
 Périphériques technologiques
IA
Sortie du Top 10 des modèles d'apprentissage auto-supervisés 2022 ! Huit réalisations des États-Unis et de la Chine dominent la liste
Périphériques technologiques
IA
Sortie du Top 10 des modèles d'apprentissage auto-supervisés 2022 ! Huit réalisations des États-Unis et de la Chine dominent la liste
Sortie du Top 10 des modèles d'apprentissage auto-supervisés 2022 ! Huit réalisations des États-Unis et de la Chine dominent la liste

L'apprentissage auto-supervisé permet aux ordinateurs d'observer le monde et de le comprendre en apprenant la structure des images, de la parole ou du texte. Cela a été à l’origine de nombreuses avancées majeures récentes en matière d’intelligence artificielle.
Alors que les chercheurs scientifiques du monde entier investissent beaucoup d’efforts dans ce domaine, il existe actuellement de grandes différences dans la manière dont les algorithmes d’apprentissage auto-supervisé apprennent à partir d’images, de paroles, de textes et d’autres modalités. Par conséquent, le forum d'intelligence artificielle Analytics India Magazine lance les dix meilleurs modèles d'apprentissage auto-supervisé en 2022 pour les lecteurs.
Data2vec

Lien papier : https://arxiv.org/pdf/2202.03555.pdf
Code source ouvert : https://t.co/3x8VCwGI2x pic.twitter.com/Q9TNDg1paj
Meta AI a publié l'algorithme data2vec en janvier pour les modèles de vision par ordinateur liés à la parole, à l'image et au texte. Selon l'équipe IA, le modèle est très compétitif dans les tâches de PNL.
Il n'utilise pas d'apprentissage contrastif ou de reconstruction qui repose sur des exemples d'entrée. L'équipe Meta AI a déclaré que la méthode de formation de data2vec consiste à représenter le modèle prédictif en fournissant une vue partielle des données d'entrée.
L'équipe a déclaré : "Nous codons d'abord les échantillons de formation masqués dans le modèle d'étudiant. Après cela, dans le même modèle, nous codons les échantillons d'entrée non masqués pour construire la cible de formation. Ce modèle (modèle d'enseignant) et l'étudiant Les modèles ne diffèrent que par les paramètres. "

Le modèle prédit la représentation du modèle des échantillons d'entraînement non masqués en fonction des échantillons d'entraînement masqués. Cela élimine la dépendance à l’égard d’objectifs spécifiques à une modalité dans la tâche d’apprentissage.
ConvNext

Lien papier : https://arxiv.org/pdf/2201.03545.pdf
Code source ouvert : https://t.co/nWx2KFtl7X
ConvN poste également appelé Le modèle ConvNet pour les années 2020 est un modèle publié par l'équipe Meta AI en mars. Il est entièrement basé sur les modules de ConvNet et est donc précis, simple dans sa conception et évolutif.

VICReg

Lien papier : https://t.co/H7crDPHCHV
Code source ouvert : https://t.co/oadSBT61P3
Variance variance covariance Régularisation (VICReg) combine des termes de variance et un mécanisme de décorrélation basé sur la réduction de redondance avec une régularisation de covariance pour éviter l'effondrement du codeur produisant des vecteurs constants ou non informatifs.

VICReg ne nécessite pas de techniques telles que le partage de poids entre branches, la normalisation par lots, la normalisation des caractéristiques, la quantification de sortie, l'arrêt des gradients, les banques de mémoire, etc., et obtient des résultats comparables à l'état de l'art sur plusieurs tâches en aval. De plus, il a été démontré expérimentalement que le terme de régularisation de la variance peut stabiliser l’apprentissage d’autres méthodes et favoriser l’amélioration des performances.
STEGO

Lien papier : https://arxiv.org/abs/2203.08414
Développé par le laboratoire d'informatique et d'intelligence artificielle du MIT en collaboration avec Microsoft et l'Université Cornell Transformateurs auto-supervisés pour l'énergie L'optimisation graphique basée sur STEGO résout l'une des tâches les plus difficiles de la vision par ordinateur : attribuer des étiquettes à chaque pixel d'une image sans supervision humaine.

STEGO a appris la "segmentation sémantique" - en termes simples, en attribuant une étiquette à chaque pixel de l'image.
La segmentation sémantique est une compétence importante pour les systèmes de vision par ordinateur actuels, car les images peuvent être interférées par des objets. Pour rendre les choses plus difficiles, ces objets ne rentrent pas toujours dans la zone de texte. Les algorithmes sont souvent mieux adaptés à des « choses » discrètes comme les personnes et les voitures qu’à des choses difficiles à quantifier comme la végétation, le ciel et la purée de pommes de terre.
Prenons comme exemple la scène de chiens jouant dans le parc. Les systèmes précédents ne pouvaient identifier que les chiens, mais en attribuant une étiquette à chaque pixel de l'image, STEGO peut décomposer l'image en plusieurs composants principaux : chien, ciel. , l'herbe et son propriétaire.

Les machines capables de « voir le monde » sont essentielles à diverses technologies émergentes telles que les voitures autonomes et les modèles prédictifs pour le diagnostic médical. Puisque STEGO peut apprendre sans étiquettes, il peut détecter des objets dans différents domaines, même des objets que les humains ne comprennent pas encore complètement.
CoBERT

Lien papier : https://arxiv.org/pdf/2210.04062.pdf
Pour l'apprentissage auto-supervisé de la représentation vocale, des chercheurs de l'Université chinoise de Hong Kong (Shenzhen) ont proposé Code BERT (CoBERT). Contrairement à d’autres méthodes d’autodistillation, leur modèle prédit des représentations de différentes modalités. Le modèle convertit la parole en une séquence de codes discrets pour l'apprentissage des représentations.

Tout d'abord, l'équipe de recherche a utilisé le modèle de code pré-entraîné HuBERT pour s'entraîner dans un espace discret. Ils ont ensuite affiné le modèle de code en un modèle vocal, dans le but de réaliser un meilleur apprentissage dans toutes les modalités. L'amélioration significative de la tâche ST suggère que les représentations de CoBERT peuvent contenir plus d'informations linguistiques que les travaux précédents.
CoBERT surpasse les performances des meilleurs algorithmes actuels sur les tâches ASR et apporte des améliorations significatives à la tâche SUPERB Speech Translation (ST).
FedX

Lien papier : https://arxiv.org/abs/2207.09158
FedX est un cadre d'apprentissage fédéré non supervisé lancé par Microsoft en coopération avec l'Université Tsinghua et l'Institut avancé des sciences de Corée et Technologie. Grâce à l'extraction de connaissances locales et mondiales et à l'apprentissage comparatif, l'algorithme apprend des représentations impartiales à partir de données locales discrètes et hétérogènes. De plus, il s'agit d'un algorithme adaptable qui peut être utilisé comme module complémentaire à divers algorithmes auto-supervisés existants dans des scénarios d'apprentissage fédéré. L'université d'Hokkaido au Japon a proposé TriBYOL pour l'apprentissage de représentations auto-supervisé en petits lots. Avec ce modèle, les chercheurs n’ont pas besoin de grandes quantités de ressources informatiques pour apprendre de bonnes représentations. Ce modèle a une structure de réseau triplet et combine une perte à trois vues, améliorant ainsi l'efficacité sur plusieurs ensembles de données et surpassant plusieurs algorithmes auto-supervisés. Des chercheurs des Nokia Bell Labs ont collaboré avec le Georgia Institute of Technology et l'Université de Cambridge pour développer ColloSSL. , Il s'agit d'un algorithme collaboratif auto-supervisé pour la reconnaissance de l'activité humaine.
Les ensembles de données de capteurs non étiquetés capturés simultanément par plusieurs appareils peuvent être considérés comme des transformations naturelles les unes des autres, qui génèrent ensuite des signaux pour l'apprentissage des représentations. Cet article propose trois méthodes : sélection de périphérique, échantillonnage contrastif et perte contrastive multi-vues.LoRot

Lien papier : https://arxiv.org/pdf/2207.10023.pdf
L'équipe de recherche de l'Université Sungkyunkwan a proposé une tâche auxiliaire auto-supervisée simple qui prédit trois attributs de rotation localisable (LoRot) pour aider au suivi des objectifs.

Ce modèle présente trois caractéristiques majeures. Tout d’abord, l’équipe de recherche a guidé le modèle pour apprendre des fonctionnalités riches. Deuxièmement, la formation distribuée ne change pas de manière significative pendant la transition d'auto-supervision. Troisièmement, le modèle est léger et polyvalent et présente une grande adaptabilité aux technologies précédentes.

TS2Vec

Lien papier : https://arxiv.org/pdf/2106.10466.pdf
Microsoft et l'Université de Pékin ont proposé un cadre d'apprentissage général TS2Vec pour l'apprentissage de la sémantique arbitraire par représentation du temps série en niveaux. Le modèle effectue un apprentissage contrastif selon une technique hiérarchique dans une vue contextuelle améliorée, fournissant une représentation contextuelle forte pour des horodatages individuels.

Les résultats montrent que le modèle TS2Vec permet d'obtenir des améliorations significatives en termes de performances par rapport à l'apprentissage de représentation de séries chronologiques non supervisé de pointe.
En 2022, il y aura d'énormes innovations dans les deux domaines de l'apprentissage auto-supervisé et de l'apprentissage par renforcement. Bien que les chercheurs débattent de ce qui est le plus important, comme l'a déclaré le gourou de l'apprentissage auto-supervisé Yann LeCun : « L'apprentissage par renforcement est comme la cerise sur le gâteau, l'apprentissage supervisé est la cerise sur le gâteau et l'apprentissage auto-supervisé est le gâteau lui-même. 》
Référence :
https://analyticsindiamag.com/top-10-self-supervised-learning-models-in-2022/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 Publication du classement national CSRankings 2024 en informatique ! La CMU domine la liste, le MIT sort du top 5
Mar 25, 2024 pm 06:01 PM
Publication du classement national CSRankings 2024 en informatique ! La CMU domine la liste, le MIT sort du top 5
Mar 25, 2024 pm 06:01 PM
Les classements majeurs nationaux en informatique 2024CSRankings viennent d’être publiés ! Cette année, dans le classement des meilleures universités CS aux États-Unis, l'Université Carnegie Mellon (CMU) se classe parmi les meilleures du pays et dans le domaine de CS, tandis que l'Université de l'Illinois à Urbana-Champaign (UIUC) a été classé deuxième pendant six années consécutives. Georgia Tech s'est classée troisième. Ensuite, l’Université de Stanford, l’Université de Californie à San Diego, l’Université du Michigan et l’Université de Washington sont à égalité au quatrième rang mondial. Il convient de noter que le classement du MIT a chuté et est sorti du top cinq. CSRankings est un projet mondial de classement des universités dans le domaine de l'informatique initié par le professeur Emery Berger de la School of Computer and Information Sciences de l'Université du Massachusetts Amherst. Le classement est basé sur des objectifs
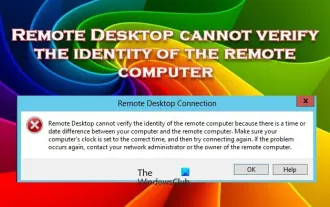 Le Bureau à distance ne peut pas authentifier l'identité de l'ordinateur distant
Feb 29, 2024 pm 12:30 PM
Le Bureau à distance ne peut pas authentifier l'identité de l'ordinateur distant
Feb 29, 2024 pm 12:30 PM
Le service Bureau à distance Windows permet aux utilisateurs d'accéder aux ordinateurs à distance, ce qui est très pratique pour les personnes qui doivent travailler à distance. Cependant, des problèmes peuvent survenir lorsque les utilisateurs ne peuvent pas se connecter à l'ordinateur distant ou lorsque Remote Desktop ne peut pas authentifier l'identité de l'ordinateur. Cela peut être dû à des problèmes de connexion réseau ou à un échec de vérification du certificat. Dans ce cas, l'utilisateur devra peut-être vérifier la connexion réseau, s'assurer que l'ordinateur distant est en ligne et essayer de se reconnecter. De plus, s'assurer que les options d'authentification de l'ordinateur distant sont correctement configurées est essentiel pour résoudre le problème. De tels problèmes avec les services Bureau à distance Windows peuvent généralement être résolus en vérifiant et en ajustant soigneusement les paramètres. Le Bureau à distance ne peut pas vérifier l'identité de l'ordinateur distant en raison d'un décalage d'heure ou de date. Veuillez vous assurer que vos calculs
 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
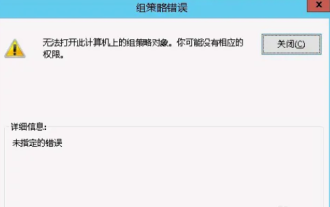 Impossible d'ouvrir l'objet Stratégie de groupe sur cet ordinateur
Feb 07, 2024 pm 02:00 PM
Impossible d'ouvrir l'objet Stratégie de groupe sur cet ordinateur
Feb 07, 2024 pm 02:00 PM
Parfois, le système d'exploitation peut mal fonctionner lors de l'utilisation d'un ordinateur. Le problème que j'ai rencontré aujourd'hui était que lors de l'accès à gpedit.msc, le système indiquait que l'objet de stratégie de groupe ne pouvait pas être ouvert car les autorisations appropriées pouvaient faire défaut. L'objet de stratégie de groupe sur cet ordinateur n'a pas pu être ouvert. Solution : 1. Lors de l'accès à gpedit.msc, le système indique que l'objet de stratégie de groupe sur cet ordinateur ne peut pas être ouvert en raison d'un manque d'autorisations. Détails : Le système ne parvient pas à localiser le chemin spécifié. 2. Une fois que l'utilisateur a cliqué sur le bouton de fermeture, la fenêtre d'erreur suivante apparaît. 3. Vérifiez immédiatement les enregistrements du journal et combinez les informations enregistrées pour découvrir que le problème réside dans le fichier C:\Windows\System32\GroupPolicy\Machine\registry.pol.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
La couche inférieure de la fonction de tri C++ utilise le tri par fusion, sa complexité est O(nlogn) et propose différents choix d'algorithmes de tri, notamment le tri rapide, le tri par tas et le tri stable.
 L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
La convergence de l’intelligence artificielle (IA) et des forces de l’ordre ouvre de nouvelles possibilités en matière de prévention et de détection de la criminalité. Les capacités prédictives de l’intelligence artificielle sont largement utilisées dans des systèmes tels que CrimeGPT (Crime Prediction Technology) pour prédire les activités criminelles. Cet article explore le potentiel de l’intelligence artificielle dans la prédiction de la criminalité, ses applications actuelles, les défis auxquels elle est confrontée et les éventuelles implications éthiques de cette technologie. Intelligence artificielle et prédiction de la criminalité : les bases CrimeGPT utilise des algorithmes d'apprentissage automatique pour analyser de grands ensembles de données, identifiant des modèles qui peuvent prédire où et quand les crimes sont susceptibles de se produire. Ces ensembles de données comprennent des statistiques historiques sur la criminalité, des informations démographiques, des indicateurs économiques, des tendances météorologiques, etc. En identifiant les tendances qui pourraient échapper aux analystes humains, l'intelligence artificielle peut donner du pouvoir aux forces de l'ordre.
 Impossible de copier les données du bureau distant vers l'ordinateur local
Feb 19, 2024 pm 04:12 PM
Impossible de copier les données du bureau distant vers l'ordinateur local
Feb 19, 2024 pm 04:12 PM
Si vous rencontrez des problèmes pour copier des données d'un poste de travail distant vers votre ordinateur local, cet article peut vous aider à les résoudre. La technologie de bureau à distance permet à plusieurs utilisateurs d'accéder à des bureaux virtuels sur un serveur central, assurant ainsi la protection des données et la gestion des applications. Cela contribue à garantir la sécurité des données et permet aux entreprises de gérer leurs applications plus efficacement. Les utilisateurs peuvent être confrontés à des difficultés lors de l'utilisation du bureau à distance, notamment l'impossibilité de copier les données du bureau distant vers l'ordinateur local. Cela peut être dû à différents facteurs. Par conséquent, cet article fournira des conseils pour résoudre ce problème. Pourquoi ne puis-je pas copier depuis le poste de travail distant vers mon ordinateur local ? Lorsque vous copiez un fichier sur votre ordinateur, il est temporairement stocké dans un emplacement appelé presse-papiers. Si vous ne pouvez pas utiliser cette méthode pour copier les données du poste de travail distant vers votre ordinateur local
