
 Périphériques technologiques
IA
Construire des générateurs de texte à l'aide de chaînes de Markov
Périphériques technologiques
IA
Construire des générateurs de texte à l'aide de chaînes de Markov
Construire des générateurs de texte à l'aide de chaînes de Markov

Dans cet article, nous présenterons un projet d'apprentissage automatique populaire : le générateur de texte. Vous apprendrez à créer un générateur de texte et à implémenter une chaîne de Markov pour obtenir un modèle de prédiction plus rapide.

Introduction aux générateurs de texte
La génération de texte est populaire dans divers secteurs, en particulier dans les domaines mobile, des applications et de la science des données. Même la presse utilise la génération de texte pour faciliter le processus d'écriture.
Dans la vie quotidienne, nous sommes exposés à certaines technologies de génération de texte. La complétion de texte, les suggestions de recherche, Smart Compose et les chatbots sont tous des exemples d'applications
Cet article utilisera la chaîne de Markov pour créer un générateur de texte. Il s'agirait d'un modèle basé sur les caractères qui prendrait le caractère précédent de la chaîne et générerait la lettre suivante de la séquence.
En entraînant notre programme à l'aide d'exemples de mots, le générateur de texte apprendra les modèles courants d'ordre des caractères. Le générateur de texte appliquera ensuite ces modèles à l'entrée, qui est un mot incomplet, et affichera le caractère ayant la plus grande probabilité de compléter le mot.
La génération de texte est une branche du traitement du langage naturel qui prédit et génère le prochain caractère en fonction des modèles de langage observés précédemment.
Avant l'apprentissage automatique, la PNL générait du texte en créant un tableau contenant tous les mots de la langue anglaise et en faisant correspondre la chaîne transmise avec les mots existants. Il y a deux problèmes avec cette approche.
- La recherche de milliers de mots sera très lente.
- Le générateur ne peut compléter que les mots qu'il a vus auparavant.
L'émergence du machine learning et du deep learning, la PNL nous permet de réduire considérablement le temps d'exécution et d'augmenter la généralité, car le générateur peut compléter des mots qu'il n'a jamais rencontrés auparavant. La PNL peut être étendue pour prédire des mots, des expressions ou des phrases si vous le souhaitez !
Pour ce projet, nous le ferons exclusivement en utilisant des chaînes de Markov. Les processus markoviens sont à la base de nombreux projets de traitement du langage naturel impliquant le langage écrit et simulant des échantillons provenant de distributions complexes.
Les processus Markov sont si puissants qu'ils peuvent être utilisés pour générer un texte apparemment réel avec juste un exemple de document.
Qu'est-ce qu'une chaîne de Markov ?
Une chaîne de Markov est un processus stochastique qui modélise une séquence d'événements où la probabilité de chaque événement dépend de l'état de l'événement précédent. Le modèle comporte un ensemble fini d’états et la probabilité conditionnelle de passer d’un état à un autre est fixe.
La probabilité de chaque transition dépend uniquement de l'état précédent du modèle, et non de l'ensemble de l'historique des événements.
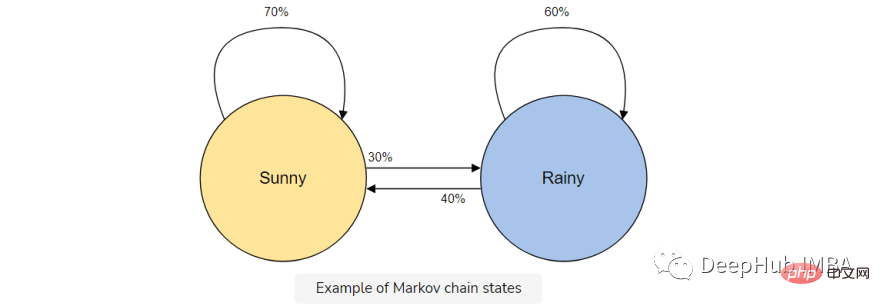
Par exemple, supposons que vous souhaitiez créer un modèle de chaîne de Markov pour prédire la météo.
Dans ce modèle nous avons deux états, ensoleillé ou pluvieux. Si nous avons une période ensoleillée aujourd'hui, il y a une probabilité plus élevée (70 %) qu'il fasse beau demain. Il en va de même pour la pluie ; s’il pleut déjà, il est probable qu’il continue à pleuvoir.
Mais il est possible (30 %) que la météo change d'état, nous l'incluons donc également dans notre modèle de chaîne de Markov.
La chaîne de Markov est le modèle parfait pour notre générateur de texte car notre modèle prédira le caractère suivant en utilisant uniquement le caractère précédent. Les avantages de l’utilisation d’une chaîne de Markov sont qu’elle est précise, qu’elle a peu de mémoire (ne stocke qu’un seul état précédent) et qu’elle est rapide à exécuter.
Mise en œuvre de la génération de texte
Ici, nous allons compléter le générateur de texte en 6 étapes :
- Générer une table de recherche : créer une table pour enregistrer la fréquence des mots
- Convertir les fréquences en probabilités : convertir nos résultats en une forme utilisable
- Charger l'ensemble de données : chargez et utilisez un ensemble d'entraînement
- Construisez une chaîne de Markov : utilisez des probabilités pour créer des chaînes pour chaque mot et caractère
- Échantillonnez les données : créez une fonction pour échantillonner différentes parties du corpus
- Générez du texte : testez notre modèle

1. Générer une table de recherche
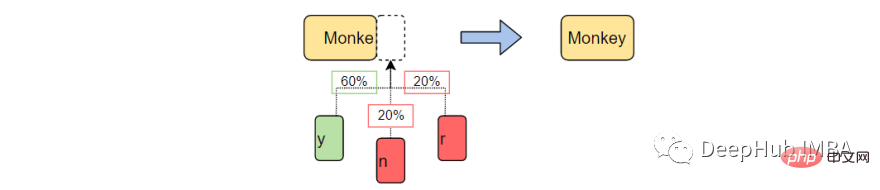
Tout d'abord, nous allons créer une table pour enregistrer l'occurrence de chaque état de caractère dans le corpus de formation. Enregistrez les derniers caractères « K » et « K+1 » du corpus de formation et enregistrez-les dans une table de recherche.
Par exemple, imaginez que notre corpus de formation contienne, "l'homme était, ils, alors, le, le". Ensuite, le nombre d'occurrences du mot est :
- "le" — 3
- "alors" — 1
- "ils" — 1
- "homme" — 1
Voici les résultats de la recherche tableau :

Dans l'exemple ci-dessus, nous prenons K = 3, ce qui signifie que 3 caractères seront considérés à la fois et le caractère suivant (K+1) sera utilisé comme caractère de sortie. Traitez le mot (X) comme un caractère dans la table de recherche ci-dessus et le caractère de sortie (Y) comme un espace simple (" ") puisqu'il n'y a pas de mot après le premier le. Le nombre de fois où cette séquence apparaît dans l'ensemble de données est également calculé, dans ce cas 3 fois.
De cette façon, les données pour chaque mot du corpus sont générées, c'est-à-dire que toutes les paires X et Y possibles sont générées.
Voici comment nous générons la table de recherche dans le code :
def generateTable(data,k=4):
T = {}
for i in range(len(data)-k):
X = data[i:i+k]
Y = data[i+k]
#print("X %s and Y %s "%(X,Y))
if T.get(X) is None:
T[X] = {}
T[X][Y] = 1
else:
if T[X].get(Y) is None:
T[X][Y] = 1
else:
T[X][Y] += 1
return T
T = generateTable("hello hello helli")
print(T)
#{'llo ': {'h': 2}, 'ello': {' ': 2}, 'o he': {'l': 2}, 'lo h': {'e': 2}, 'hell': {'i': 1, 'o': 2}, ' hel': {'l': 2}}Explication simple du code :
Sur la ligne 3, un dictionnaire est créé qui stockera X et ses valeurs Y et de fréquence correspondantes. Les lignes 9 à 17 vérifient les occurrences de X et Y. S'il existe déjà une paire X et Y dans le dictionnaire de recherche, augmentez-la simplement de 1.
2. Convertir la fréquence en probabilité
Une fois que nous avons ce tableau et le nombre d'occurrences, nous pouvons obtenir la probabilité que Y se produise après une occurrence donnée de x. La formule est :
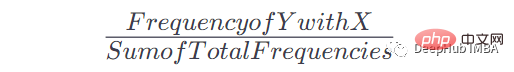
Par exemple, si X = le, Y = n, notre formule est comme ceci :
La fréquence de Y = n quand = 2/8= 0,125= 12,5%
Voici comment nous appliquez cette formule pour convertir la table de recherche en une probabilité utilisable de chaîne de Markov :
def convertFreqIntoProb(T):
for kx in T.keys():
s = float(sum(T[kx].values()))
for k in T[kx].keys():
T[kx][k] = T[kx][k]/s
return T
T = convertFreqIntoProb(T)
print(T)
#{'llo ': {'h': 1.0}, 'ello': {' ': 1.0}, 'o he': {'l': 1.0}, 'lo h': {'e': 1.0}, 'hell': {'i': 0.3333333333333333, 'o': 0.6666666666666666}, ' hel': {'l': 1.0}}Explication simple :
Résumez les valeurs de fréquence d'une clé particulière, puis divisez chaque valeur de fréquence pour cette clé par cette valeur ajoutée pour obtenir le probabilité.
3. Chargez l'ensemble de données
Le véritable corpus de formation sera ensuite chargé. Vous pouvez utiliser n’importe quel document texte long (.txt) de votre choix.
Pour simplifier, un discours politique sera utilisé pour fournir suffisamment de vocabulaire pour enseigner notre modèle.
text_path = "train_corpus.txt"
def load_text(filename):
with open(filename,encoding='utf8') as f:
return f.read().lower()
text = load_text(text_path)
print('Loaded the dataset.')Cet ensemble de données peut fournir suffisamment d'événements pour que notre exemple de projet puisse faire des prédictions raisonnablement précises. Comme pour tout apprentissage automatique, un corpus de formation plus vaste produira des prédictions plus précises.
4. Construisons une chaîne de Markov
Construisons une chaîne de Markov et associons la probabilité à chaque caractère. Les fonctions generateTable() et convertFreqIntoProb() créées aux étapes 1 et 2 seront utilisées ici pour construire le modèle de Markov.
def MarkovChain(text,k=4): T = generateTable(text,k) T = convertFreqIntoProb(T) return T model = MarkovChain(text)
Ligne 1, crée une méthode pour générer un modèle de Markov. La méthode accepte un corpus de texte et une valeur K, qui est la valeur qui indique au modèle de Markov de considérer K caractères et de prédire le caractère suivant. Ligne 2, la table de recherche est générée en fournissant le corpus de texte et K à la méthode generateTable(), que nous avons créée dans la section précédente. La ligne 3 convertit la fréquence en valeur de probabilité à l'aide de la méthode convertFreqIntoProb(), que nous avons également créée dans la leçon précédente.
5. Échantillonnage de texte
Créez une fonction d'échantillonnage qui utilise le mot inachevé (ctx), le modèle de chaîne de Markov (modèle) de l'étape 4 et le nombre de caractères utilisés pour former la base du mot (k).
Nous utiliserons cette fonction pour échantillonner le contexte transmis, renvoyer le prochain caractère possible et déterminer la probabilité qu'il s'agisse du bon caractère.
import numpy as np
def sample_next(ctx,model,k):
ctx = ctx[-k:]
if model.get(ctx) is None:
return " "
possible_Chars = list(model[ctx].keys())
possible_values = list(model[ctx].values())
print(possible_Chars)
print(possible_values)
return np.random.choice(possible_Chars,p=possible_values)
sample_next("commo",model,4)
#['n']
#[1.0]Explication du code :
La fonction sample_next accepte trois paramètres : ctx, modèle et valeur k.
ctx est un texte utilisé pour générer un nouveau texte. Mais ici seuls les K derniers caractères de ctx seront utilisés par le modèle pour prédire le prochain caractère de la séquence. Par exemple, nous passons commun, K = 4, et le texte que le modèle utilise pour générer le caractère suivant est ommo, car le modèle de Markov n'utilise que l'historique précédent.
Dans les lignes 9 et 10, les caractères possibles et leurs valeurs de probabilité sont imprimés, puisque ces caractères sont également présents dans notre modèle. Nous obtenons que le prochain caractère prédit soit n, avec une probabilité de 1,0. Parce que le mot commo est plus susceptible d'être plus courant après avoir généré le caractère suivant
À la ligne 12, nous renvoyons un caractère basé sur la valeur de probabilité discutée ci-dessus.
6. Générer du texte
Enfin, combinez toutes les fonctions ci-dessus pour générer du texte.
def generateText(starting_sent,k=4,maxLen=1000):
sentence = starting_sent
ctx = starting_sent[-k:]
for ix in range(maxLen):
next_prediction = sample_next(ctx,model,k)
sentence += next_prediction
ctx = sentence[-k:]
return sentence
print("Function Created Successfully!")
text = generateText("dear",k=4,maxLen=2000)
print(text)Les résultats sont les suivants :
dear country brought new consciousness. i heartily great service of their lives, our country, many of tricoloring a color flag on their lives independence today.my devoted to be oppression of independence.these day the obc common many country, millions of oppression of massacrifice of indian whom everest. my dear country is not in the sevents went was demanding and nights by plowing in the message of the country is crossed, oppressed, women, to overcrowding for years of the south, it is like the ashok chakra of constitutional states crossed, deprived, oppressions of freedom, i bow my heart to proud of our country.my dear country, millions under to be a hundred years of the south, it is going their heroes.
La fonction ci-dessus accepte trois paramètres : le mot de départ du texte généré, la valeur de K et la longueur maximale de caractères du texte requis. L'exécution du code entraînera un texte de 2 000 caractères commençant par "cher".
Bien que ce discours n'ait pas beaucoup de sens, les mots sont complets et imitent souvent des modèles de mots familiers.
Ce qu'il faut apprendre ensuite
Il s'agit d'un simple projet de génération de texte. Utilisez ce projet pour découvrir comment le traitement du langage naturel et les chaînes de Markov fonctionnent en action, que vous pourrez utiliser tout en poursuivant votre parcours d'apprentissage en profondeur.
Cet article vise simplement à présenter le projet expérimental de chaîne de Markov, car il ne jouera aucun rôle dans l'application réelle. Si vous souhaitez obtenir un meilleur effet de génération de texte, veuillez apprendre des outils comme GPT-3.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Dans les domaines de l’apprentissage automatique et de la science des données, l’interprétabilité des modèles a toujours été au centre des préoccupations des chercheurs et des praticiens. Avec l'application généralisée de modèles complexes tels que l'apprentissage profond et les méthodes d'ensemble, la compréhension du processus décisionnel du modèle est devenue particulièrement importante. Explainable AI|XAI contribue à renforcer la confiance dans les modèles d'apprentissage automatique en augmentant la transparence du modèle. L'amélioration de la transparence des modèles peut être obtenue grâce à des méthodes telles que l'utilisation généralisée de plusieurs modèles complexes, ainsi que les processus décisionnels utilisés pour expliquer les modèles. Ces méthodes incluent l'analyse de l'importance des caractéristiques, l'estimation de l'intervalle de prédiction du modèle, les algorithmes d'interprétabilité locale, etc. L'analyse de l'importance des fonctionnalités peut expliquer le processus de prise de décision du modèle en évaluant le degré d'influence du modèle sur les fonctionnalités d'entrée. Estimation de l’intervalle de prédiction du modèle
 Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Cet article présentera comment identifier efficacement le surajustement et le sous-apprentissage dans les modèles d'apprentissage automatique grâce à des courbes d'apprentissage. Sous-ajustement et surajustement 1. Surajustement Si un modèle est surentraîné sur les données de sorte qu'il en tire du bruit, alors on dit que le modèle est en surajustement. Un modèle surajusté apprend chaque exemple si parfaitement qu'il classera mal un exemple inédit/inédit. Pour un modèle surajusté, nous obtiendrons un score d'ensemble d'entraînement parfait/presque parfait et un score d'ensemble/test de validation épouvantable. Légèrement modifié : "Cause du surajustement : utilisez un modèle complexe pour résoudre un problème simple et extraire le bruit des données. Parce qu'un petit ensemble de données en tant qu'ensemble d'entraînement peut ne pas représenter la représentation correcte de toutes les données."
 Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
En termes simples, un modèle d’apprentissage automatique est une fonction mathématique qui mappe les données d’entrée à une sortie prédite. Plus précisément, un modèle d'apprentissage automatique est une fonction mathématique qui ajuste les paramètres du modèle en apprenant à partir des données d'entraînement afin de minimiser l'erreur entre la sortie prédite et la véritable étiquette. Il existe de nombreux modèles dans l'apprentissage automatique, tels que les modèles de régression logistique, les modèles d'arbre de décision, les modèles de machines à vecteurs de support, etc. Chaque modèle a ses types de données et ses types de problèmes applicables. Dans le même temps, il existe de nombreux points communs entre les différents modèles, ou il existe une voie cachée pour l’évolution du modèle. En prenant comme exemple le perceptron connexionniste, en augmentant le nombre de couches cachées du perceptron, nous pouvons le transformer en un réseau neuronal profond. Si une fonction noyau est ajoutée au perceptron, elle peut être convertie en SVM. celui-ci
 L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
Dans les années 1950, l’intelligence artificielle (IA) est née. C’est à ce moment-là que les chercheurs ont découvert que les machines pouvaient effectuer des tâches similaires à celles des humains, comme penser. Plus tard, dans les années 1960, le Département américain de la Défense a financé l’intelligence artificielle et créé des laboratoires pour poursuivre son développement. Les chercheurs trouvent des applications à l’intelligence artificielle dans de nombreux domaines, comme l’exploration spatiale et la survie dans des environnements extrêmes. L'exploration spatiale est l'étude de l'univers, qui couvre l'ensemble de l'univers au-delà de la terre. L’espace est classé comme environnement extrême car ses conditions sont différentes de celles de la Terre. Pour survivre dans l’espace, de nombreux facteurs doivent être pris en compte et des précautions doivent être prises. Les scientifiques et les chercheurs pensent qu'explorer l'espace et comprendre l'état actuel de tout peut aider à comprendre le fonctionnement de l'univers et à se préparer à d'éventuelles crises environnementales.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
 Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
MetaFAIR s'est associé à Harvard pour fournir un nouveau cadre de recherche permettant d'optimiser le biais de données généré lors de l'apprentissage automatique à grande échelle. On sait que la formation de grands modèles de langage prend souvent des mois et utilise des centaines, voire des milliers de GPU. En prenant comme exemple le modèle LLaMA270B, sa formation nécessite un total de 1 720 320 heures GPU. La formation de grands modèles présente des défis systémiques uniques en raison de l’ampleur et de la complexité de ces charges de travail. Récemment, de nombreuses institutions ont signalé une instabilité dans le processus de formation lors de la formation des modèles d'IA générative SOTA. Elles apparaissent généralement sous la forme de pics de pertes. Par exemple, le modèle PaLM de Google a connu jusqu'à 20 pics de pertes au cours du processus de formation. Le biais numérique est à l'origine de cette imprécision de la formation,
