


Bonjour à tous ! Je suis frère Tigre.
En tant qu'analystes de données, nous devons souvent créer des graphiques d'analyse statistique. Mais lorsqu’il y a trop de rapports, leur création nous prend souvent la plupart de notre temps. Cela nous a empêché de consacrer beaucoup de temps à l’analyse des données. Mais en tant qu'analystes de données, nous devrions faire de notre mieux pour découvrir les informations pertinentes cachées derrière les données dans les tableaux et les graphiques, au lieu de simplement créer des tableaux et des graphiques statistiques, puis d'envoyer des rapports.
L'automatisation peut toujours gagner du temps et améliorer l'efficacité de notre travail. Laissez notre programmation réduire autant que possible le couplage du code d'implémentation de chaque fonction et mieux maintenir le code. Cela nous fera gagner beaucoup de temps et nous libérera pour effectuer un travail plus précieux et plus significatif.
Si l'effet de codage est correct, il peut être utilisé pour toujours. S'il est effectué manuellement, certaines erreurs peuvent être commises. Il est plus rassurant de s'en remettre à un programme fixe. Lorsque les exigences changent, seule une partie du code peut être modifiée pour résoudre le problème.
Tout d'abord, nous devons formuler les rapports dont nous avons besoin en fonction des besoins de l'entreprise. Tous les rapports n'ont pas besoin d'être automatisés. Certaines données complexes d'indicateurs de développement secondaires nécessitent une programmation automatisée, ce qui est plus compliqué. , et divers BUG peuvent être cachés. Par conséquent, nous devons résumer les caractéristiques des rapports que nous utilisons dans notre travail. Voici plusieurs aspects que nous devons prendre en compte de manière approfondie :
Pour certains tableaux souvent utilisés en entreprise, nous devrons peut-être le faire. Inclus dans les procédures automatisées. Par exemple, liste d'informations sur les clients, rapport sur les flux de ventes, rapport sur les pertes commerciales, rapports mensuels et annuels, etc.
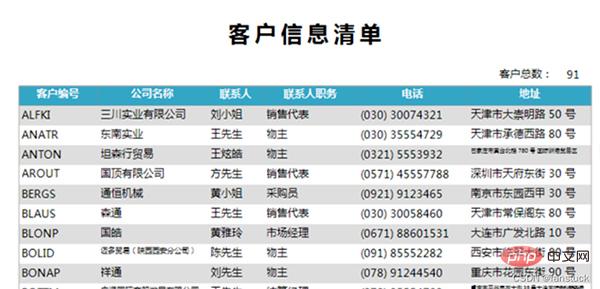
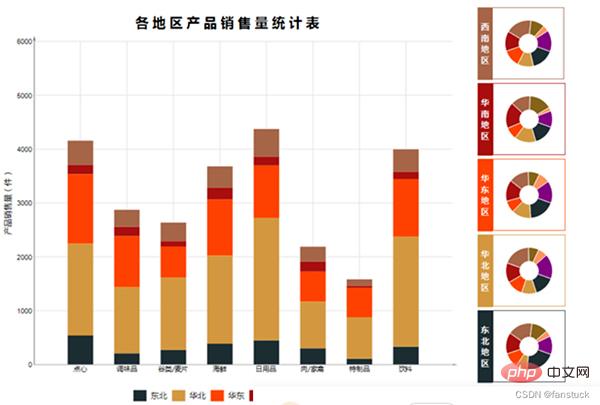
Il est nécessaire d'automatiser ces rapports qui sont fréquemment utilisés. Pour les rapports qui doivent être utilisés occasionnellement, ou pour les indicateurs de développement secondaires, ou les rapports qui nécessitent de copier des statistiques, il n'est pas nécessaire d'automatiser ces rapports.
Cela équivaut au coût et au taux d'intérêt S'il est difficile d'automatiser certains rapports et dépasse le temps requis pour notre analyse statistique ordinaire, il n'est pas nécessaire de l'automatiser. Par conséquent, lorsque vous démarrez un travail d'automatisation, vous devez mesurer si le temps passé à développer des scripts ou le temps passé à créer manuellement des tableaux est plus court. Bien sûr, je fournirai un ensemble de solutions de mise en œuvre, mais uniquement pour certains rapports simples et couramment utilisés.
Pour chaque processus et étape de notre rapport, chaque entreprise est différente. Nous devons coder pour mettre en œuvre les fonctions de chaque étape en fonction du scénario commercial. Par conséquent, le processus que nous créons doit être cohérent avec la logique métier, et le programme que nous créons doit également être logique.
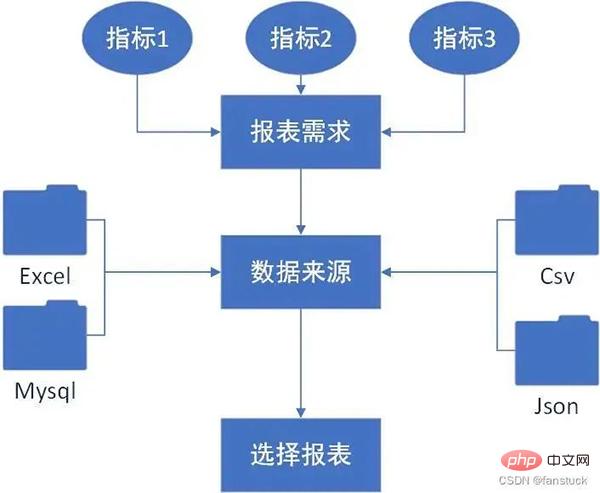
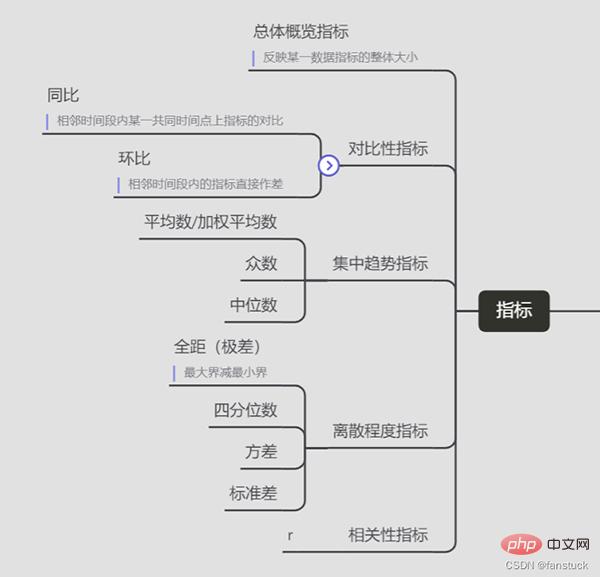
Nous devons d'abord savoir de quels indicateurs nous avons besoin :
Indicateurs
Reflètent la taille globale d'un certain indicateur de données
Différence directe entre les indicateurs de périodes adjacentes
Comparaison des indicateurs à un moment commun dans des périodes adjacentes
Nous prenons un rapport simple pour simuler et mettre en œuvre :
Tout d'abord, nous devons comprendre d'où proviennent nos données, c'est-à-dire la source de données. Notre traitement final des données est converti en DataFrame pour l'analyse, la source de données doit donc être convertie sous forme DataFrame :
import pandas as pd
import json
import pymysql
from sqlalchemy import create_engine
# 打开数据库连接
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
passwd='xxxx',
charset = 'utf8'
)
engine=create_engine('mysql+pymysql://root:xxxx@localhost/mysql?charset=utf8')
def read_excel(file):
df_excel=pd.read_excel(file)
return df_excel
def read_json(file):
with open(file,'r')as json_f:
df_json=pd.read_json(json_f)
return df_json
def read_sql(table):
sql_cmd ='SELECT * FROM %s'%table
df_sql=pd.read_sql(sql_cmd,engine)
return df_sql
def read_csv(file):
df_csv=pd.read_csv(file)
return df_csvLe code ci-dessus peut être utilisé normalement via des tests, mais la fonction de lecture de pandas est conçue pour lire différentes formes de fichiers Les paramètres de la fonction de lecture ont également des significations différentes et doivent être ajustés directement en fonction de la forme du tableau.
D'autres fonctions de lecture seront ajoutées après la rédaction de l'article. Sauf que read_sql doit se connecter à la base de données, les autres sont relativement simples.
Prenons les informations utilisateur comme exemple :
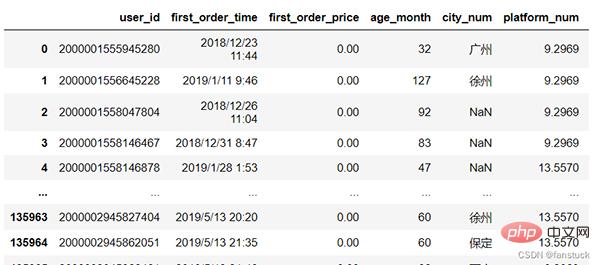
我们需要统计的指标为:
#将城市空值的一行删除 df=df[df['city_num'].notna()] #删除error df=df.drop(df[df['city_num']=='error'].index) #统计df = df.city_num.value_counts()

我们仅获取前10名的城市就好了,封装为饼图:
def pie_chart(df):
#将城市空值的一行删除
df=df[df['city_num'].notna()]
#删除error
df=df.drop(df[df['city_num']=='error'].index)
#统计
df = df.city_num.value_counts()
df.head(10).plot.pie(subplots=True,figsize=(5, 6),autopct='%.2f%%',radius = 1.2,startangle = 250,legend=False)
pie_chart(read_csv('user_info.csv'))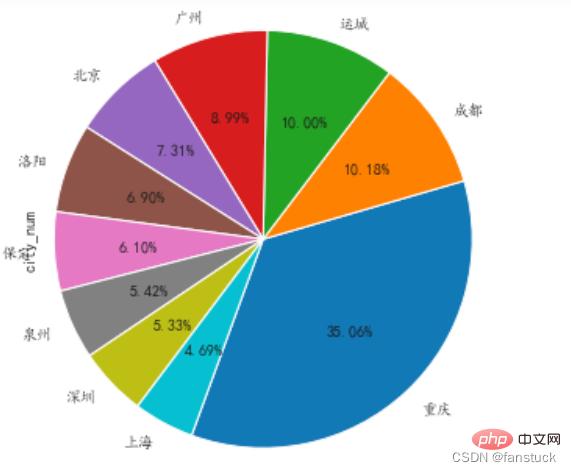
将图表保存起来:
plt.savefig('fig_cat.png')要是你觉得matplotlib的图片不太美观的话,你也可以换成echarts的图片,会更加好看一些:
pie = Pie()
pie.add("",words)
pie.set_global_opts(title_opts=opts.TitleOpts(title="前十地区"))
#pie.set_series_opts(label_opts=opts.LabelOpts(user_df))
pie.render_notebook()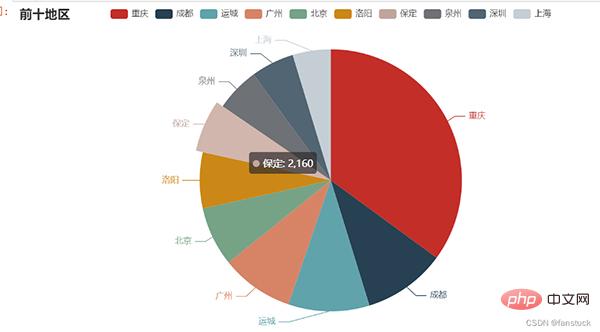
封装后就可以直接使用了:
def echart_pie(user_df):
user_df=user_df[user_df['city_num'].notna()]
user_df=user_df.drop(user_df[user_df['city_num']=='error'].index)
user_df = user_df.city_num.value_counts()
name=user_df.head(10).index.tolist()
value=user_df.head(10).values.tolist()
words=list(zip(list(name),list(value)))
pie = Pie()
pie.add("",words)
pie.set_global_opts(title_opts=opts.TitleOpts(title="前十地区"))
#pie.set_series_opts(label_opts=opts.LabelOpts(user_df))
return pie.render_notebook()
user_df=read_csv('user_info.csv')
echart_pie(user_df)可以进行保存,可惜不是动图:
from snapshot_selenium import snapshot make_snapshot(snapshot,echart_pie(user_df).render(),"test.png")
保存为网页的形式就可以自动加载JS进行渲染了:
echart_pie(user_df).render('problem.html')
os.system('problem.html')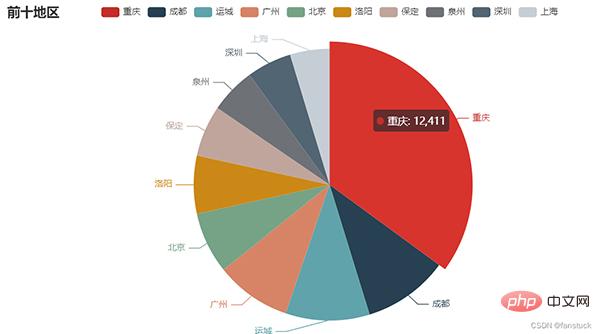
做出来的一系列报表一般都要发给别人看的,对于一些每天需要发送到指定邮箱或者需要发送多封报表的可以使用Python来自动发送邮箱。
在Python发送邮件主要借助到smtplib和email这个两个模块。
不同种类的邮箱服务器连接地址不一样,大家根据自己平常使用的邮箱设置相应的服务器进行连接。这里博主用网易邮箱展示:
首先需要开启POP3/SMTP/IMAP服务:
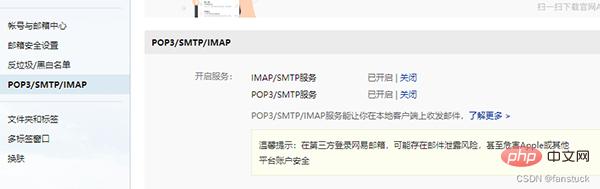
之后便可以根据授权码使用python登入了。
import smtplib
from email import encoders
from email.header import Header
from email.utils import parseaddr,formataddr
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
#发件人邮箱
asender="fanstuck@163.com"
#收件人邮箱
areceiver="1079944650@qq.com"
#抄送人邮箱
acc="fanstuck@163.com"
#邮箱主题
asubject="谢谢关注"
#发件人地址
from_addr="fanstuck@163.com"
#邮箱授权码
password="####"
#邮件设置
msg=MIMEMultipart()
msg['Subject']=asubject
msg['to']=areceiver
msg['Cc']=acc
msg['from']="fanstuck"
#邮件正文
body="你好,欢迎关注fanstuck,您的关注就是我继续创作的动力!"
msg.attach(MIMEText(body,'plain','utf-8'))
#添加附件
htmlFile = 'C:/Users/10799/problem.html'
html = MIMEApplication(open(htmlFile , 'rb').read())
html.add_header('Content-Disposition', 'attachment', filename='html')
msg.attach(html)
#设置邮箱服务器地址和接口
smtp_server="smtp.163.com"
server = smtplib.SMTP(smtp_server,25)
server.set_debuglevel(1)
#登录邮箱
server.login(from_addr,password)
#发生邮箱
server.sendmail(from_addr,areceiver.split(',')+acc.split(','),msg.as_string())
#断开服务器连接
server.quit()运行测试:
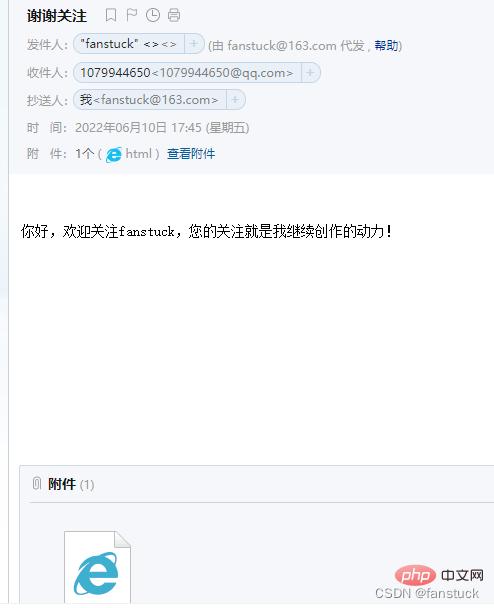
下载文件:
完全没问题!!!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



