


Bonjour à tous, je suis M. Zhanshu !
Comme le dit le proverbe : ne serait-il pas formidable d’avoir des amis venus de loin ? C'est une chose très heureuse d'avoir des amis qui viennent jouer avec nous, nous devons donc faire de notre mieux pour être propriétaires et emmener nos amis jouer ! La question est donc de savoir quel est le meilleur moment, où aller et quel est l’endroit le plus amusant ?
Aujourd'hui, je vais vous apprendre étape par étape comment utiliser le pool de fils de discussion pour explorer les informations sur les attractions et examiner les données du même voyage et créer un nuage de mots et une visualisation de données ! ! ! Informez-vous des informations sur les attractions touristiques de différentes villes.
Avant de commencer à explorer les données, commençons par comprendre les fils de discussion.
Processus : un processus est une activité de code en cours d'exécution sur une collection de données et constitue l'unité de base de l'allocation des ressources et de la planification dans le système.
Thread : Il s'agit d'un processus léger, de la plus petite unité d'exécution de programme et d'un chemin d'exécution du processus.
Il y a au moins un thread dans un processus, et plusieurs threads dans le processus partagent les ressources du processus.
Avant de créer des multi-threads, apprenons d'abord le cycle de vie des threads, comme le montre la figure ci-dessous :
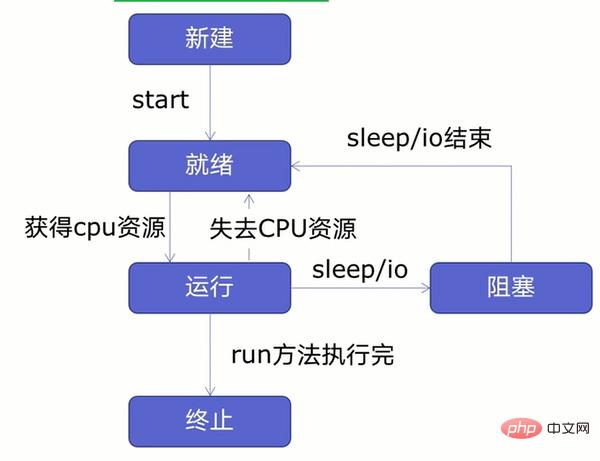
Comme le montre la figure, les threads peuvent être divisés en cinq états - Nouveau, Prêt et En cours d'exécution, blocage, résiliation.
Créez d'abord un nouveau thread et démarrez le thread. Une fois que le thread est entré dans l'état prêt, le thread dans l'état prêt ne s'exécutera pas immédiatement. Il n'entrera dans l'état d'exécution qu'après avoir obtenu les ressources CPU. Le thread peut perdre des ressources CPU ou rencontrer des problèmes. Lors des opérations de veille ou d'E/S (lecture, écriture, etc.), le thread entre dans l'état prêt ou bloqué. Il n'entrera pas dans l'état d'exécution tant que la veille, l'opération d'E/S n'est pas terminée ou que les ressources du CPU ne sont pas disponibles. récupéré. Il entrera dans l’état terminé après l’exécution.
Remarque : la création d'un nouveau système de threads nécessite l'allocation de ressources, et la terminaison du système de threads nécessite le recyclage des ressources. Alors, comment réduire la surcharge système liée à la création/termination des threads ? À ce stade, nous pouvons créer un pool de threads pour réutiliser les threads, donc ? que nous pouvons réduire les frais généraux du système.
Avant de créer un pool de threads, apprenons d'abord à créer des multi-threads.
La création de multi-threads peut être divisée en quatre étapes :
import requests
urls=[
f'https://www.cnblogs.com/#p{page}'
for page in range(1,50)
]
def get_parse(url):
response=requests.get(url)
print(url,len(response.text))Créer des fils de discussion
Dans l'étape précédente, nous avons créé la fonction d'exploration, puis nous créerons des fils de discussion. Le code spécifique est le suivant :import threading #多线程 def multi_thread(): threads=[] for url in urls: threads.append( threading.Thread(target=get_parse,args=(url,)) )
target est la fonction en cours d'exécution ;
args sont les paramètres requis pour exécuter la fonction.
Notez que les paramètres dans args doivent être transmis sous forme de tuples, puis ajoutez le thread à la liste vide des threads via la méthode .append().for thread in threads: thread.start()
En attendant la fin
Après avoir démarré le fil, vous attendrez que le fil se termine. Le code spécifique est le suivant :for thread in threads: thread.join()
Le multi-threading a été créé. Ensuite, nous allons tester la vitesse du multi-threading. Le code spécifique est le suivant :
if __name__ == '__main__': t1=time.time() multi_thread() t2=time.time() print(t2-t1)
Multi-threading crawls 50 blog. garer des pages Web Cela ne prend que plus d'une seconde et l'URL de la requête réseau multithread est aléatoire.
Testons le temps d'exécution d'un seul thread. Le code spécifique est le suivant :
if __name__ == '__main__': t1=time.time() for i in urls: get_parse(i) t2=time.time() print(t2-t1)
Les résultats d'exécution sont présentés dans la figure ci-dessous : 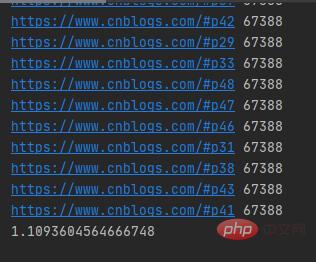
Il a fallu plus de 9 secondes pour explorer 50 blogs de jardin Web. pages avec un seul fil de discussion. Les URL d’envoi des requêtes réseau sont séquentielles.
Comme nous l'avons dit ci-dessus, la création d'un nouveau système de threads nécessite l'allocation de ressources, et la terminaison du système de threads nécessite le recyclage des ressources. Afin de réduire la surcharge du système, nous pouvons créer un pool de threads.
一个线程池由两部分组成,如下图所示:
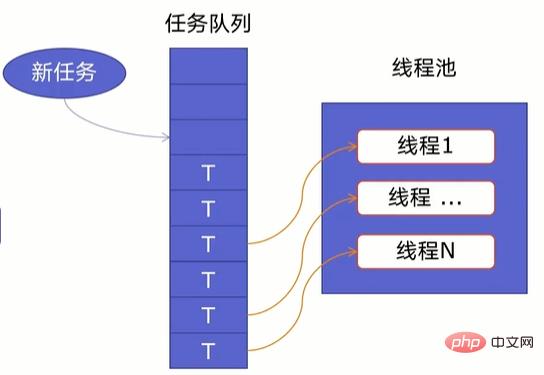
当任务队列里有任务时,线程池的线程会从任务队列中取出任务并执行,执行完任务后,线程会执行下一个任务,直到没有任务执行后,线程会回到线程池中等待任务。
使用线程池可以处理突发性大量请求或需要大量线程完成任务(处理时间较短的任务)。
好了,了解了线程池原理后,我们开始创建线程池。
Python提供了ThreadPoolExecutor类来创建线程池,其语法如下所示:
ThreadPoolExecutor(max_workers=None, thread_name_prefix='', initializer=None, initargs=())
其中:
注意:在启动 max_workers 个工作线程之前也会重用空闲的工作线程。
在ThreadPoolExecutor类中提供了map()和submit()函数来插入任务队列。其中:
map()函数
map()语法格式为:
map(调用方法,参数队列)
具体示例如下所示:
import requestsimport concurrent.futuresimport timeurls=[f'https://www.cnblogs.com/#p{page}'for page in range(1,50)]def get_parse(url):response=requests.get(url)return response.textdef map_pool():with concurrent.futures.ThreadPoolExecutor(max_workers=20) as pool:htmls=pool.map(get_parse,urls)htmls=list(zip(urls,htmls))for url,html in htmls:print(url,len(html))if __name__ == '__main__':t1=time.time()map_pool()t2=time.time()print(t2-t1)首先我们导入requests网络请求库、concurrent.futures模块,把所有的URL放在urls列表中,然后自定义get_parse()方法来返回网络请求返回的数据,再自定义map_pool()方法来创建代理池,其中代理池的最大max_workers为20,调用map()方法把网络请求任务放在任务队列中,在把返回的数据和URL合并为元组,并放在htmls列表中。
运行结果如下图所示:
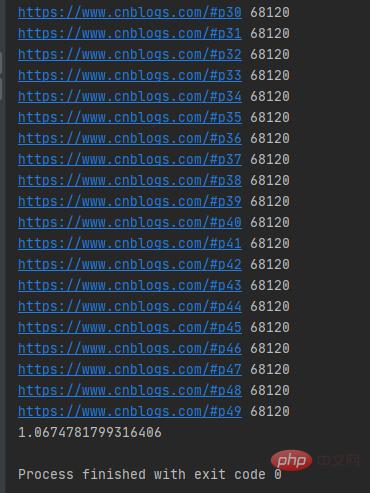
可以发现map()函数返回的结果和传入的参数顺序是对应的。
注意:当我们直接在自定义方法get_parse()中打印结果时,打印结果是乱序的。
submit()函数
submit()函数语法格式如下:
submit(调用方法,参数)
具体示例如下:
def submit_pool():with concurrent.futures.ThreadPoolExecutor(max_workers=20)as pool:futuress=[pool.submit(get_parse,url)for url in urls]futures=zip(urls,futuress)for url,future in futures:print(url,len(future.result()))
运行结果如下图所示:
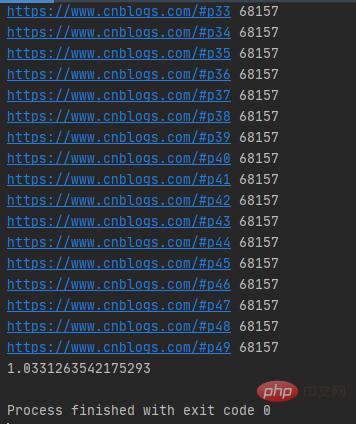
注意:submit()函数输出结果需需要调用result()方法。
好了,线程知识就学到这里了,接下来开始我们的爬虫。
首先我们进入同程旅行的景点网页并打开开发者工具,如下图所示:
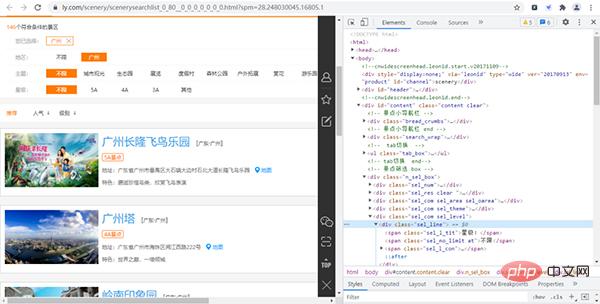
经过寻找,我们发现各个景点的基础信息(详情页URL、景点id等)都存放在下图的URL链接中,
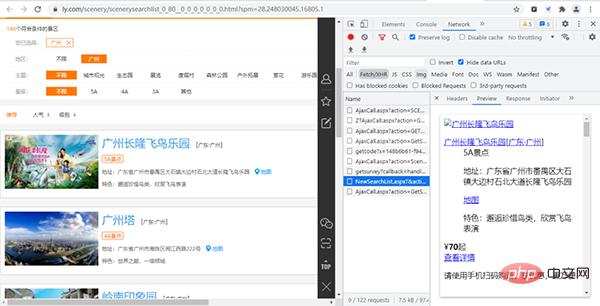
其URL链接为:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=2&kw=&pid=6&cid=80&cyid=0&sort=&isnow=0&spType=&lbtypes=&IsNJL=0&classify=0&grade=&dctrack=1%CB%871629537670551030%CB%8720%CB%873%CB%872557287248299209%CB%870&iid=0.6901326566387387
经过增删改查操作,我们可以把该URL简化为:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=1&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0
其中page为我们翻页的重要参数。
打开该URL链接,如下图所示:
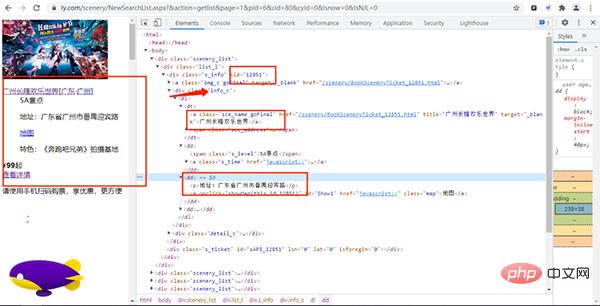
通过上面的URL链接,我们可以获取到很多景点的基础信息,随机打开一个景点的详情网页并打开开发者模式,经过查找,评论数据存放在如下图的URL链接中,
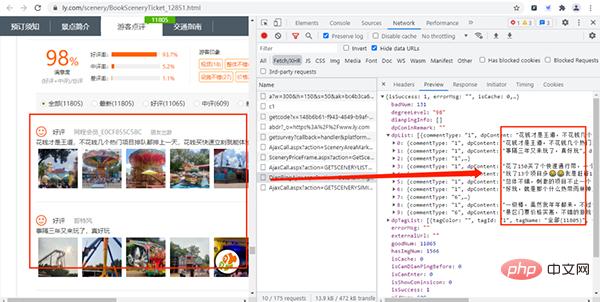
其URL链接如下所示:
https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid=12851&page=1&pageSize=10&labId=1&sort=0&iid=0.48901069375088
其中:action、labId、iid、sort为常量,sid是景点的id,page控制翻页,pageSize是每页获取的数据量。
在上上步中,我们知道景点id的存放位置,那么构造评论数据的URL就很简单了。
这次我们爬虫步骤是:
首先我们先获取景点的名字、id、价格、特色、地点和等级,主要代码如下所示:
def get_parse(url):response=requests.get(url,headers=headers)Xpath=parsel.Selector(response.text)data=Xpath.xpath('/html/body/div')for i in data:Scenery_data={'title':i.xpath('./div/div[1]/div[1]/dl/dt/a/text()').extract_first(),'sid':i.xpath('//div[@]/div/@sid').extract_first(),'Grade':i.xpath('./div/div[1]/div[1]/dl/dd[1]/span/text()').extract_first(), 'Detailed_address':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:',''),'characteristic':i.xpath('./div/div[1]/div[1]/dl/dd[3]/p/text()').extract_first(),'price':i.xpath('./div/div[1]/div[2]/div[1]/span/b/text()').extract_first(),'place':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:','')[6:8]}首先自定义方法get_parse()来发送网络请求后使用parsel.Selector()方法来解析响应的文本数据,然后通过xpath来获取数据。
获取景点基本信息后,接下来通过景点基本信息中的sid来构造评论信息的URL链接,主要代码如下所示:
def get_data(Scenery_data):for i in range(1,3):link = f'https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid={Scenery_data["sid"]}&page={i}&pageSize=100&labId=1&sort=0&iid=0.20105777381446832'response=requests.get(link,headers=headers)Json=response.json()commtent_detailed=Json.get('dpList')# 有评论数据if commtent_detailed!=None:for i in commtent_detailed:Comment_information={'dptitle':Scenery_data['title'],'dpContent':i.get('dpContent'),'dpDate':i.get('dpDate')[5:7],'lineAccess':i.get('lineAccess')}#没有评论数据elif commtent_detailed==None:Comment_information={'dptitle':Scenery_data['title'],'dpContent':'没有评论','dpDate':'没有评论','lineAccess':'没有评论'}首先自定义方法get_data()并传入刚才获取的景点基础信息数据,然后通过景点基础信息的sid来构造评论数据的URL链接,当在构造评论数据的URL时,需要设置pageSize和page这两个变量来获取多条评论和进行翻页,构造URL链接后就发送网络请求。
这里需要注意的是:有些景点是没有评论,所以我们需要通过if语句来进行设置。
这次我们把数据存放在MySQL数据库中,由于数据比较多,所以我们把数据分为两种数据表,一种是景点基础信息表,一种是景点评论数据表,主要代码如下所示:
#创建数据库def create_db():db=pymysql.connect(host=host,user=user,passwd=passwd,port=port)cursor=db.cursor()sql='create database if not exists commtent default character set utf8'cursor.execute(sql)db.close()create_table()#创建景点信息数据表def create_table():db=pymysql.connect(host=host,user=user,passwd=passwd,port=port,db='commtent')cursor=db.cursor()sql = 'create table if not exists Scenic_spot_data (title varchar(255) not null, link varchar(255) not null,Grade varchar(255) not null, Detailed_address varchar(255) not null, characteristic varchar(255)not null, price int not null, place varchar(255) not null)'cursor.execute(sql)db.close()
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,然后关闭数据库连接,最后调用自定义方法create_table()来创建景点信息数据表。
这里我们只给出了创建景点信息数据表的代码,因为创建数据表只是sql这条语句稍微有点不同,其他都一样,大家可以参考这代码来创建各个景点评论数据表。
创建好数据库和数据表后,接下来就要保存数据了,主要代码如下所示:
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,使用了try-except语句,当保存的数据不成功,就调用rollback()方法,撤消当前事务中所做的所有更改,并释放此连接对象当前使用的任何数据库锁。
#保存景点数据到景点数据表中def saving_scenery_data(srr):db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='commtent')cursor = db.cursor()sql = 'insert into Scenic_spot_data(title, link, Grade, Detailed_address, characteristic,price,place) values(%s,%s,%s,%s,%s,%s,%s)'try:cursor.execute(sql, srr)db.commit()except:db.rollback()db.close()
注意:srr是传入的景点信息数据。
好了,单线程爬虫已经写好了,接下来将创建一个函数来创建我们的线程池,使单线程爬虫变为多线程,主要代码如下所示:
urls = [f'https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page={i}&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0'for i in range(1, 6)]def multi_thread():with concurrent.futures.ThreadPoolExecutor(max_workers=8)as pool:h=pool.map(get_parse,urls)if __name__ == '__main__':create_db()multi_thread()创建线程池的代码很简单就一个with语句和调用map()方法
运行结果如下图所示:
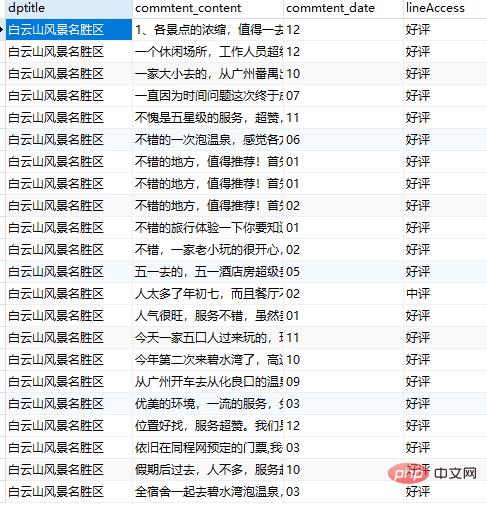
好了,数据已经获取到了,接下来将进行数据分析。
首先我们来分析一下各个景点那个月份游玩的人数最多,这样我们就不用担心去游玩的时机不对了。
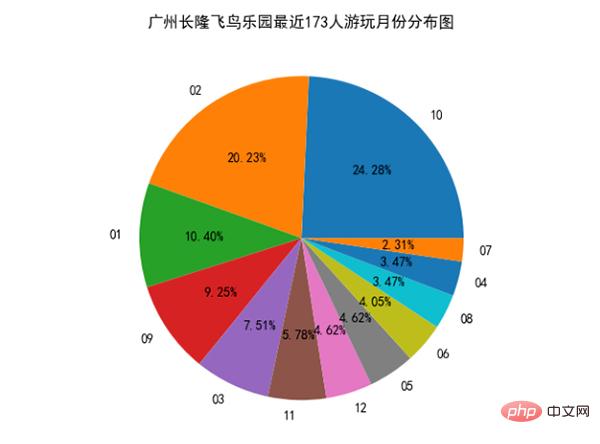
我们发现10月、2月、1月去广州长隆飞鸟乐园游玩的人数占总体比例最多。分析完月份后,我们来看看评论情况如何:
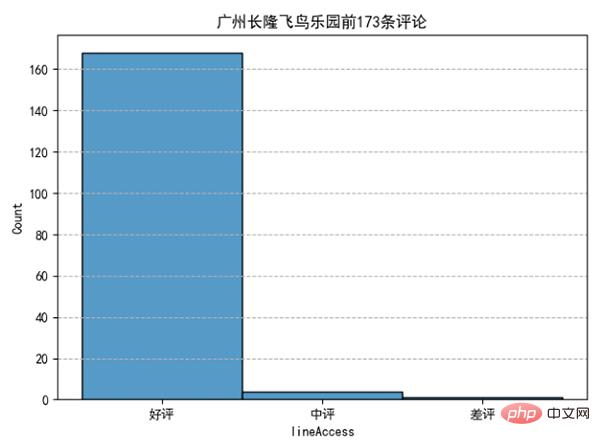
可以发现去好评占了绝大部分,可以说:去长隆飞鸟乐园玩耍,去了都说好。看了评论情况,评论内容有什么:

好了,获取旅游景点信息及评论并做词云、数据可视化就讲到这里了。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



