
 Périphériques technologiques
IA
La recherche montre que les modèles d'apprentissage par renforcement sont vulnérables aux attaques par inférence d'adhésion
Périphériques technologiques
IA
La recherche montre que les modèles d'apprentissage par renforcement sont vulnérables aux attaques par inférence d'adhésion
La recherche montre que les modèles d'apprentissage par renforcement sont vulnérables aux attaques par inférence d'adhésion

Traducteur | Li Rui
Réviseur | Sun Shujuan
À mesure que l'apprentissage automatique fait partie de nombreuses applications que les gens utilisent quotidiennement, les gens accordent de plus en plus d'attention à la manière d'identifier et de résoudre la sécurité et les vulnérabilités de l'apprentissage automatique. modèles. Menaces pour la vie privée.
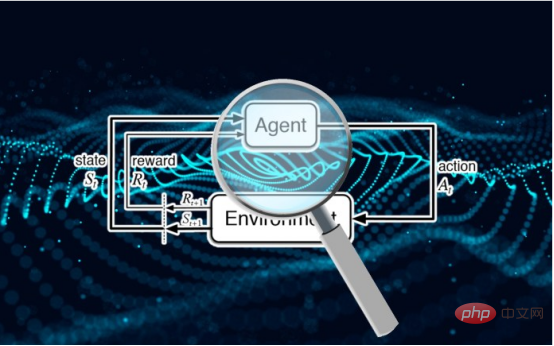
Cependant, les menaces de sécurité auxquelles sont confrontés les différents paradigmes d'apprentissage automatique varient et certains domaines de la sécurité de l'apprentissage automatique restent sous-étudiés. En particulier, la sécurité des algorithmes d’apprentissage par renforcement n’a pas reçu beaucoup d’attention ces dernières années.
Des chercheurs de l'Université McGill, du Machine Learning Laboratory (MILA) au Canada et de l'Université de Waterloo ont mené une nouvelle étude axée sur les menaces pour la vie privée liées aux algorithmes d'apprentissage par renforcement profond. Les chercheurs proposent un cadre pour tester la vulnérabilité des modèles d’apprentissage par renforcement aux attaques par inférence d’appartenance.
Les résultats de recherche montrent que les attaquants peuvent attaquer efficacement les systèmes d'apprentissage par renforcement profond (RL) et peuvent obtenir des informations sensibles utilisées pour entraîner des modèles. Leurs découvertes sont importantes car les techniques d’apprentissage par renforcement font désormais leur chemin dans les applications industrielles et grand public.
Attaque d'inférence d'adhésion
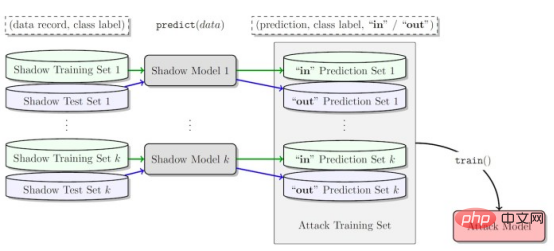
L'attaque d'inférence d'adhésion observe le comportement d'un modèle d'apprentissage automatique cible et prédit les exemples utilisés pour l'entraîner.
Chaque modèle d'apprentissage automatique est formé sur un ensemble d'exemples. Dans certains cas, les exemples de formation incluent des informations sensibles, telles que des données de santé ou financières ou d'autres informations personnellement identifiables.
Les attaques par inférence de membres sont une série de techniques qui tentent de forcer un modèle d'apprentissage automatique à divulguer les données de son ensemble d'entraînement. Alors que les exemples contradictoires (le type d'attaque le plus connu contre l'apprentissage automatique) se concentrent sur la modification du comportement des modèles d'apprentissage automatique et sont considérés comme une menace pour la sécurité, les attaques par inférence d'appartenance se concentrent sur l'extraction d'informations du modèle et constituent davantage une menace pour la vie privée.
Les attaques par inférence d'adhésion ont été bien étudiées dans les algorithmes d'apprentissage automatique supervisé, où les modèles sont formés sur des exemples étiquetés.
Contrairement à l'apprentissage supervisé, les systèmes d'apprentissage par renforcement profond n'utilisent pas d'exemples étiquetés. Un agent d'apprentissage par renforcement (RL) reçoit des récompenses ou des pénalités en fonction de ses interactions avec l'environnement. Il apprend et développe progressivement son comportement grâce à ces interactions et signaux de renforcement.
Les auteurs de l'article ont déclaré dans des commentaires écrits : « Les récompenses dans l'apprentissage par renforcement ne représentent pas nécessairement des étiquettes ; par conséquent, elles ne peuvent pas servir d'étiquettes prédictives souvent utilisées dans la conception d'attaques d'inférence d'appartenance dans d'autres paradigmes d'apprentissage
. Recherche "Il n'existe actuellement aucune étude sur la fuite potentielle de données utilisées directement pour former des agents d'apprentissage par renforcement profond", ont écrit les chercheurs dans leur article.
Ce manque de recherche s'explique en partie par le fait que l'apprentissage par renforcement est. moins efficace dans le monde réel. Les applications sont limitées.
Les auteurs du document de recherche déclarent : « Malgré des progrès significatifs dans le domaine de l'apprentissage par renforcement profond, tels qu'Alpha Go, Alpha Fold et GT Sophy, les modèles d'apprentissage par renforcement profond ne sont toujours pas largement adoptés à l'échelle industrielle. D’un autre côté, la confidentialité des données est un domaine de recherche très largement utilisé. Le manque de modèles d’apprentissage par renforcement profond dans les applications industrielles réelles a considérablement retardé la recherche dans ce domaine de recherche fondamental et important, entraînant une recherche insuffisante sur les attaques contre les systèmes d’apprentissage par renforcement.
Avec le besoin croissant d'appliquer des algorithmes d'apprentissage par renforcement à l'échelle industrielle dans des scénarios du monde réel, l'accent et les exigences strictes des cadres qui abordent les aspects de confidentialité des algorithmes d'apprentissage par renforcement d'un point de vue contradictoire et algorithmique deviennent de plus en plus évidents et pertinent.
Défis de l'inférence d'adhésion dans l'apprentissage par renforcement profond
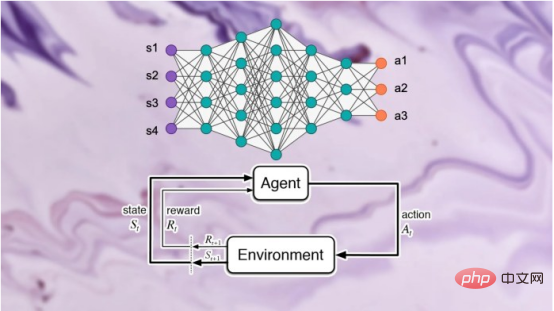
Les auteurs du document de recherche ont déclaré : « Nos efforts pour développer la première génération d'algorithmes d'apprentissage par renforcement profond préservant la confidentialité nous ont amenés à réaliser que de la confidentialité De D’un point de vue, il existe des différences structurelles fondamentales entre les algorithmes d’apprentissage automatique traditionnels et les algorithmes d’apprentissage par renforcement. Les chercheurs ont découvert que, plus important encore, les différences fondamentales entre l'apprentissage par renforcement profond et d'autres paradigmes d'apprentissage posent de sérieux défis lors du déploiement de modèles d'apprentissage par renforcement profond pour des applications pratiques, compte tenu des conséquences potentielles sur la vie privée. Sur la base de cette compréhension, la plus grande question pour nous est la suivante : dans quelle mesure les algorithmes d'apprentissage par renforcement profond sont-ils vulnérables aux attaques contre la vie privée telles que les attaques par inférence d'adhésion. Les modèles d'attaque par inférence d'adhésion existants sont conçus spécifiquement pour d'autres paradigmes d'apprentissage ? la vulnérabilité des algorithmes d’apprentissage par renforcement profond à de telles attaques est en grande partie inconnue, étant donné les graves implications pour la vie privée lorsqu’ils sont déployés dans le monde. La nécessité de sensibiliser davantage la recherche et l’industrie était la principale motivation de cette étude » Pendant la formation. , un modèle d'apprentissage par renforcement passe par plusieurs étapes, chacune consistant en une trajectoire ou une séquence d'actions et d'états. Par conséquent, un algorithme d’attaque par inférence d’appartenance réussi pour l’apprentissage par renforcement doit apprendre les points de données et les trajectoires utilisés pour entraîner le modèle. D’une part, cela rend plus difficile la conception d’algorithmes d’inférence d’appartenance pour les systèmes d’apprentissage par renforcement, d’autre part, cela rend également difficile l’évaluation de la robustesse des modèles d’apprentissage par renforcement face à de telles attaques ; Les auteurs déclarent : « Les attaques par inférence d'adhésion (MIA) sont difficiles en apprentissage par renforcement par rapport à d'autres types d'apprentissage automatique en raison de la nature séquentielle et dépendante du temps des points de données utilisés lors de la formation et de la prédiction Many-to. -de nombreuses relations entre les points de données sont fondamentalement différentes des autres paradigmes d'apprentissage » La différence fondamentale entre l'apprentissage par renforcement et les autres paradigmes d'apprentissage automatique rend difficile la conception et l'évaluation d'attaques d'inférence d'appartenance pour l'apprentissage par renforcement profond. façons. Dans leur étude, les chercheurs se sont concentrés sur les algorithmes d'apprentissage par renforcement non liés aux politiques, où les processus de collecte de données et de formation de modèles sont séparés. L'apprentissage par renforcement utilise un « tampon de relecture » pour décorréler les trajectoires d'entrée et permettre à l'agent d'apprentissage par renforcement d'explorer de nombreuses trajectoires différentes à partir du même ensemble de données. L'apprentissage par renforcement sans politique est particulièrement important pour de nombreuses applications du monde réel où les données de formation préexistent et sont fournies à l'équipe d'apprentissage automatique qui forme le modèle d'apprentissage par renforcement. L’apprentissage par renforcement non lié aux politiques est également essentiel pour créer des modèles d’attaque par inférence d’adhésion. L'apprentissage par renforcement sans politique utilise un « tampon de relecture » pour réutiliser les données précédemment collectées lors de la formation du modèle. Les auteurs déclarent : « Les phases d'exploration et d'exploitation sont séparées dans un véritable apprentissage par renforcement sans politique. model . Par conséquent, la stratégie cible n'affecte pas les trajectoires d'entraînement. Ce paramètre est particulièrement adapté lors de la conception d'un cadre d'attaque par inférence de membres dans un environnement de boîte noire, car l'attaquant ne connaît ni la structure interne du modèle cible ni la méthode utilisée pour le faire. collecter les trajectoires d'entraînement. Stratégie d'exploration. » Dans une attaque d'inférence d'appartenance à une boîte noire, l'attaquant ne peut observer que le comportement du modèle d'apprentissage par renforcement formé. Dans ce cas particulier, l’attaquant suppose que le modèle cible a été formé sur des trajectoires générées à partir d’un ensemble de données privées, ce qui correspond à la manière dont fonctionne l’apprentissage par renforcement sans politique. Dans l'étude, les chercheurs ont choisi le « Batch Constrained Deep Q Learning » (BCQ), un algorithme avancé d'apprentissage par renforcement sans politique qui montre d'excellentes performances dans les tâches de contrôle. Cependant, ils montrent que leur technique d’attaque par inférence d’appartenance peut être étendue à d’autres modèles d’apprentissage par renforcement non liés aux politiques. Une façon pour les attaquants de mener des attaques par inférence d'appartenance est de développer des « modèles fantômes ». Il s'agit d'un modèle d'apprentissage automatique de classificateur qui a été formé sur un mélange de données provenant de la même distribution que les données de formation du modèle cible et ailleurs. Après la formation, le modèle fantôme peut faire la distinction entre les points de données qui appartiennent à l'ensemble de formation du modèle d'apprentissage automatique cible et les nouvelles données que le modèle n'a pas vues auparavant. La création de modèles fantômes pour les agents d’apprentissage par renforcement est délicate en raison de la nature séquentielle de la formation du modèle cible. Les chercheurs y sont parvenus en plusieurs étapes. Tout d'abord, ils alimentent l'entraîneur du modèle d'apprentissage par renforcement avec un nouvel ensemble de trajectoires de données non privées et observent les trajectoires générées par le modèle cible. L'entraîneur d'attaque utilise ensuite les trajectoires d'entraînement et de sortie pour entraîner un classificateur d'apprentissage automatique afin de détecter les trajectoires d'entrée utilisées dans l'entraînement du modèle d'apprentissage par renforcement cible. Enfin, le classificateur reçoit de nouvelles trajectoires à classer comme membres en formation ou de nouveaux exemples de données. Formation de modèles fantômes pour les attaques d'inférence d'adhésion contre des modèles d'apprentissage par renforcement Les chercheurs ont testé leurs attaques d'inférence d'adhésion dans différents modes, y compris différentes longueurs de trajectoire, simple versus trajectoires multiples et trajectoires corrélées ou décorrélées. Les chercheurs ont déclaré dans leur article : « Les résultats montrent que le cadre d'attaque que nous proposons est très efficace pour déduire les points de données de formation du modèle d'apprentissage par renforcement... Les résultats obtenus démontrent qu'il existe une forte probabilité d'utiliser l'apprentissage par renforcement profond. Risque pour la vie privée. » Leurs résultats montrent que les attaques à trajectoires multiples sont plus efficaces que les attaques à trajectoire unique, et que la précision de l’attaque augmente à mesure que les trajectoires deviennent plus longues et corrélées. Les auteurs déclarent : « Le cadre naturel est bien sûr celui des modèles individuels, dans lesquels l'attaquant souhaite identifier la présence d'un individu spécifique dans l'ensemble de formation utilisé pour entraîner la politique d'apprentissage par renforcement cible (définissant la trajectoire entière en renforcement). apprentissage). Cependant, les attaques par inférence d'appartenance (MIA) en mode collectif montrent qu'en plus de la corrélation temporelle capturée par les caractéristiques de la politique de formation, l'attaquant peut également exploiter la corrélation croisée entre les trajectoires de formation de la politique cible » Cela signifie également que les attaquants ont besoin d'architectures d'apprentissage plus complexes et d'un réglage des hyperparamètres plus sophistiqué pour exploiter les corrélations croisées entre les trajectoires d'entraînement et les corrélations temporelles au sein des trajectoires, ont déclaré les chercheurs. Les chercheurs ont déclaré : « Comprendre ces différents modes d'attaque peut nous permettre de mieux comprendre l'impact sur la sécurité et la confidentialité des données, car cela nous permet de mieux comprendre les différents angles sous lesquels les attaques peuvent se produire et l'impact sur la confidentialité. violations. L'étendue de l'impact. » Les chercheurs ont testé leur attaque sur un modèle d'apprentissage par renforcement formé sur trois tâches basées sur la physique Open AIGym et MuJoCo. moteurs. Les chercheurs ont déclaré : « Nos expériences actuelles couvrent trois tâches de mouvement de haute dimension, Hopper, Half-Cheetah et Ant. Ces tâches sont toutes des tâches de simulation de robot et favorisent principalement l'extension des expériences aux tâches d'apprentissage des robots du monde réel. ” Une autre direction intéressante permettant aux membres de l'application de déduire des attaques est celle des systèmes conversationnels tels qu'Amazon Alexa, Apple Siri et Google Assistant, ont déclaré les chercheurs du journal. Dans ces applications, les points de données sont présentés par la trace complète de l'interaction entre le chatbot et l'utilisateur final. Dans ce contexte, le chatbot est une politique d'apprentissage par renforcement formé, et les interactions de l'utilisateur avec le robot forment la trajectoire d'entrée. Les auteurs déclarent : « Dans ce cas, le modèle collectif est l'environnement naturel. En d'autres termes, l'attaquant peut déduire que l'utilisateur se trouve dans » L'équipe explore d'autres applications pratiques où ce type de. une attaque pourrait affecter les systèmes d’apprentissage par renforcement. Ils pourront également étudier comment ces attaques peuvent être appliquées à l’apprentissage par renforcement dans d’autres contextes. Les auteurs déclarent : « Une extension intéressante de ce domaine de recherche consiste à étudier les attaques par inférence de membres contre des modèles d'apprentissage par renforcement profond dans un environnement de boîte blanche, où la structure interne de la politique cible est également connue de l'attaquant. » Les chercheurs espèrent que leur étude fera la lumière sur les problèmes de sécurité et de confidentialité dans les applications d'apprentissage par renforcement du monde réel et sensibilisera la communauté de l'apprentissage automatique afin que davantage de recherches puissent être menées dans ce domaine. Titre original : Les modèles d'apprentissage par renforcement sont sujets aux attaques par inférence d'adhésion, auteur : Ben DicksonConcevoir des attaques d'inférence d'adhésion contre les systèmes d'apprentissage par renforcement
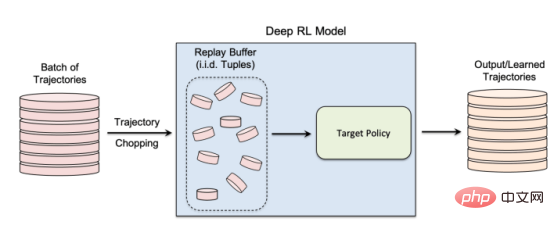
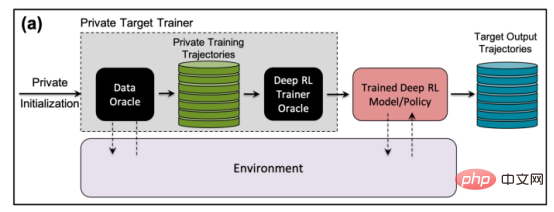
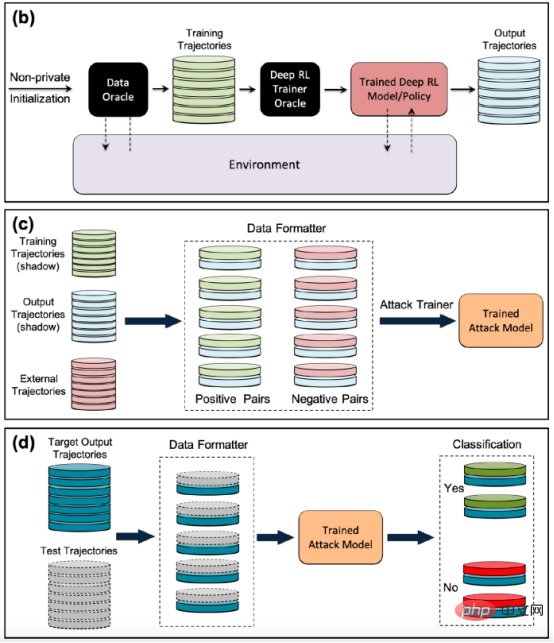
Test des attaques d'inférence d'adhésion contre des systèmes d'apprentissage par renforcement
Attaques d'inférence d'adhésion du monde réel sur les systèmes d'apprentissage par renforcement
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
 Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
01Aperçu des perspectives Actuellement, il est difficile d'atteindre un équilibre approprié entre efficacité de détection et résultats de détection. Nous avons développé un algorithme YOLOv5 amélioré pour la détection de cibles dans des images de télédétection optique haute résolution, en utilisant des pyramides de caractéristiques multicouches, des stratégies de têtes de détection multiples et des modules d'attention hybrides pour améliorer l'effet du réseau de détection de cibles dans les images de télédétection optique. Selon l'ensemble de données SIMD, le mAP du nouvel algorithme est 2,2 % meilleur que YOLOv5 et 8,48 % meilleur que YOLOX, permettant ainsi d'obtenir un meilleur équilibre entre les résultats de détection et la vitesse. 02 Contexte et motivation Avec le développement rapide de la technologie de télédétection, les images de télédétection optique à haute résolution ont été utilisées pour décrire de nombreux objets à la surface de la Terre, notamment des avions, des voitures, des bâtiments, etc. Détection d'objets dans l'interprétation d'images de télédétection
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Apprentissage automatique en C++ : un guide pour la mise en œuvre d'algorithmes d'apprentissage automatique courants en C++
Jun 03, 2024 pm 07:33 PM
Apprentissage automatique en C++ : un guide pour la mise en œuvre d'algorithmes d'apprentissage automatique courants en C++
Jun 03, 2024 pm 07:33 PM
En C++, la mise en œuvre d'algorithmes d'apprentissage automatique comprend : Régression linéaire : utilisée pour prédire des variables continues. Les étapes comprennent le chargement des données, le calcul des poids et des biais, la mise à jour des paramètres et la prédiction. Régression logistique : utilisée pour prédire des variables discrètes. Le processus est similaire à la régression linéaire, mais utilise la fonction sigmoïde pour la prédiction. Machine à vecteurs de support : un puissant algorithme de classification et de régression qui implique le calcul de vecteurs de support et la prédiction d'étiquettes.
 Comment la conception de l'architecture de sécurité du framework Java doit-elle être équilibrée avec les besoins de l'entreprise ?
Jun 04, 2024 pm 02:53 PM
Comment la conception de l'architecture de sécurité du framework Java doit-elle être équilibrée avec les besoins de l'entreprise ?
Jun 04, 2024 pm 02:53 PM
La conception du framework Java assure la sécurité en équilibrant les besoins de sécurité avec les besoins de l'entreprise : en identifiant les principaux besoins de l'entreprise et en hiérarchisant les exigences de sécurité pertinentes. Développez des stratégies de sécurité flexibles, répondez aux menaces par niveaux et effectuez des ajustements réguliers. Tenez compte de la flexibilité architecturale, prenez en charge l’évolution de l’entreprise et des fonctions de sécurité abstraites. Donnez la priorité à l’efficacité et à la disponibilité, optimisez les mesures de sécurité et améliorez la visibilité.
 L'algorithme CVM révolutionnaire résout plus de 40 ans de problèmes de comptage ! Un informaticien lance une pièce de monnaie pour trouver le mot unique pour « Hamlet »
Jun 07, 2024 pm 03:44 PM
L'algorithme CVM révolutionnaire résout plus de 40 ans de problèmes de comptage ! Un informaticien lance une pièce de monnaie pour trouver le mot unique pour « Hamlet »
Jun 07, 2024 pm 03:44 PM
Compter semble simple, mais en pratique, c'est très difficile. Imaginez que vous êtes transporté dans une forêt tropicale vierge pour effectuer un recensement de la faune. Chaque fois que vous voyez un animal, prenez une photo. Les appareils photo numériques enregistrent uniquement le nombre total d'animaux suivis, mais vous êtes intéressé par le nombre d'animaux uniques, mais il n'y a pas de statistiques. Alors, quelle est la meilleure façon d’accéder à cette population animale unique ? À ce stade, vous devez dire : commencez à compter maintenant et comparez enfin chaque nouvelle espèce de la photo à la liste. Cependant, cette méthode de comptage courante n'est parfois pas adaptée aux informations pouvant atteindre des milliards d'entrées. Des informaticiens de l'Institut indien de statistique, UNL, et de l'Université nationale de Singapour ont proposé un nouvel algorithme : le CVM. Il peut approximer le calcul de différents éléments dans une longue liste.
 Quel framework Golang est le meilleur pour les applications d'apprentissage automatique ?
Jun 04, 2024 pm 03:59 PM
Quel framework Golang est le meilleur pour les applications d'apprentissage automatique ?
Jun 04, 2024 pm 03:59 PM
Dans les applications de machine learning, le framework GoLang le plus adapté dépend des exigences de l'application : TensorFlowLite : inférence de modèle légère, adaptée aux appareils mobiles. Keras : des modèles de réseaux neuronaux conviviaux et faciles à créer et à former. PyTorch : flexible, prend en charge des modèles personnalisés et des temps de formation rapides. MXNet : évolutif et adapté au traitement de grands ensembles de données. XGBoost : rapide, évolutif et adapté aux tâches de classification de données structurées.
