
 Périphériques technologiques
IA
Wang Lin de Taifan Technology : Base de données graphique - une nouvelle voie vers l'intelligence cognitive
Périphériques technologiques
IA
Wang Lin de Taifan Technology : Base de données graphique - une nouvelle voie vers l'intelligence cognitive
Wang Lin de Taifan Technology : Base de données graphique - une nouvelle voie vers l'intelligence cognitive

Invité | Wang Lin
Organisé | Zhang Feng
Planification | Il existe deux intelligences artificielles. Les plus grandes factions : le rationalisme et l'empirisme. . Mais dans les vrais produits de qualité industrielle, ces deux factions se complètent. Comment introduire plus de contrôlabilité et plus de connaissances dans la boîte noire de ce modèle nécessite l’application de graphes de connaissances, qui véhiculent des connaissances symboliques.
Il y a quelques jours, lors de la
WOT Global Technology Innovation Conference organisée par 51CTO, le Dr Wang Lin, CTO de Taifan Technology, a présenté l'évolution du sujet "Base de données graphique : à travers" A New Approach to Cognitive Intelligence", qui se concentre sur l'histoire et l'évolution du modèle de base de données graphique ; les moyens importants permettant aux bases de données graphiques d'atteindre l'intelligence cognitive, ainsi que la conception et l'expérience pratique des bases de données graphiques sur OpenGauss. Le contenu du discours est désormais organisé comme suit, en espérant vous inspirer :
D'une certaine dimension, l'intelligence artificielle peut être divisée en deux catégories, l'une est le
connexionnisme
, et l'autre C'est le
C'est l'apprentissage profond que nous connaissons, qui simule la structure du cerveau humain pour faire des choses telles que la perception, la reconnaissance et le jugement. L'autre type est le
Symbolisme, qui simule généralement l'esprit humain. Les processus cognitifs sont des opérations sur des représentations symboliques. Par conséquent, il est souvent utilisé pour réfléchir et raisonner. Une technologie représentative typique est le graphe de connaissances.
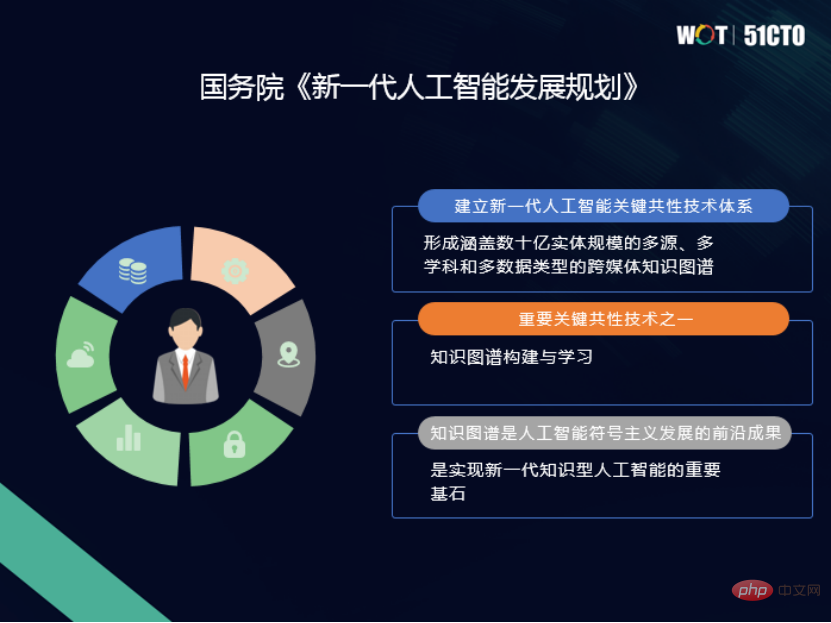
4 façons d'améliorer l'IA avec des graphiques
Le graphe de connaissances est essentiellement un réseau sémantique basé sur des graphiques, qui représente les entités et les relations entre les entités. À un niveau élevé, un graphe de connaissances est également un ensemble de connaissances interdépendantes, décrivant le monde réel et les relations entre les entités et les choses sous une forme que les humains peuvent comprendre.
Le graphe de connaissances peut nous apporter plus de connaissances sur le domaine et des informations contextuelles pour nous aider à prendre des décisions. Du point de vue de l'application, les graphes de connaissances peuvent être divisés en trois types :

Le premier est
Les connaissances extraites de données structurées et semi-structurées sont transformées en un graphe de connaissances pertinent dans le domaine. L'application la plus typique est le moteur de recherche de Google. Le deuxième est le
graphique des connaissances de perception externe. Regroupez les sources de données externes et mappez-les aux entités internes d’intérêt. Une application typique est l'analyse des risques de la chaîne d'approvisionnement. À travers la chaîne d'approvisionnement, vous pouvez voir des informations sur les fournisseurs, en amont et en aval, les usines et autres lignes d'approvisionnement, afin que vous puissiez analyser où les problèmes existent et s'il existe un risque d'interruption. Le troisième est le
Graphique de connaissances sur le traitement du langage naturel. Le traitement du langage naturel comprend un grand nombre de termes techniques et même des mots-clés dans le domaine, qui peuvent nous aider à effectuer des requêtes en langage naturel. 2. Améliorer l'efficacité opérationnelle
Les méthodes d'apprentissage automatique reposent souvent sur des données stockées dans des tables, et la plupart de ces données sont en fait des opérations gourmandes en ressources. Les graphiques de connaissances peuvent fournir un contenu pertinent dans des domaines à haute efficacité. Les données sont connectées. pour atteindre plusieurs degrés de séparation dans les relations, ce qui est propice à une analyse rapide et à grande échelle. De ce point de vue, le graphique lui-même accélère l’effet de l’apprentissage automatique.
De plus, les algorithmes d'apprentissage automatique doivent souvent être calculés sur toutes les données. Grâce à une simple requête graphique, vous pouvez renvoyer le sous-graphique des données requises, accélérant ainsi l'efficacité opérationnelle.
3. Améliorer la précision des prédictions
La relation est souvent le prédicteur de comportement le plus puissant, et les caractéristiques de la relation peuvent être facilement obtenues à partir du graphique.
En associant des données et des diagrammes de relations, les caractéristiques des relations peuvent être extraites plus directement. Mais dans les méthodes traditionnelles d’apprentissage automatique, de nombreuses informations importantes sont parfois perdues lors de l’abstraction et de la simplification des données. Les propriétés relationnelles nous permettent donc d’analyser sans perdre ces informations. De plus, les algorithmes graphiques simplifient le processus de découverte d’anomalies telles que des communautés restreintes. Nous pouvons marquer des nœuds au sein de communautés restreintes et extraire ces informations pour les utiliser dans la formation de modèles d'apprentissage automatique. Enfin, la sélection des fonctionnalités est effectuée à l'aide d'algorithmes graphiques pour réduire le nombre de fonctionnalités utilisées dans le modèle au sous-ensemble le plus pertinent.
4. Explicabilité
Ces dernières années, nous avons souvent entendu parler d'« explicabilité ». C'est aussi un défi particulièrement important dans l'application de l'intelligence artificielle. Nous devons comprendre comment l'intelligence artificielle arrive à ce résultat. présente également de nombreux attraits en termes d'interprétabilité, notamment dans certains domaines d'application spécifiques, tels que le médical, le financier et le judiciaire.
L'interprétabilité comprend trois aspects :
(1) Données interprétables. Nous devons savoir pourquoi les données ont été sélectionnées, quelle est la source des données ? Les données doivent être interprétables.
(2) Prédiction interprétable. Les prédictions interprétables signifient que nous devons savoir quelles caractéristiques sont utilisées et quels poids sont utilisés pour une prédiction spécifique.
(3) Algorithme interprétable. Les perspectives actuelles des algorithmes explicables sont très attrayantes, mais il reste encore un long chemin à parcourir dans le domaine de la recherche. Les réseaux tenseurs sont actuellement proposés, et de telles méthodes peuvent être utilisées pour donner aux algorithmes une certaine interprétabilité.
Modèle de données graphiques grand public
Étant donné que les graphiques sont si importants pour l'application et le développement de l'intelligence artificielle, comment pouvons-nous en faire bon usage ? La première chose à laquelle vous devez prêter attention est la gestion du stockage du graphique, qui est le modèle de données du graphique.
Il existe actuellement deux modèles de données graphiques les plus courants : les graphiques RDF et les graphiques d'attributs.
1. Diagramme RDF
RDF signifie Resource Description Framework. Il s'agit d'un modèle de données standard formulé par le W3C pour représenter l'échange d'informations compréhensibles par machine sur le World Wide Web sémantique. Dans un graphe RDF, chaque ressource possède une URL HTTP comme l'un de ses identifiants uniques. La définition RDF se présente sous la forme d'un triplet, représentant un énoncé de fait, où S représente le sujet, P est le prédicat et O est l'objet. Sur la photo, Bob s'intéresse à The MonoLisa, affirmant qu'il s'agit d'un diagramme RDF.

correspond au modèle de données du graphe RDF et possède son propre langage de requête - SPARQL. SPARQL est le langage de requête standard pour les graphes de connaissances RDF développé par le W3C. SPARQL tire les leçons de SQL dans sa syntaxe et est un langage de requête déclaratif. L'unité de base de la requête est également un modèle de triplet.
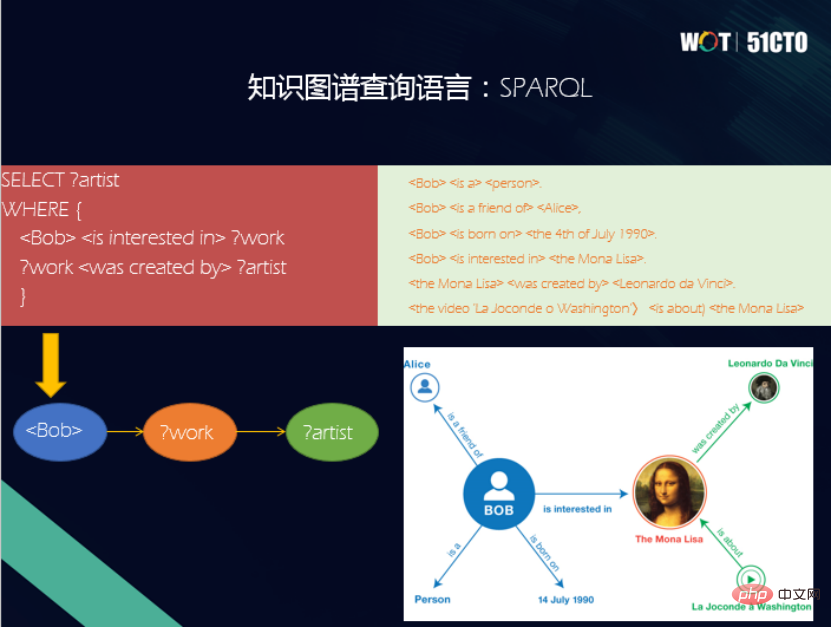
2. Graphique d'attributs
Chaque sommet et chaque arête du modèle de graphe d'attributs ont un identifiant unique, et les sommets et les arêtes ont également une étiquette, qui est équivalente au type de ressource dans le graphe RDF. De plus, les sommets et les arêtes possèdent également un ensemble d'attributs, composé de noms d'attribut et de valeurs d'attribut, formant ainsi un modèle de graphe d'attributs.
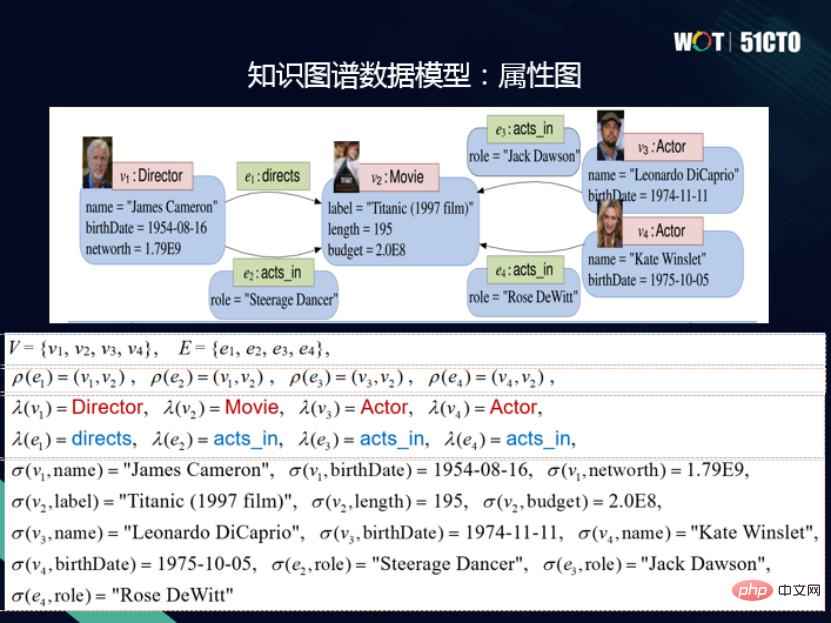
De même, le modèle de graphique d'attributs dispose également d'un langage de requête - Cypher. Cypher est également un langage de requête déclaratif. Les utilisateurs doivent uniquement déclarer ce qu'ils souhaitent rechercher et n'ont pas besoin d'indiquer comment rechercher. Une caractéristique majeure de Cypher est l'utilisation de la syntaxe artistique ASCII pour exprimer la correspondance de modèles graphiques.
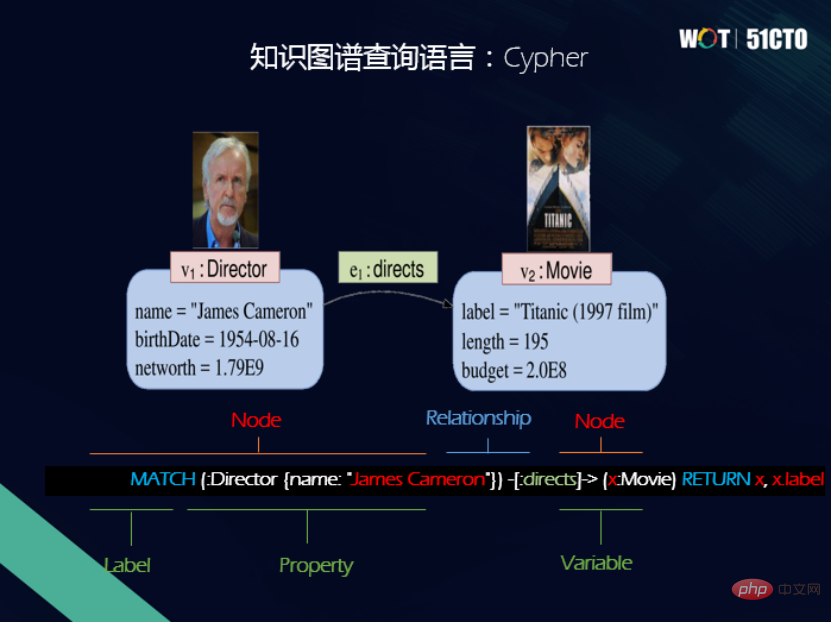
Avec le développement de l'intelligence artificielle, le développement de l'intelligence cognitive et l'application des graphes de connaissances se multiplient. Par conséquent, les bases de données graphiques ont reçu de plus en plus d'attention sur le marché ces dernières années, mais un problème important actuellement rencontré dans les graphiques est l'incohérence entre les modèles de données et les langages de requête, qui est un problème urgent qui doit être résolu.
La motivation pour étudier la base de données de graphes OpenGauss
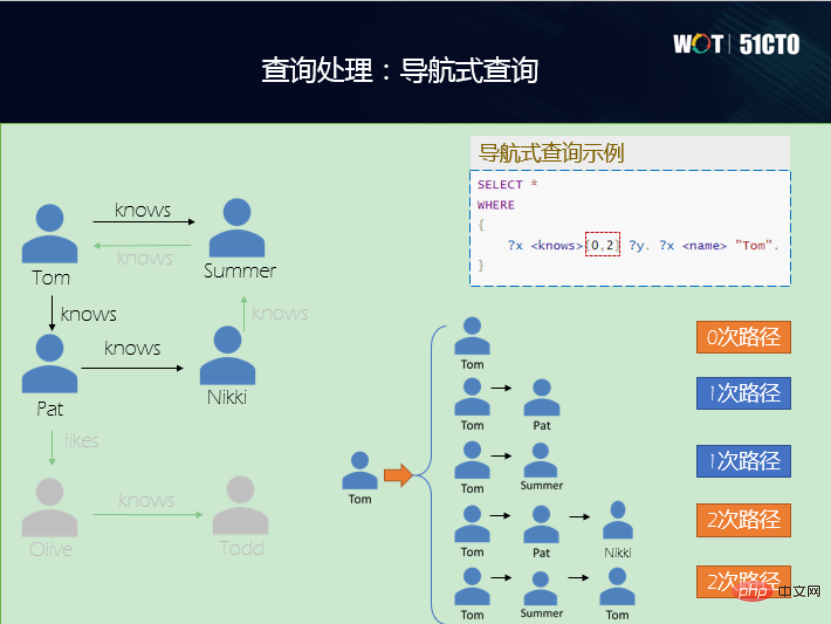
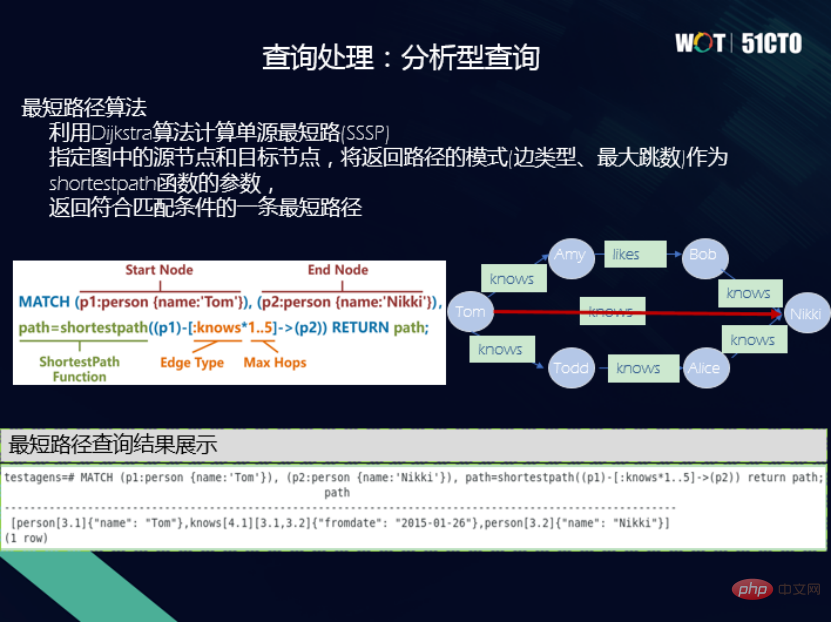
D'une part, je souhaite profiter des caractéristiques du graphe de connaissances lui-même. Par exemple, en termes de hautes performances, de haute disponibilité, de haute sécurité et de facilité d'exploitation et de maintenance, il est très important que la base de données puisse intégrer ces fonctionnalités dans la base de données graphique. D'autre part, nous partons de la considération du modèle de données graphiques. Il existe actuellement deux modèles de données et deux langages de requête. Si vous alignez les opérateurs sémantiques derrière ces deux langages de requête différents, tels que la projection, la sélection, la jointure, etc. dans les bases de données relationnelles, si vous alignez la sémantique derrière les langages SPARQL et Cypher, Fournit. deux vues syntaxiques différentes, réalisant ainsi naturellement l'interopérabilité. C'est-à-dire que la sémantique interne peut être cohérente, de sorte que vous pouvez utiliser Cypher pour vérifier les graphiques RDF, et vous pouvez également utiliser SPARQL pour vérifier les graphiques d'attributs, ce qui constitue une très bonne fonctionnalité. La couche sous-jacente utilise OpenGauss et utilise le modèle relationnel comme graphe pour stocker le modèle physique. L'idée est de résoudre les incohérences entre le graphe RDF et le graphe d'attributs, et stockez-les physiquement sur la couche sous-jacente en trouvant le plus grand dénominateur commun. Faites-en une unité. Basé sur cette idée, la couche inférieure de l'architecture d'OpenGauss-Graph est l'infrastructure, suivie des méthodes d'accès, des graphes d'attributs unifiés et des méthodes de traitement et de gestion des graphes RDF. Next est un moteur d'exécution de traitement de requêtes unifié pour prendre en charge des opérateurs sémantiques unifiés, notamment des opérateurs de correspondance de sous-graphes, des opérateurs de navigation de chemin, des opérateurs d'analyse de graphiques et des opérateurs de requête par mot-clé. Plus haut se trouve l'interface API unifiée, qui fournit l'interface SPARQL et l'interface Cypher. De plus, il existe des normes linguistiques pour un langage de requête unifié et une interface visuelle pour les requêtes interactives. Les deux points suivants sont principalement pris en compte lors de la conception d'une solution de stockage : (1) Elle ne doit pas être trop complexe, car l'efficacité d'une solution de stockage ce qui est trop complexe ne sera pas trop élevé. (2) Il doit être capable d'adapter intelligemment les types de données de deux graphes de connaissances différents. Il existe donc une solution de rangement pour la table à points et la table à bords. Il existe une table de points commune appelée propriétés. Pour différents points, il y aura un héritage ; la table de bords aura également un héritage de différentes tables de bords. Différents types de tables de points et de tables d'arêtes auront une copie, conservant ainsi une solution de stockage pour une collection de tables de points et d'arêtes. S'il s'agit d'un graphique d'attributs, les points avec des étiquettes différentes trouveront différentes tables de points. Par exemple, le professeur trouvera la table de points du professeur. Les attributs des points sont mappés aux colonnes d'attributs dans la table de points ; il en va de même pour la table des bords, les auteurs sont mappés à la table des bords des auteurs et les bords sont mappés à une ligne de la table des bords avec les ID de le nœud de début et le nœud de fin. Grâce à une méthode aussi simple en apparence mais en réalité très polyvalente, le graphe RDF et le graphe d'attributs peuvent être unifiés à partir de la couche physique. Mais dans les applications réelles, il existe un grand nombre d'entités non typées. À l'heure actuelle, nous adoptons la méthode de classification de la sémantique dans la table typée la plus proche. En plus du stockage, la chose la plus importante est la requête. Au niveau sémantique, nous avons aligné les opérations et atteint l'interopérabilité entre deux langages de requête, SPARQL et Cypher. Dans ce cas, deux niveaux sont impliqués : grammaire et lexique, et leur analyse ne doit pas entrer en conflit entre eux. Un mot-clé est cité ici. Par exemple, si vous cochez SPARQL, vous activerez la syntaxe de SPARQL. Si vous cochez Cypher, vous activerez la syntaxe de Cypher pour éviter les conflits. Nous avons également implémenté de nombreux opérateurs de requêtes. (1) Requête de correspondance de sous-graphe, interrogeant tous les compositeurs, leurs compositions et l'anniversaire du compositeur est un problème typique de correspondance de sous-graphe. Il peut être divisé en graphe d'attributs et en graphe RDF, et leur flux de traitement général est également le même. Par exemple, le point correspondant est ajouté à la liste chaînée de jointure, puis une opération de sélection est ajoutée sur la colonne des propriétés, puis des contraintes sont imposées sur la connexion entre les tables de points correspondant aux modèles de points de tête et de queue. Le graphe RDF effectue des opérations importantes sur les points de début et de fin de la table de bords. En fin de compte, les contraintes de projection sont ajoutées aux variables et le résultat final est généré. Les processus sont similaires. Les requêtes de correspondance de sous-graphes prennent également en charge certaines fonctions intégrées, telles que la fonction FILTER, qui prend en charge les restrictions de forme variable, les opérateurs logiques, l'agrégation et les opérateurs arithmétiques. Bien entendu, cette partie peut également être étendue en continu. (2) Requête de navigation, qui n'est pas disponible dans les bases de données relationnelles traditionnelles. Le côté gauche de la figure ci-dessous est un petit graphique de réseau social. Vous pouvez voir que la connaissance est à sens unique. Tom connaît Pat, mais Pat ne connaît pas Tom. Dans la requête de navigation, si vous effectuez une requête à deux sauts, voyez qui connaît Tom. Si c'est 0 saut, Tom se connaît. Le premier saut est que Tom connaît Pat et Tom connaît Summer. Le deuxième saut est celui où Tom fait la connaissance de Pat, puis de Nikki, puis de nouveau de Tom. (3) Requête par mot-clé, voici deux exemples, tsvector et tsquery. L'une consiste à convertir le document en une liste de termes ; l'autre consiste à demander si le mot ou l'expression spécifié existe dans le vecteur. Lorsque le texte du knowledge graph est relativement long et possède des attributs relativement longs, cette fonction peut être utilisée pour lui fournir une fonction de recherche par mot clé, ce qui est également très utile. (4) Requête analytique , il existe des requêtes uniques pour les bases de données graphiques, telles que le chemin le plus court , Pagerank, etc. sont tous des opérateurs de requête basés sur des graphiques, qui peuvent être utilisé dans Implémenté dans la base de données graphique. Par exemple, pour vérifier quel est le chemin le plus court de Tom à Nikki, l'opérateur de chemin le plus court est implémenté via Cypher, et le chemin le plus court peut être généré et le résultat est trouvé. En plus des fonctions mentionnées ci-dessus, nous avons également implémenté un studio visuel interactif, dans lequel vous pouvez saisir le langage de requête de Cypher et SPARQL pour obtenir un diagramme visuel intuitif, qui peut être consulté ci-dessus Pour la maintenance, la gestion et l'application des graphiques, de nombreuses interactions peuvent être effectuées sur les graphiques. À l'avenir, nous ajouterons plus d'opérateurs, de requêtes de graphiques et de recherches de graphiques pour réaliser davantage de directions et de scénarios d'application. Enfin, tout le monde est invité à visiter la communauté OpenGauss Graph, et les amis intéressés par OpenGauss Graph sont également invités à rejoindre la communauté, en tant que nouveaux contributeurs, et à construire ensemble la communauté OpenGauss Graph. Wang Lin, Ph.D. en ingénierie, responsable de la communauté de bases de données OpenGauss Graph, CTO de Taifan Technology, ingénieur principal, vice-président de la China Computer Association YOCSEF Tianjin 21-22, Membre du comité exécutif du comité spécial du système d'information du CCF, sélectionné dans le projet Tianjin 131 Talent. OpenGauss—Architecture graphique
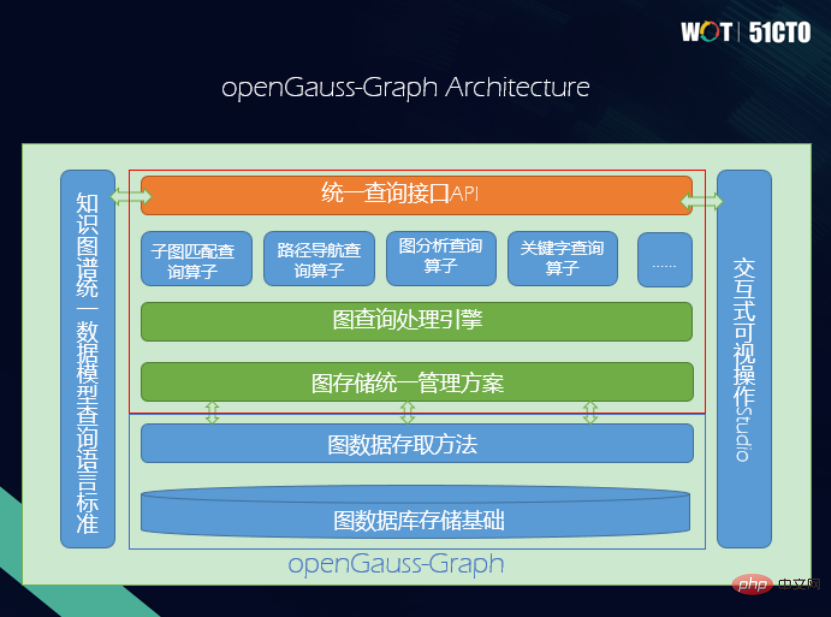
Conception d'une solution de stockage
Pratique de traitement des requêtes



Introduction de l'invité
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
1. Introduction au contexte Tout d’abord, présentons l’historique du développement de la technologie Yunwen. Yunwen Technology Company... 2023 est la période où les grands modèles prédominent. De nombreuses entreprises pensent que l'importance des graphiques a été considérablement réduite après les grands modèles et que les systèmes d'information prédéfinis étudiés précédemment ne sont plus importants. Cependant, avec la promotion du RAG et la prévalence de la gouvernance des données, nous avons constaté qu'une gouvernance des données plus efficace et des données de haute qualité sont des conditions préalables importantes pour améliorer l'efficacité des grands modèles privatisés. Par conséquent, de plus en plus d'entreprises commencent à y prêter attention. au contenu lié à la construction des connaissances. Cela favorise également la construction et le traitement des connaissances à un niveau supérieur, où de nombreuses techniques et méthodes peuvent être explorées. On voit que l'émergence d'une nouvelle technologie ne détruit pas toutes les anciennes technologies, mais peut également intégrer des technologies nouvelles et anciennes.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
