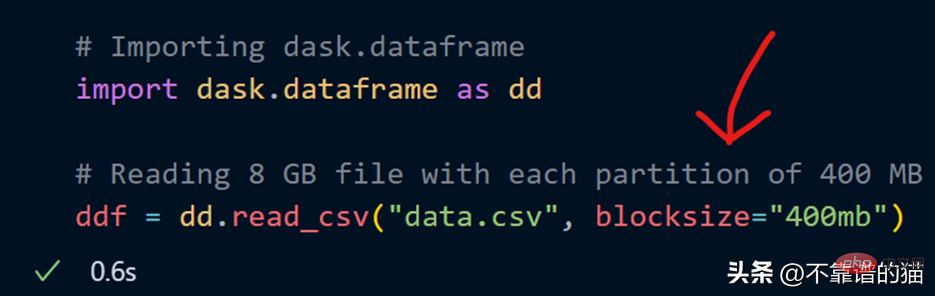
Maintenant, un paramètre de taille de bloc avec une valeur de chaîne de 400 Mo est spécifié, ce qui donne à chaque partition une taille de 400 Mo. Voyons combien de partitions il y a
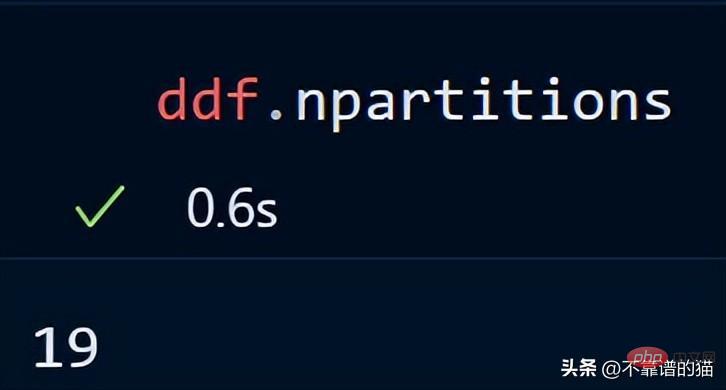
Point clé : lors de l'utilisation de Dask DataFrames, une bonne règle une solution empirique consiste à conserver les partitions sous 100 Mo.
Une partition spécifique du dataframe peut être appelée en utilisant :
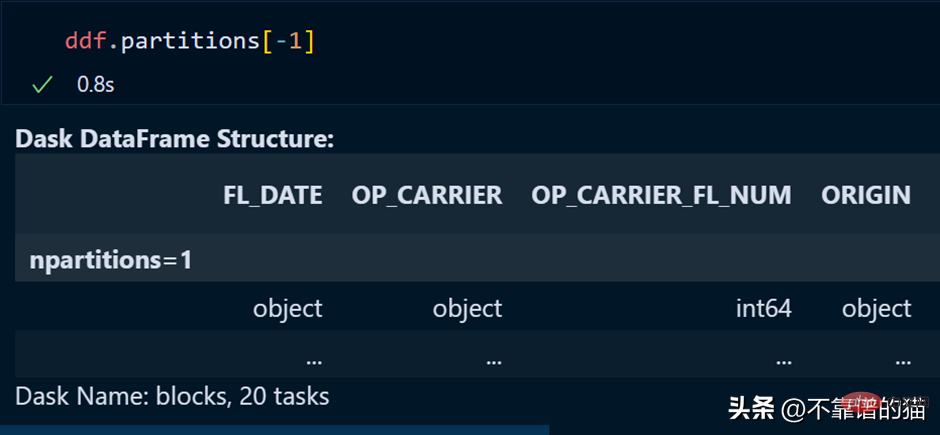
La dernière partition peut également être appelée en utilisant un index négatif, tout comme nous l'avons fait lors de l'appel du dernier élément de la liste.
Voyons la forme de l'ensemble de données :
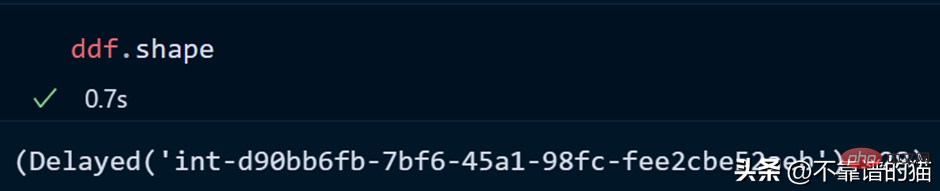
Vous pouvez utiliser len() pour vérifier le nombre de lignes dans l'ensemble de données :
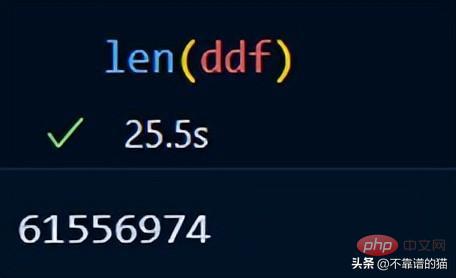
Dask inclut déjà un exemple d'ensemble de données. J'utiliserai des données de séries chronologiques pour vous montrer comment dask effectue des opérations mathématiques sur un ensemble de données.
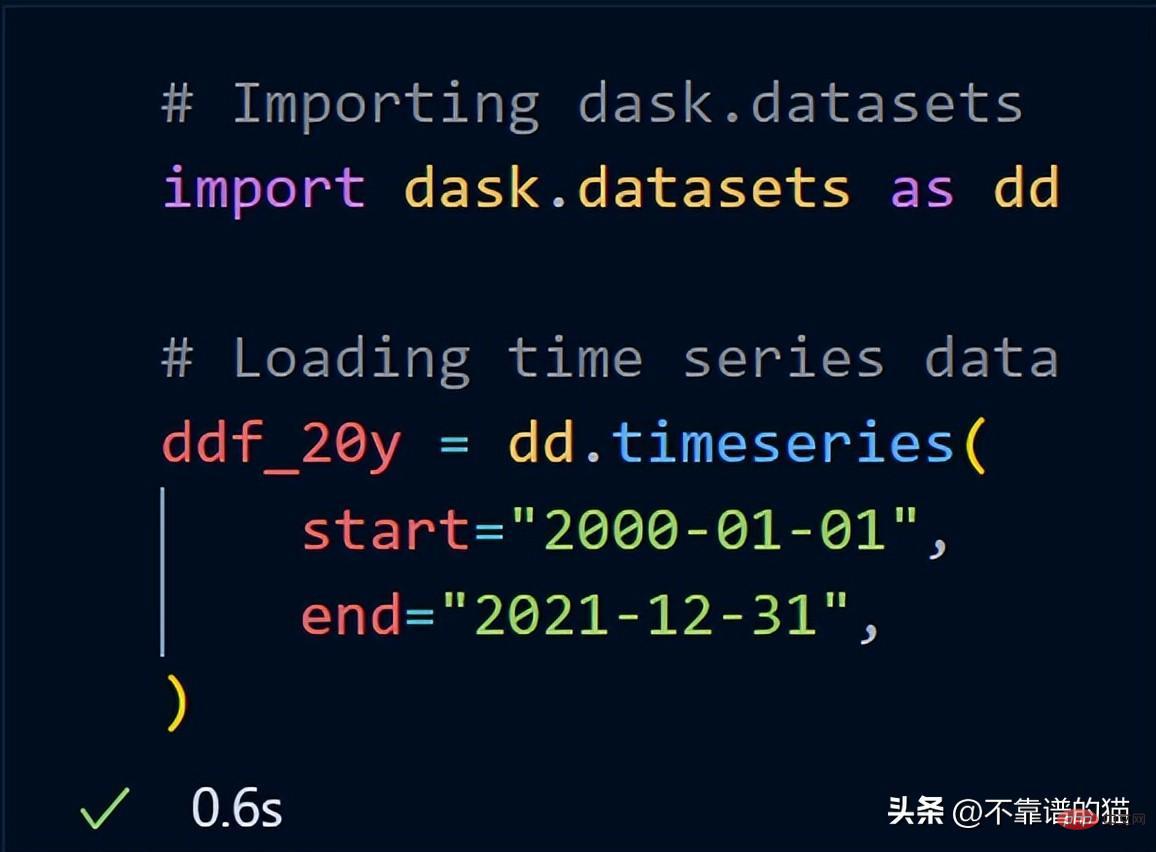
Après avoir importé dask.datasets, ddf_20y a chargé les données de séries chronologiques du 1er janvier 2000 au 31 décembre 2021.
Regardons le nombre de partitions pour nos données de séries chronologiques.
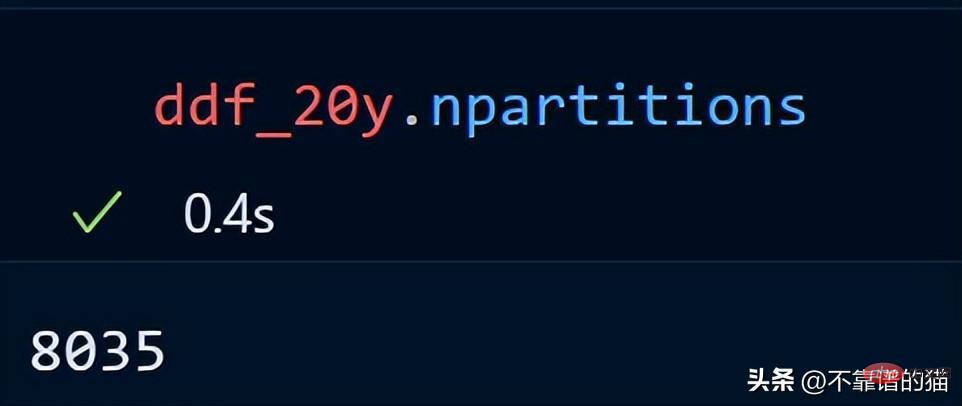
Les données de séries chronologiques sur 20 ans sont réparties dans 8035 partitions.
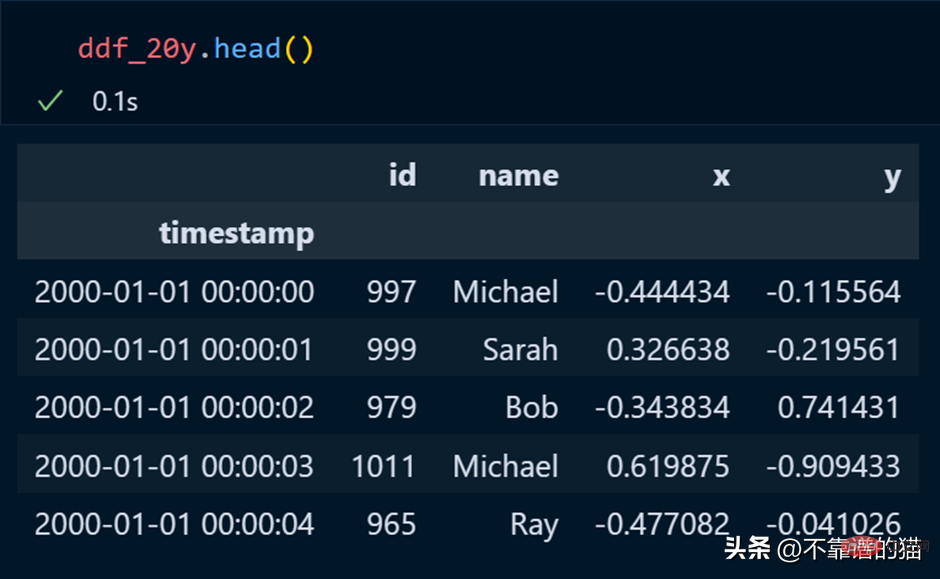
Chez les pandas, nous utilisons head pour imprimer les premières lignes de l'ensemble de données, et il en va de même pour dask.
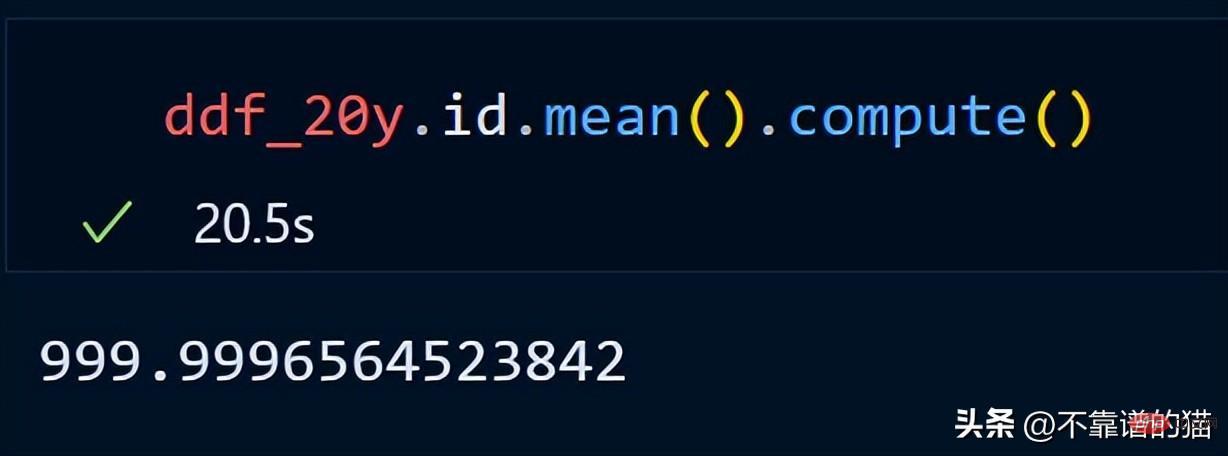
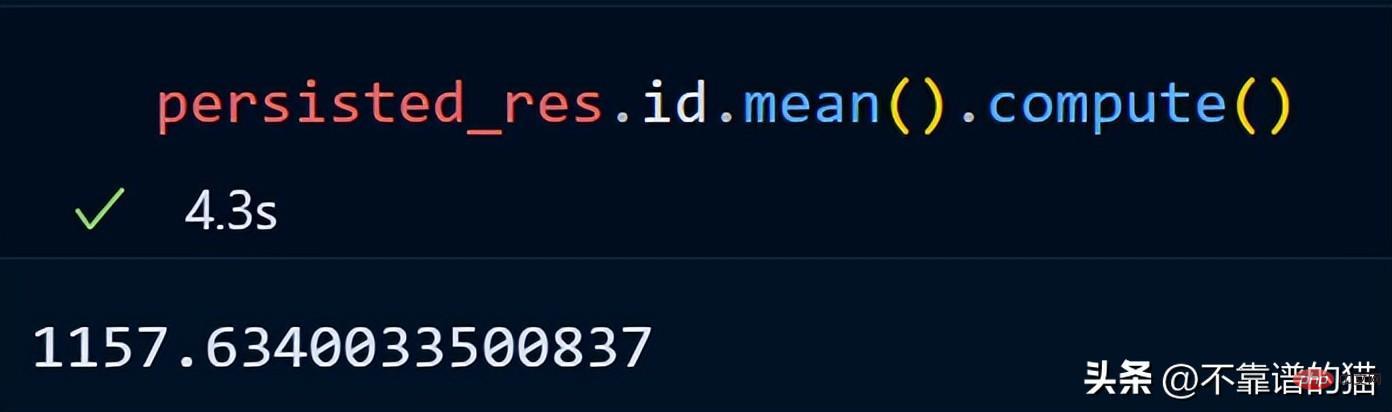
Calculons la moyenne de la colonne id.
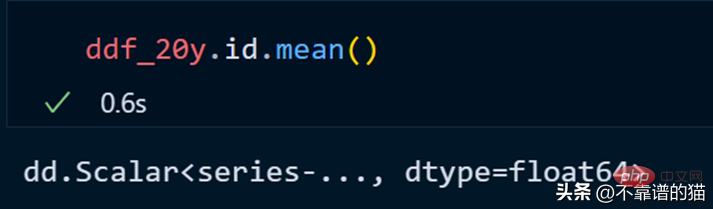
dask n'imprime pas le nombre total de lignes du dataframe car il utilise des calculs paresseux (la sortie n'est affichée que lorsque cela est nécessaire). Pour afficher la sortie, nous pouvons utiliser la méthode de calcul.
Supposons que je veuille normaliser chaque colonne de l'ensemble de données (convertir la valeur entre 0 et 1), le code Python est le suivant :
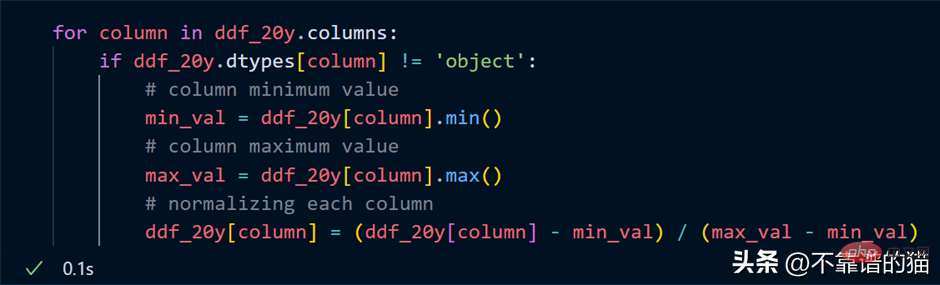
Parcourez les colonnes et trouvez la somme minimale de chacune valeur maximale de la colonne et normalisez ces colonnes à l’aide d’une formule mathématique simple.
Point clé : dans notre exemple de normalisation, ne pensez pas qu'un calcul numérique réel se produit, il s'agit simplement d'une évaluation paresseuse (le résultat ne vous est jamais montré tant qu'il n'est pas nécessaire).
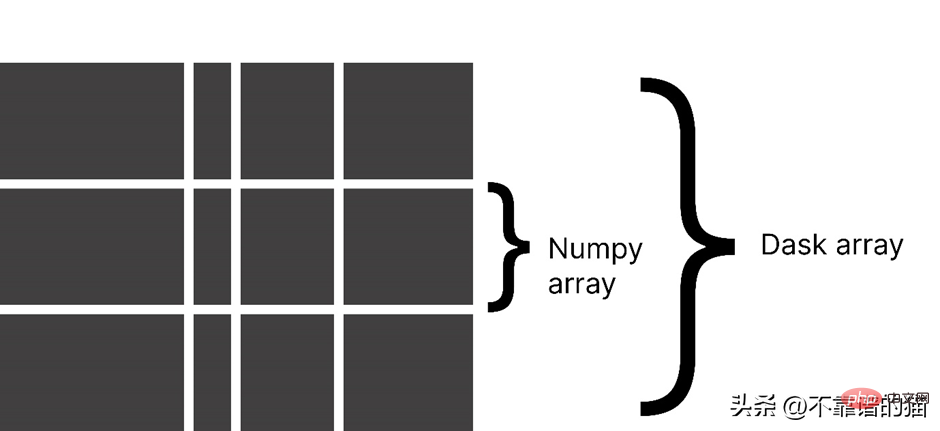
Pourquoi utiliser le tableau Dask ?
Dask divise un tableau en petits morceaux, chaque morceau étant un tableau NumPy.
dask.arrays est utilisé pour gérer de grands tableaux, le code Python suivant utilise dask pour créer un tableau de 10 000 x 10 000 et le stocke dans la variable x.
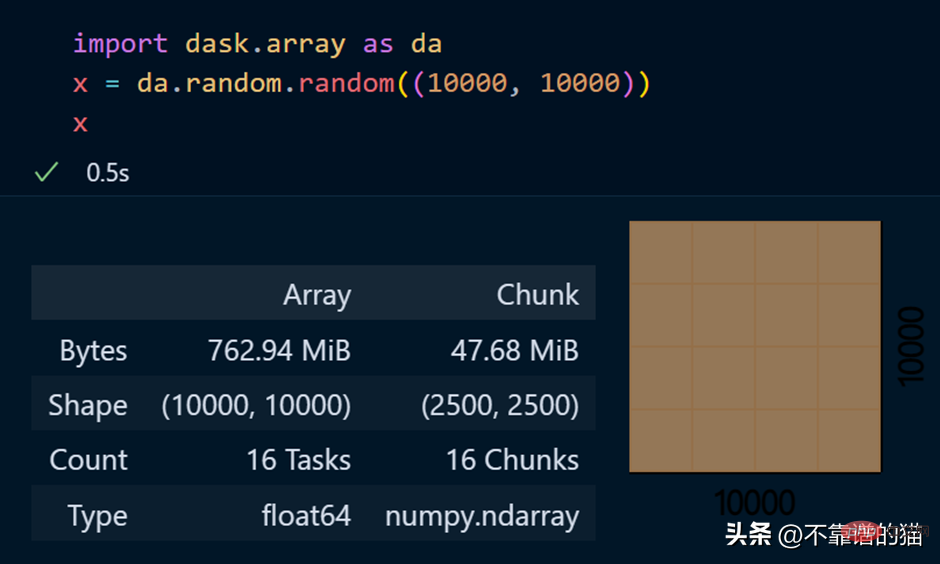
L'appel de la variable x produit diverses informations sur le tableau.
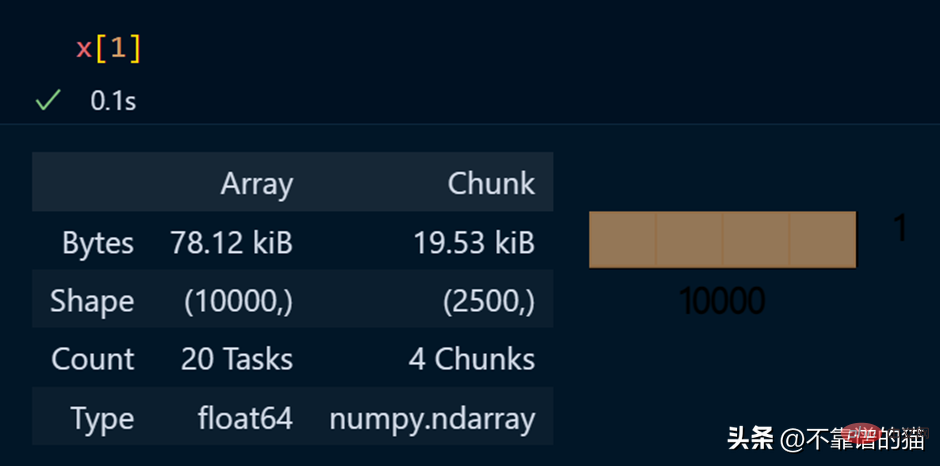
Afficher des éléments spécifiques d'un tableau
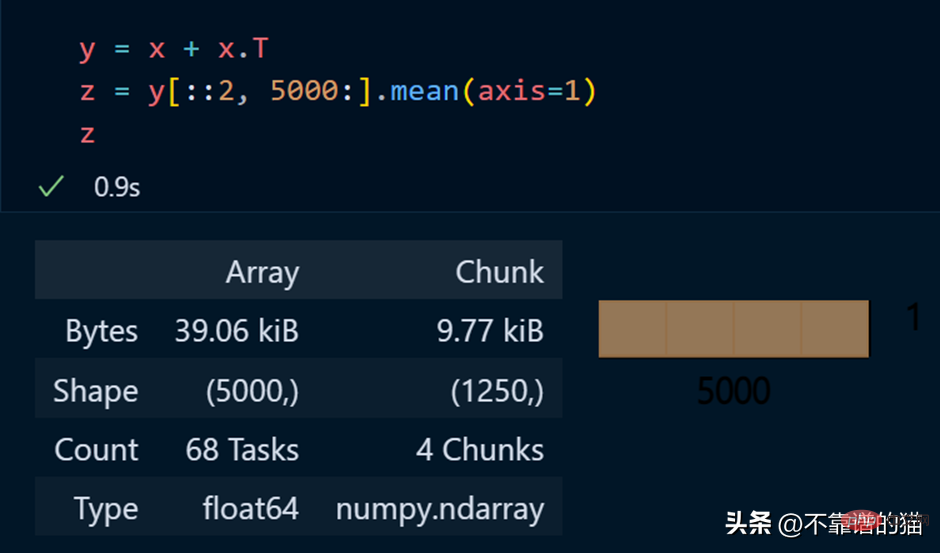
Exemple Python d'exécution d'opérations mathématiques sur un tableau dask :
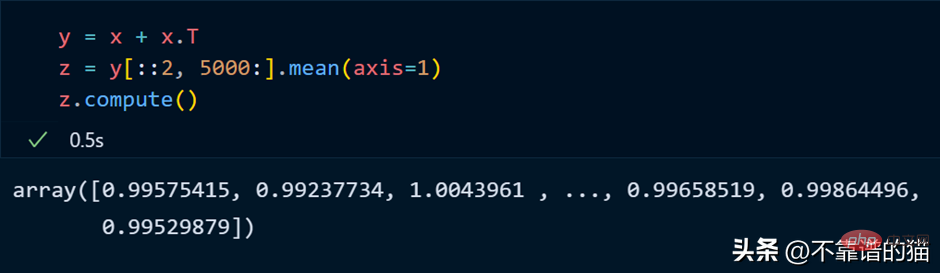
正如您所看到的,由于延迟执行,它不会向您显示输出。我们可以使用compute来显示输出:
dask 数组支持大多数 NumPy 接口,如下所示:
- 数学运算:+, *, exp, log, ...
- sum(), mean(), std(), sum(axis=0), ...
- 张量/点积/矩阵乘法:tensordot
- 重新排序/转置:transpose
- 切片:x[:100, 500:100:-2]
- 使用列表或 NumPy 数组进行索引:x[:, [10, 1, 5]]
- 线性代数:svd、qr、solve、solve_triangular、lstsq
但是,Dask Array 并没有实现完整 NumPy 接口。
你可以从他们的官方文档中了解更多关于 dask.arrays 的信息。
什么是Dask Persist?
假设您想对机器学习数据集执行一些耗时的操作,您可以将数据集持久化到内存中,从而使数学运算运行得更快。
从 dask.datasets 导入了时间序列数据
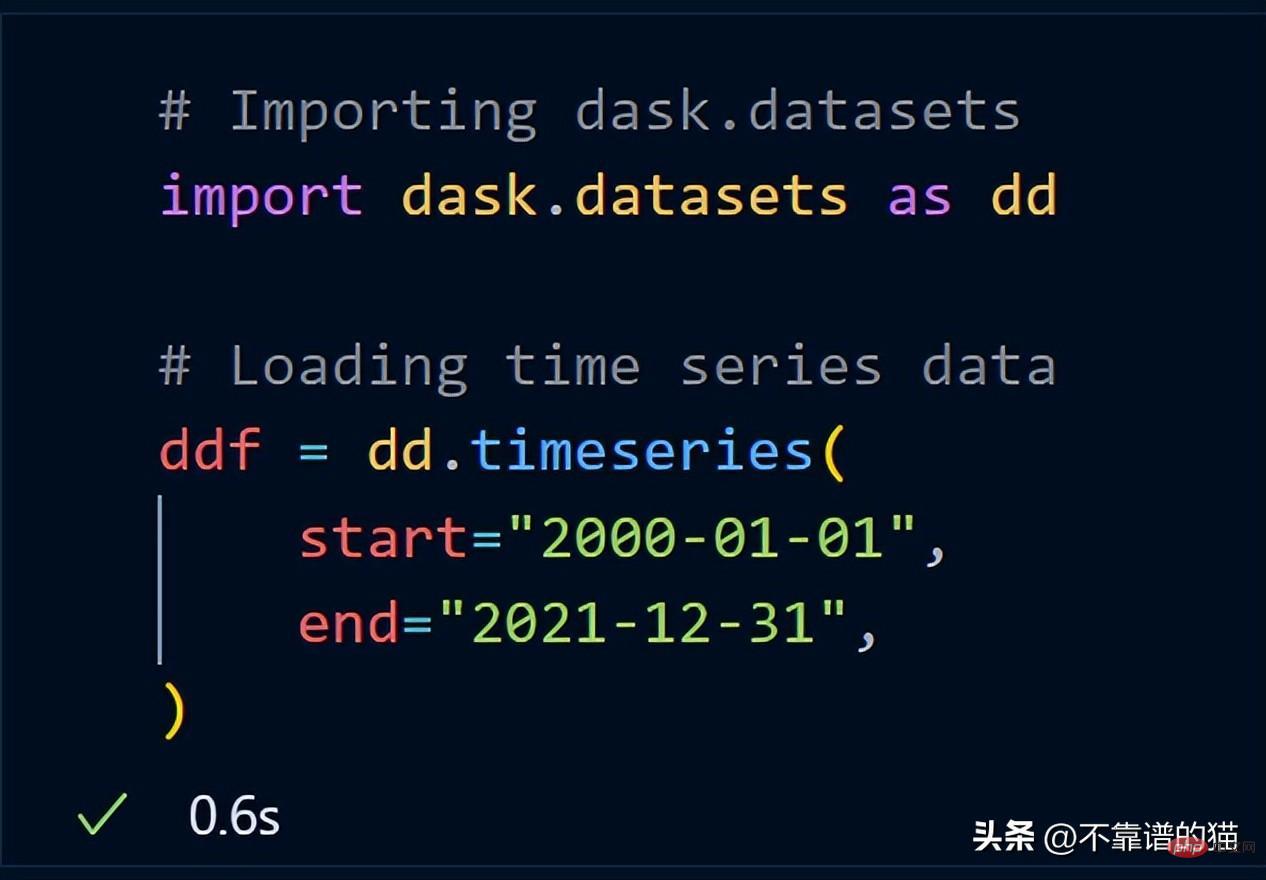
让我们取数据集的一个子集并计算该子集的总行数。
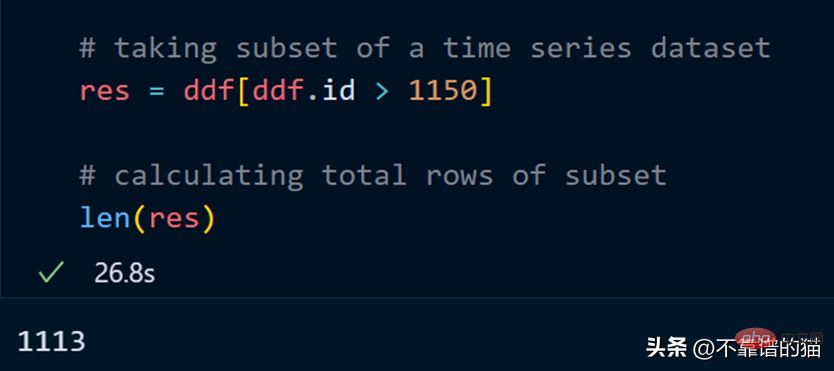
计算总行数需要 27 秒。
我们现在使用 persist 方法:
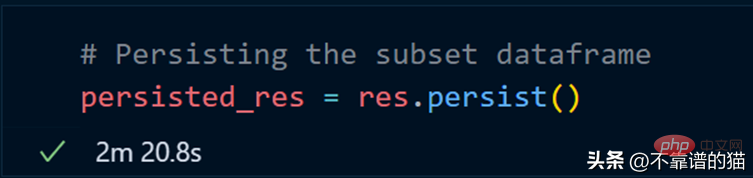
持久化我们的子集总共花了 2 分钟,现在让我们计算总行数。
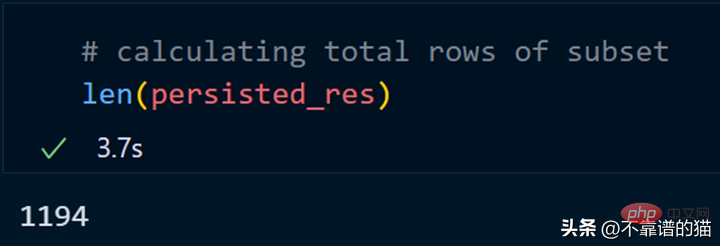
同样,我们可以对持久化数据集执行其他操作以减少计算时间。
persist应用场景:
- 数据量大
- 获取数据的一个子集
- 对子集应用不同的操作
为什么选择 Dask ML?
Dask ML有助于在大型数据集上使用流行的Python机器学习库(如Scikit learn等)来应用ML(机器学习)算法。
什么时候应该使用 dask ML?
- 数据不大(或适合 RAM),但训练的机器学习模型需要大量超参数,并且调优或集成技术需要大量时间。
- 数据量很大。
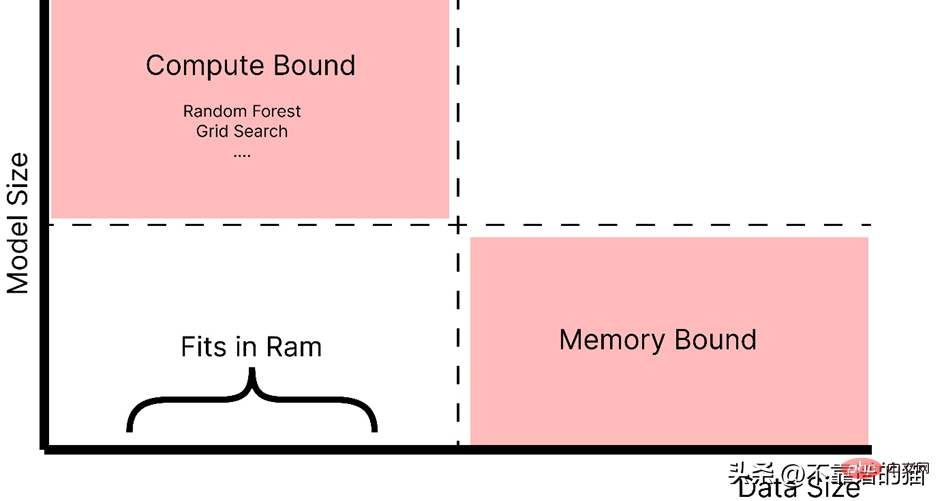
正如你所看到的,随着模型大小的增加,例如,制作一个具有大量超参数的复杂模型,它会引起计算边界的问题,而如果数据大小增加,它会引起内存分配错误。因此,在这两种情况下(红色阴影区域)我们都使用 Dask 来解决这些问题。
如官方文档中所述,dask ml 库用例:
- 对于内存问题,只需使用 scikit-learn(或其他ML 库)。
- 对于大型模型,使用 dask_ml.joblib 和scikit-learn estimators。
- 对于大型数据集,使用 dask_ml estimators。
让我们看一下 Dask.distributed 的架构:
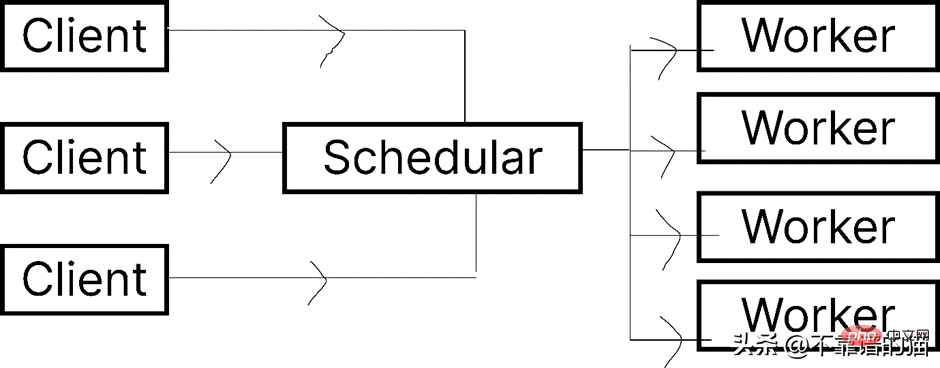
Dask 让您能够在计算机集群上运行任务。在 dask.distributed 中,只要您分配任务,它就会立即开始执行。
简单地说,client就是提交任务的你,执行任务的是Worker,调度器则执行两者之间通信。
python -m <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span> distributed –upgrade
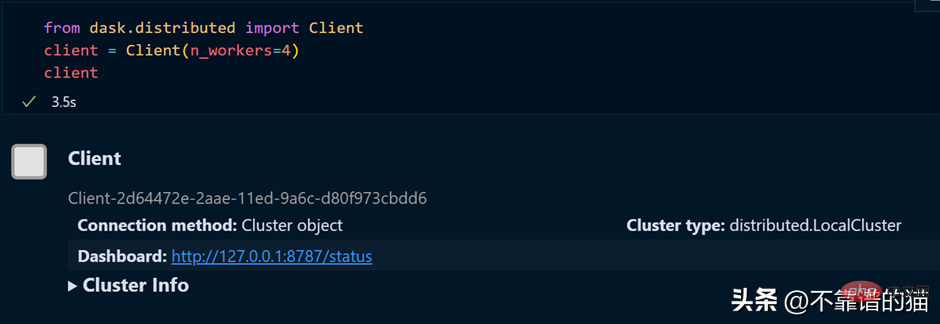
如果您使用的是单台机器,那么就可以通过以下方式创建一个具有4个worker的dask集群
如果需要dashboard,可以安装bokeh,安装bokeh的命令如下:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">bokeh</span>
就像我们从 dask.distributed 创建客户端一样,我们也可以从 dask.distributed 创建调度程序。
要使用 dask ML 库,您必须使用以下命令安装它:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span>-ml
我们将使用 Scikit-learn 库来演示 dask-ml 。
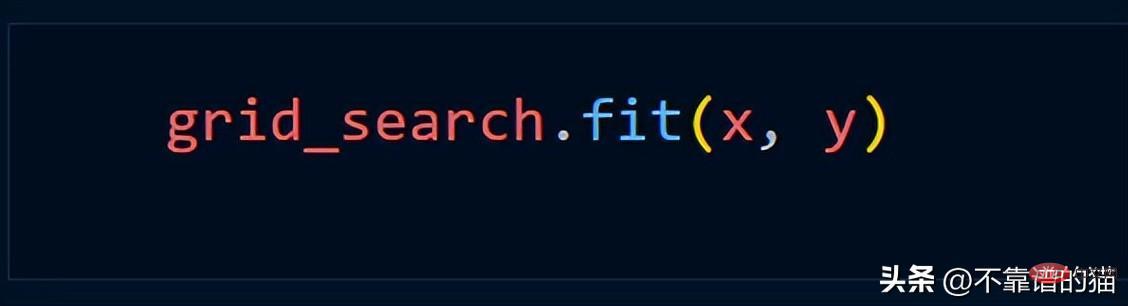
En supposant que nous utilisons la méthode Grid_Search, nous utilisons généralement le code Python suivant
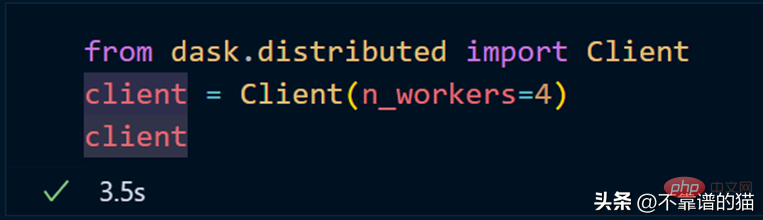
Créez un cluster à l'aide de dask.distributed :
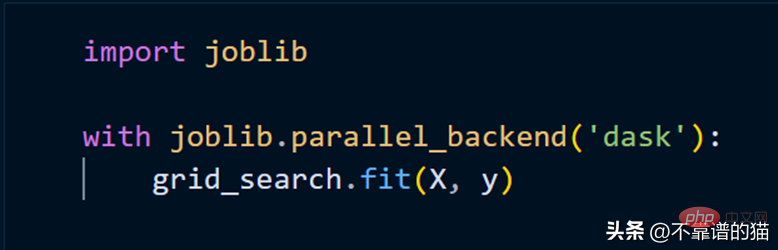
Pour adapter le modèle scikit-learn à l'aide de clusters, il nous suffit d'utiliser joblib.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment les plumes PS contrôlent-elles la douceur de la transition?
Apr 06, 2025 pm 07:33 PM
Comment les plumes PS contrôlent-elles la douceur de la transition?
Apr 06, 2025 pm 07:33 PM
La clé du contrôle des plumes est de comprendre sa nature progressive. Le PS lui-même ne fournit pas la possibilité de contrôler directement la courbe de gradient, mais vous pouvez ajuster de manière flexible le rayon et la douceur du gradient par plusieurs plumes, des masques correspondants et des sélections fines pour obtenir un effet de transition naturel.
 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment configurer des plumes de PS?
Apr 06, 2025 pm 07:36 PM
Comment configurer des plumes de PS?
Apr 06, 2025 pm 07:36 PM
La plume PS est un effet flou du bord de l'image, qui est réalisé par la moyenne pondérée des pixels dans la zone de bord. Le réglage du rayon de la plume peut contrôler le degré de flou, et plus la valeur est grande, plus elle est floue. Le réglage flexible du rayon peut optimiser l'effet en fonction des images et des besoins. Par exemple, l'utilisation d'un rayon plus petit pour maintenir les détails lors du traitement des photos des caractères et l'utilisation d'un rayon plus grand pour créer une sensation brumeuse lorsque le traitement de l'art fonctionne. Cependant, il convient de noter que trop grand, le rayon peut facilement perdre des détails de bord, et trop petit, l'effet ne sera pas évident. L'effet de plumes est affecté par la résolution de l'image et doit être ajusté en fonction de la compréhension de l'image et de la saisie de l'effet.
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
MySQL a refusé de commencer? Ne paniquez pas, vérifions-le! De nombreux amis ont découvert que le service ne pouvait pas être démarré après avoir installé MySQL, et ils étaient si anxieux! Ne vous inquiétez pas, cet article vous emmènera pour le faire face calmement et découvrez le cerveau derrière! Après l'avoir lu, vous pouvez non seulement résoudre ce problème, mais aussi améliorer votre compréhension des services MySQL et vos idées de problèmes de dépannage, et devenir un administrateur de base de données plus puissant! Le service MySQL n'a pas réussi et il y a de nombreuses raisons, allant des erreurs de configuration simples aux problèmes système complexes. Commençons par les aspects les plus courants. Connaissances de base: une brève description du processus de démarrage du service MySQL Service Startup. Autrement dit, le système d'exploitation charge les fichiers liés à MySQL, puis démarre le démon mysql. Cela implique la configuration
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
