
 Périphériques technologiques
IA
Exercice pratique sur l'arbre de décision d'apprentissage automatique
Périphériques technologiques
IA
Exercice pratique sur l'arbre de décision d'apprentissage automatique
Exercice pratique sur l'arbre de décision d'apprentissage automatique

Traducteur | Zhu Xianzhong
Réviseur | Sun Shujuan
Arbres de décision dans l'apprentissage automatique
Les algorithmes d'apprentissage automatique modernes changent notre vie quotidienne. Par exemple, de grands modèles linguistiques tels que BERT alimentent la recherche Google, et GPT-3 alimente de nombreuses applications linguistiques de haut niveau.
D’un autre côté, créer des algorithmes d’apprentissage automatique complexes est beaucoup plus facile aujourd’hui que jamais. Cependant, quelle que soit la complexité des algorithmes d'apprentissage automatique, ils entrent tous dans l'une des catégories d'apprentissage suivantes :
- En fait, l'arbre de décision est l'un des plus anciens algorithmes d'apprentissage automatique supervisé et peut résoudre un large éventail de problèmes réels. La recherche montre que la première invention de l’algorithme d’arbre de décision remonte à 1963.
- Ensuite, approfondissons les détails de cet algorithme et voyons pourquoi ce type d'algorithme est toujours si populaire aujourd'hui.
- Qu'est-ce qu'un arbre de décision ? L'algorithme d'arbre de décision est un algorithme d'apprentissage automatique supervisé populaire en raison de sa manière relativement plus simple de gérer des ensembles de données complexes. Les arbres de décision tirent leur nom de leur similitude avec la structure d'un arbre ; une structure arborescente se compose de plusieurs composants tels que des racines, des branches et des feuilles sous forme de nœuds et d'arêtes. Ils sont utilisés pour l’analyse des décisions, un peu comme un organigramme de décision basé sur « if-else », où les décisions produiront les prédictions souhaitées. Les arbres de décision peuvent apprendre ces règles de décision if-else pour diviser l'ensemble de données et enfin générer un modèle de données arborescent.
- Des arbres de décision ont été appliqués à la prédiction de résultats discrets pour des problèmes de classification et à la prédiction de résultats numériques continus pour des problèmes de régression. Au fil des années, les scientifiques ont développé de nombreux algorithmes différents tels que CART, C4.5 et des algorithmes d'ensemble tels que les forêts aléatoires et les arbres à gradient amélioré.
Anatomie des différents composants d'un arbre de décision
Le but de l'algorithme de l'arbre de décision est de prédire le résultat de l'ensemble de données d'entrée. L'ensemble de données de l'arborescence est divisé en trois formes : attributs, valeurs d'attribut et types à prédire. Comme pour tout algorithme d’apprentissage supervisé, l’ensemble de données est divisé en deux types : l’ensemble d’entraînement et l’ensemble de test. Parmi eux, l’ensemble d’entraînement définit les règles de décision que l’algorithme apprend et applique à l’ensemble de test.Avant de rassembler les étapes de l'algorithme de l'arbre de décision, comprenons d'abord les composants de l'arbre de décision :
Nœud racine : C'est le nœud de départ en haut de l'arbre de décision et contient tous les attributs valeurs. Le nœud racine est divisé en nœuds de décision en fonction des règles de décision apprises par l'algorithme.
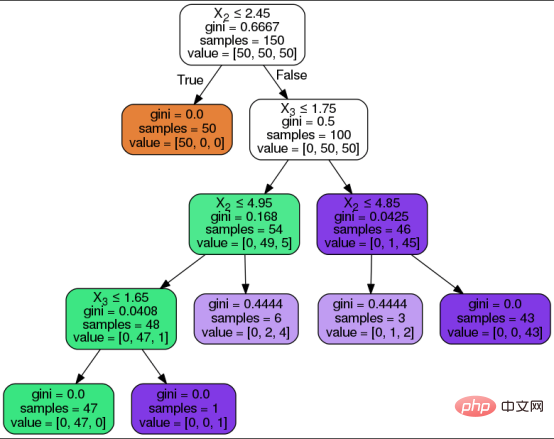
Nœud de décision/nœud interne : le nœud interne est le nœud de décision entre le nœud racine et le nœud feuille, correspondant à la règle de décision et à son chemin de réponse. Les nœuds représentent des questions et les branches affichent des chemins vers des réponses pertinentes basées sur ces questions.
Nœuds feuilles : les nœuds feuilles sont des nœuds terminaux qui représentent les prédictions cibles. Ces nœuds ne seront pas davantage divisés.
- Ce qui suit est une représentation visuelle d'un arbre de décision et de ses composants ci-dessus, l'algorithme de l'arbre de décision passe par les étapes suivantes pour arriver à la prédiction souhaitée :
- L'algorithme commence à partir du nœud racine avec tous valeurs d'attribut.
- Le nœud racine est divisé en nœuds de décision en fonction des règles de décision apprises par l'algorithme à partir de l'ensemble d'entraînement.
- Faites passer les nœuds de décision internes à travers les branches/bords en fonction de la question et de son chemin de réponse.
Continuez les étapes précédentes jusqu'à ce que vous atteigniez un nœud feuille ou que tous les attributs soient utilisés.
- Afin de sélectionner le meilleur attribut sur chaque nœud, la répartition sera basée sur l'une des deux mesures de sélection d'attribut suivantes :
- Indice Gini (Indice Gini) mesure l'impureté Gini (Impurité Gini) pour indiquer la probabilité qu'un algorithme classe mal une étiquette de classe aléatoire.
- Le gain d'information mesure l'amélioration de l'entropie après la division pour éviter une répartition 50/50 des classes prédites. L'entropie est une mesure mathématique de l'impureté dans un échantillon de données donné. L'état chaotique dans l'arbre de décision est représenté par la partition qui est proche de 50/50. Cas de classification des fleurs à l'aide d'un algorithme d'arbre de décision
- Étiquettes/types de fleurs prévus dans l'ensemble de données : Setosis, Versicolor, Virginica.
- 贷款批准
- 支出管理
- 客户流失预测
- 新产品的可行性分析,等等。
Une brève explication sur l'ensemble de données
L'ensemble de données de ce tutoriel est un ensemble de données sur la fleur d'iris. Cet ensemble de données est déjà intégré à la bibliothèque open source Scikit, les développeurs n'ont donc pas besoin de le charger en externe. Cet ensemble de données comprend un total de quatre attributs d'iris et les valeurs d'attribut correspondantes, qui seront entrées dans le modèle pour prédire l'un des trois types de fleurs d'iris.
- Attributs/caractéristiques dans l'ensemble de données : longueur des sépales, largeur des sépales, longueur des pétales, largeur des pétales.
Importer des bibliothèques
Tout d'abord, importez les bibliothèques requises pour exécuter l'implémentation de l'arbre de décision via le morceau de code suivant.import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
data_set = load_iris()
print('Iris plant classes to predict: ', data_set.target_names)
print('Four features of iris plant: ', data_set.feature_names)
 Attributs et balises séparés
Attributs et balises séparés
#提取花的特性和类型信息
X_att = data_set.data
y_label = data_set.target
print('数据集中总的样本数:', X_att.shape[0])
data_view=pd.DataFrame({
'sepal length':X_att[:,0],
'sepal width':X_att[:,1],
'petal length':X_att[:,2],
'petal width':X_att[:,3],
'species':y_label
})
data_view.head()
#数据集拆分为训练集和测试集两部分
X_att_train, X_att_test, y_label_train, y_label_test = train_test_split(X_att, y_label, random_state = 42, test_size = 0.25)
un arbre de décision en utilisant la fonction DecisionTreeClassifier pour créer un modèle de classification, classification standard Réglé sur "entropie" way . La norme permet à de définir la métrique de sélection d'attribut comme gain d'informations (Gain d'informations). Le code associe ensuite le modèle à notre ensemble d'attributs et d'étiquettes d'entraînement. 下面的代码负责计算并打印决策树分类模型在训练集和测试集上的准确性。为了计算准确度分数,我们使用了predict函数。测试结果是:训练集和测试集的准确率分别为100%和94.7%。 当今社会,机器学习决策树在许多行业的决策过程中都得到广泛应用。其中,决策树的最常见应用首先是在金融和营销部门,例如可用于如下一些子领域: 作为本文决策树主题讨论的总结,我们有充分的理由安全地假设:决策树的可解释性仍然很受欢迎。决策树之所以容易理解,是因为它们可以被人类以可视化方式展现并便于解释。因此,它们是解决机器学习问题的直观方法,同时也能够确保结果是可解释的。机器学习中的可解释性是我们过去讨论过的一个小话题,它也与即将到来的人工智能伦理主题存在密切联系。 与任何其他机器学习算法一样,决策树自然也可以加以改进,以避免过度拟合和出现过于偏向于优势预测类别。剪枝和ensembling技术是克服决策树算法缺点方案最常采用的方法。决策树尽管存在这些缺点,但仍然是决策分析算法的基础,并将在机器学习领域始终保持重要位置。 朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。 原文标题:An Introduction to Decision Trees for Machine Learning,作者:Stylianos Kampakis#应用决策树分类器
clf_dt = DecisionTreeClassifier(criterion = 'entropy')
clf_dt.fit(X_att_train, y_label_train)
计算模型精度
print('Training data accuracy: ', accuracy_score(y_true=y_label_train, y_pred=clf_dt.predict(X_att_train)))
print('Test data accuracy: ', accuracy_score(y_true=y_label_test, y_pred=clf_dt.predict(X_att_test)))真实世界中的决策树应用程序
如何改进决策树?
译者介绍
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
L'annotation d'images est le processus consistant à associer des étiquettes ou des informations descriptives à des images pour donner une signification et une explication plus profondes au contenu de l'image. Ce processus est essentiel à l’apprentissage automatique, qui permet d’entraîner les modèles de vision à identifier plus précisément les éléments individuels des images. En ajoutant des annotations aux images, l'ordinateur peut comprendre la sémantique et le contexte derrière les images, améliorant ainsi la capacité de comprendre et d'analyser le contenu de l'image. L'annotation d'images a un large éventail d'applications, couvrant de nombreux domaines, tels que la vision par ordinateur, le traitement du langage naturel et les modèles de vision graphique. Elle a un large éventail d'applications, telles que l'assistance aux véhicules pour identifier les obstacles sur la route, en aidant à la détection. et le diagnostic des maladies grâce à la reconnaissance d'images médicales. Cet article recommande principalement de meilleurs outils d'annotation d'images open source et gratuits. 1.Makesens
 Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Dans les domaines de l’apprentissage automatique et de la science des données, l’interprétabilité des modèles a toujours été au centre des préoccupations des chercheurs et des praticiens. Avec l'application généralisée de modèles complexes tels que l'apprentissage profond et les méthodes d'ensemble, la compréhension du processus décisionnel du modèle est devenue particulièrement importante. Explainable AI|XAI contribue à renforcer la confiance dans les modèles d'apprentissage automatique en augmentant la transparence du modèle. L'amélioration de la transparence des modèles peut être obtenue grâce à des méthodes telles que l'utilisation généralisée de plusieurs modèles complexes, ainsi que les processus décisionnels utilisés pour expliquer les modèles. Ces méthodes incluent l'analyse de l'importance des caractéristiques, l'estimation de l'intervalle de prédiction du modèle, les algorithmes d'interprétabilité locale, etc. L'analyse de l'importance des fonctionnalités peut expliquer le processus de prise de décision du modèle en évaluant le degré d'influence du modèle sur les fonctionnalités d'entrée. Estimation de l’intervalle de prédiction du modèle
 Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
En termes simples, un modèle d’apprentissage automatique est une fonction mathématique qui mappe les données d’entrée à une sortie prédite. Plus précisément, un modèle d'apprentissage automatique est une fonction mathématique qui ajuste les paramètres du modèle en apprenant à partir des données d'entraînement afin de minimiser l'erreur entre la sortie prédite et la véritable étiquette. Il existe de nombreux modèles dans l'apprentissage automatique, tels que les modèles de régression logistique, les modèles d'arbre de décision, les modèles de machines à vecteurs de support, etc. Chaque modèle a ses types de données et ses types de problèmes applicables. Dans le même temps, il existe de nombreux points communs entre les différents modèles, ou il existe une voie cachée pour l’évolution du modèle. En prenant comme exemple le perceptron connexionniste, en augmentant le nombre de couches cachées du perceptron, nous pouvons le transformer en un réseau neuronal profond. Si une fonction noyau est ajoutée au perceptron, elle peut être convertie en SVM. celui-ci
 Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Cet article présentera comment identifier efficacement le surajustement et le sous-apprentissage dans les modèles d'apprentissage automatique grâce à des courbes d'apprentissage. Sous-ajustement et surajustement 1. Surajustement Si un modèle est surentraîné sur les données de sorte qu'il en tire du bruit, alors on dit que le modèle est en surajustement. Un modèle surajusté apprend chaque exemple si parfaitement qu'il classera mal un exemple inédit/inédit. Pour un modèle surajusté, nous obtiendrons un score d'ensemble d'entraînement parfait/presque parfait et un score d'ensemble/test de validation épouvantable. Légèrement modifié : "Cause du surajustement : utilisez un modèle complexe pour résoudre un problème simple et extraire le bruit des données. Parce qu'un petit ensemble de données en tant qu'ensemble d'entraînement peut ne pas représenter la représentation correcte de toutes les données."
 L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
Dans les années 1950, l’intelligence artificielle (IA) est née. C’est à ce moment-là que les chercheurs ont découvert que les machines pouvaient effectuer des tâches similaires à celles des humains, comme penser. Plus tard, dans les années 1960, le Département américain de la Défense a financé l’intelligence artificielle et créé des laboratoires pour poursuivre son développement. Les chercheurs trouvent des applications à l’intelligence artificielle dans de nombreux domaines, comme l’exploration spatiale et la survie dans des environnements extrêmes. L'exploration spatiale est l'étude de l'univers, qui couvre l'ensemble de l'univers au-delà de la terre. L’espace est classé comme environnement extrême car ses conditions sont différentes de celles de la Terre. Pour survivre dans l’espace, de nombreux facteurs doivent être pris en compte et des précautions doivent être prises. Les scientifiques et les chercheurs pensent qu'explorer l'espace et comprendre l'état actuel de tout peut aider à comprendre le fonctionnement de l'univers et à se préparer à d'éventuelles crises environnementales.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
 Perspectives sur les tendances futures de la technologie Golang dans l'apprentissage automatique
May 08, 2024 am 10:15 AM
Perspectives sur les tendances futures de la technologie Golang dans l'apprentissage automatique
May 08, 2024 am 10:15 AM
Le potentiel d'application du langage Go dans le domaine de l'apprentissage automatique est énorme. Ses avantages sont les suivants : Concurrence : il prend en charge la programmation parallèle et convient aux opérations intensives en calcul dans les tâches d'apprentissage automatique. Efficacité : les fonctionnalités du garbage collector et du langage garantissent l’efficacité du code, même lors du traitement de grands ensembles de données. Facilité d'utilisation : la syntaxe est concise, ce qui facilite l'apprentissage et l'écriture d'applications d'apprentissage automatique.
