
 Périphériques technologiques
IA
Wayformer : Un réseau d'attention simple et efficace pour la prédiction de mouvement
Périphériques technologiques
IA
Wayformer : Un réseau d'attention simple et efficace pour la prédiction de mouvement
Wayformer : Un réseau d'attention simple et efficace pour la prédiction de mouvement

L'article arXiv « Wayformer : Motion Forecasting via Simple & Efficient Attention Networks », mis en ligne en juillet 2022, est l'œuvre de Google Waymo.

La prédiction de mouvement pour la conduite autonome est une tâche difficile car des scénarios de conduite complexes entraînent diverses formes mixtes d'entrées statiques et dynamiques. La meilleure façon de représenter et de fusionner les informations historiques sur la géométrie des routes, la connectivité des voies, les états des feux de circulation variables dans le temps et les ensembles dynamiques d'agents et leurs interactions dans des codages efficaces est un problème non résolu. Pour modéliser cet ensemble diversifié de fonctionnalités d’entrée, il existe de nombreuses approches pour concevoir des systèmes tout aussi complexes avec différents ensembles de modules spécifiques aux modalités. Il en résulte des systèmes difficiles à mettre à l’échelle, à faire évoluer ou à faire des compromis entre qualité et efficacité de manière rigoureuse.
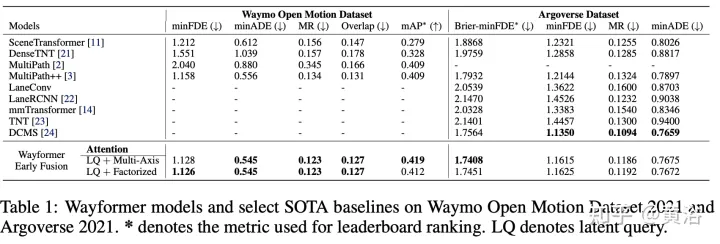
Le Wayformer présenté dans cet article est une série d'architectures de prédiction de mouvement simples et similaires basées sur l'attention. Wayformer fournit une description de modèle compacte composée d'encodeurs et de décodeurs de scène basés sur l'attention. Dans l'encodeur de scène, la sélection de pré-fusion, post-fusion et fusion hiérarchique des modes d'entrée est étudiée. Pour chaque type de fusion, explorez des stratégies qui compromis entre efficacité et qualité grâce à l’attention à la décomposition ou à l’attention latente aux requêtes. La structure de pré-fusion est simple et non seulement indépendante du mode, mais permet également d'obtenir des résultats de pointe sur l'ensemble de données Waymo Open Movement Dataset (WOMD) et le classement Argoverse.
Les scènes de conduite sont composées de données multimodales, telles que les informations routières, l'état des feux de circulation, l'historique des agents et les interactions. Pour la modalité, il existe une 4ème dimension Contexte, qui représente « l'ensemble des objectifs contextuels » pour chaque agent modélisé (c'est-à-dire une représentation des autres usagers de la route).
L'histoire de l'intellect contient une série d'états intellectuels passés ainsi que l'état actuel. Pour chaque pas de temps, considérez les caractéristiques qui définissent l'état de l'agent, telles que x, y, la vitesse, l'accélération, le cadre de délimitation, etc., ainsi qu'une dimension de contexte.
Tenseur d'interaction représente la relation entre les agents. Pour chaque agent modélisé, un nombre fixe de contextes voisins les plus proches entourant l'agent modélisé sont pris en compte. Ces agents contextuels représentent des agents qui influencent le comportement de l'agent modélisé.
Feuille routière contient des éléments routiers autour de l'agent. Les segments de la carte routière sont représentés sous forme de polylignes, un ensemble de segments spécifiés par leurs extrémités et annotés avec des informations de type qui se rapprochent de la forme de la route. Utilisez le segment de feuille de route le plus proche de l'agent de modélisation. Veuillez noter que les entités routières n'ont pas de dimension temporelle et que la dimension temporelle 1 peut être ajoutée.
Pour chaque agent, Informations sur les feux tricolores contient l'état des feux de circulation les plus proches de l'agent. Chaque point de feu de circulation possède des caractéristiques qui décrivent l'emplacement et la fiabilité du signal.
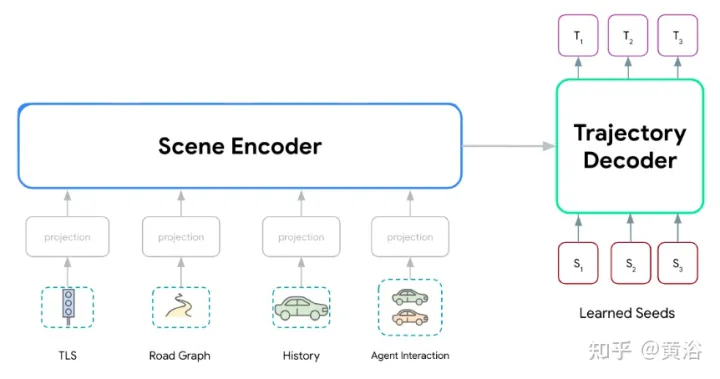
Série de modèles Wayformer, composée de deux composants principaux : un encodeur de scène et un décodeur. L'encodeur de scène se compose principalement d'un ou plusieurs encodeurs d'attention, qui sont utilisés pour résumer la scène de conduite. Le décodeur est constitué d'un ou de plusieurs modules d'attention croisée de transformateur standard, qui saisissent la requête initiale apprise, puis génèrent des trajectoires avec une attention croisée de codage de scène.
Comme le montre la figure, le modèle Wayformer traite l'entrée multimodale pour produire un encodage de scène : cet encodage de scène est utilisé comme contexte du décodeur, générant k trajectoires possibles couvrant plusieurs modalités dans l'espace de sortie.
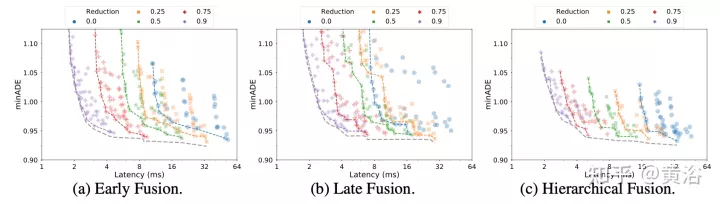
La diversité des entrées de l'encodeur de scène fait de cette intégration une tâche non triviale. Les modalités peuvent ne pas être représentées au même niveau d'abstraction ou à la même échelle : {pixels vs objets cibles}. Par conséquent, certaines modalités peuvent nécessiter plus de calculs que d’autres. La décomposition informatique entre les modes dépend de l'application et est très importante pour les ingénieurs. Trois niveaux de fusion sont proposés ici pour simplifier ce processus : {Post, Pre, Grade}, comme le montre la figure :
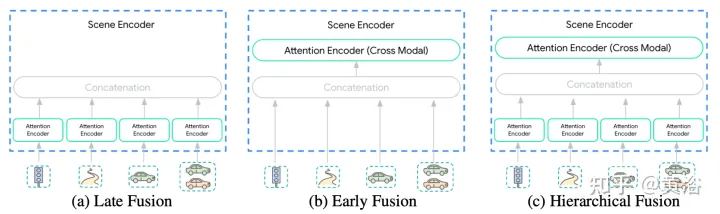
Post fusion est la méthode la plus couramment utilisée pour les modèles de prédiction de mouvement, où chaque modalité a sa propre encodeur dédié. Définir la largeur de ces encodeurs pour qu'elle soit égale évite d'introduire des couches de projection supplémentaires dans la sortie. De plus, en partageant la même profondeur sur tous les encodeurs, l’espace d’exploration est réduit à une taille gérable. Les informations ne peuvent être transférées qu'à travers les modalités de la couche d'attention croisée du décodeur de trajectoire.
Pré-fusionAu lieu de dédier un encodeur d'auto-attention à chaque modalité, les paramètres de la modalité spécifique sont réduits à la couche de projection. L'encodeur de scène sur la figure se compose d'un seul encodeur d'auto-attention (« l'encodeur multimodal »), permettant au réseau d'avoir une flexibilité maximale dans l'attribution d'importance entre les modalités tout en ayant un biais inductif minimal.
Fusion hiérarchiqueComme compromis entre les deux premiers extrêmes, le volume est décomposé de manière hiérarchique entre des encodeurs d'auto-attention spécifiques à une modalité et des encodeurs intermodaux. Comme cela se fait en post-fusion, la largeur et la profondeur sont partagées dans l'encodeur attentionnel et l'encodeur multimodal. Cela divise efficacement la profondeur de l'encodeur de scène entre les encodeurs spécifiques à une modalité et les encodeurs multimodaux.
Les réseaux de transformateurs ne s'adaptent pas bien aux grandes séquences multidimensionnelles en raison des deux facteurs suivants :
- (a) L'attention personnelle est quadratique par rapport à la longueur de la séquence d'entrée.
- (b) Les réseaux à réaction positionnelle sont des sous-réseaux coûteux.
La méthode d'accélération est discutée ci-dessous (S est la dimension spatiale, T est la dimension du domaine temporel), et son cadre est comme le montre la figure :
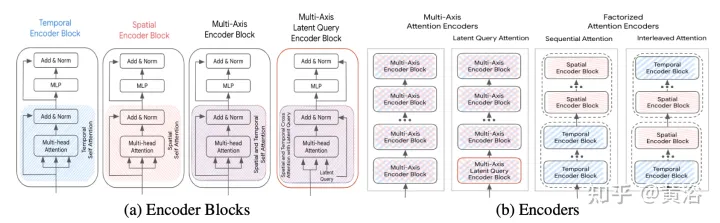
Attention multi-axes : Cela fait référence à le paramètre par défaut Le paramètre du transformateur, qui applique l'auto-attention dans les dimensions spatiales et temporelles, devrait être le plus coûteux en termes de calcul. La complexité informatique de la fusion antérieure, postérieure et hiérarchique avec attention multi-axes est O(Sm2×T2).
Attention factorisée : La complexité informatique de l'auto-attention est le quadratique de la longueur de la séquence d'entrée. Cela devient encore plus évident dans les séquences multidimensionnelles, car chaque dimension supplémentaire augmente la taille de l'entrée d'un facteur multiplicatif. Par exemple, certaines modalités d’entrée ont des dimensions temporelles et spatiales, donc le coût de calcul évolue en O(Sm2×T2). Pour atténuer cette situation, envisagez de décomposer l’attention selon deux dimensions. Cette méthode exploite la structure multidimensionnelle de la séquence d'entrée et réduit le coût du sous-réseau d'auto-attention de O(S2×T2) à O(S2)+O(T2) en appliquant l'auto-attention dans chaque dimension individuellement.
Bien que l'attention décomposée ait le potentiel de réduire l'effort de calcul par rapport à l'attention multi-axes, la complexité est introduite lors de l'application de l'attention personnelle à l'ordre de chaque dimension. Nous comparons ici deux paradigmes d'attention décomposés :
- Attention séquentielle : un encodeur à N couches se compose de N/2 blocs d'encodeur temporel et d'un autre bloc d'encodeur spatial N/2.
- Attention entrelacée : L'encodeur à couche N se compose de blocs d'encodeurs temporels et spatiaux alternant N/2 fois.
Attention aux requêtes latentes : Une autre façon de gérer le coût de calcul des grandes séquences d'entrée consiste à utiliser des requêtes latentes dans le premier bloc d'encodeur, où l'entrée est mappée sur l'espace latent. Ces variables latentes sont ensuite traitées par une série de blocs d'encodeur qui reçoivent et renvoient l'espace latent. Cela permet une liberté totale dans la définition de la résolution de l’espace latent, réduisant ainsi le coût de calcul du composant d’auto-attention et du réseau de rétroaction positionnelle dans chaque bloc. Définissez le montant de la réduction (R=Lout/Lin) en pourcentage de la longueur de la séquence d'entrée. En post-fusion et en fusion hiérarchique, le facteur de réduction R reste inchangé pour tous les codeurs d'attention.
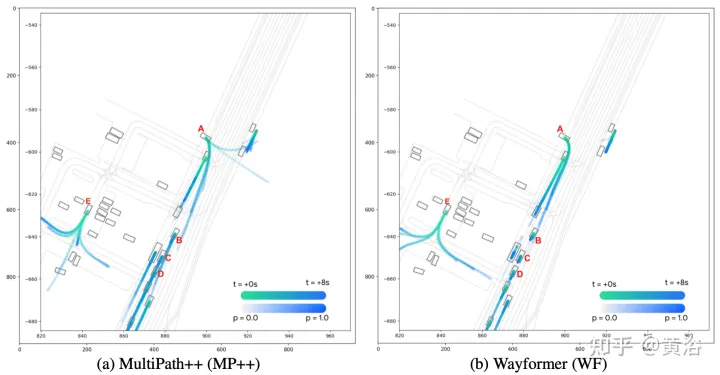
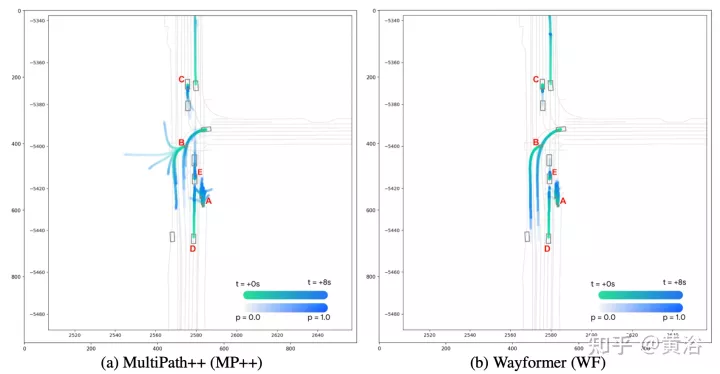
Le prédicteur Wayformer génère un mélange gaussien, représentant la trajectoire que l'agent peut emprunter. Pour générer des prédictions, un décodeur Transformer est utilisé, qui entre un ensemble de k requêtes initiales apprises (Si) et effectue une attention croisée avec les intégrations de scène du codeur pour générer des intégrations pour chaque composant du mélange gaussien. Étant donné l'intégration d'un composant spécifique dans un mélange, une couche de projection linéaire produit une log-vraisemblance non canonique de ce composant, estimant la vraisemblance totale du mélange. Pour générer des trajectoires, une autre projection de couche linéaire est utilisée, produisant 4 séries temporelles correspondant à la moyenne et à l'écart type logarithmique de la gaussienne prédite à chaque pas de temps. Lors de l'entraînement, la perte est décomposée en pertes respectives de classification et de régression. En supposant k gaussiennes prédites, la vraisemblance du mélange est entraînée pour maximiser la probabilité logarithmique de la vraie trajectoire. Si le prédicteur produit un mélange de gaussiennes avec plusieurs modes, il est difficile de raisonner, et les mesures de référence limitent souvent le nombre de trajectoires considérées. Par conséquent, au cours du processus d’évaluation, l’agrégation des trajectoires est appliquée, réduisant ainsi le nombre de modes considérés tout en conservant la diversité du mélange de sorties d’origine. Les résultats expérimentaux sont les suivants :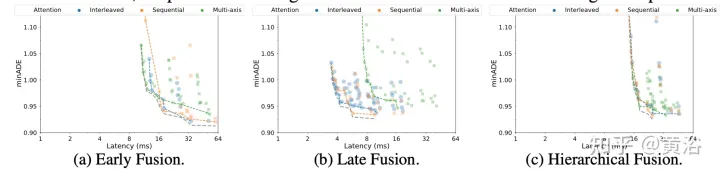
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
