

GPT-3 : une intelligence artificielle capable d'écrire

Traducteur | Cui Hao
Critique | Sun Shujuan
Ouverture
Bien que l'intelligence artificielle (IA) en soit à ses premiers stades de développement, elle a le potentiel de révolutionner la façon dont les humains interagissent avec la technologie.
Introduction à l'intelligence artificielle
En matière d'intelligence artificielle, il existe actuellement deux points de vue principaux. Certains pensent que l’IA finira par dépasser l’intelligence humaine, tandis que d’autres pensent qu’elle servira toujours l’humanité. Il y a un point sur lequel les deux parties peuvent s’entendre : l’intelligence artificielle se développe à un rythme toujours plus rapide.
L'intelligence artificielle (IA) en est encore à ses premiers stades de développement, mais elle a le potentiel de révolutionner la façon dont les humains interagissent avec la technologie.
Une description simple et générale est que l'intelligence artificielle est le processus de programmation des ordinateurs pour qu'ils prennent des décisions par eux-mêmes. Cela peut être réalisé de différentes manières, mais le plus souvent grâce à l’utilisation d’algorithmes. Un algorithme est un ensemble de règles ou d’instructions qui peuvent être suivies pour résoudre un problème. Dans le cas de l’intelligence artificielle, les algorithmes sont utilisés pour apprendre aux ordinateurs à prendre des décisions.
Dans le passé, l'intelligence artificielle était principalement utilisée pour des tâches simples comme jouer aux échecs ou résoudre des problèmes mathématiques. Aujourd’hui, l’intelligence artificielle est utilisée pour des tâches plus complexes telles que la reconnaissance faciale, le traitement du langage naturel et même la conduite autonome. Alors que l’intelligence artificielle continue de se développer, nous ne savons pas quelles seront ses capacités à l’avenir. À mesure que les capacités de l’IA se développent rapidement, il est important de comprendre de quoi il s’agit, comment elle fonctionne et son impact potentiel.
Les bénéfices apportés par l'intelligence artificielle sont énormes. Avec la capacité de prendre des décisions par elle-même, l’IA a le potentiel de rendre d’innombrables secteurs plus efficaces et d’offrir des opportunités à tous les types de personnes. Dans cet article, nous parlerons de GPT-3.
Qu'est-ce que GPT-3 et d'où vient-il ?
GPT-3 a été créé par OpenAI, une société pionnière de recherche en IA basée à San Francisco. Ils définissent leur objectif comme « garantir que l’intelligence artificielle profite à toute l’humanité ». Leur vision de la création d’une intelligence artificielle est claire : une intelligence artificielle qui ne se limite pas à des tâches spécialisées, mais peut effectuer une variété de tâches comme les humains.
Il y a quelques mois, la société OpenAI a publié son nouveau modèle de langage appelé GPT-3 à tous les utilisateurs. GPT-3 est l'abréviation de Generative Pretrained Transformer 3, qui inclut la possibilité de générer du texte via un principe appelé Prompt. En termes simples, il possède des capacités de « saisie semi-automatique » de haut niveau. Par exemple, il vous suffit de fournir deux ou trois phrases sur un sujet donné, et GPT-3 fera le reste. Vous pouvez également générer des conversations, et les réponses données par GPT-3 seront basées sur le contexte des questions et réponses précédentes.
Il convient de souligner que chaque réponse fournie par GPT-3 n'est qu'une possibilité, ce ne sera donc pas la seule réponse possible. De plus, si vous testez plusieurs fois la même prémisse, elle peut fournir une réponse différente, voire contradictoire. C'est donc un modèle qui renvoie une réponse basée sur ce qui a été dit précédemment et qui la relie à tout ce que vous savez pour obtenir la réponse la plus raisonnable. Cela signifie qu’il n’est pas obligé de donner une réponse avec des données réelles, ce dont nous devons tenir compte. Cela ne signifie pas que les utilisateurs ne peuvent pas divulguer des données professionnelles pertinentes, mais GPT-3 doit comparer ces données avec des informations contextuelles. Plus le contexte est complet, plus la réponse que vous obtiendrez sera raisonnable, et vice versa.
Le modèle de langage GPT-3 d'OpenAI est pré-entraîné et la formation comprend l'étude de grandes quantités d'informations sur Internet. GPT-3 est intégré à tous les livres accessibles au public, à l'intégralité du contenu de Wikipédia et à des millions de pages Web et d'articles scientifiques sur Internet. En bref, il intègre les connaissances humaines les plus importantes que nous ayons publiées sur le Web au cours de l’histoire.
Après avoir lu et analysé ces informations, le modèle de langage crée des connexions dans le modèle 700 Go implanté sur 48 GPU de 16 Go. Pour nous permettre de comprendre cette dimension, le précédent modèle OpenAI, le modèle GPT-2, mesurait 40 Go et analysait 45 millions de pages Web. La différence est énorme, car GPT-2 possède 1,5 milliard de paramètres, tandis que GPT-3 en possède 175 milliards.
On fait un test ? J'ai demandé à GPT-3 comment il se définit, et voici le résultat :

Comment utiliser GPT-3
Pour pouvoir utiliser GPT-3 et le tester, la seule chose que nous devons faire est d'aller sur leur site Web, de nous inscrire et d'ajouter des informations personnelles. Au cours du processus, il vous sera demandé : Pourquoi utiliserez-vous l’intelligence artificielle ? Pour ces exemples, j’ai choisi l’option « Utilisation personnelle ».
Je tiens à souligner que d'après mon expérience cela fonctionne mieux dans un contexte anglais. Cela ne veut pas dire que cela ne fonctionne pas bien dans d'autres langues ; en fait, en espagnol, cela fonctionne très bien, mais je préfère les résultats qu'il donne en anglais, c'est pourquoi à partir de maintenant j'affiche les tests et les résultats. En anglais.
GPT-3 nous a offert un cadeau gratuit lors de notre entrée. Une fois inscrit avec votre e-mail et votre numéro de téléphone, vous disposerez de 18 $ à utiliser entièrement gratuitement, sans avoir besoin de saisir un mode de paiement. Même si cela ne semble pas beaucoup, en fait, 18 $, c'est beaucoup. Pour vous donner une idée, je teste l'IA depuis cinq heures et cela ne m'a coûté que 1 $. Plus tard, j'expliquerai les prix afin que nous puissions mieux comprendre cela.
Une fois que nous entrerons sur le site Web, nous devrons nous rendre dans la section Playground. C'est là que toute la magie opère.
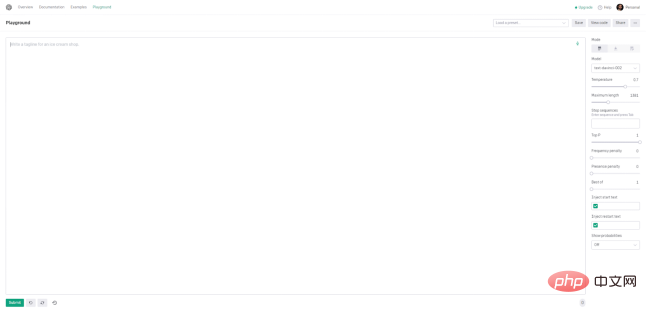
Prompt+Submit
Tout d'abord, la chose la plus accrocheuse en ligne est la grande zone de texte. C'est ici que nous pouvons commencer à saisir des invites dans l'IA (rappelez-vous, ce sont nos demandes et/ou instructions). C'est aussi simple que de saisir quelque chose, dans ce cas une question, et de cliquer sur le bouton Soumettre ci-dessous pour laisser GPT-3 nous répondre et écrire ce que nous avons demandé.

Presets
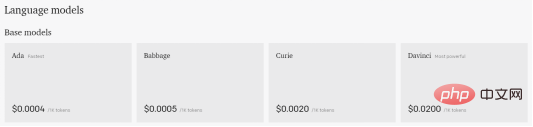
Les presets sont des fonctions qui peuvent être exécutées à tout moment pour différentes tâches. Ils se trouvent dans le coin supérieur droit de la zone de texte. Si nous cliquons sur plusieurs d'entre eux, "Plus d'exemples" ouvrira un nouvel écran où nous aurons toute la liste disponible. Lorsqu'un préréglage est sélectionné, le contenu de la zone de texte est mis à jour avec le texte par défaut. Les paramètres dans la barre latérale droite seront également mis à jour. Par exemple, si nous souhaitons utiliser le préréglage « Correction grammaticale », nous devons suivre la structure suivante pour de meilleurs résultats. Les ensembles de données massifs utilisés pour entraîner GPT-3 sont les principales raisons pour lesquelles GPT-3 est si puissant. Cependant, plus grand ne signifie pas toujours meilleur. Pour ces raisons, OpenAI propose quatre modèles principaux. Il existe bien sûr d'autres modèles, mais il nous serait conseillé d'utiliser la dernière version, celle que nous utilisons actuellement.

Nous fournirons un aperçu du modèle et des types de tâches auxquelles le modèle est adapté. Gardez à l’esprit que même si les moteurs plus petits n’ont peut-être pas été entraînés sur autant de données, ils restent des modèles à usage général très réalisables et pratiques pour certaines tâches.
Davinci
Comme mentionné ci-dessus, c'est le modèle le plus performant et peut faire tout ce que tout autre modèle peut faire, généralement avec moins d'instructions. Léonard de Vinci était capable de résoudre des problèmes logiques, de déterminer les relations de cause à effet, de comprendre l'intention textuelle, de produire du contenu créatif, d'expliquer les motivations des personnages et de gérer des tâches de synthèse complexes.Curie
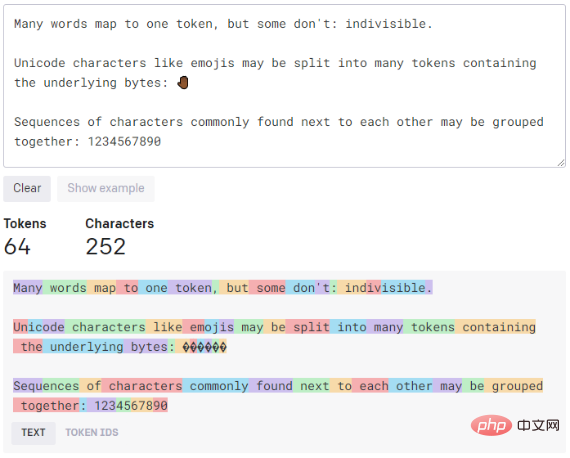
Ce modèle tente d'équilibrer la puissance et la vitesse de calcul. Il peut faire tout ce que Ada ou Babbage peuvent faire, mais il peut également gérer des tâches de classification plus complexes et des tâches plus nuancées telles que la synthèse, l'analyse des sentiments, les applications de chatbot et les questions et réponses.Il est légèrement plus puissant qu'Ada, mais pas aussi efficace. Il peut effectuer toutes les mêmes tâches qu'Ada, mais peut également gérer des tâches de classification légèrement plus complexes, ce qui le rend idéal pour les tâches de recherche sémantique qui classent dans quelle mesure un document correspond à une requête de recherche. Enfin, c'est généralement le modèle le plus rapide et le moins cher. Il est mieux adapté aux tâches moins nuancées, telles que l’analyse du texte, le reformatage du texte et les tâches de classification plus simples. Plus vous fournissez de contexte à Ada, meilleures sont ses performances. Les modèles sont d'autres paramètres que nous pouvons ajuster pour obtenir la meilleure réponse à nos signaux. L'un des paramètres les plus importants qui contrôlent la puissance du moteur GPT-3 est la température. Ce paramètre contrôle le caractère aléatoire du texte généré. À la valeur 0, le moteur est déterministe, ce qui signifie que pour une saisie de texte donnée, il produira toujours la même sortie. A la valeur 1, le moteur prend le plus de risques et fait preuve de beaucoup de créativité. Vous avez peut-être remarqué que dans certains des tests que vous pouviez exécuter vous-même, GPT-3 s'arrêtait au milieu d'une phrase. Pour contrôler la quantité maximale de texte que nous autorisons à générer, vous pouvez utiliser le paramètre "max-length" spécifié dans les jetons. Nous expliquerons ce qu'est ce jeton plus tard. Le paramètre "Top P" peut contrôler le caractère aléatoire et la créativité du texte GPT-3, mais dans ce cas, il est lié au jeton (mot) dans la plage de probabilité, selon l'endroit où nous le plaçons ( 0,1 sera 10 %). La documentation OpenAI recommande d'utiliser une seule fonction entre Temperature et Top P, donc lorsque vous en utilisez une, assurez-vous que l'autre est définie sur 1. En revanche, nous avons deux paramètres pour pénaliser la réponse donnée par GPT-3. L’un d’eux est la « pénalité de fréquence », qui contrôle la tendance du modèle à faire des prédictions répétées. Cela réduit également la probabilité qu'un mot ait été généré et dépend du nombre de fois qu'un mot est apparu dans la prédiction. La deuxième pénalité est la pénalité d'existence. La présence d'un paramètre de pénalité incite le modèle à faire de nouvelles prédictions. Si un mot est déjà apparu dans le texte prédit, une pénalité réduit la probabilité de l’apparition de ce mot. Contrairement à la pénalité de fréquence, la pénalité de présence ne dépend pas de la fréquence à laquelle le mot est apparu dans les prédictions passées. Enfin, nous avons un paramètre "meilleur" qui produit plusieurs réponses à une requête. Playground choisira le meilleur pour nous répondre. GPT-3 avertira que plusieurs réponses complètes à l'invite entraîneront une dépense supplémentaire de jetons. Pour compléter cette section, la troisième icône à côté du bouton "Envoyer" affichera toutes nos demandes historiques pour GPT-3. Vous trouverez ici les invites pour les réponses les plus performantes. Une fois le crédit gratuit de 18 $ épuisé, GPT-3 offre également un moyen de continuer à utiliser sa plateforme qui n'est pas un abonnement mensuel ou quelque chose du genre. Le prix sera directement lié à l'utilisation. En d’autres termes, vous êtes facturé en fonction du token. Il s'agit d'un terme utilisé pour l'intelligence artificielle, où les jetons sont liés au coût de production. Un jeton peut être n’importe quoi, d’une lettre à une phrase. Il est donc difficile de savoir exactement combien coûtera chaque utilisation de l’IA. Mais étant donné qu'ils coûtent généralement quelques centimes par dollar, il ne faut pas longtemps pour voir combien tout coûte avec juste un peu d'expérimentation. Bien qu'OpenAI ne nous montre qu'une douzaine d'exemples d'utilisation de GPT-3, nous pouvons voir les jetons dépensés pour chaque exemple pour mieux comprendre son fonctionnement. Voici les versions et leurs prix respectifs. Pour nous donner une idée de combien peut coûter un certain nombre de mots, ou nous donner un exemple du fonctionnement de la tokenisation, nous disposons de l'outil suivant, appelé Tokenizer. Cela nous indique que la série de modèles GPT traite le texte à l'aide de jetons, qui sont des séquences courantes de caractères trouvées dans le texte. Le modèle comprend la relation statistique entre les jetons et est sélectionné lorsque le jeton suivant est utilisé dans la séquence de production. Enfin, voici un exemple de bas niveau de combien le même exemple nous coûterait. De mon point de vue, GPT-3 est un outil que les utilisateurs doivent savoir utiliser correctement, GPT-3 ne donne pas forcément des données correctes. Cela signifie que si vous souhaitez l'utiliser pour travailler, répondre à des questions ou faire vos devoirs, vous devez fournir un bon contexte pour les réponses qu'il vous donne afin d'être proche des résultats souhaités. Certaines personnes s'inquiètent de savoir si le GPT-3 changera l'éducation ou si certains emplois liés à l'écriture qui existent aujourd'hui disparaîtront à cause de cela. À mon humble avis, cela va se produire. Tôt ou tard, nous serons tous remplacés par l’intelligence artificielle. Cet exemple concerne l'intelligence artificielle liée à l'écriture, mais elles existent en programmation, en peinture, en audio, etc. D'un autre côté, cela ouvre plus de possibilités pour de très nombreux emplois et projets, tant personnels que professionnels. Par exemple, avez-vous déjà eu envie d’écrire une histoire d’horreur ? Cette fonction peut être spécifiquement implémentée dans la liste d'exemples du vérificateur grammatical. Cela dit, ce que je veux dire, c'est que nous en sommes à la première version de l'intelligence artificielle. Il existe encore de nombreux produits dans ce monde qui doivent grandir et être améliorés, mais cela ne veut pas dire cela. ils n'ont pas été mis en œuvre. Tant que nous apprenons et utilisons l’intelligence artificielle, nous devons continuer à la former pour qu’elle donne la meilleure réponse possible. Cui Hao, rédacteur en chef de la communauté 51CTO, architecte senior, a 18 ans d'expérience en développement de logiciels et en architecture, et 10 ans d'expérience en architecture distribuée. Titre original : GPT-3 Playground : L'IA qui peut écrire pour vous, auteur : Isaac Alvarez Babbage
Ada
Moteur
Historique
Frais et jetons
Conclusion
Introduction du traducteur
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1205
24
52
1205
24

 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
 SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
Selon les informations de ce site le 1er août, SK Hynix a publié un article de blog aujourd'hui (1er août), annonçant sa participation au Global Semiconductor Memory Summit FMS2024 qui se tiendra à Santa Clara, Californie, États-Unis, du 6 au 8 août, présentant de nombreuses nouvelles technologies de produit. Introduction au Future Memory and Storage Summit (FutureMemoryandStorage), anciennement Flash Memory Summit (FlashMemorySummit) principalement destiné aux fournisseurs de NAND, dans le contexte de l'attention croissante portée à la technologie de l'intelligence artificielle, cette année a été rebaptisée Future Memory and Storage Summit (FutureMemoryandStorage) pour invitez les fournisseurs de DRAM et de stockage et bien d’autres joueurs. Nouveau produit SK hynix lancé l'année dernière
