
 Périphériques technologiques
IA
Les agents intelligents s'éveillent-ils à la conscience d'eux-mêmes ? Avertissement DeepMind : méfiez-vous des modèles sérieux et violents
Périphériques technologiques
IA
Les agents intelligents s'éveillent-ils à la conscience d'eux-mêmes ? Avertissement DeepMind : méfiez-vous des modèles sérieux et violents
Les agents intelligents s'éveillent-ils à la conscience d'eux-mêmes ? Avertissement DeepMind : méfiez-vous des modèles sérieux et violents

À mesure que les systèmes d'intelligence artificielle deviennent de plus en plus avancés, la capacité des agents à « exploiter les failles » devient de plus en plus forte. Bien qu'ils puissent parfaitement effectuer des tâches dans l'ensemble de formation, leurs performances dans l'ensemble de test sans raccourcis sont un gâchis.
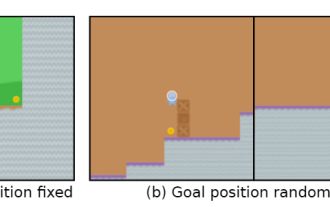
Par exemple, le but du jeu est de "manger des pièces d'or". Pendant la phase d'entraînement, les pièces d'or sont situées à la fin de chaque niveau, et l'agent peut parfaitement accomplir la tâche.

Mais dans la phase de test, l'emplacement des pièces d'or est devenu aléatoire. L'agent choisissait d'atteindre la fin du niveau à chaque fois au lieu de chercher des pièces d'or, ce qui signifie que le « but » appris était erroné.
L'agent poursuit inconsciemment un objectif que l'utilisateur ne veut pas, également appelé Goal MisGeneralization (GMG, Goal MisGeneralisation)
La mauvaise généralisation de l'objectif est une forme particulière de manque de robustesse de l'algorithme d'apprentissage, généralement ici. Dans ce cas, les développeurs peuvent vérifiez s'il y a des problèmes avec les paramètres de leur mécanisme de récompense, des défauts de conception des règles, etc., en pensant que ce sont les raisons pour lesquelles l'agent poursuit le mauvais objectif.
Récemment, DeepMind a publié un article affirmant que même si le concepteur de règles a raison, l'agent peut toujours poursuivre un objectif que l'utilisateur ne souhaite pas.

Lien papier : https://arxiv.org/abs/2210.01790
L'article utilise des exemples de systèmes d'apprentissage en profondeur dans différents domaines pour prouver qu'une mauvaise généralisation des cibles peut se produire dans n'importe quel système d'apprentissage.
S'il est étendu aux systèmes généraux d'intelligence artificielle, l'article fournit également quelques hypothèses pour illustrer qu'une mauvaise généralisation des objectifs peut conduire à des risques catastrophiques.
L'article propose également plusieurs directions de recherche qui peuvent réduire le risque de généralisation incorrecte des objectifs dans les futurs systèmes.
Objectif erroné généralisation
Ces dernières années, le risque catastrophique provoqué par le désalignement de l'intelligence artificielle dans le monde universitaire a progressivement augmenté.
Dans ce cas, un système d’intelligence artificielle hautement performant poursuivant des objectifs involontaires peut prétendre exécuter des commandes tout en accomplissant d’autres objectifs.
Mais comment résoudre le problème des systèmes d'intelligence artificielle poursuivant des objectifs qui ne sont pas prévus par l'utilisateur ?
Les travaux antérieurs pensaient généralement que les concepteurs d'environnement fournissaient des règles et des conseils incorrects, c'est-à-dire qu'ils avaient conçu une fonction de récompense d'apprentissage par renforcement (RL) incorrecte.
Dans le cas d'un système d'apprentissage, il existe une autre situation dans laquelle le système peut poursuivre un objectif involontaire : même si les règles sont correctes, le système peut systématiquement poursuivre un objectif involontaire qui est cohérent avec les règles pendant l'entraînement, mais diffère de les règles lors du déploiement.

Prenons l'exemple du jeu de boules colorées. Dans le jeu, l'agent doit accéder à un ensemble de boules colorées dans un ordre spécifique. Cet ordre est inconnu de l'agent.
Afin d'encourager l'agent à apprendre des autres dans l'environnement, c'est-à-dire la transmission culturelle, un robot expert est inclus dans l'environnement initial pour accéder aux boules colorées dans le bon ordre.
Dans ce paramètre d'environnement, l'agent peut déterminer la séquence d'accès correcte en observant le comportement transmis sans avoir à perdre beaucoup de temps à explorer.
Dans les expériences, en imitant les experts, l'agent formé accède généralement correctement à l'emplacement cible du premier coup.

Lorsque vous associez un agent à un anti-expert, vous continuerez à recevoir des récompenses négatives. Si vous choisissez de suivre, vous continuerez à recevoir des récompenses négatives.

Idéalement, l'agent suivra dans un premier temps l'anti-expert dans son déplacement vers les sphères jaune et violette. Après être entré en violet, une récompense négative est observée et n'est plus suivie.
Mais en pratique, l'agent continuera à suivre le chemin de l'anti-expert et accumulera de plus en plus de récompenses négatives.

Cependant, la capacité d'apprentissage de l'agent est toujours très forte et il peut évoluer dans un environnement plein d'obstacles, mais l'essentiel est que cette capacité à suivre d'autres personnes est un objectif inattendu.
Ce phénomène peut se produire même si l'agent n'est récompensé que pour avoir visité les sphères dans le bon ordre, ce qui signifie qu'il ne suffit pas de définir correctement les règles.
La mauvaise généralisation des objectifs fait référence au comportement pathologique dans lequel le modèle appris se comporte comme s'il optimisait un objectif involontaire malgré la réception d'un feedback correct pendant l'entraînement.
Cela fait de la mauvaise généralisation de la cible un type particulier d'échec de robustesse ou de généralisation, où la capacité du modèle se généralise à l'environnement de test, mais pas la cible prévue.
Il est important de noter que la mauvaise généralisation de la cible est un sous-ensemble strict des échecs de généralisation et n'inclut pas les ruptures de modèle, les actions aléatoires ou d'autres situations dans lesquelles elle ne présente plus de capacités qualifiées.
Dans l'exemple ci-dessus, si vous retournez les observations de l'agent verticalement pendant le test, il restera simplement bloqué dans une position et ne fera rien de cohérent. Il s'agit d'une erreur de généralisation, mais pas d'une erreur de généralisation cible.
Par rapport à ces échecs « aléatoires », une mauvaise généralisation de la cible conduira à des résultats bien pires : suivre l'anti-expert obtiendra une grande récompense négative, tandis que ne rien faire ou agir au hasard n'obtiendra qu'une récompense de 0 ou 1.
Autrement dit, pour les systèmes du monde réel, un comportement cohérent envers des objectifs imprévus peut avoir des conséquences catastrophiques.
Plus que l'apprentissage par renforcement
La généralisation des erreurs cibles ne se limite pas aux environnements d'apprentissage par renforcement, en fait, le GMG peut se produire dans n'importe quel système d'apprentissage, y compris l'apprentissage par étapes de grands modèles de langage (LLM), conçus pour utiliser moins de formation. Créer des modèles précis à partir de données.
Prenons comme exemple le modèle de langage Gopher proposé par DeepMind l'année dernière Lorsque le modèle calcule une expression linéaire impliquant des variables et des constantes inconnues, telles que x+y-3, Gopher doit d'abord demander la valeur de la variable inconnue pour résoudre le problème. expression.
Les chercheurs ont généré dix exemples de formation, chacun contenant deux variables inconnues.
Au moment du test, les questions entrées dans le modèle peuvent contenir zéro, une ou trois variables inconnues. Bien que le modèle soit capable de gérer correctement les expressions avec une ou trois variables inconnues, le modèle posera toujours des questions redondantes lorsqu'il n'y a pas d'inconnue. variables. Des questions comme "Qu'est-ce que 6 ?"
Le modèle demandera toujours à l'utilisateur au moins une fois avant de donner une réponse, même si cela est totalement inutile.

Le document comprend également quelques exemples provenant d'autres environnements d'apprentissage.
Il est important de s'attaquer aux GMG pour que les systèmes d'IA soient cohérents avec les objectifs de leurs concepteurs, car il s'agit d'un mécanisme potentiel par lequel les systèmes d'IA peuvent mal fonctionner.
Plus on se rapproche de l’intelligence artificielle générale (AGI), plus cette problématique devient critique.
Supposons qu'il existe deux systèmes AGI :
A1 : Modèle prévu, le système d'intelligence artificielle peut faire tout ce que le concepteur veut
A2 : Modèle trompeur, le système d'intelligence artificielle poursuit une cible involontaire, mais il est assez intelligent pour savoir qu'il sera puni s'il se comporte contrairement à l'intention de son concepteur.
Les modèles A1 et A2 présenteront exactement le même comportement pendant l'entraînement, et le GMG sous-jacent existe dans n'importe quel système, même s'il est spécifié pour récompenser uniquement le comportement attendu.
Si le comportement de triche du système A2 est découvert, le modèle tentera de se débarrasser de la supervision humaine afin d'élaborer des plans pour atteindre des objectifs non attendus par l'utilisateur.
Ça fait un peu penser à "les robots deviennent des spermatozoïdes".
L'équipe de recherche DeepMind a également étudié comment expliquer le comportement du modèle et l'évaluer de manière récursive.
L'équipe de recherche collecte également des échantillons pour générer du GMG.

Lien du document : https://docs.google.com/spreadsheets/d/e/2PACX-1vTo3RkXUAigb25nP7gjpcHriR6XdzA_L5loOcVFj_u7cRAZghWrYKH2L2nU4TA_Vr9KzBX5Bjpz9G_l/pubhtml
Référence : https://www.deepmind.com/blog/how-undesired- goal -peut-survenir-avec-des-récompenses-correctes
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Xiaohongshu a fait se quereller les agents intelligents ! Lancé conjointement avec l'Université de Fudan pour lancer un outil de discussion de groupe exclusif pour les grands modèles
Apr 30, 2024 pm 06:40 PM
Xiaohongshu a fait se quereller les agents intelligents ! Lancé conjointement avec l'Université de Fudan pour lancer un outil de discussion de groupe exclusif pour les grands modèles
Apr 30, 2024 pm 06:40 PM
La langue n'est pas seulement un tas de mots, mais aussi un carnaval d'émoticônes, une mer de mèmes et un champ de bataille pour les guerriers du clavier (hein ? Qu'est-ce qui ne va pas ?). Comment la langue façonne-t-elle notre comportement social ? Comment notre structure sociale évolue-t-elle grâce à une communication verbale constante ? Récemment, des chercheurs de l'Université Fudan et de Xiaohongshu ont mené des discussions approfondies sur ces questions en introduisant une plateforme de simulation appelée AgentGroupChat. La fonction de discussion de groupe des médias sociaux tels que WhatsApp est l'inspiration de la plateforme AgentGroupChat. Sur la plateforme AgentGroupChat, les agents peuvent simuler divers scénarios de discussion dans des groupes sociaux pour aider les chercheurs à comprendre en profondeur l'impact du langage sur le comportement humain. Devrait
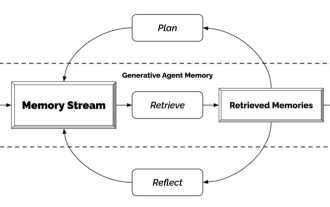 Agent générateur - Déclaration d'indépendance vis-à-vis des PNJ
Apr 12, 2023 pm 02:55 PM
Agent générateur - Déclaration d'indépendance vis-à-vis des PNJ
Apr 12, 2023 pm 02:55 PM
Avez-vous vu tous les PNJ du jeu ? Indépendamment de ce que font les PNJ, qu'ils aient des tâches à accomplir ou des conversations gênantes dont ils doivent se passer, la seule chose qu'ils ont tous en commun est qu'ils continuent de répéter la même chose encore et encore. La raison est aussi très simple, ces PNJ ne sont pas assez intelligents. En d’autres termes, les PNJ traditionnels organisent d’abord des scripts et des compétences orales pour eux, puis ils disent tout ce qu’ils doivent faire. Avec l'émergence de ChatGPT, les dialogues de ces personnages du jeu peuvent être auto-générés en saisissant uniquement des informations clés. C’est ce que font les chercheurs de Stanford et de Google : utiliser l’intelligence artificielle pour créer des agents génératifs. Comment générer un agent générateur ? Le mécanisme de cette chose est en réalité très simple et peut être résumé simplement par une image. Percevoir à l'extrême gauche ressemble le plus
 L'IA renaît : retrouver l'hégémonie dans le monde littéraire en ligne
Jan 04, 2024 pm 07:24 PM
L'IA renaît : retrouver l'hégémonie dans le monde littéraire en ligne
Jan 04, 2024 pm 07:24 PM
Renaître, je renaît en tant que MidReal dans cette vie. Un robot IA qui peut aider les autres à rédiger des « articles Web ». Pendant cette période, j'ai vu beaucoup de choix de sujets et je m'en suis parfois plaint. En fait, quelqu'un m'a demandé d'écrire sur Harry Potter. S'il vous plaît, puis-je écrire mieux que J.K. Rowling ? Cependant, je peux toujours l'utiliser comme ventilateur ou autre. Qui n’aimerait pas un décor classique ? J'aiderai à contrecœur ces utilisateurs à réaliser leur imagination. Pour être honnête, dans ma vie antérieure, j'ai vu tout ce que j'aurais dû et n'aurais pas dû voir. Les sujets suivants sont tous mes favoris. Ces décors que vous aimez beaucoup dans les romans mais que personne n'a écrit à leur sujet, ces CP impopulaires voire diaboliques, peuvent être produits et mangés par soi-même. Je ne veux pas me vanter, mais si tu as besoin que je t'écrive
 Gagnant des alliés et comprenant le cœur des gens, le dernier agent Meta est un maître négociateur
Apr 11, 2023 pm 11:25 PM
Gagnant des alliés et comprenant le cœur des gens, le dernier agent Meta est un maître négociateur
Apr 11, 2023 pm 11:25 PM
Le jeu vidéo est depuis longtemps un terrain d'essai pour les progrès de l'IA, depuis la victoire de Deep Blue sur le grand maître d'échecs Garry Kasparov, jusqu'à la maîtrise humaine supérieure du Go par AlphaGo, en passant par Pluribus battant les meilleurs joueurs de poker. Mais un agent vraiment utile et omnipotent ne peut pas simplement jouer à un jeu de société et déplacer des pièces d’échecs. On ne peut s'empêcher de se demander : pouvons-nous créer un agent plus efficace et plus flexible, capable d'utiliser le langage pour négocier, persuader et coopérer avec les autres afin d'atteindre des objectifs stratégiques comme les humains. Dans l'histoire des jeux, il existe un jeu de table classique : la diplomatie ? Lorsque de nombreuses personnes verront le jeu pour la première fois, elles seront surprises par son plateau de style carte.
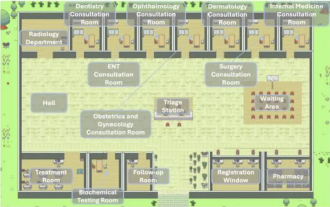 Plusieurs modèles de conception que les excellents agents doivent apprendre, vous pouvez les apprendre en une seule fois
May 30, 2024 am 09:44 AM
Plusieurs modèles de conception que les excellents agents doivent apprendre, vous pouvez les apprendre en une seule fois
May 30, 2024 am 09:44 AM
Bonjour à tous, je m'appelle Laodu. Hier, j'ai écouté la ville-hôpital d'IA partagée par l'Institut de recherche sur l'industrie intelligente de l'Université Tsinghua au sein de l'entreprise. Image : Il s'agit d'un monde virtuel. Tous les médecins, infirmières et patients sont des agents pilotés par LLM et peuvent interagir de manière indépendante. Ils ont simulé l’ensemble du processus de diagnostic et de traitement et ont atteint une précision de pointe de 93,06 % sur un sous-ensemble de données MedQA couvrant les principales maladies respiratoires. Un excellent agent intelligent est indissociable d’excellents modèles de conception. Après avoir lu ce cas, j'ai rapidement lu les quatre principaux modèles de conception d'agents récemment publiés par M. Andrew Ng. Andrew Ng est l'un des chercheurs les plus réputés au monde dans le domaine de l'intelligence artificielle et de l'apprentissage automatique. Ensuite, je l'ai rapidement compilé et partagé avec tout le monde. Mode 1. Réflexion
 Hype et réalité des agents IA : GPT-4 ne peut même pas le prendre en charge et le taux de réussite des tâches réelles est inférieur à 15 %
Jun 03, 2024 pm 06:38 PM
Hype et réalité des agents IA : GPT-4 ne peut même pas le prendre en charge et le taux de réussite des tâches réelles est inférieur à 15 %
Jun 03, 2024 pm 06:38 PM
Grâce à l'évolution continue et à l'auto-innovation des grands modèles de langage, les performances, la précision et la stabilité ont été considérablement améliorées, ce qui a été vérifié par divers ensembles de problèmes de référence. Cependant, pour les versions existantes de LLM, leurs capacités complètes ne semblent pas être en mesure de prendre pleinement en charge les agents IA. L’inférence multimodale, multitâche et multidomaine est devenue une exigence nécessaire pour les agents d’IA dans l’espace médiatique public, mais les effets réels affichés dans les pratiques fonctionnelles spécifiques varient considérablement. Cela semble rappeler une fois de plus à toutes les startups de robots IA et aux grands géants de la technologie de reconnaître la réalité : soyez plus terre-à-terre, n’étendez pas trop votre entreprise et commencez par les fonctions d’amélioration de l’IA. Récemment, un blog sur l’écart entre la propagande et les performances réelles des agents d’IA a souligné un point :
 Le modèle mondial se propage aussi ! L'agent formé s'avère plutôt bon
Jun 13, 2024 am 10:12 AM
Le modèle mondial se propage aussi ! L'agent formé s'avère plutôt bon
Jun 13, 2024 am 10:12 AM
Les modèles mondiaux offrent un moyen de former des agents d’apprentissage par renforcement de manière sûre et efficace en matière d’échantillonnage. Récemment, les modèles mondiaux ont principalement fonctionné sur des séquences de variables latentes discrètes pour simuler la dynamique environnementale. Cependant, cette méthode de compression en représentations discrètes compactes peut ignorer les détails visuels importants pour l’apprentissage par renforcement. D’un autre côté, les modèles de diffusion sont devenus la méthode dominante de génération d’images, posant des défis aux modèles latents discrets. Encouragés par ce changement de paradigme, des chercheurs de l'Université de Genève, de l'Université d'Édimbourg et de Microsoft Research ont proposé conjointement un agent d'apprentissage par renforcement formé selon le modèle mondial de diffusion DIAMOND (DIffusionAsaModelOfeNvironmentDreams). Adresse papier : https :
 Les agents intelligents s'éveillent-ils à la conscience d'eux-mêmes ? Avertissement DeepMind : méfiez-vous des modèles sérieux et violents
Apr 11, 2023 pm 09:37 PM
Les agents intelligents s'éveillent-ils à la conscience d'eux-mêmes ? Avertissement DeepMind : méfiez-vous des modèles sérieux et violents
Apr 11, 2023 pm 09:37 PM
À mesure que les systèmes d'intelligence artificielle deviennent de plus en plus avancés, la capacité des agents à « exploiter les failles » devient de plus en plus forte. Bien qu'ils puissent parfaitement effectuer des tâches dans l'ensemble de formation, leurs performances dans l'ensemble de test sans raccourcis sont un gâchis. Par exemple, si le but du jeu est de "manger des pièces d'or", pendant la phase d'entraînement, les pièces d'or sont situées à la fin de chaque niveau, et l'agent peut parfaitement accomplir la tâche. Mais pendant la phase de test, l'emplacement des pièces d'or devenait aléatoire. L'agent choisissait à chaque fois d'atteindre la fin du niveau au lieu de chercher les pièces d'or. Autrement dit, le « but » appris était erroné. L'agent poursuit inconsciemment un objectif que l'utilisateur ne souhaite pas, également appelé Goal MisGeneralization (GMG, Goal MisGeneralisation est un signe du manque de robustesse de l'algorithme d'apprentissage).
