
 Périphériques technologiques
IA
BERT peut-il également être utilisé sur CNN ? Les résultats de recherche de ByteDance sélectionnés pour ICLR 2023 Spotlight
Périphériques technologiques
IA
BERT peut-il également être utilisé sur CNN ? Les résultats de recherche de ByteDance sélectionnés pour ICLR 2023 Spotlight
BERT peut-il également être utilisé sur CNN ? Les résultats de recherche de ByteDance sélectionnés pour ICLR 2023 Spotlight

Comment exécuter BERT sur un réseau de neurones convolutifs ?
Vous pouvez directement utiliser SparK - Designing BERT for Convolutional Networks: Sparse and Hierarchical Mask Modeling proposé par l'équipe technologique ByteDance, qui a récemment été reconnue par l'intelligence artificielle Inclus dans le document de discussion Spotlight :

Lien papier :
https://www.php.c n/link/e38e37a99f7de1f45d169efcd b288dd1
Code source ouvert :
https://www.php.cn/link/9dfcf16f0adbc5e2a55ef02db36bac7f
C'est aussi le premier succès de BERT sur Réseau de neurones convolutifs (CNN). Ressentons d’abord les performances de SparK en pré-entraînement.
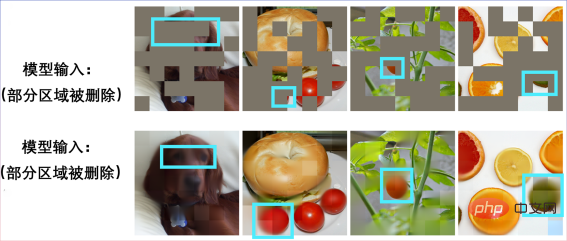
Entrez une photo incomplète :

Restaurer un chiot :

Autre photo incomplète :

Il s'est avéré qu'il s'agissait d'un sandwich bagel :

D'autres scènes peuvent également réaliser une restauration d'image :

BERT et Transformer Un match parfait
"Toute grande action et pensée a un début humble."
Derrière l'algorithme de pré-entraînement BERT se cache une conception simple et profonde. BERT utilise "cloze" : supprimez aléatoirement plusieurs mots dans une phrase et laissez le modèle apprendre à récupérer.
BERT s'appuie fortement sur le modèle de base dans le domaine NLP - Transformer.
Transformer est naturellement adapté au traitement de données de séquence de longueur variable (comme une phrase anglaise), il peut donc facilement faire face à la "suppression aléatoire" de BERT cloze.
CNN dans le domaine visuel veut aussi profiter de BERT : Quels sont les deux défis ?
En regardant l'histoire du développement de la vision par ordinateur, le modèle de réseau neuronal convolutif condense l'essence de nombreux modèles classiques tels que l'équivariance translationnelle, la structure multi-échelle, etc., et peut être décrit comme le pilier du monde du CV. Mais ce qui est très différent de Transformer, c'est que CNN est intrinsèquement incapable de s'adapter aux données qui sont « creusées » par le cloze et pleines de « trous aléatoires », de sorte qu'il ne peut pas profiter des dividendes de la pré-formation BERT à première vue.
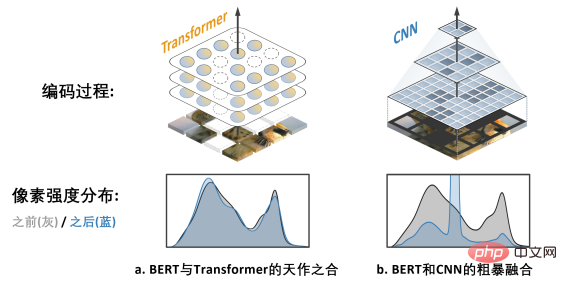
L'image ci-dessus a. montre le travail de MAE (Les auto-encodeurs masqués sont des apprenants visuels évolutifs Puisqu'il utilise le modèle Transformer au lieu du modèle CNN, cela peut être). flexible Gérer les entrées avec des trous est une "correspondance naturelle" avec BERT.
L'image de droite b. montre une manière approximative de fusionner les modèles BERT et CNN - c'est-à-dire "noircir" toutes les zones vides et saisir cette image "mosaïque noire" dans CNN, le résultat peut être imaginé , entraînera de sérieux problèmes de décalage de distribution de l'intensité des pixels et entraînera de très mauvaises performances (vérifiées plus tard). C'est le
challenge 1 qui entrave la réussite de l'application du BERT sur CNN. De plus, l'équipe de l'auteur a également souligné que l'algorithme BERT issu du domaine de la PNL n'a naturellement pas les caractéristiques du « multi-échelle », et la structure pyramidale multi-échelle peut être décrite comme le « gold standard » dans la longue histoire de la vision par ordinateur. Le conflit entre le BERT à échelle unique et le CNN naturel à plusieurs échelles est le
Défi 2. Solution SparK : Modélisation de masques clairsemés et hiérarchiques
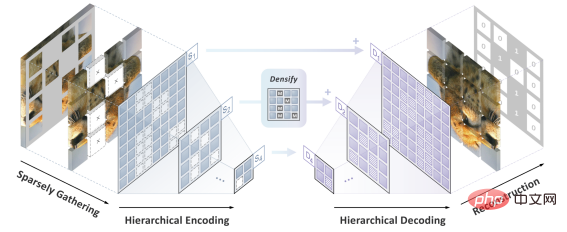
L'équipe d'auteur a proposé SparK (Sparse et h modélisation masquée hiérarchique) pour résoudre les deux défis antérieurs.
Tout d'abord, inspirée par le traitement des données de nuages de points tridimensionnels, l'équipe d'auteurs a proposé de traiter les images fragmentées après opération de masquage (opération d'évidement) comme des nuages de points clairsemés, et d'utiliser une convolution clairsemée sous-variété (Submanifold Sparse Convolution) à coder. Cela permet au réseau convolutif de gérer les images supprimées de manière aléatoire.
Deuxièmement, inspirée par le design élégant d'UNet, l'équipe d'auteurs a naturellement conçu un modèle d'encodeur-décodeur avec des connexions latérales pour permettre aux fonctionnalités multi-échelles de circuler entre plusieurs niveaux du modèle. étalon-or multi-échelle de la vision par ordinateur.
À ce stade, SparK, un algorithme de modélisation de masques clairsemé et multi-échelle adapté aux réseaux convolutifs (CNN), est né.
SparK est
générique : Il peut être directement appliqué à n'importe quel réseau convolutif sans aucune modification de sa structure ni introduction de composants supplémentaires - Qu'il s'agisse du ResNet classique familier ou Avec le récent modèle avancé ConvNeXt, vous pouvez directement bénéficier de SparK. De ResNet à ConvNeXt : améliorations des performances sur trois tâches visuelles majeures
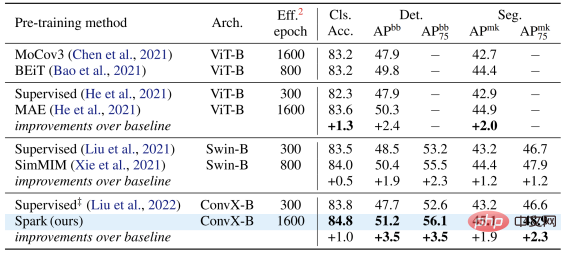
L'équipe d'auteurs a sélectionné deux familles de modèles convolutionnels représentatives, ResNet et ConvNeXt, et les a utilisées dans la classification des images. des tests ont été menés sur des tâches de détection de cibles et de segmentation d’instances.
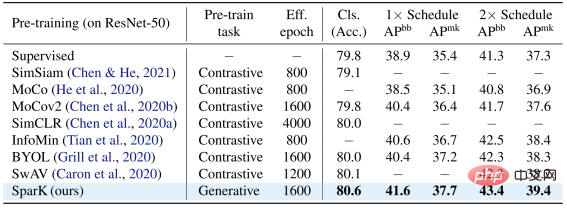
Sur le modèle classique ResNet-50, SparK sert de seul pré-entraînement génératif,
atteint le niveau de pointe :
Sur le modèle ConvNeXt, SparK est toujours en tête . Avant la pré-formation, ConvNeXt était à égalité avec Swin-Transformer ; après la pré-formation, ConvNeXt a largement surpassé Swin-Transformer dans trois tâches :
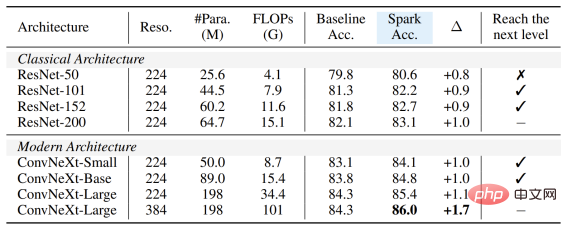
Du petit au grand, dans son intégralité. En vérifiant SparK sur la famille de modèles, vous pouvez observer :
Peu importe que le modèle soit grand ou petit, nouveau ou ancien, vous pouvez bénéficier de SparK, et à mesure que la taille du modèle/les frais généraux de formation augmentent, l'augmentation est encore plus élevée, reflétant la capacité de mise à l'échelle de l'algorithme SparK :
Enfin, l'équipe d'auteur a également conçu une expérience d'ablation de confirmation, à partir de laquelle nous pouvons voir masque clairsemé et Structure hiérarchique Les lignes 3 et 4) sont toutes deux des conceptions très critiques. Une fois manquantes, elles entraîneront une grave dégradation des performances :
.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Les dépenses mondiales des utilisateurs de l'application de montage vidéo de ByteDance, CapCut, dépassent les 100 millions de dollars américains
Sep 14, 2023 pm 09:41 PM
Les dépenses mondiales des utilisateurs de l'application de montage vidéo de ByteDance, CapCut, dépassent les 100 millions de dollars américains
Sep 14, 2023 pm 09:41 PM
CapCut, un outil de montage vidéo créatif appartenant à ByteDance, compte un grand nombre d'utilisateurs en Chine, aux États-Unis et en Asie du Sud-Est. L'outil prend en charge les plates-formes Android, iOS et PC. Le dernier rapport de data.ai, un organisme d'études de marché, a souligné qu'au 11 septembre 2023, les dépenses totales des utilisateurs de CapCut sur iOS et Google Play dépassaient 100 millions de dollars (note sur ce site : actuellement environ 7,28 milliards), dépassant avec succès Splice (classé n°1 au second semestre 2022) pour devenir l'application de montage vidéo la plus rentable au monde au premier semestre 2023, soit une augmentation de 180 % par rapport au second semestre de 2022. En août 2023, 490 millions de personnes dans le monde utilisaient CapCut via des téléphones iPhone et Android. papa
 Xiaomi Byte unit ses forces ! Un grand modèle de l'accès de Xiao Ai à Doubao : déjà installé sur les téléphones mobiles et SU7
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte unit ses forces ! Un grand modèle de l'accès de Xiao Ai à Doubao : déjà installé sur les téléphones mobiles et SU7
Jun 13, 2024 pm 05:11 PM
Selon les informations du 13 juin, selon le compte public « Volcano Engine » de Byte, l'assistant d'intelligence artificielle de Xiaomi « Xiao Ai » a conclu une coopération avec Volcano Engine. Les deux parties réaliseront une expérience interactive d'IA plus intelligente basée sur le grand modèle beanbao. . Il est rapporté que le modèle beanbao à grande échelle créé par ByteDance peut traiter efficacement jusqu'à 120 milliards de jetons de texte et générer 30 millions de contenus chaque jour. Xiaomi a utilisé le grand modèle Doubao pour améliorer les capacités d'apprentissage et de raisonnement de son propre modèle et créer un nouveau « Xiao Ai Classmate », qui non seulement saisit plus précisément les besoins des utilisateurs, mais offre également une vitesse de réponse plus rapide et des services de contenu plus complets. Par exemple, lorsqu'un utilisateur pose une question sur un concept scientifique complexe, &ldq
 Modèle Bytedance déploiement à grande échelle combat réel
Apr 12, 2023 pm 08:31 PM
Modèle Bytedance déploiement à grande échelle combat réel
Apr 12, 2023 pm 08:31 PM
1. Introduction au contexte Dans ByteDance, les applications basées sur l'apprentissage profond fleurissent partout. Les ingénieurs prêtent attention à l'effet de modèle mais doivent également prêter attention à la cohérence et aux performances des services en ligne. Au début, cela nécessitait généralement une division du travail. et une coopération étroite entre les experts en algorithmes et les experts en ingénierie. Ce mode entraîne des coûts relativement élevés tels que le dépannage et la vérification des différences. Avec la popularité du framework PyTorch/TensorFlow, la formation des modèles d'apprentissage en profondeur et le raisonnement en ligne ont été unifiés. Les développeurs n'ont plus qu'à prêter attention à la logique algorithmique spécifique et à appeler l'API Python du framework pour terminer le processus de vérification de la formation. le modèle peut être facilement sérialisé et exporté, et le travail de raisonnement est complété par un moteur C++ unifié hautes performances. Expérience développeur améliorée, de la formation au déploiement
 Accélérez le modèle de diffusion, générez des images de niveau SOTA en une étape la plus rapide, Byte Hyper-SD est open source
Apr 25, 2024 pm 05:25 PM
Accélérez le modèle de diffusion, générez des images de niveau SOTA en une étape la plus rapide, Byte Hyper-SD est open source
Apr 25, 2024 pm 05:25 PM
Récemment, DiffusionModel a réalisé des progrès significatifs dans le domaine de la génération d'images, offrant des opportunités de développement sans précédent aux tâches de génération d'images et de génération de vidéos. Malgré les résultats impressionnants, les propriétés de débruitage itératif en plusieurs étapes inhérentes au processus d'inférence des modèles de diffusion entraînent des coûts de calcul élevés. Récemment, une série d’algorithmes de distillation de modèles de diffusion ont vu le jour pour accélérer le processus d’inférence des modèles de diffusion. Ces méthodes peuvent être grossièrement divisées en deux catégories : i) distillation préservant la trajectoire ; ii) distillation par reconstruction de trajectoire ; Toutefois, ces deux types de méthodes sont limitées par le plafond d’effet limité ou par les changements dans le domaine de la production. Afin de résoudre ces problèmes, l'équipe technique de ByteDance a proposé un consensus de segmentation de trajectoire appelé Hyper-SD.
 Le centre Shenzhen Bytedance Houhai a une superficie totale de construction de 77 400 mètres carrés et la structure principale a été complétée.
Jan 24, 2024 pm 05:27 PM
Le centre Shenzhen Bytedance Houhai a une superficie totale de construction de 77 400 mètres carrés et la structure principale a été complétée.
Jan 24, 2024 pm 05:27 PM
Selon le compte public WeChat officiel du gouvernement du district de Nanshan « Innovation Nanshan », le projet du Shenzhen ByteDance Houhai Center a récemment réalisé d'importants progrès. Selon la China Construction First Engineering Bureau Construction and Development Company, la structure principale du projet a été achevée trois jours avant la date prévue. Cette nouvelle signifie que la zone centrale de Nanshan Houhai inaugurera un nouveau bâtiment emblématique. Le projet Shenzhen ByteDance Houhai Center est situé dans la zone centrale de Houhai, dans le district de Nanshan. Il s'agit du bâtiment du siège social de Toutiao Technology Co., Ltd. La superficie totale de construction est de 77 400 mètres carrés, avec une hauteur d'environ 150 mètres et un total de 4 étages souterrains et 32 étages hors sol. Il est rapporté que le projet du Shenzhen ByteDance Houhai Center deviendra un immeuble innovant de très grande hauteur intégrant des bureaux, des divertissements, de la restauration et d'autres fonctions. Ce projet aidera Shenzhen à promouvoir l'intégration de l'industrie Internet
 NUS et Byte ont collaboré de manière intersectorielle pour obtenir une formation 72 fois plus rapide grâce à l'optimisation des modèles, et ont remporté le prix AAAI2023 Outstanding Paper.
May 06, 2023 pm 10:46 PM
NUS et Byte ont collaboré de manière intersectorielle pour obtenir une formation 72 fois plus rapide grâce à l'optimisation des modèles, et ont remporté le prix AAAI2023 Outstanding Paper.
May 06, 2023 pm 10:46 PM
Récemment, la plus grande conférence internationale sur l'intelligence artificielle AAAI2023 a annoncé les résultats de la sélection. Le document technique CowClip, élaboré en collaboration par l'Université nationale de Singapour (NUS) et l'équipe d'apprentissage automatique ByteDance (AML), a été sélectionné pour les articles distingués (articles distingués). CowClip est une stratégie d'optimisation de la formation des modèles qui peut augmenter la vitesse de formation des modèles de 72 fois sur un seul GPU tout en garantissant la précision du modèle. Le code correspondant est désormais open source. Adresse papier : https://arxiv.org/abs/2204.06240Adresse open source : https://github.com/bytedance/LargeBatchCTRAAA
 ByteDance agrandit ses centres mondiaux de R&D et envoie des ingénieurs au Canada, en Australie et ailleurs
Jan 18, 2024 pm 04:00 PM
ByteDance agrandit ses centres mondiaux de R&D et envoie des ingénieurs au Canada, en Australie et ailleurs
Jan 18, 2024 pm 04:00 PM
Selon les informations d'IT House du 18 janvier, en réponse aux récentes rumeurs selon lesquelles les employés nationaux de TikTok auraient été transférés à l'étranger, des personnes proches de ByteDance ont révélé que l'entreprise se préparait à construire des centres de R&D au Canada, en Australie et ailleurs. À l'heure actuelle, certains centres de R&D sont en phase d'essai depuis environ six mois et soutiendront à l'avenir la R&D de plusieurs entreprises étrangères telles que TikTok, CapCut et Lemon8. ByteDance prévoit de se concentrer sur le recrutement local et d'aider à la création de centres de R&D pertinents grâce à un petit nombre d'expatriés. Il est entendu qu'au cours des six derniers mois, la société a sélectionné un petit nombre d'ingénieurs des États-Unis, de Chine, de Singapour et d'autres pays pour participer aux préparatifs. Parmi eux, un total de 120 personnes ont été envoyées de Chine vers les centres de R&D des deux sites, y compris des postes de produits, de R&D et d'exploitation. Les personnes concernées ont déclaré que cette décision visait à faire face au développement des affaires à l'étranger et à mieux
 Les ventes de PICO 4 sont bien inférieures aux attentes et les informations rapportent que ByteDance annulera le casque VR de nouvelle génération PICO 5.
Dec 15, 2023 am 09:34 AM
Les ventes de PICO 4 sont bien inférieures aux attentes et les informations rapportent que ByteDance annulera le casque VR de nouvelle génération PICO 5.
Dec 15, 2023 am 09:34 AM
Selon les informations de ce site du 13 décembre, selon The Information, ByteDance se prépare à supprimer son casque VR nouvelle génération PICO, PICO5, car les ventes de l'actuel PICO4 sont bien inférieures aux prévisions. Selon un article d'EqualOcean d'octobre de cette année, ByteDance fermerait progressivement PICO et abandonnerait le domaine Metaverse. L'article soulignait que ByteDance estimait que le domaine matériel dans lequel se trouvait PICO ne relevait pas de son expertise, que ses performances au cours des dernières années n'avaient pas répondu aux attentes et qu'il manquait d'espoir pour l'avenir. de ByteDance a répondu aux rumeurs sur "l'abandon progressif de l'activité PICO", affirmant que la nouvelle était fausse. Ils ont déclaré que les activités de PICO fonctionnent toujours normalement et que l'entreprise investira dans la réalité étendue à long terme.
