
 développement back-end
Tutoriel Python
Obtenez et stockez des données de séries chronologiques avec Python
développement back-end
Tutoriel Python
Obtenez et stockez des données de séries chronologiques avec Python
Obtenez et stockez des données de séries chronologiques avec Python


Traducteur | Bugatti
Reviewer | Sun Shujuan
Ce tutoriel présentera comment utiliser Python pour obtenir des données de séries chronologiques à partir de l'API OpenWeatherMap et les convertir en un Pandas DataFrame. Ensuite, nous utiliserons le client Python InfluxDB pour écrire ces données sur la plateforme de données de séries chronologiques InfluxDB.
Nous convertirons la réponse JSON de l'appel API en un Pandas DataFrame car c'est le moyen le plus simple d'écrire des données dans InfluxDB. Étant donné qu'InfluxDB est une base de données spécialement conçue, nos écritures dans InfluxDB sont conçues pour répondre aux exigences élevées en termes d'ingestion de données de séries chronologiques.
Conditions requises
Ce tutoriel est réalisé sur un système macOS avec Python 3 installé via Homebrew. Il est recommandé d'installer des outils supplémentaires tels que virtualenv, pyenv ou conda-env pour simplifier l'installation de Python et du Client. Exigences complètes ici :
txt influxdb-client=1.30.0 pandas=1.4.3 requests>=2.27.1
Ce tutoriel suppose également que vous avez déjà créé un compte cloud InfluxDB de niveau gratuit ou que vous utilisez InfluxDB OSS et que vous avez également :
- créé le bucket. Vous pouvez considérer les compartiments comme le plus haut niveau d'organisation des données dans une base de données ou InfluxDB.
- Jeton créé.
Enfin, ce tutoriel nécessite que vous ayez déjà créé un compte avec OpenWeatherMap et créé un token.
Demander des données météorologiques
Tout d'abord, nous devons demander des données. Nous utiliserons la bibliothèque de requêtes pour renvoyer des données météorologiques horaires à partir d'une longitude et d'une latitude spécifiées via l'API OpenWeatherMap.
# Get time series data from OpenWeatherMap API
params = {'lat':openWeatherMap_lat, 'lon':openWeatherMap_lon, 'exclude':
"minutely,daily", 'appid':openWeatherMap_token}
r = requests.get(openWeather_url, params = params).json()
hourly = r['hourly']Convertir les données en Pandas DataFrame
Ensuite, convertissez les données JSON en Pandas DataFrame. Nous convertissons également l'horodatage d'un horodatage Unix de seconde précision en un objet datetime. Cette conversion est effectuée car la méthode d'écriture InfluxDB nécessite que l'horodatage soit au format objet datetime. Ensuite, nous utiliserons cette méthode pour écrire des données dans InfluxDB. Nous avons également supprimé les colonnes que nous ne voulions pas écrire dans InfluxDB.
python # Convert data to Pandas DataFrame and convert timestamp to datetime object df = pd.json_normalize(hourly) df = df.drop(columns=['weather', 'pop']) df['dt'] = pd.to_datetime(df['dt'], unit='s') print(df.head)
Écrivez le DataFrame Pandas dans InfluxDB
Créez maintenant une instance pour la bibliothèque client Python InfluxDB et écrivez le DataFrame dans InfluxDB. Nous avons précisé le nom de la mesure. Les mesures contiennent des données dans des compartiments. Vous pouvez le considérer comme la structure de deuxième niveau le plus élevé dans l'organisation des données d'InfluxDB après les compartiments.
Vous pouvez également spécifier les colonnes à convertir en balises à l'aide du paramètre data_frame__tag_columns.
Comme nous n'avons spécifié aucune colonne comme étiquettes, toutes nos colonnes seront converties en champs dans InfluxDB. Les balises sont utilisées pour écrire des métadonnées sur vos données de série chronologique, qui peuvent être utilisées pour interroger plus efficacement des sous-ensembles de données. Les champs sont l'endroit où vous stockez les données réelles des séries chronologiques dans InfluxDB. Ce document (https://docs.influxdata.com/influxdb/cloud/reference/key-concepts/?utm_source=vendor&utm_medium=referral&utm_campaign=2022-07_spnsr-ctn_obtaining-storing-ts-pything_tns) entre plus en détail sur ces concepts de données .
on # Write data to InfluxDB with InfluxDBClient(url=url, token=token, org=org) as client: df = df client.write_api(write_options=SYNCHRONOUS).write(bucket=bucket,record=df, data_frame_measurement_name="weather", data_frame_timestamp_column="dt")
Script complet
Pour réviser, pourquoi ne pas jeter un œil au script complet. Nous procédons comme suit :
1. Importez la bibliothèque.
2. Collectez les éléments suivants :
- Seau InfluxDB
- Organisation InfluxDB
- Jeton InfluxDB
- URL InfluxDB
- URL OpenWeatherMap
- Jeton OpenWeatherMap
3. demande.
4. Convertissez la réponse JSON en Pandas DataFrame.
5. Supprimez toutes les colonnes que vous ne souhaitez pas écrire dans InfluxDB.
6. Convertissez la colonne d'horodatage de l'heure Unix en objet datetime Pandas.
7. Créez une instance pour la bibliothèque client Python InfluxDB.
8. Écrivez un DataFrame et spécifiez le nom de la mesure et la colonne d'horodatage.
python
import requests
import influxdb_client
import pandas as pd
from influxdb_client import InfluxDBClient
from influxdb_client.client.write_api import SYNCHRONOUS
bucket = "OpenWeather"
org = "" # or email you used to create your Free Tier
InfluxDB Cloud account
token = "
url = "" # for example,
https://us-west-2-1.aws.cloud2.influxdata.com/
openWeatherMap_token = ""
openWeatherMap_lat = "33.44"
openWeatherMap_lon = "-94.04"
openWeather_url = "https://api.openweathermap.org/data/2.5/onecall"
# Get time series data from OpenWeatherMap API
params = {'lat':openWeatherMap_lat, 'lon':openWeatherMap_lon, 'exclude':
"minutely,daily", 'appid':openWeatherMap_token}
r = requests.get(openWeather_url, params = params).json()
hourly = r['hourly']
# Convert data to Pandas DataFrame and convert timestamp to datetime
object
df = pd.json_normalize(hourly)
df = df.drop(columns=['weather', 'pop'])
df['dt'] = pd.to_datetime(df['dt'], unit='s')
print(df.head)
# Write data to InfluxDB
with InfluxDBClient(url=url, token=token, org=org) as client:
df = df
client.write_api(write_options=SYNCHRONOUS).write(bucket=bucket,record=df,
data_frame_measurement_name="weather",
data_frame_timestamp_column="dt")Requête de données
Maintenant que nous avons écrit les données dans InfluxDB, nous pouvons utiliser l'interface utilisateur d'InfluxDB pour interroger les données. Accédez à Data Explorer (à partir de la barre de navigation de gauche). À l’aide de Query Builder, sélectionnez les données que vous souhaitez visualiser et la plage que vous souhaitez visualiser, puis cliquez sur Soumettre.
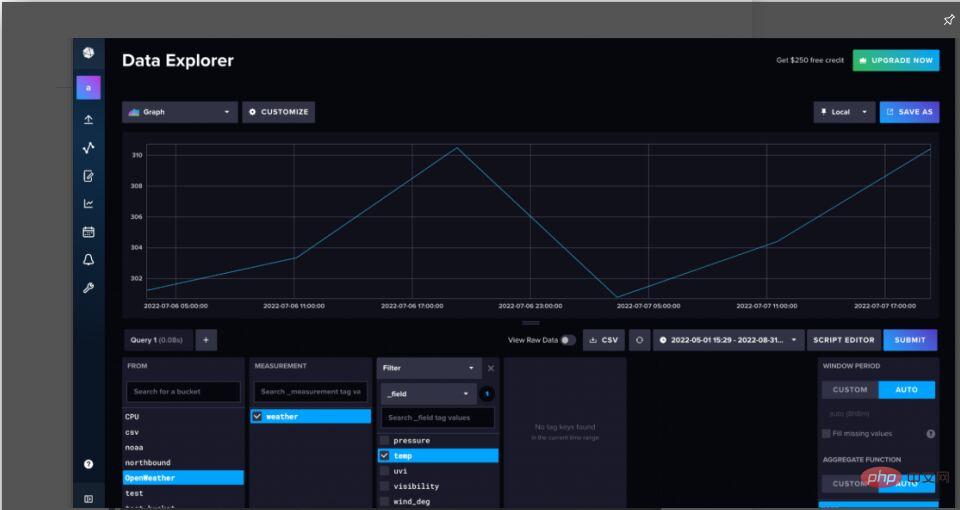
Figure 1. Vue matérialisée par défaut des données météorologiques. InfluxDB agrège automatiquement les données de séries chronologiques afin que les nouveaux utilisateurs n'interrogent pas accidentellement trop de données et ne provoquent des délais d'attente.
Conseil de pro : lorsque vous interrogez des données à l'aide du générateur de requêtes, InfluxDB sous-échantillonne automatiquement les données. Pour interroger des données brutes, accédez à l'éditeur de script pour afficher la requête Flux sous-jacente. Flux est un langage de requête et de script natif pour InfluxDB qui peut être utilisé pour analyser et créer des prédictions à l'aide de vos données de séries chronologiques. Utilisez la fonction AggregateWindow() pour décommenter ou supprimer des lignes afin de voir les données d'origine.
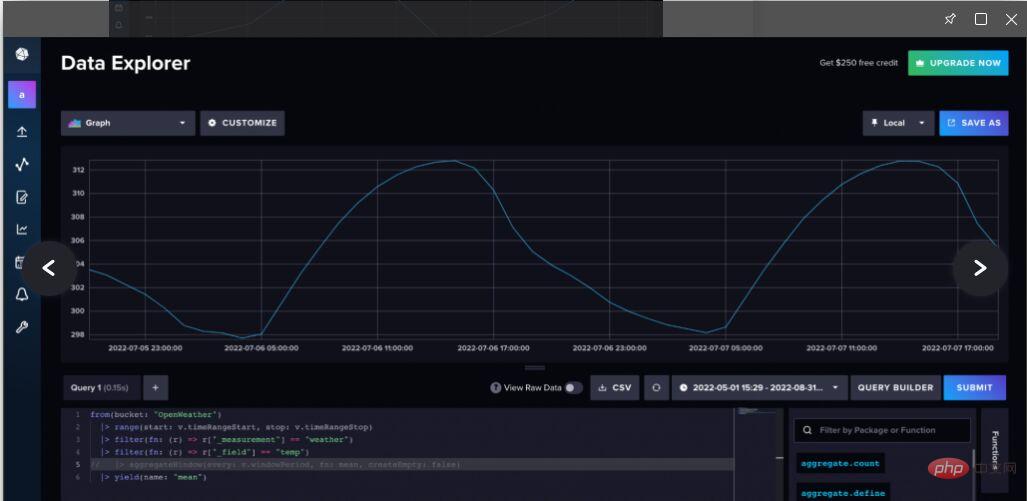
Figure 2. Accédez à l'éditeur de script et décommentez ou supprimez la fonction AggregateWindow() pour afficher les données météorologiques brutes
Conclusion
J'espère que cet article pourra vous aider à utiliser pleinement la bibliothèque client Python InfluxDB pour obtenir des données de séries chronologiques et stockez-le dans InfluxDB. Si vous souhaitez en savoir plus sur l'utilisation de la bibliothèque client Python pour interroger les données d'InfluxDB, je vous recommande de jeter un œil à cet article (https://thenewstack.io/getting-started-with-python-and-influxdb/). Il convient également de mentionner que vous pouvez utiliser Flux pour obtenir des données de l'API OpenWeatherMap et les stocker dans InfluxDB. Si vous utilisez InfluxDB Cloud, cela signifie que le script Flux sera hébergé et exécuté périodiquement, afin que vous puissiez obtenir un flux fiable de données météorologiques introduit dans l'instance. Pour en savoir plus sur la façon d'utiliser Flux pour obtenir des données météorologiques selon un calendrier défini par l'utilisateur, veuillez lire cet article (https://www.influxdata.com/blog/tldr-influxdb-tech-tips-handling-json-objects- mapping-arrays/?utm_source=vendor&utm_medium=referral&utm_campaign=2022-07_spnsr-ctn_obtaining-storing-ts-pything_tns).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment résoudre le problème des autorisations rencontré lors de la visualisation de la version Python dans le terminal Linux?
Apr 01, 2025 pm 05:09 PM
Comment résoudre le problème des autorisations rencontré lors de la visualisation de la version Python dans le terminal Linux?
Apr 01, 2025 pm 05:09 PM
Solution aux problèmes d'autorisation Lors de la visualisation de la version Python dans Linux Terminal Lorsque vous essayez d'afficher la version Python dans Linux Terminal, entrez Python ...
 Comment copier efficacement la colonne entière d'une dataframe dans une autre dataframe avec différentes structures dans Python?
Apr 01, 2025 pm 11:15 PM
Comment copier efficacement la colonne entière d'une dataframe dans une autre dataframe avec différentes structures dans Python?
Apr 01, 2025 pm 11:15 PM
Lorsque vous utilisez la bibliothèque Pandas de Python, comment copier des colonnes entières entre deux frames de données avec différentes structures est un problème courant. Supposons que nous ayons deux dats ...
 Pourquoi mon code ne peut-il pas faire renvoyer les données par l'API? Comment résoudre ce problème?
Apr 01, 2025 pm 08:09 PM
Pourquoi mon code ne peut-il pas faire renvoyer les données par l'API? Comment résoudre ce problème?
Apr 01, 2025 pm 08:09 PM
Pourquoi mon code ne peut-il pas faire renvoyer les données par l'API? En programmation, nous rencontrons souvent le problème du retour des valeurs nulles lorsque l'API appelle, ce qui n'est pas seulement déroutant ...
 Les annotations des paramètres Python peuvent-elles utiliser des chaînes?
Apr 01, 2025 pm 08:39 PM
Les annotations des paramètres Python peuvent-elles utiliser des chaînes?
Apr 01, 2025 pm 08:39 PM
Utilisation alternative des annotations des paramètres Python Dans la programmation Python, les annotations des paramètres sont une fonction très utile qui peut aider les développeurs à mieux comprendre et utiliser les fonctions ...
 Comment les scripts Python effacent-ils la sortie en position de curseur à un emplacement spécifique?
Apr 01, 2025 pm 11:30 PM
Comment les scripts Python effacent-ils la sortie en position de curseur à un emplacement spécifique?
Apr 01, 2025 pm 11:30 PM
Comment les scripts Python effacent-ils la sortie en position de curseur à un emplacement spécifique? Lors de l'écriture de scripts Python, il est courant d'effacer la sortie précédente à la position du curseur ...
 Python multiplateform de bureau de bureau de bureau: quelle bibliothèque GUI est la meilleure pour vous?
Apr 01, 2025 pm 05:24 PM
Python multiplateform de bureau de bureau de bureau: quelle bibliothèque GUI est la meilleure pour vous?
Apr 01, 2025 pm 05:24 PM
Choix de la bibliothèque de développement d'applications de bureau multiplateforme Python De nombreux développeurs Python souhaitent développer des applications de bureau pouvant s'exécuter sur Windows et Linux Systems ...
 Dessin graphique de sablier Python: comment éviter les erreurs variables non définies?
Apr 01, 2025 pm 06:27 PM
Dessin graphique de sablier Python: comment éviter les erreurs variables non définies?
Apr 01, 2025 pm 06:27 PM
Précision avec Python: Source de sablier Dessin graphique et vérification d'entrée Cet article résoudra le problème de définition variable rencontré par un novice Python dans le programme de dessin graphique de sablier. Code...
 Comment compter et trier efficacement de grands ensembles de données de produit dans Python?
Apr 01, 2025 pm 08:03 PM
Comment compter et trier efficacement de grands ensembles de données de produit dans Python?
Apr 01, 2025 pm 08:03 PM
Conversion et statistiques de données: traitement efficace des grands ensembles de données Cet article introduira en détail comment convertir une liste de données contenant des informations sur le produit en une autre contenant ...
