
 Périphériques technologiques
IA
Technologies clés pour la modélisation et l'animation humaines numériques
Périphériques technologiques
IA
Technologies clés pour la modélisation et l'animation humaines numériques
Technologies clés pour la modélisation et l'animation humaines numériques

Introduction : Cet article présentera les travaux de recherche liés aux technologies clés de la modélisation et de l'animation humaines numériques d'un point de vue graphique, telles que la modélisation du visage, l'édition des cheveux, les vêtements virtuels, etc. Il comprend principalement les parties suivantes :
- Retouche de portraits de visage et conception de costumes.
- Ensemble de données et méthode de base pour la découpe des cils.
- Animation en temps réel de vêtements amples basée sur le deep learning.
1. Édition de portraits de visage et conception de vêtements
1. Ajustement gras et fin du portrait vidéo numérique du visage
Publication d'un rapport oral sur l'ajustement gras et fin du portrait vidéo à ACM Multimedia2021. , principalement pour ajuster la graisse et la minceur du visage dans la vidéo afin d'obtenir un effet naturel qui ne peut pas être visuellement évident.

2. Double Chin Removal

Double Chin Removal est un article publié dans Siggraph 2021. Supprimer un double menton est difficile dans l'édition de visage, car cela implique à la fois la texture et la géométrie. Si elle est affichée, la première ligne est l'image originale, et le double menton peut disparaître progressivement en ajustant les paramètres (deuxième ligne).
3. L'épilation portrait

L'épilation portrait consiste à enlever les poils de la personne sur la photo donnée. Vous pouvez modifier les cheveux, par exemple changer une chevelure pour un personnage. Si vous conservez les cheveux d'origine, cela interférera avec le résultat de la synthèse. Dans la reconstruction tridimensionnelle des personnes numériques, si les cheveux d'origine sont conservés, ils interféreront avec la texture. Notre méthode permet d’obtenir des résultats de reconstruction 3D sans interférence avec la texture des cheveux.
4. Vêtements virtuels

Fournissez une photo et synthétisez des vêtements virtuels sur le corps d'une personne, afin que vous puissiez porter de nouveaux vêtements à votre guise.

Dans le contexte du développement durable, il y a beaucoup de problèmes dans l'industrie de la mode. Les vêtements virtuels offrent une excellente solution.

Par exemple, le côté gauche est constitué de vrais vêtements et le côté droit est constitué de vêtements virtuels. On voit que les vêtements virtuels et les vêtements réels sont très similaires.

2022 Baidu World Conference Digital Human Le modèle et l'animation des vêtements de Xi Jiajia sont fournis par nos soins.
2. Ensemble de données et méthode de base pour l'extraction des cils
1. Contexte de recherche


L'image ci-dessus est la personne numérique dans le film et le travail de la chirurgie plastique virtuelle.
Ce que nous voulons étudier, c'est comment construire une méthode de reconstruction de visage en trois dimensions de haute précision. Une méthode consiste à collecter des photos des utilisateurs et à utiliser MVS pour reconstruire le modèle tridimensionnel, mais cette méthode a un effet médiocre sur le traitement des cils. Parce qu'il y a des informations géométriques dans les cils, cela interférera avec la reconstruction et rendra le contour des yeux imprécis.

2. Travaux connexes : Reconstruction du visage de haute précision
Il existe de nombreux travaux de recherche connexes, tels que la géométrie du visage et la reconstruction des cheveux, la reconstruction des paupières et du globe oculaire, etc., mais il n'y en a pas méthode réalisable pour éditer avec précision les cils.

3. Algorithme de découpe d'image et ensemble de données de découpe
① Méthode de découpe basée sur une image tridimensionnelle
Pour modifier les cils, vous pouvez utiliser la découpe pour découper les cils. Ce qui précède consiste à résoudre une équation mal posée, comme le montre la figure ci-dessous. Il s'agit d'un exemple de découpe naturelle basée sur le diagramme de la troisième partie, qui peut donner de bons résultats. Cependant, cette méthode présente un inconvénient : elle nécessite la saisie d’un graphe en trois parties et il est très difficile de construire un graphe en trois parties.

② Ensemble de données de découpe
Il y a eu beaucoup de travail sur les ensembles de données de découpe ces dernières années, comme l'ensemble de données CVPR2009 ci-dessous.

③ Découpe d'écran bleu
La découpe d'écran bleu est beaucoup utilisée dans les effets spéciaux de films. Un écran vert ou un écran bleu est généralement utilisé, puis la valeur du masque de premier plan est calculée grâce à certaines méthodes de triangulation. .

4. Ensemble de données et méthode de base pour la découpe des cils
① Introduction à la méthode de base de l'ensemble de données
Ce que nous voulons résoudre, c'est la découpe des cils. L'entrée de gauche est une photo contenant des cils, et la valeur du masque est calculée via le réseau de tapis EyelashNet.

② Motivation de la recherche
Il y a des textures géométriques dans la zone des cils, qui vont grandement interférer avec les résultats lors du paramétrage de la reconstruction tridimensionnelle. L'effet est très mauvais, et il est très. Il faut du temps pour compter sur des artistes pour le réparer. Cela demande beaucoup de travail, il faut donc une méthode pour arracher automatiquement les cils.

③Principal défi
Si les cils sont retirés manuellement, cela prend beaucoup de temps et est laborieux. En utilisant la méthode de filtrage Gabor, l’effet n’est toujours pas bon. Des méthodes de matage d’images peuvent également être utilisées, mais la construction d’ensembles de données est très difficile. Si vous utilisez une découpe d'écran bleu, les cils poussent sur les paupières, de sorte que l'image d'arrière-plan telle que les paupières et les paupières ne peut pas être séparée et remplacée. De plus, les gens cligneront des yeux, ce qui rendra difficile de rester immobile lors de la collecte des cils. collecter plusieurs strictement alignés Et il est très difficile d'appliquer des cils de couleurs différentes.


④ Collecte de données sur les cils
Nous appliquons un agent fluorescent sur les cils, allumons le flash UVA, vous pouvez voir l'effet de fluorescence, puis obtenons les résultats de segmentation des cils. Mais cela ne suffit pas et un traitement plus approfondi est nécessaire.

⑤ Calcul du masque de cils
Nous utilisons l'ensemble de données obtenu à l'étape précédente comme entrée et utilisons le réseau de matage pour prédire les résultats réels de matage. Mais si nous utilisons uniquement l’ensemble de données d’origine, l’effet n’est pas très bon et nous n’avons pas de vérité terrain. Nous avons conçu la méthode de synthèse virtuelle Render EyelashNet pour préchauffer, puis utilisé les résultats expérimentaux pour prédire un résultat estimé. Combinés avec un travail manuel, nous avons filtré ces mauvais résultats et avons finalement obtenu un ensemble de données avec un masque initial. Ensuite, vous pouvez utiliser cet ensemble de données pour vous entraîner et obtenir un résultat affiné. Le résultat affiné est placé dans l'ensemble de données puis entraîné après itération, un meilleur ensemble de données est finalement obtenu.

5. Système de collecte de données sur les cils
① Équipement de collecte
Nous avons construit un système de collecte, comprenant 16 caméras, un flash UV 365 nm, un système de lumière de remplissage, etc. Paramètres spécifiques Vous pouvez voir la capture d'écran.


② Coloration des cils et positionnement des yeux
Nous avons invité de nombreux étudiants de l'Université du Zhejiang à appliquer un agent fluorescent sur le nuancier des cils. La personne doit rester immobile, puis utiliser le laser pour positionner les cils. département des yeux.

Comparaison des résultats de l'activation et de la désactivation du flash UV :

③ Alignement de correction
Idéalement, il n'y a pas de décalage entre les deux images de contrôle d'entrée, mais personnes Les paupières bougent facilement et il y aura des écarts.Nous utilisons FlowNet2 pour obtenir un champ de flux optique, utilisons les résultats du champ de flux optique pour décaler les cils fluorescents, puis obtenons une image strictement alignée, obtenant ainsi le résultat de segmentation.

6. Étape d'inférence
① Réseau GCA
Dans l'étape d'inférence, nous utilisons principalement le réseau GCA publié à l'AAAI en 2020.

L'entrée du réseau GCA est une image RVB et une image en trois parties, et la sortie est un masque de cils. Nos résultats de segmentation précédents peuvent être utilisés comme résultat initial de l'image en trois parties, résolvant ainsi le problème de l'image en trois parties des cils, problèmes difficiles construits artificiellement.

② Réseau d'inférence de masque

Ici, l'image tridimensionnelle est remplacée par l'image du masque de cils et l'image RVB originale en entrée, et par un entraînement progressif, combiné au préchauffage de l'entraînement RenderEyelashNet réseau, obtenez un résultat de masque, puis ajoutez ce résultat à l'entrée en tant qu'ensemble de formation et obtenez un ensemble de données de découpe de cils visuellement correct grâce à un filtrage manuel, de sorte qu'il y ait à la fois des données virtuelles et des données réelles. Utilisez cet ensemble de données pour la formation et l'inférence, et obtenez enfin la version prévue du masque pour cils. Ensuite, placez-le dans l'ensemble d'entraînement et répétez à nouveau, vous pouvez généralement obtenir le résultat souhaité en deux fois.

③ Sélection manuelle
Même les équipements matériels et logiciels les plus avancés ne peuvent pas garantir l'exactitude de la collecte des cils. Nous utilisons la sélection manuelle pour supprimer certains mauvais résultats afin de garantir l'exactitude des données d'entraînement.

④ Réseau de base

Après avoir entraîné le réseau de base, saisissez une image pour tester et obtenez de meilleurs résultats. Pour une image inconnue, nous ne savons pas quelle est son image tridimensionnelle. Si nous saisissons directement une image en niveaux de gris, nous pouvons toujours obtenir de bons résultats de prédiction des cils.

7. Ensemble de données
① Ensemble de données de formation
Nous capturons des données sur les cils pour 12 expressions oculaires et 15 vues.

② Ensemble de données de test

Afin de vérifier notre méthode, lors du test, nous avons utilisé à la fois les données que nous avons collectées nous-mêmes et certaines données d'images sur Internet.
Après deux itérations progressives, les résultats que nous avons obtenus sont déjà très bons et proches de la vraie valeur.

③ Comparaison de méthodes
Nous l'avons comparée aux meilleures méthodes actuelles Qu'elle soit visuelle ou quantitative, notre méthode est nettement meilleure que la méthode précédente.


④ Expérience d'ablation
Nous avons également réalisé des expériences d'ablation pour vérifier que chaque partie de notre méthode est indispensable.

⑤ Affichage des résultats
Nous avons utilisé quelques photos sur Internet pour vérification, ces photos n'ont pas Ground Truth. Mais pour ces photos, notre méthode permet toujours de calculer de meilleurs résultats de découpe des cils.

⑥ Application
Nous avons coopéré avec Tencent NEXT Studio pour utiliser cette méthode pour une reconstruction faciale tridimensionnelle de haute précision, et la zone des cils a été très réaliste.

Une autre application est l'édition d'embellissement des cils. Une fois que vous avez des cils, vous pouvez changer leur couleur ou les allonger. Cependant, si cette méthode est utilisée dans des endroits où les gens portent des lunettes et où l’intensité lumineuse est évidente, les résultats seront biaisés.

8. Résumé
Nous avons proposé EyelashNet, le premier ensemble de données de découpe de cils de haute qualité, contenant 5400 données de découpe de cils capturées de haute qualité et 5272 données de découpe de cils virtuelles.
Nous proposons un système de marquage fluorescent spécialement conçu pour capturer des images et des masques de cils de haute qualité.
Notre méthode permet d'atteindre des performances de pointe sur les découpes de cils.
3. Animation en temps réel de vêtements amples basée sur le deep learning
Ce travail consiste à simuler des vêtements amples. Nous avons coopéré avec l'Université du Maryland et Tencent NEXT Studio, et des articles connexes ont été publiés sur Siggraph2022. Ce travail propose une méthode de prédiction en temps réel pour les vêtements amples basée sur l'apprentissage profond, capable de bien gérer les mouvements à grande échelle et prenant en charge des paramètres de simulation variables.

1. Squelette virtuel
L'une des technologies de base de ce travail est le squelette virtuel, qui est un ensemble d'os simulés qui utilisent des méthodes de transformation rigide et de simulation hybride linéaire pour contrôler la déformation des vêtements. Grâce aux os virtuels, nous pouvons simuler efficacement les déformations complexes des vêtements amples, et ces os peuvent être utilisés comme entrée pour guider la génération des détails des vêtements.

2. Contexte de travail
Il existe généralement deux types de méthodes pour faire bouger les vêtements. L'une est la méthode physique, qui est coûteuse en calcul, l'autre est basée sur les données. en apprenant à partir de données réelles, cette méthode est relativement rapide et a de bonnes performances.

Ces dernières années, il y a eu de plus en plus de méthodes d'apprentissage automatique et d'apprentissage profond, mais ces méthodes soit prédisent la déformation des vêtements dans des conditions statiques, soit prédisent la déformation dynamique des vêtements ajustés. Mais en fait, de nombreux vêtements, comme les jupes, sont amples. Bien que certaines méthodes puissent prédire la déformation des vêtements amples, elles ne sont pas très efficaces pour prédire la déformation des grands mouvements. Et aucune des méthodes actuelles ne prend en charge les paramètres variables.

3. Contribution à la recherche
Notre recherche a principalement deux contributions. La première consiste à utiliser des méthodes d'apprentissage profond pour prédire la déformation complexe des vêtements amples. . ——Partie basse fréquence et partie haute fréquence. Utiliser des os virtuels pour représenter la déformation de la partie basse fréquence et l'utiliser pour déduire la partie haute fréquence ; la deuxième contribution consiste à utiliser les mouvements du corps combinés avec des paramètres de simulation physique comme entrée, et à utiliser cette méthode pour gérer l'hétérogénéité de les deux entrées.

4. Description sommaire
① Méthode de génération de squelette virtuel

Utilisez d'abord la méthode de simulation pour obtenir un ensemble de formation de vérité terrain et effectuez un lissage laplacien sur ces ensembles de formation. obtenez un maillage basse fréquence, puis effectuez un traitement de décomposition cutanée pour obtenir des os et des poids virtuels.
② Réseau de mouvement
obtient la séquence de mouvement du squelette virtuel à travers la séquence de mouvement du corps, prédit les informations de déformation basse fréquence via le réseau de mouvement, utilise les informations basse fréquence pour prédire les informations haute fréquence, et enfin obtient les résultats de la simulation (graphique le plus à droite) .

③ Variables des paramètres de simulation
Nous voulons évaluer différentes variables de paramètres et prédire les résultats des paramètres de simulation que nous n'avons pas vus à travers le réseau RBF, afin de pouvoir utiliser un ensemble de paramètres de réseau Différentes prédictions peut être fait.

5. Méthode
① Préparation des données
Nous devons d'abord générer des données de vérité terrain. Nous avons utilisé le Houdini Vellum Solver pour simuler environ 40 000 images d'animation. Nous n’avons pas utilisé les résultats de capture de mouvements de personnes réelles, mais les actions vidéo provenant d’Internet. En effet, nous voulons simuler de grands mouvements, mais les mouvements des personnes réelles sont plus petits.

②Décomposition de la peau
Séquence de déformation à basse fréquence Nous utilisons la décomposition de la peau pour obtenir des os virtuels, et le résultat est un modèle à peau hybride linéaire. Ce modèle comprend une pose de repos et correspond au poids de la peau de chaque os. . La translation et la rotation du squelette virtuel à chaque image sont également obtenues. Les os virtuels n'ont pas de relation hiérarchique, il n'y a pas de relation entre les os parents et les os enfants, et chaque os a sa propre rotation et translation.
De plus, les os virtuels n'ont pas de réelle signification réaliste. Les os virtuels sont obtenus pour chaque animation spécifique. Nous utilisons Motion Network pour traiter l'entrée du corps. Chaque réseau correspond à différents paramètres de simulation corporelle. L'entrée est uniquement la rotation des articulations et la translation du personnage, et la sortie est le résultat de l'inférence du maillage correspondant aux paramètres physiques. .

③ Réseau d'action
Le réseau d'action déduit les parties basse fréquence et haute fréquence en séquence.
- Module basse fréquence
La partie basse fréquence utilise le réseau neuronal récurrent GRU pour convertir les mouvements du corps d'entrée en rotation et translation des os virtuels. Le réseau est qu'il peut obtenir les informations de la trame précédente, afin de mieux capturer les effets dynamiques, une déformation basse fréquence peut être obtenue en utilisant le dépouillement de mélange linéaire d'os virtuel.

- Module haute fréquence
Le réseau d'action peut être utilisé pour prédire la partie haute fréquence. L'un est GRU pour obtenir des caractéristiques haute fréquence, et l'autre est GNN. pour obtenir des caractéristiques de partie basse fréquence et combiner les deux parties de caractéristiques, les informations haute fréquence sont obtenues via MLP. Le résultat final est obtenu en additionnant les résultats haute fréquence et basse fréquence.

- Réseau neuronal RBF
Afin de traiter l'entrée des paramètres de simulation physique, nous avons formé de nombreux réseaux de mouvement avec différentes actions pour les résultats de simulation de paramètres correspondant à la sortie du. même action, nous utilisons Le réseau de neurones RBF additionne ces résultats, avec des coefficients de pondération dépendant de la distance entre les paramètres de simulation et les paramètres de simulation du réseau correspondant, et utilise un perceptron multicouche pour projeter les paramètres dans un espace avant de calculer la distance.

6. Résultats
En simulation en temps réel, les vêtements amples peuvent très bien être simulés sans modifier les paramètres de simulation. Les résultats de simulation à gauche sont très proches de la vérité terrain et le côté droit traite de paramètres variables.

Une autre question est de savoir comment sélectionner le nombre d'os virtuels. Notre expérience a révélé que pour la partie basse fréquence, un nombre trop petit n'a aucun effet positif, et qu'un nombre trop élevé n'aide pas beaucoup. 80 est un meilleur résultat. Mais pour la partie haute fréquence, plus il y a d'os virtuels, mieux c'est, afin que les détails puissent être mieux exprimés.
- Nombre d'os virtuels

- Améliorer la partie ample
Le lâche fait référence à la distance entre les vêtements et le corps humain, la partie rouge signifie plus loin, la partie bleue signifie plus loin signifie section serrée, on voit que nos résultats (à l'extrême droite) sont meilleurs.

Ceci est un tableau de comparaison entre les cas de basse fréquence et de haute fréquence et la vraie valeur. Notre méthode est plus proche de la vérité terrain.
- Résultats de comparaison qualitative
En regardant visuellement la comparaison de différentes méthodes, bien que notre effet soit légèrement différent de la vérité terrain, il est relativement meilleur, quelle que soit la haute ou la basse fréquence partie. Tous relativement proches.

- Résultats de comparaison quantitative
Nous avons également effectué des analyses quantitatives, telles que RMSE, STED et d'autres indicateurs, et les résultats ont montré qu'elle était nettement meilleure que la méthode précédente, même pour les vêtements moulants et traditionnels La méthode est également assez similaire.


- Expérience d'ablation RBF
Nous avons fait une expérience d'ablation à travers le réseau RBF pour vérifier notre méthode.

7. Perspectives d'avenir et résumé
Dans le cas de mouvements très importants, les jambes dans les résultats de la simulation peuvent passer à travers les vêtements. En effet, l'évitement des collisions est ajouté via le réseau d'énergie. D'autres méthodes de skinning pourront également être utilisées à l'avenir pour obtenir de meilleurs résultats.

La reconstruction et l'animation de visages de haute précision sont très importantes dans de nombreuses applications, telles que les jeux, les humains virtuels et le métaverse. Elles nécessitent toutes un traitement en temps réel et constituent également un défi de taille. De plus, les vêtements couvrent plus de 80 % du corps humain et constituent également une partie importante de l’humain numérique. Dans les applications graphiques, nous accordons peut-être plus d’attention aux visages de près, mais à une distance légèrement plus grande, nous accordons plus d’attention aux vêtements. Je pense que l’orientation future du développement consiste à utiliser des méthodes peu coûteuses pour créer des applications humaines numériques en temps réel très réalistes.

IV. Séance de questions et réponses
Q1 : Comment assurer la généralisation des squelettes virtuels ?
A1 : Les os virtuels sont calculés. Changer un ensemble de vêtements nécessite de régénérer de nouveaux os, et le nombre et la transformation sont également différents. Il est calculé en temps réel lors de l'inférence.
Q2 : Est-il facile de confectionner des vêtements en trois dimensions ?
A2 : C'est toujours très pratique. Les personnes qui ne l'ont jamais appris auparavant peuvent l'apprendre rapidement après la formation. Même si vous concevez une tenue à partir de zéro, vous pourrez peut-être concevoir une tenue très compliquée en une ou deux heures.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment accélérer les effets d'animation dans Windows 11 : 2 méthodes expliquées
Apr 24, 2023 pm 04:55 PM
Comment accélérer les effets d'animation dans Windows 11 : 2 méthodes expliquées
Apr 24, 2023 pm 04:55 PM
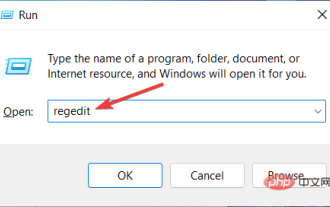
Lorsque Microsoft a lancé Windows 11, de nombreux changements ont été apportés. L'un des changements est une augmentation du nombre d'animations de l'interface utilisateur. Certains utilisateurs souhaitent changer la façon dont les choses apparaissent et doivent trouver un moyen de le faire. Avoir des animations rend le tout plus agréable et plus convivial. L'animation utilise des effets visuels pour rendre l'ordinateur plus attrayant et plus réactif. Certains d'entre eux incluent des menus coulissants après quelques secondes ou minutes. De nombreuses animations sur votre ordinateur peuvent affecter les performances du PC, le ralentir et interférer avec votre travail. Dans ce cas, vous devez désactiver l'animation. Cet article présentera plusieurs façons dont les utilisateurs peuvent améliorer la vitesse de leurs animations sur PC. Vous pouvez utiliser l'Éditeur du Registre ou un fichier personnalisé que vous exécutez pour appliquer les modifications. Comment améliorer les animations dans Windows 11
 Animation CSS : comment obtenir l'effet flash des éléments
Nov 21, 2023 am 10:56 AM
Animation CSS : comment obtenir l'effet flash des éléments
Nov 21, 2023 am 10:56 AM
Animation CSS : Comment obtenir l'effet flash des éléments, des exemples de code spécifiques sont nécessaires dans la conception Web, les effets d'animation peuvent parfois apporter une bonne expérience utilisateur à la page. L'effet scintillant est un effet d'animation courant qui peut rendre les éléments plus accrocheurs. Ce qui suit explique comment utiliser CSS pour obtenir l'effet flash des éléments. 1. Implémentation de base de Flash Tout d'abord, nous devons utiliser la propriété d'animation de CSS pour obtenir l'effet flash. La valeur de l'attribut animation doit spécifier le nom de l'animation, le temps d'exécution de l'animation et le temps de retard de l'animation.
![L'animation ne fonctionne pas dans PowerPoint [Corrigé]](https://img.php.cn/upload/article/000/887/227/170831232982910.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) L'animation ne fonctionne pas dans PowerPoint [Corrigé]
Feb 19, 2024 am 11:12 AM
L'animation ne fonctionne pas dans PowerPoint [Corrigé]
Feb 19, 2024 am 11:12 AM
Essayez-vous de créer une présentation mais vous ne parvenez pas à ajouter une animation ? Si les animations ne fonctionnent pas dans PowerPoint sur votre PC Windows, cet article vous aidera. Il s’agit d’un problème courant dont se plaignent de nombreuses personnes. Par exemple, les animations peuvent cesser de fonctionner lors de présentations dans Microsoft Teams ou lors d'enregistrements d'écran. Dans ce guide, nous explorerons diverses techniques de dépannage pour vous aider à corriger les animations qui ne fonctionnent pas dans PowerPoint sous Windows. Pourquoi mes animations PowerPoint ne fonctionnent-elles pas ? Nous avons remarqué que certaines raisons possibles pouvant entraîner le dysfonctionnement de l'animation dans PowerPoint sous Windows sont les suivantes : En raison de problèmes personnels
 Comment configurer l'animation ppt pour entrer d'abord puis sortir
Mar 20, 2024 am 09:30 AM
Comment configurer l'animation ppt pour entrer d'abord puis sortir
Mar 20, 2024 am 09:30 AM
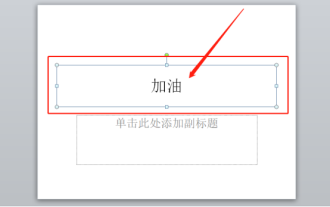
Nous utilisons souvent ppt dans notre travail quotidien, alors connaissez-vous toutes les fonctions opérationnelles de ppt ? Par exemple : comment définir les effets d'animation dans ppt, comment définir les effets de commutation et quelle est la durée de l'effet de chaque animation ? Chaque diapositive peut-elle être lue automatiquement, entrer puis quitter l'animation ppt, etc. Dans le numéro d'aujourd'hui, je partagerai avec vous les étapes spécifiques d'entrée puis de sortie de l'animation ppt. Elles sont ci-dessous. 1. Tout d'abord, nous ouvrons ppt sur l'ordinateur, cliquez à l'extérieur de la zone de texte pour sélectionner la zone de texte (comme indiqué dans le cercle rouge dans la figure ci-dessous). 2. Ensuite, cliquez sur [Animation] dans la barre de menu et sélectionnez l'effet [Effacer] (comme indiqué dans le cercle rouge sur la figure). 3. Ensuite, cliquez sur [
 Après un retard de deux ans, le film d'animation national en 3D 'Er Lang Shen : The Deep Sea Dragon' devrait sortir le 13 juillet.
Jan 26, 2024 am 09:42 AM
Après un retard de deux ans, le film d'animation national en 3D 'Er Lang Shen : The Deep Sea Dragon' devrait sortir le 13 juillet.
Jan 26, 2024 am 09:42 AM
Ce site Web a rapporté le 26 janvier que le film d'animation national en 3D « Er Lang Shen : Le dragon des profondeurs » avait publié une série de dernières images fixes et a officiellement annoncé qu'il sortirait le 13 juillet. Il est entendu que "Er Lang Shen : The Deep Sea Dragon" est produit par Mihuxing (Beijing) Animation Co., Ltd., Horgos Zhonghe Qiancheng Film Co., Ltd., Zhejiang Hengdian Film Co., Ltd., Zhejiang Gongying Film. Co., Ltd., Chengdu Le film d'animation produit par Tianhuo Technology Co., Ltd. et Huawen Image (Beijing) Film Co., Ltd. et réalisé par Wang Jun devait initialement sortir en Chine continentale le 22 juillet 2022. . Synopsis de l'intrigue de ce site : Après la bataille des dieux conférés, Jiang Ziya a pris la « Liste des dieux conférés » pour diviser les dieux, puis la liste des dieux conférés a été scellée par la Cour céleste sous la mer profonde de Kyushu Royaume secret. En fait, en plus de conférer des positions divines, il existe également de nombreux esprits maléfiques puissants scellés dans la liste des dieux conférés.
 Comment utiliser Vue pour implémenter des effets d'animation de machine à écrire
Sep 19, 2023 am 09:33 AM
Comment utiliser Vue pour implémenter des effets d'animation de machine à écrire
Sep 19, 2023 am 09:33 AM
Comment utiliser Vue pour implémenter des effets spéciaux d'animation de machine à écrire L'animation de machine à écrire est un effet spécial courant et accrocheur qui est souvent utilisé dans les titres de sites Web, les slogans et autres affichages de texte. Dans Vue, nous pouvons obtenir des effets d'animation de machine à écrire en utilisant les instructions personnalisées de Vue. Cet article présentera en détail comment utiliser Vue pour obtenir cet effet spécial et fournira des exemples de code spécifiques. Étape 1 : Créer un projet Vue Tout d'abord, nous devons créer un projet Vue. Vous pouvez utiliser VueCLI pour créer rapidement un nouveau projet Vue, ou manuellement
 Comment désactiver les animations dans Windows 11
Apr 16, 2023 pm 11:34 PM
Comment désactiver les animations dans Windows 11
Apr 16, 2023 pm 11:34 PM
Microsoft Windows 11 inclut de nombreuses nouvelles fonctionnalités et fonctionnalités. L'interface utilisateur a été mise à jour et la société a également introduit de nouveaux effets. Par défaut, les effets d'animation sont appliqués aux contrôles et autres objets. Dois-je désactiver ces animations ? Bien que Windows 11 propose des animations et des effets de fondu visuellement attrayants, ils peuvent rendre votre ordinateur lent pour certains utilisateurs car ils ajoutent un peu de décalage à certaines tâches. Il est facile de désactiver les animations pour une expérience utilisateur plus réactive. Après avoir vu les autres modifications apportées au système d'exploitation, nous vous expliquerons comment activer ou désactiver les effets d'animation dans Windows 11. Nous avons également un article sur la façon de
 Le PV final de l'animation principale 'Arknights: Winter Hidden Return' a été annoncé et sera lancé le 7 octobre.
Sep 23, 2023 am 11:37 AM
Le PV final de l'animation principale 'Arknights: Winter Hidden Return' a été annoncé et sera lancé le 7 octobre.
Sep 23, 2023 am 11:37 AM
Le contenu qui doit être réécrit sur ce site est : 9 Le contenu qui doit être réécrit est : Mois Le contenu qui doit être réécrit est : 23 Le contenu qui doit être réécrit est : Daily News, le drame principal de la deuxième saison de la série animée "Arknights" "Arknights : Winter Hidden Return" est sortie. Le contenu qui doit être réécrit est : PV Le contenu qui doit être réécrit est : 10. Le contenu qui doit être réécrit. est : 7. Le contenu qui doit être réécrit est : 7 Le contenu est : Le contenu qui doit être réécrit est : 00:23 Le contenu qui doit être réécrit est : Officiellement lancé, cliquez ici pour accéder au site officiel de le thème. Le contenu qui doit être réécrit est le suivant : Ce site a remarqué que "Arknights : Winter Hidden Return" est la suite de "Arknights : Prelude to Dawn". Le résumé de l'intrigue est le suivant : Afin de prévenir les infectés, un groupe de
