


Bonjour à tous.
Il s'agit d'un cas de prévision du prix de l'immobilier, qui provient du site Web Kaggle. C'est la première question de concurrence pour de nombreux débutants en algorithmes.
Ce cas dispose d'un processus complet pour résoudre les problèmes d'apprentissage automatique, y compris l'EDA, l'ingénierie des fonctionnalités, la formation de modèles, la fusion de modèles, etc.
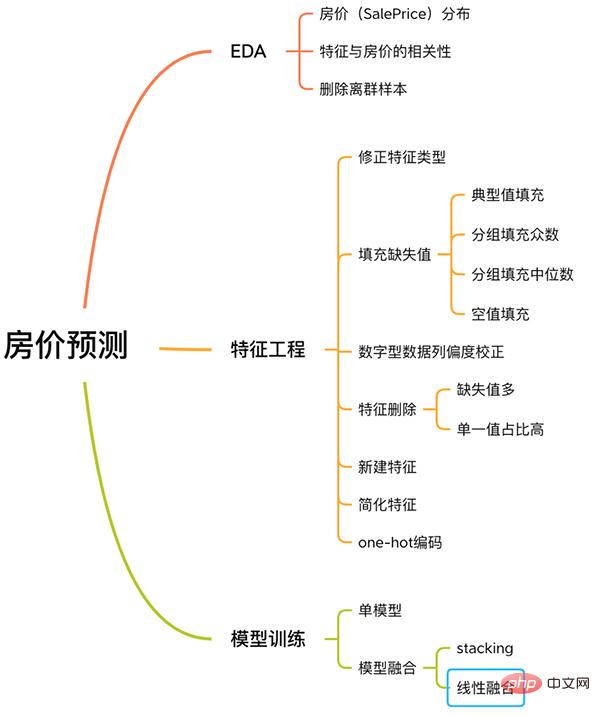
Processus de prévision du prix de l'immobilier
Suivez-moi ci-dessous pour en savoir plus sur cette affaire.
Pas de longs mots, pas de code redondant, juste des explications simples.
Le but de l'analyse exploratoire des données (EDA) est de nous donner une compréhension complète de l'ensemble de données. À cette étape, le contenu que nous explorons est le suivant :

Contenu EDA
train = pd.read_csv('./data/train.csv')
test = pd.read_csv('./data/test.csv')

Échantillons d'entraînement
train et test sont respectivement l'ensemble d'entraînement et l'ensemble de test, avec 1460 échantillons. respectivement 80 fonctionnalités.
La colonne SalePrice représente le prix du logement que nous voulons prédire.
Étant donné que notre tâche est de prédire les prix de l'immobilier, l'élément principal sur lequel se concentrer dans l'ensemble de données est la distribution de la valeur de la colonne du prix de l'immobilier (SalePrice).
sns.distplot(train['SalePrice']);
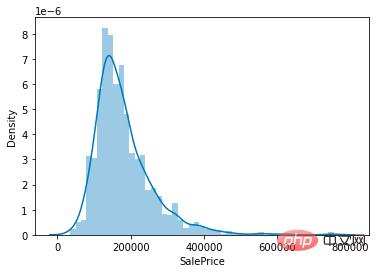
Distribution de la valeur du prix de l'immobilier
Comme le montre la figure, la valeur maximale de la colonne SalePrice est relativement raide et la valeur maximale est asymétrique vers la gauche.
Vous pouvez également appeler directement les fonctions skew() et kurt() pour calculer les valeurs d'asymétrie et d'aplatissement spécifiques de SalePrice.
Pour les situations où l'asymétrie et l'aplatissement sont relativement importants, il est recommandé d'utiliser log() pour lisser la colonne SalePrice.
Après avoir compris la distribution de SalePrice, nous pouvons calculer la corrélation entre 80 caractéristiques et SalePrice.
Concentrez-vous sur les 10 fonctionnalités ayant la plus forte corrélation avec SalePrice.
# 计算列之间相关性
corrmat = train.corr()
# 取 top10
k = 10
cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index
# 绘图
cm = np.corrcoef(train[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()
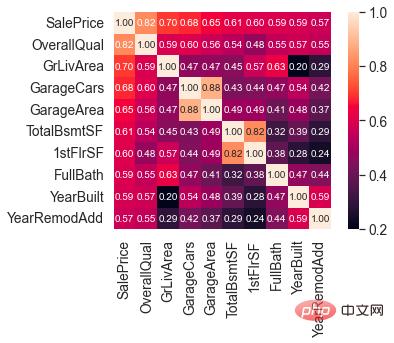
Caractéristiques fortement corrélées avec SalePrice
OverallQual (matériaux et finitions de la maison), GrLivArea (surface habitable hors sol), GarageCars (capacité du garage) et TotalBsmtSF (surface du sous-sol) sont fortement corrélées avec SalePrice.
Ces fonctionnalités seront également ciblées lors de l'ingénierie des fonctionnalités ultérieurement.
Étant donné que la taille de l'échantillon de l'ensemble de données est très petite, les valeurs aberrantes ne sont pas propices à notre entraînement ultérieur du modèle.
Il est donc nécessaire de calculer les valeurs aberrantes de chaque caractéristique numérique et d'éliminer les échantillons présentant le plus de valeurs aberrantes.
# 获取数值型特征 numeric_features = train.dtypes[train.dtypes != 'object'].index # 计算每个特征的离群样本 for feature in numeric_features: outs = detect_outliers(train[feature], train['SalePrice'],top=5, plot=False) all_outliers.extend(outs) # 输出离群次数最多的样本 print(Counter(all_outliers).most_common()) # 剔除离群样本 train = train.drop(train.index[outliers])
detect_outliers() est une fonction personnalisée qui utilise l'algorithme LocalOutlierFactor de la bibliothèque sklearn pour calculer les valeurs aberrantes.
À ce stade, l'EDA est terminée. Enfin, l'ensemble de formation et l'ensemble de test sont fusionnés pour effectuer l'ingénierie des fonctionnalités suivante.
y = train.SalePrice.reset_index(drop=True) train_features = train.drop(['SalePrice'], axis=1) test_features = test features = pd.concat([train_features, test_features]).reset_index(drop=True)
features combine les fonctionnalités de l'ensemble d'entraînement et de l'ensemble de test, et ce sont les données que nous traiterons ci-dessous.
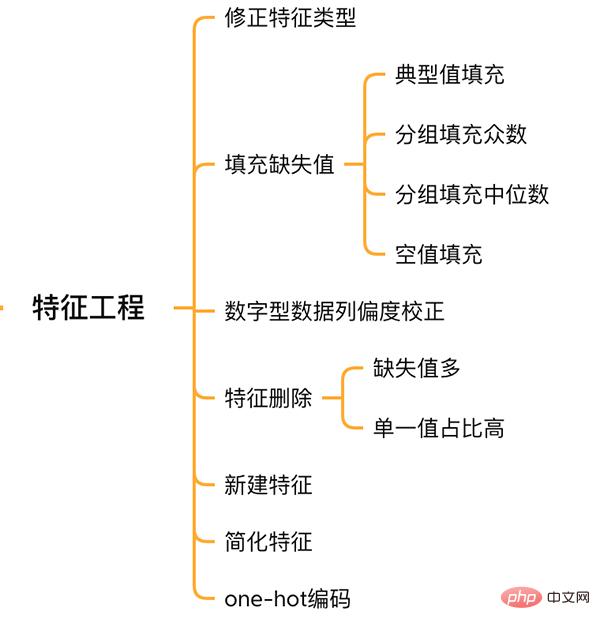
Feature Engineering
MSSubClass (type de maison), YrSold (année de vente) et MoSold (mois de vente) sont des fonctionnalités catégorielles, mais elles sont représentées par des chiffres. doivent être convertis en fonctionnalités de texte.
features['MSSubClass'] = features['MSSubClass'].apply(str) features['YrSold'] = features['YrSold'].astype(str) features['MoSold'] = features['MoSold'].astype(str)
Il n'existe pas de norme unifiée pour remplir les valeurs manquantes. Il faut décider en fonction des différentes fonctionnalités de la manière de les remplir.
# Functional:文档提供了典型值 Typ
features['Functional'] = features['Functional'].fillna('Typ') #Typ 是典型值
# 分组填充需要按照相似的特征分组,取众数或中位数
# MSZoning(房屋区域)按照 MSSubClass(房屋)类型分组填充众数
features['MSZoning'] = features.groupby('MSSubClass')['MSZoning'].transform(lambda x: x.fillna(x.mode()[0]))
#LotFrontage(到接到举例)按Neighborhood分组填充中位数
features['LotFrontage'] = features.groupby('Neighborhood')['LotFrontage'].transform(lambda x: x.fillna(x.median()))
# 车库相关的数值型特征,空代表无,使用0填充空值。
for col in ('GarageYrBlt', 'GarageArea', 'GarageCars'):
features[col] = features[col].fillna(0)
est similaire à l'exploration de la colonne SalePrice, lissant les fonctionnalités avec une asymétrie élevée.
# skew()方法,计算特征的偏度(skewness)。 skew_features = features[numeric_features].apply(lambda x: skew(x)).sort_values(ascending=False) # 取偏度大于 0.15 的特征 high_skew = skew_features[skew_features > 0.15] skew_index = high_skew.index # 处理高偏度特征,将其转化为正态分布,也可以使用简单的log变换 for i in skew_index: features[i] = boxcox1p(features[i], boxcox_normmax(features[i] + 1))
Les fonctionnalités qui sont presque toutes des valeurs manquantes ou qui ont une forte proportion de valeurs uniques (99,94%) peuvent être supprimées directement.
features = features.drop(['Utilities', 'Street', 'PoolQC',], axis=1)
En même temps, plusieurs fonctionnalités peuvent être fusionnées pour générer de nouvelles fonctionnalités.
Parfois, il est difficile pour le modèle d'apprendre la relation entre les fonctionnalités. La fusion manuelle des fonctionnalités peut réduire la difficulté d'apprentissage du modèle et améliorer l'effet.
# 将原施工日期和改造日期融合 features['YrBltAndRemod']=features['YearBuilt']+features['YearRemodAdd'] # 将地下室面积、1楼、2楼面积融合 features['TotalSF']=features['TotalBsmtSF'] + features['1stFlrSF'] + features['2ndFlrSF']
On peut constater que les fonctionnalités que nous fusionnons sont toutes des fonctionnalités fortement liées à SalePrice.
Enfin, simplifiez les fonctionnalités et effectuez le traitement 01 sur les fonctionnalités à distribution monotone (par exemple : 99 données sur 100 ont une valeur de 0,9, et l'autre a une valeur de 0,1).
features['haspool'] = features['PoolArea'].apply(lambda x: 1 if x > 0 else 0) features['has2ndfloor'] = features['2ndFlrSF'].apply(lambda x: 1 if x > 0 else 0)
到这里特征工程就做完了, 我们需要从features中将训练集和测试集重新分离出来,构造最终的训练数据。
X = features.iloc[:len(y), :] X_sub = features.iloc[len(y):, :] X = np.array(X.copy()) y = np.array(y) X_sub = np.array(X_sub.copy())
因为SalePrice是数值型且是连续的,所以需要训练一个回归模型。
首先以岭回归(Ridge) 为例,构造一个k折交叉验证模型。
from sklearn.linear_model import RidgeCV from sklearn.pipeline import make_pipeline from sklearn.model_selection import KFold kfolds = KFold(n_splits=10, shuffle=True, random_state=42) alphas_alt = [14.5, 14.6, 14.7, 14.8, 14.9, 15, 15.1, 15.2, 15.3, 15.4, 15.5] ridge = make_pipeline(RobustScaler(), RidgeCV(alphas=alphas_alt, cv=kfolds))
岭回归模型有一个超参数alpha,而RidgeCV的参数名是alphas,代表输入一个超参数alpha数组。在拟合模型时,会从alpha数组中选择表现较好某个取值。
由于现在只有一个模型,无法确定岭回归是不是最佳模型。所以我们可以找一些出场率高的模型多试试。
# lasso lasso = make_pipeline( RobustScaler(), LassoCV(max_iter=1e7, alphas=alphas2, random_state=42, cv=kfolds)) #elastic net elasticnet = make_pipeline( RobustScaler(), ElasticNetCV(max_iter=1e7, alphas=e_alphas, cv=kfolds, l1_ratio=e_l1ratio)) #svm svr = make_pipeline(RobustScaler(), SVR( C=20, epsilon=0.008, gamma=0.0003, )) #GradientBoosting(展开到一阶导数) gbr = GradientBoostingRegressor(...) #lightgbm lightgbm = LGBMRegressor(...) #xgboost(展开到二阶导数) xgboost = XGBRegressor(...)
有了多个模型,我们可以再定义一个得分函数,对模型评分。
#模型评分函数 def cv_rmse(model, X=X): rmse = np.sqrt(-cross_val_score(model, X, y, scoring="neg_mean_squared_error", cv=kfolds)) return (rmse)
以岭回归为例,计算模型得分。
score = cv_rmse(ridge)
print("Ridge score: {:.4f} ({:.4f})n".format(score.mean(), score.std()), datetime.now(), ) #0.1024
运行其他模型发现得分都差不多。
这时候我们可以任选一个模型,拟合,预测,提交训练结果。还是以岭回归为例
# 训练模型
ridge.fit(X, y)
# 模型预测
submission.iloc[:,1] = np.floor(np.expm1(ridge.predict(X_sub)))
# 输出测试结果
submission = pd.read_csv("./data/sample_submission.csv")
submission.to_csv("submission_single.csv", index=False)
submission_single.csv是岭回归预测的房价,我们可以把这个结果上传到 Kaggle 网站查看结果的得分和排名。
有时候为了发挥多个模型的作用,我们会将多个模型融合,这种方式又被称为集成学习。
stacking 是一种常见的集成学习方法。简单来说,它会定义个元模型,其他模型的输出作为元模型的输入特征,元模型的输出将作为最终的预测结果。
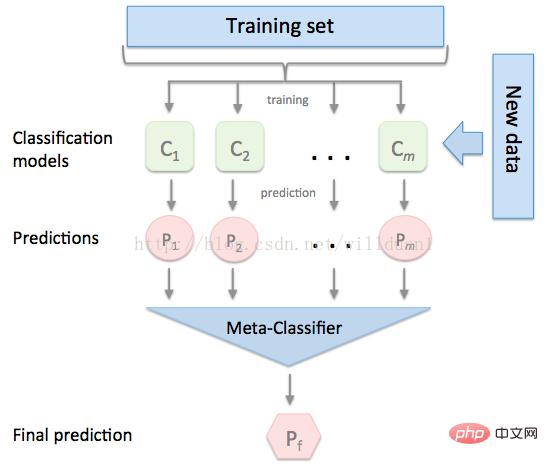
stacking
这里,我们用mlextend库中的StackingCVRegressor模块,对模型做stacking。
stack_gen = StackingCVRegressor( regressors=(ridge, lasso, elasticnet, gbr, xgboost, lightgbm), meta_regressor=xgboost, use_features_in_secondary=True)
训练、预测的过程与上面一样,这里不再赘述。
多模型线性融合的思想很简单,给每个模型分配一个权重(权重加和=1),最终的预测结果取各模型的加权平均值。
# 训练单个模型 ridge_model_full_data = ridge.fit(X, y) lasso_model_full_data = lasso.fit(X, y) elastic_model_full_data = elasticnet.fit(X, y) gbr_model_full_data = gbr.fit(X, y) xgb_model_full_data = xgboost.fit(X, y) lgb_model_full_data = lightgbm.fit(X, y) svr_model_full_data = svr.fit(X, y) models = [ ridge_model_full_data, lasso_model_full_data, elastic_model_full_data, gbr_model_full_data, xgb_model_full_data, lgb_model_full_data, svr_model_full_data, stack_gen_model ] # 分配模型权重 public_coefs = [0.1, 0.1, 0.1, 0.1, 0.15, 0.1, 0.1, 0.25] # 线性融合,取加权平均 def linear_blend_models_predict(data_x,models,coefs, bias): tmp=[model.predict(data_x) for model in models] tmp = [c*d for c,d in zip(coefs,tmp)] pres=np.array(tmp).swapaxes(0,1) pres=np.sum(pres,axis=1) return pres
到这里,房价预测的案例我们就讲解完了,大家可以自己运行一下,看看不同方式训练出来的模型效果。
回顾整个案例会发现,我们在数据预处理和特征工程上花费了很大心思,虽然机器学习问题模型原理比较难学,但实际过程中往往特征工程花费的心思最多。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



