

Traducteur | Zhu Xianzhong
Reviewer | Sun Shujuan
Dans cet article, j'aimerais partager avec vous ma méthode d'optimisation des données d'entrée du modèle d'apprentissage profond. En tant que data scientist et ingénieur de données, j'ai appliqué avec succès cette technique à mon propre travail. Vous apprendrez à utiliser les informations contextuelles pour enrichir les données d'entrée du modèle à travers des cas de développement concrets et réels. Cela vous aidera à concevoir des modèles d’apprentissage profond plus robustes et précis.

Les modèles d'apprentissage en profondeur sont très puissants car ils sont très efficaces pour intégrer des informations contextuelles. Nous pouvons améliorer les performances des réseaux de neurones en ajoutant plusieurs contextes aux dimensions des données d'origine. Nous pouvons y parvenir grâce à une ingénierie de données intelligente.
Lorsque vous développez un nouvel algorithme d'apprentissage profond prédictif, vous pouvez choisir une architecture de modèle parfaitement adaptée à votre cas d'utilisation spécifique. En fonction des données d'entrée et de la tâche de prédiction réelle, vous avez peut-être pensé à de nombreuses méthodes : si vous envisagez de classer des images, vous choisirez probablement un réseau neuronal convolutif si vous prédisez des séries temporelles ou analysez du texte, alors le réseau LSTM ; Cela pourrait être une option prometteuse. Souvent, les décisions concernant l’architecture correcte du modèle dépendent en grande partie du type de données entrant dans le modèle.
En conséquence, trouver la structure de données d'entrée correcte (c'est-à-dire définir la couche d'entrée du modèle) est devenue l'une des étapes les plus critiques de la conception d'un modèle. Je consacre généralement plus de temps de développement à la conception de la forme des données d'entrée qu'à toute autre chose. Pour être clair, nous n'avons pas besoin de traiter une structure de données brutes donnée, il suffit de trouver un modèle approprié. La capacité des réseaux de neurones à gérer en interne l’ingénierie et la sélection des fonctionnalités (« modélisation de bout en bout ») ne nous dispense pas d’optimiser la structure des données d’entrée. Nous devons exploiter les données de manière à ce que les modèles puissent en tirer le meilleur sens et prendre les décisions les plus éclairées (c'est-à-dire les prédictions les plus précises). Le facteur « secret » ici est l’information contextuelle. Autrement dit, nous devrions enrichir les données brutes avec autant de contexte que possible.
Alors, qu'est-ce que j'entends spécifiquement par « contexte » ci-dessus ? Laissez-nous vous donner un exemple. Mary est une data scientist qui commence un nouvel emploi en développant un système de prévision des ventes pour une entreprise de vente au détail de boissons. En bref, sa tâche est la suivante : étant donné un magasin spécifique et un produit spécifique (limonade, jus d'orange, bière...), son modèle doit être capable de prédire les ventes futures de ce produit dans le magasin spécifique. Les prédictions seront appliquées à des milliers de produits différents proposés par des centaines de magasins différents. Jusqu'à présent, le système fonctionne bien. La première journée de Mary s'est déroulée au service commercial, où le travail de prévision était déjà effectué, quoique manuellement par Peters, un comptable commercial expérimenté. Son objectif est de comprendre sur quelle base l'expert du domaine détermine la demande future pour un produit particulier. En tant que bonne data scientist, Mary prévoit que les années d’expérience de Peters seront très utiles pour définir quelles données pourraient être les plus précieuses pour le modèle. Pour le savoir, Mary a posé deux questions à Peters.
Première question : « Quelles données avez-vous analysées pour calculer le nombre de bouteilles d'une marque spécifique de limonade que nous vendrons dans nos magasins à Berlin le mois prochain ? Comment avez-vous interprété les données ? »
Peters a répondu : « Au fil du temps, nous avons a fait ses premiers pas dans la vente de limonade à Berlin". Il a ensuite dessiné le graphique suivant pour illustrer sa stratégie :
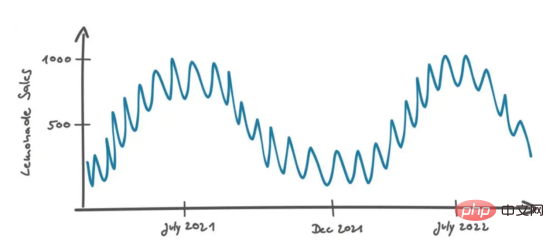
Dans le graphique ci-dessus, on voit qu'il y a une courbe continue avec un pic en juillet/août (heure d'été de Berlin). En été, lorsque la température est plus élevée, les gens préfèrent manger des collations, ce qui augmente les ventes de produits. Sur une échelle de temps plus petite (environ un mois), on constate que les ventes fluctuent dans une fourchette d'environ 10 articles, éventuellement en raison d'événements imprévisibles (bruit aléatoire).
Peters a poursuivi : "Quand je vois le schéma répétitif d'augmentation des ventes en été et de diminution des ventes en hiver, je pense qu'il est très probable que cela se produise également à l'avenir, j'estime donc les ventes en fonction de cette possibilité." Cela semble raisonnable.
Peters interprète les données de ventes dans un contexte temporel, où la distance entre deux points de données est définie par leur différence de temps. Si les données ne sont pas classées par ordre chronologique, elles sont difficiles à interpréter. Par exemple, si nous examinions uniquement la répartition des ventes dans un histogramme, le contexte temporel serait perdu et notre meilleure estimation des ventes futures serait une valeur globale, telle que la médiane de toutes les valeurs.
Le contexte apparaît lorsque les données sont triées d'une certaine manière.
Il va sans dire que vous devez alimenter votre modèle de prévision des ventes avec des données de ventes historiques dans le bon ordre chronologique pour enregistrer le contexte « gratuit » de la base de données. Les modèles d'apprentissage profond sont très puissants car ils sont très efficaces pour intégrer des informations contextuelles, à l'instar de notre cerveau (dans ce cas, bien sûr, celui de Peters).
Vous êtes-vous déjà demandé : pourquoi l'apprentissage profond est si efficace pour la classification d'images et la détection d'objets d'image ? Parce qu'il y a déjà beaucoup de contexte « naturel » dans les images ordinaires : les images sont essentiellement des points de données d'intensité lumineuse, disposés selon deux dimensions d'arrière-plan, à savoir la distance spatiale dans la direction x et l'espacement spatial dans la direction y. Et le cinéma, en tant que forme animée (une séquence temporelle d'images), ajoute le temps comme troisième dimension contextuelle.
Le contexte étant très bénéfique pour la prédiction, nous pouvons améliorer les performances du modèle en ajoutant davantage de dimensions contextuelles, même si ces dimensions sont déjà incluses dans les données d'origine. Nous y sommes parvenus grâce à des méthodes intelligentes d’ingénierie des données, comme décrit ci-dessous.
Nous devons servir les données de manière à ce que les modèles puissent en tirer le meilleur sens et prendre les décisions les plus éclairées. Je consacre généralement plus de temps de développement à la conception de la forme des données d'entrée qu'à toute autre chose.
Reprenons la discussion de Mary et Peters. Mary savait que dans la plupart des cas, les données réelles n'étaient pas aussi bonnes que le graphique ci-dessus, elle a donc légèrement modifié le graphique pour qu'il ressemble à ceci :
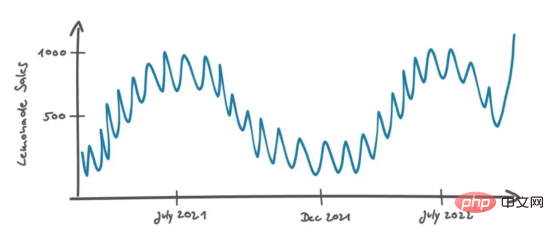
La deuxième question posée par Mary était : "Et si le Le dernier point de données de vente est supérieur au niveau de bruit habituel ? Cela pourrait être un scénario réel. Peut-être que le produit mène une campagne marketing réussie. Peut-être que la recette a changé et a désormais meilleur goût. Dans ce cas, l'effet est durable. et les ventes futures resteront au même niveau élevé. Ou cela peut simplement être une anomalie due à des événements aléatoires. Par exemple, une classe en visite à Berlin entre dans le magasin et tous les enfants achètent une bouteille de cette limonade. Dans ce cas, la croissance des ventes n'est pas stable et ne peut être considérée que comme des données de bruit. Dans ce cas, comment décidez-vous s'il s'agit d'un réel effet sur les ventes ?
Vous pouvez voir Peters se gratter la tête avant de répondre : "Dans ce cas, je regarde les ventes dans des magasins similaires à Berlin. Par exemple, nos magasins à Hambourg et Munich. Les magasins sont comparables car ils sont également situés dans les grandes villes allemandes. Je n'envisagerais pas un magasin dans un zone rurale car je m'attendrais à des clients différents avec des goûts et des préférences différents. "
Il a additionné les courbes de ventes des autres magasins avec deux scénarios possibles. "Si je constate une augmentation des ventes à Berlin, je pense que c'est du bruit. Mais si je constate une augmentation des ventes de limonade à Hambourg et à Munich, je m'attends à ce que ce soit un effet constant." Dans certaines situations plutôt difficiles, Peters considère davantage de données pour prendre des décisions plus éclairées. Il ajoute une nouvelle dimension de données dans le contexte des différents magasins. Comme mentionné ci-dessus, le contexte apparaît lorsque les données sont ordonnées d'une certaine manière. Pour créer un contexte de magasin, nous devons d'abord définir une mesure de distance pour trier les données des différents magasins en conséquence. Par exemple, Peters différencie les magasins en fonction de la taille de la ville dans laquelle ils se trouvent.
En appliquant certaines compétences en programmation SQL et Numpy, nous pouvons fournir un contexte similaire pour nos modèles. Tout d’abord, nous devons comprendre la taille de la population de la ville où se trouvent les magasins de notre entreprise ; ensuite, nous mesurons la distance entre tous les magasins en fonction des différences de population ; enfin, nous combinons toutes les données de ventes dans une matrice 2D, où la première dimension est Le temps, la deuxième dimension est la mesure de la distance entre nos magasins.
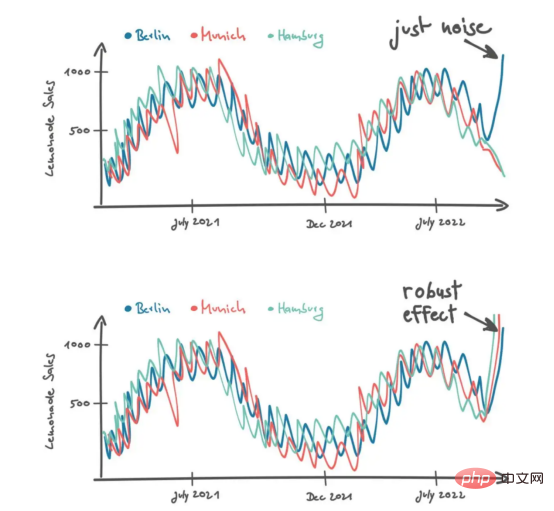
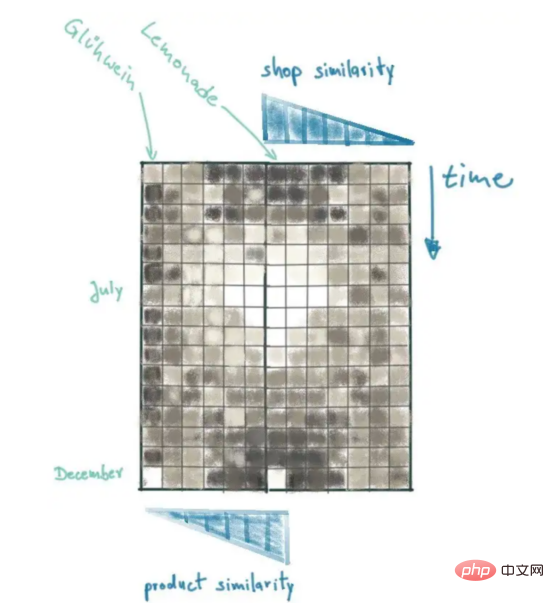
La matrice des ventes dans la figure fournit un bon résumé des ventes récentes de limonade, et les tendances qui en résultent peuvent être expliquées visuellement. Jetez un œil au point de données dans le coin inférieur gauche de la matrice des ventes : il s’agit des données de ventes les plus récentes pour Berlin. Notez que ce point positif est probablement une exception, car les magasins similaires (par exemple Burgers) ne répéteront pas la forte augmentation des ventes. En revanche, le pic des ventes de juillet a été reproduit par des magasins similaires.
Nous devons donc toujours ajouter une métrique de distance pour créer du contexte.
Maintenant, nous traduisons la déclaration de Peters en termes mathématiques qui peuvent être modélisés en fonction de la taille de la population de la ville où se trouve le produit. Lors de l’ajout de nouvelles dimensions contextuelles, nous devons considérer très attentivement la mesure de distance correcte. Cela dépend des facteurs qui affectent l'entité que nous voulons prédire. Les facteurs d'influence dépendent entièrement du produit et l'indicateur de distance doit être adapté en conséquence. Par exemple, si vous examinez les ventes de bière en Allemagne, vous constaterez que les consommateurs sont susceptibles d'acheter des produits auprès de brasseries locales (il existe environ 1 300 brasseries différentes à travers le pays).
Les gens de Cologne boivent généralement du Kursch, mais lorsque vous conduisez une demi-heure au nord de la région de Düsseldorf, les gens évitent le Kursch au profit de la bière Al Special, plus foncée et plus maltée. Par conséquent, dans le cas des ventes de bière allemandes, modéliser la distance entre les magasins en fonction de la distance géographique pourrait être un choix raisonnable. Ce n’est cependant pas le cas pour d’autres catégories de produits (limonade, jus d’orange, boissons pour sportifs…).
En ajoutant une dimension contextuelle supplémentaire, nous avons créé un ensemble de données riche en contexte dans lequel des modèles prédictifs potentiels peuvent obtenir des profils de ventes de limonade à différents moments et dans différents magasins. Cela permet au modèle de prendre des décisions éclairées concernant les ventes futures dans le magasin de Berlin en examinant l'historique des ventes récentes et en regardant à gauche et à droite les magasins similaires situés dans d'autres endroits.
À partir de là, nous pouvons ajouter davantage le type de produit comme dimension contextuelle supplémentaire. Par conséquent, nous enrichissons la matrice des ventes avec des données provenant d’autres produits, classés en fonction de leur similarité avec la limonade (notre cible de prédiction). Encore une fois, nous devons trouver une bonne métrique de similarité. Le Coca ressemble-t-il plus à de la limonade qu'à du jus d'orange ? Sur quelles données peut-on définir des classements de similarité ?
Dans le cas des magasins, nous avons une mesure continue, qui est la population de la ville. Nous parlons maintenant de catégories de produits. Ce que nous voulons vraiment trouver, ce sont des produits qui ont un comportement de vente similaire à celui de la limonade. Contrairement à la limonade, nous pouvons effectuer une analyse de corrélation croisée des données de ventes résolues dans le temps pour tous les produits. De cette manière, nous obtenons un coefficient de corrélation de Pearson pour chaque produit, qui nous indique à quel point les modèles de vente sont similaires. Les boissons gazeuses telles que le Coca peuvent avoir des tendances de vente similaires à celles de la limonade, les ventes augmentant au cours de l'été. D'autres produits se comporteront complètement différemment. Par exemple, le Gühwein, un vin chaud et doux servi sur les marchés de Noël, peut connaître un fort pic de ventes en décembre et n'avoir pratiquement aucune vente pendant le reste de l'année.
【Note du traducteur】Résolu dans le temps : Le nom de la physique ou des statistiques. D'autres mots couramment utilisés à ce sujet sont diagnostic résolu dans le temps, spectre résolu dans le temps, etc.
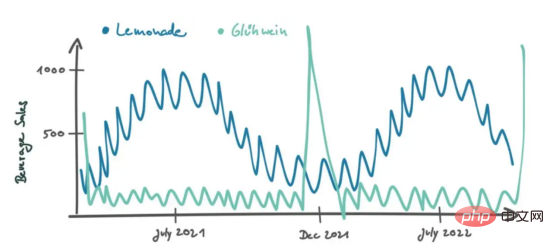
L'analyse de corrélation croisée montrera que le vin Glühwein a un coefficient de Pearson plus faible (en fait négatif), tandis que le Coca a un coefficient de Pearson plus élevé.
Bien qu'en ajoutant une troisième dimension à la matrice de vente, nous pouvons inclure le contexte du produit en rejoignant la deuxième dimension dans la direction opposée. Cela place les données de vente les plus importantes (ventes de limonade à Berlin) au centre :
Bien que nous disposions désormais d'une structure de données très informative, jusqu'à présent, nous n'avons qu'une seule fonctionnalité : le nombre de produits vendus pour un produit spécifique dans un magasin spécifique à une heure précise. Cela peut déjà suffire pour faire des prévisions robustes et précises, mais nous pouvons également ajouter des informations utiles supplémentaires provenant d’autres sources de données.
Par exemple, le comportement d’achat de boissons dépendra probablement de la météo. Par exemple, pendant les étés très chauds, la demande de limonade peut augmenter. Nous pouvons fournir des données météorologiques (telles que la température de l’air) comme deuxième couche de la matrice. Les données météorologiques seront classées dans le même contexte (emplacement du magasin et produit) que les données de vente. Pour différents produits, nous obtiendrons les mêmes données sur la température de l’air. Cependant, selon les heures et les emplacements des magasins, nous verrons qu'il existe des différences, qui peuvent fournir des informations utiles pour les données.

De cette façon, nous disposons d'une matrice tridimensionnelle qui contient en outre des données de ventes et de température. Notez que nous n'avons pas ajouté de dimension contextuelle supplémentaire en incluant des données de température. Comme je l'ai déjà souligné, le contexte entre en jeu lorsque les données sont triées d'une certaine manière. Pour le contexte de données que nous avons établi, nous avons trié les données en fonction du temps, de la similarité des produits et de la similarité des magasins. Cependant, l’ordre des caractéristiques (dans notre cas, le long de la troisième dimension de la matrice) n’a pas d’importance. En fait, notre structure de données est équivalente à une image couleur RVB. Dans une image RVB, nous avons deux dimensions contextuelles (dimensions spatiales x et y) et trois couches de couleurs (rouge, vert, bleu). Pour une interprétation correcte de l'image, l'ordre des canaux de couleur est arbitraire. Une fois que vous l’avez défini, vous devez le garder en ordre. Mais pour les données organisées dans un contexte spécifique, nous n’avons pas de métrique de distance.
En bref, la structure des données d'entrée ne peut pas être déterminée à l'avance. Il est donc temps pour nous de laisser libre cours à notre créativité et à notre intuition pour découvrir de nouveaux indicateurs de faisabilité.
En ajoutant deux contextes supplémentaires et une couche de fonctionnalités supplémentaire aux données de ventes résolues dans le temps, nous obtenons une « image » bidimensionnelle avec deux « canaux » (ventes et température). Cette structure de données fournit une vue complète des ventes récentes de limonade dans un magasin spécifique, ainsi que des informations sur les ventes et la météo de magasins similaires et de produits similaires. Les structures de données que nous avons créées jusqu'à présent sont bien adaptées à l'interprétation par des réseaux de neurones profonds, contenant par exemple plusieurs couches convolutives et unités LSTM. Mais en raison du manque d'espace, je ne vais pas expliquer comment commencer à concevoir un réseau neuronal approprié sur cette base. Cela pourrait faire l’objet de mon article de suivi.
Je veux que vous puissiez avoir vos propres idées, et même si la structure de vos données d'entrée n'est pas prédéterminée, vous pouvez (devriez) utiliser toute votre créativité et votre intuition pour l'étendre.
De manière générale, les structures de données riches en contexte ne sont pas gratuites. Afin de prédire divers produits dans tous les magasins de l'entreprise, nous devons générer des milliers d'informations de profil de vente contextuellement riches (une matrice pour la gamme de produits de chaque magasin). Vous devez effectuer beaucoup de travail supplémentaire pour concevoir des mesures de traitement et de mise en mémoire tampon efficaces afin de mettre les données sous la forme dont vous avez besoin et de les fournir pour les cycles ultérieurs de formation rapide et de prédiction du réseau neuronal. Bien sûr, vous obtenez ainsi le modèle d'apprentissage profond souhaité, capable de faire des prédictions précises et d'être très robuste même avec des données bruitées, car il peut sembler capable de « enfreindre les règles » et de prendre des décisions très judicieuses.
Zhu Xianzhong, rédacteur en chef de la communauté 51CTO, blogueur expert 51CTO, conférencier, professeur d'informatique dans une université de Weifang et vétéran de l'industrie de la programmation indépendante.
Titre original : Context-Enriched Data : The Secret Superpower for Your Deep Learning Model, auteur : Christoph Möhl
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Algorithme de remplacement de page
Algorithme de remplacement de page
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 Lequel est le plus simple, thinkphp ou laravel ?
Lequel est le plus simple, thinkphp ou laravel ?
 Qu'est-ce que Bitcoin ? Est-ce légal ?
Qu'est-ce que Bitcoin ? Est-ce légal ?
 Comment résoudre le problème de la non-suppression de fichiers sur l'ordinateur
Comment résoudre le problème de la non-suppression de fichiers sur l'ordinateur
 qu'est-ce que le HDMI
qu'est-ce que le HDMI
 Comment retirer de l'argent de Yiouokex
Comment retirer de l'argent de Yiouokex
 Comment changer l'adresse IP sous Linux
Comment changer l'adresse IP sous Linux








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



