
 développement back-end
Tutoriel Python
Lors de l'apprentissage de Python, comment ne pas maîtriser ces 22 bibliothèques couramment utilisées ?
développement back-end
Tutoriel Python
Lors de l'apprentissage de Python, comment ne pas maîtriser ces 22 bibliothèques couramment utilisées ?
Lors de l'apprentissage de Python, comment ne pas maîtriser ces 22 bibliothèques couramment utilisées ?


Quel est l’état actuel de l’utilisation de Python dans diverses industries à travers le monde ?
Cette question est l’intention initiale de ma rédaction de cet article. J'ai trouvé les 22 packages Python les plus couramment utilisés, dans l'espoir de vous inspirer.
J'ai d'abord répertorié les packages Python les plus téléchargés sur PyPI au cours de l'année écoulée. Jetons un coup d'œil à ce que font ces packages, comment ils interagissent les uns avec les autres et pourquoi ils sont si populaires.
1. Urllib3
893 millions de téléchargements
Urllib3 est un client HTTP pour Python, qui fournit de nombreuses fonctions qui ne sont pas disponibles dans la bibliothèque standard Python.
- Thread-safe
- Pool de connexions
- Vérification SSL/TLS côté client
- Téléchargement de fichiers à l'aide d'un encodage multipart
- Fonctions auxiliaires pour la retransmission des requêtes et la gestion des redirections HTTP
- Prend en charge l'encodage gzip et deflate
- Prise en charge HTTP et SOCKS proxy
Bien qu'il s'appelle Urllib3, ce n'est pas un successeur de urllib2 fourni avec Python. Si vous souhaitez utiliser autant que possible les fonctionnalités de base de Python (par exemple, si elles ne peuvent pas être installées en raison de certaines restrictions), jetez un œil à urllib.request.
Pour les utilisateurs finaux, je recommande fortement le package de requêtes (voir le sixième élément de la liste). Urllib3 se classe premier car près de 1 200 packages en dépendent, et nombre de ces packages figurent également en tête de liste.
2, Six
732 millions de téléchargements
Six est un outil de compatibilité Python 2 et Python 3. Le but de ce projet est de permettre au code de s'exécuter à la fois sur Python 2 et Python 3.
Il fournit de nombreuses fonctions qui masquent les différences de syntaxe entre Python 2 et Python 3. L'exemple le plus simple à comprendre est six.print_(). Dans Python 3, vous devez utiliser la fonction print() lors de la sortie, tandis que dans Python 2, l'impression sans parenthèses est utilisée. Par conséquent, l’utilisation de six.print_() prend en charge les deux langues.
Points clés :
- Le nom du package six vient de 2 x 3 = 6
- Les bibliothèques similaires incluent future
- Si vous souhaitez convertir le code en Python 3 (Python 2 n'est plus supporté), vous pouvez jetez un œil à 2to3
Bien que je comprenne que ce package est si populaire, j'espère toujours que les gens abandonneront Python 2 dès que possible, d'autant plus que Python 2 n'est officiellement plus supporté à partir du 1er janvier 2020.
3. Botocore, boto3, s3transfer, awscli
Réunissez ces projets :
- botocore : n°3, 660 millions de téléchargements
- s3transfer : n°7, 584 millions de téléchargements
- awscli : n°17, 394 millions de téléchargements
- boto3 : n°22, 329 millions de téléchargements
Botocore est l'interface sous-jacente d'AWS. botocore est la base de la bibliothèque boto3 (#22), qui vous donne accès aux services S3, EC2 et autres d'Amazon.
Botocore est également la base d'AWS-CLI, l'interface de ligne de commande pour AWS.
s3transfer (7th) est une bibliothèque Python permettant de gérer les transferts S3. La bibliothèque est encore en développement et sa page d'accueil recommande toujours de ne pas l'utiliser, ou du moins de corriger la version lors de son utilisation, car son API peut changer même entre des numéros de version mineurs. boto3, AWS-CLI et de nombreux autres projets s'appuient sur s3transfer.
Le classement si élevé des bibliothèques liées à AWS montre à quel point les services AWS sont populaires.
4. Pip
627 millions de téléchargements
Je suppose que beaucoup de gens connaissent et aiment pip (outil d'installation de packages Python). Utiliser pip pour installer des packages à partir de Python Package Index et d'autres référentiels tels que des miroirs locaux ou des référentiels personnalisés contenant des logiciels privés se fait sans effort.
Faits intéressants sur pip :
- Le nom de Pip est une définition récursive : Pip installe des packages
- Pip est très facile à utiliser. Pour installer un package, exécutez simplement pip install . Pour supprimer, exécutez simplement pip uninstall .
- Le plus grand avantage de Pip est qu'il peut installer une série de packages, généralement placés dans le fichier exigences.txt. Ce fichier peut également spécifier le numéro de version détaillé de chaque package. La plupart des projets Python incluront ce fichier.
- Utilisez pip en conjonction avec virtualenv (#57) pour créer des environnements prévisibles et indépendants qui n'interagissent pas avec le propre environnement du système.
5, python-dateutil
617 millions de téléchargements
Le module Python-dateutil fournit de puissantes extensions fonctionnelles au module datetime standard. Tout ce que Python datetime ordinaire ne peut pas faire peut être fait avec python-dateutil.
De nombreuses fonctions très intéressantes peuvent être réalisées avec cette bibliothèque. Je vais juste vous donner un exemple très utile : analyse floue des chaînes de date à partir des fichiers journaux :
from dateutil.parser import parse logline = 'INFO 2020-01-01T00:00:01 Happy new year, human.' timestamp = parse(log_line, fuzzy=True) print(timestamp) # 2020-01-01 00:00:01
6, requêtes
611 millions de téléchargements
Requêtes Basées sur la bibliothèque téléchargée numéro un urllib3. Avec lui, l’envoi de demandes est extrêmement simple. De nombreuses personnes préfèrent les requêtes à urllib3, il y a donc probablement plus d'utilisateurs finaux de requêtes que urllib3. Ce dernier est de niveau inférieur et apparaît généralement comme une dépendance d'autres projets.
L'exemple suivant montre à quel point les requêtes sont faciles à utiliser :
import requests
r = requests.get('https://api.github.com/user', auth=('user', 'pass'))
r.status_code
# 200
r.headers['content-type']
# 'application/json; charset=utf8'
r.encoding
# 'utf-8'
r.text
# u'{"type":"User"...'
r.json()
# {u'disk_usage': 368627, u'private_gists': 484, ...}
7、s3transfer
第3、7、17和22名互相关联,所以请参见第3名的介绍。
8、Certifi
5.52亿次下载
近年来,几乎所有网站都开始使用SSL,这一点可以从地址栏中的锁图标看出来,该图标的意思是网站是安全的、加密的,可以避免窃听。
加密基于SSL证书,SSL证书由可信的公司或非营利组织负责签发,如 LetsEncrypt。这些组织会对利用它们的证书对签发的证书进行数字签名。
利用这些证书的公开部分,浏览器就可以验证网站的签名,从而证明你访问的是真正的网站,而且别人没有在窃听数据。
Python 也可以做到同样的功能,这就需要用到 certifi。它和 Chrome、Firefox 和 Edge 等Web浏览器中包含的根证书集合没有什么区别。
Certifi 是一个根证书集合,这样 Python 代码就可以验证SSL证书的可信度。
许多项目都信赖并依赖 certifi,可以在这里看到这些项目。这也是为何该项目排名如此高的原因。
9、Idna
5.27亿次下载
根据 PyPI 的页面,idna提供“对于RFC5891中定义的IDNA协议(Internationalised Domain Names in Applications)的支持”。
我们来看看 idna 是什么意思:
IDNA 是处理包含非 ASCII 字符的域名的规则。但原始的域名不是已经支持非 ASCII 字符了吗?那么问题何在?
问题是许多应用程序(如Email客户端和Web浏览器等)并不支持非 ASCII 字符。或者更具体地说,Email 和 HTTP 协议并不支持这些字符。
在许多国家这并不是问题,但像中国、俄罗斯、德国、印尼等国家就很不方便。因此,这些国家的一些聪明人联合起来提出了 IDNA,也并非完全偶然。
IDNA 的核心是两个函数:ToASCII 和 ToUnicode。ToASCCI 会将国际化的 Unicode 域名转换成 ASCII 字符串,而 ToUnicode 会做相反的处理。在 IDNA 包中,这两个函数叫做 idna.encode() 和 idna.decode(),参见下面的例子:
import idna
idna.encode('ドメイン.テスト')
# b'xn--eckwd4c7c.xn--zckzah'
print(idna.decode('xn--eckwd4c7c.xn--zckzah'))
# ドメイン.テスト
该编码的详细内容可以参见 RFC3490。
10、PyYAML
5.25亿次下载
YAML 是一种数据序列化格式。它的设计目标是同时方便人类和机器阅读——人类很容易读懂,计算机解析也不难。
PyYAML 是 Python 的 YAM 解析器和编码器,也就是说它可以读写 YAML 格式。它可以将任何 Python 对象编码为 YAML:列表,字典,甚至类实例都可以。
Python 提供了自己的配置管理器,但 YAML 提供的功能远胜于 Python 自带的 ConfigParser(只能使用最基本的.ini文件)。
例如,YAML 能存储任何数据类型:boolean,list,float等。ConfigParse 的内部一切都保存为字符串。如果你要用 ConfigParser 来加载证书,就需要指明你需要的是整数:
config.getint(“section”, “my_int”)
而 pyyaml 能够自动识别类型,因此只需这样就能获得 int:
config[“section”][“my_int”]
YAML 还允许任意深度的嵌套,尽管并非每个项目都需要,但非常方便。
你可以自行决定使用哪一个,但许多项目都使用 YAML 作为配置文件,因此该项目的流行度非常高。
11、pyasn1
5.12亿次下载
像 IDNA 一样,这个项目的描述的信息量也非常大:
ASN.1 类型和 DER/BER/CER 编码(X.208)的纯 Python 实现。
幸运的是,我们依然能找到这个几十年之久的标准的许多资料。ASN.1 是 Abstract Syntax Notation One(抽象语法记法一)的缩写,是数据序列化的鼻祖。它来自于通讯行业。也许你知道 protocol buffer 或者 Apache Thrift 吧?ASN.1正是它们的1984年版本。
ASN.1 描述了一种不同系统之间的跨平台的接口,可以通过该接口发送数据结构。
还记得第8名的 certifi 吗?ASN.1 用于定义 HTTPS 协议以及许多其他加密系统中使用的证书的格式。ASN.1 还广泛用于 SNMP、LDAP、Kerberos、UMTS、LTE 和 VOIP 等协议中。
它是个非常复杂的标准,人们已经发现某些实现充满了脆弱性。你可以看看 Reddit 上的这个关于 ASN.1 的讨论(https://www.reddit.com/r/programming/comments/1hf7ds/useful_old_technologies_asn1/)。
除非真正必要,否则我建议不要使用它。但由于许多地方都在使用该协议,因此许多包都依赖于它。
12、docutils
5.08亿次下载
Docutils 是一个模块化系统,用于将纯文本文档转换成其他格式,如 HTML、XML 和 LaTeX等。docutils 可以读取 reStructuredText 格式(一种类似于 MarkDown 的容易阅读的格式)的纯文本文档。
我猜你一定听说过 PEP 文档,甚至可能阅读过。PEP 文档是什么?
PEP 的意思是 Python Enhanced Proposal(Python增强提案)。PEP 是一篇设计文档,用于给 Pytho n社区提供信息,或者为 Python(或其处理器、环境)描述一个新特性。PEP 应该提供特性的精确的技术标准,并给出该特性的理由。
PEP 文档就是使用固定的 reStructuredText 模板,然后通过 docutils 转换成漂亮的文档。
Sphinx 的核心也使用了 docutils。Sphinx 用于创建文档项目。如果说 docutils 是一台机器,那么 Sphinx 就是一个工厂。它的最初设计目的是构建P ython 本身的文档,但许多其他项目也利用 Sphinx 来创建文档。
你一定度过 readthedocs.org 上的文档吧?那里的文档都是使用 Sphinx 和 docutils 创建的。
13、Chardet
5.01亿下载
你可以使用 chardet 模块来检查文件或数据流的字符集。在分析大量随机的文本时这个功能非常有用。但也可以用来判断远程下载的数据的字符串。
在安装 chardet 后,就可以使用命令行工具 chardetect,使用方法如下:
chardetect somefile.txt somefile.txt: ascii with confidence 1.0
也可以在程序中使用该库,参见文档(https://chardet.readthedocs.io/en/latest/usage.html)。
Requests 和许多其他包都依赖于 chardet。我估计不会有太多人直接使用 chardet,所以它的流行度肯定是来自于这些依赖。
14、RSA
4.92亿次下载
Rsa是 RSA 的纯 Python 实现。它支持如下功能:
- 加密和解密
- 签名和签名验证
- 根据 PKCS#1 version 1.5生成秘钥
它可以作为 Python 库使用,也可以在命令行上使用。
- RSA 名称中的三个字母来自于三个人的姓:Ron Rivest,Adi Shamir,和Leonard Adleman。他们于1977年发明了该算法。
- RSA 是最早出现的一批公钥加密系统,广泛用于安全数据传输。这种加密系统包括两个秘钥:一个是公钥,一个是私钥。使用公钥加密数据,然后该数据只能用私钥进行解密。
- RSA 算法很慢。通常并不使用 RSA 算法直接加密用户数据,而是用它来加密对称加密系统中使用的共享秘钥,因为对称加密系统速度很快,适合用来加密大量数据。
下面代码演示了 RSA 的使用方法:
import rsa
# Bob creates a key pair:
(bob_pub, bob_priv) = rsa.newkeys(512)
# Alice ecnrypts a message for Bob
# with his public key
crypto = rsa.encrypt('hello Bob!', bob_pub)
# When Bob gets the message, he
# decrypts it with his private key:
message = rsa.decrypt(crypto, bob_priv)
print(message.decode('utf8'))
# hello Bob!
假设 Bob 拥有私钥 private,Alice 就能确信只有 Bob 才能阅读该信息。
但 Bob 并不能确信 Alice 是信息的发送者,因为任何人都可以获得 Bob 的公钥。为了证明发送者的确是 Alice,她可以使用自己的私钥对信息进行签名。Bob 可以使用 Alice 的公钥对签名进行验证,来确保发送者的确是 Alice。
许多其他包都依赖于 rsa,如 google-auth(第37名),oauthlib(第54名),awscli(第17名)。这个包并不会经常被直接使用,因为有许多更快、更原生的方法。
15、Jmespath
4.73亿次下载
在 Python 中使用 JSON 很容易,因为 JSON 可以完美地映射到 Python 的字典上。我认为这是最好的特性之一。
说实话我从来没听说过 jmepath 这个包,尽管我使用过很多 JSON。我会使用 json.loads() 然后手动从字典中读取数据,或许还得写几个循环。
JMESPath,读作“James path”,能更容易地在 Python 中使用 JSON。你可以用声明的方式定义怎样从 JSON 文档中读取数据。
下面是一些最基本的例子:
import jmespath
# Get a specific element
d = {"foo": {"bar": "baz"}}
print(jmespath.search('foo.bar', d))
# baz
# Using a wildcard to get all names
d = {"foo": {"bar": [{"name": "one"}, {"name": "two"}]}}
print(jmespath.search('foo.bar[*].name', d))
# [“one”, “two”]
这仅仅是它的冰山一角。更多用法参见它的文档和 PyPI 主页。
16、Setuptools
4.01亿次下载
Setuptools 是用来创建 Python 包的工具。
这个项目的文档很糟糕。文档并没有描述它的功能,还包含死链接。真正的好文档在这里:https://packaging.python.org/,以及这篇文章中关于怎样创建 Python 包的教程:https://packaging.python.org/tutorials/packaging-projects/。
17、awscli
第3、7、17和22名互相关联,所以请参见第3名的介绍。
18、pytz
3.94亿次下载
类似于第5名的 dateutils,该库可以帮助你操作日期和时间。处理时区很麻烦。幸运的是,这个包可以让时区处理变得很容易。
关于时间,我的经验是:在内部永远使用UTC,只有在需要产生供人阅读的输出时才转换成本地时间。
下面是 pytz 的例子:
from datetime import datetime
from pytz import timezone
amsterdam = timezone('Europe/Amsterdam')
ams_time = amsterdam.localize(datetime(2002, 10, 27, 6, 0, 0))
print(ams_time)
# 2002-10-27 06:00:00+01:00
# It will also know when it's Summer Time
# in Amsterdam (similar to Daylight Savings Time):
ams_time = amsterdam.localize(datetime(2002, 6, 27, 6, 0, 0))
print(ams_time)
# 2002-06-27 06:00:00+02:00
更多文档和例子可以参见 PyPI 页面。
19、Futures
3.89亿次下载
从 Python 3.2 开始,python 开始提供 concurrent.futures 模块,可以帮你执行异步操作。futures 包是该库的反向移植,所以它是用于 Python 2 的。当前的 Python 3 版本不需要该包,因为 Python 3 本身就提供了该功能。
前面我说过,从2020年1月1日起官方已经停止支持 Python 2。我希望明年再做这个列表的时候,不再看到这个包排进前22名。
下面是 futures 包的基本用法:
from concurrent.futures import ThreadPoolExecutor
from time import sleep
def return_after_5_secs(message):
sleep(5)
return message
pool = ThreadPoolExecutor(3)
future = pool.submit(return_after_5_secs,
("Hello world"))
print(future.done())
# False
sleep(5)
print(future.done())
# True
print(future.result())
# Hello World
可见,我们可以创建一个线程池,然后提交一个函数,让某个线程执行。同时,你的程序会继续在主线程上运行。这是实现并行执行的一种很容易的方式。
20、Colorama
3.70亿次下载
你可以使用 Colorama 在终端上添加颜色:
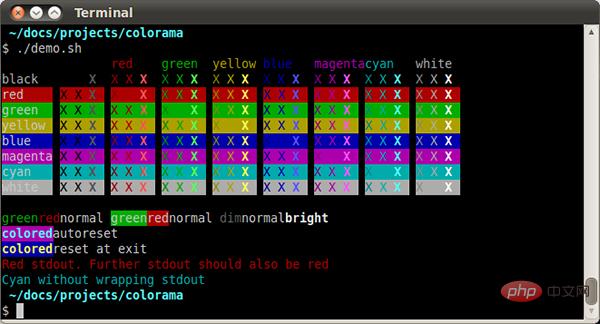
下面的示例演示了实现这个功能有多么容易:
from colorama import Fore, Back, Style
print(Fore.RED + 'some red text')
print(Back.GREEN + 'and with a green background')
print(Style.DIM + 'and in dim text')
print(Style.RESET_ALL)
print('back to normal now')
21、Simplejson
3.41亿次下载
Python 自带的 json 模块有什么问题导致了这个包有如此高的排名?没有任何问题!实际上, Python 的 json 就是 simplejson。但 simplejson 有一些优点:
能在更多 Python 版本上运行
更新频率高于 Python
一部分代码是用C编写的,运行得非常快
有时候你会看到脚本中这样写:
try: import simplejson as json except ImportError: import json
不过,除非确实需要一些标准库中没有的功能,我依然会使用 json。SImplejson 可能比 json快很多,因为它的一部分是用C实现的。但是除非你要处理几千个 JSON 文件,否则这点速度提升并不明显。此外还可以看看 UltraJSON,这是个几乎完全用C编写的包,应该速度更快。
22、boto3
第3、7、17和22名互相关联,所以请参见第3名的介绍。
结束语
只写22个包很难,因为后面的许多包都是终端用户更倾向使用的包。
写这篇文章给了我一些启示:
许多排名靠前的包提供一些核心的功能,如处理时间、配置文件、加密和标准化等。它们通常是其他项目的依赖。
最常见的使用场景就是连接。许多包提供的功能就是连接到服务器,或者支持其他包连接服务器。
其他包是对 Python 的扩展,比如用于创建 Python 包的工具,创建文档的工具,创建版本兼容性的工具,等等。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle est la raison pour laquelle PS continue de montrer le chargement?
Apr 06, 2025 pm 06:39 PM
Quelle est la raison pour laquelle PS continue de montrer le chargement?
Apr 06, 2025 pm 06:39 PM
Les problèmes de «chargement» PS sont causés par des problèmes d'accès aux ressources ou de traitement: la vitesse de lecture du disque dur est lente ou mauvaise: utilisez Crystaldiskinfo pour vérifier la santé du disque dur et remplacer le disque dur problématique. Mémoire insuffisante: améliorez la mémoire pour répondre aux besoins de PS pour les images à haute résolution et le traitement complexe de couche. Les pilotes de la carte graphique sont obsolètes ou corrompues: mettez à jour les pilotes pour optimiser la communication entre le PS et la carte graphique. Les chemins de fichier sont trop longs ou les noms de fichiers ont des caractères spéciaux: utilisez des chemins courts et évitez les caractères spéciaux. Problème du PS: réinstaller ou réparer le programme d'installation PS.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Comment les plumes PS contrôlent-elles la douceur de la transition?
Apr 06, 2025 pm 07:33 PM
Comment les plumes PS contrôlent-elles la douceur de la transition?
Apr 06, 2025 pm 07:33 PM
La clé du contrôle des plumes est de comprendre sa nature progressive. Le PS lui-même ne fournit pas la possibilité de contrôler directement la courbe de gradient, mais vous pouvez ajuster de manière flexible le rayon et la douceur du gradient par plusieurs plumes, des masques correspondants et des sélections fines pour obtenir un effet de transition naturel.
 Comment configurer des plumes de PS?
Apr 06, 2025 pm 07:36 PM
Comment configurer des plumes de PS?
Apr 06, 2025 pm 07:36 PM
La plume PS est un effet flou du bord de l'image, qui est réalisé par la moyenne pondérée des pixels dans la zone de bord. Le réglage du rayon de la plume peut contrôler le degré de flou, et plus la valeur est grande, plus elle est floue. Le réglage flexible du rayon peut optimiser l'effet en fonction des images et des besoins. Par exemple, l'utilisation d'un rayon plus petit pour maintenir les détails lors du traitement des photos des caractères et l'utilisation d'un rayon plus grand pour créer une sensation brumeuse lorsque le traitement de l'art fonctionne. Cependant, il convient de noter que trop grand, le rayon peut facilement perdre des détails de bord, et trop petit, l'effet ne sera pas évident. L'effet de plumes est affecté par la résolution de l'image et doit être ajusté en fonction de la compréhension de l'image et de la saisie de l'effet.
 Que dois-je faire si la carte PS est dans l'interface de chargement?
Apr 06, 2025 pm 06:54 PM
Que dois-je faire si la carte PS est dans l'interface de chargement?
Apr 06, 2025 pm 06:54 PM
L'interface de chargement de la carte PS peut être causée par le logiciel lui-même (corruption de fichiers ou conflit de plug-in), l'environnement système (corruption du pilote ou des fichiers système en raison), ou matériel (corruption du disque dur ou défaillance du bâton de mémoire). Vérifiez d'abord si les ressources informatiques sont suffisantes, fermez le programme d'arrière-plan et publiez la mémoire et les ressources CPU. Correction de l'installation de PS ou vérifiez les problèmes de compatibilité pour les plug-ins. Mettre à jour ou tomber la version PS. Vérifiez le pilote de la carte graphique et mettez-le à jour et exécutez la vérification du fichier système. Si vous résumez les problèmes ci-dessus, vous pouvez essayer la détection du disque dur et les tests de mémoire.
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Quel impact la plume de PS a-t-elle sur la qualité de l'image?
Apr 06, 2025 pm 07:21 PM
Quel impact la plume de PS a-t-elle sur la qualité de l'image?
Apr 06, 2025 pm 07:21 PM
Les plumes de PS peuvent entraîner une perte de détails d'image, une saturation des couleurs réduite et une augmentation du bruit. Pour réduire l'impact, il est recommandé d'utiliser un rayon de plumes plus petit, de copier la couche puis de plume, et de comparer soigneusement la qualité d'image avant et après les plumes. De plus, les plumes ne conviennent pas à tous les cas, et parfois les outils tels que les masques conviennent plus à la gestion des bords de l'image.
