
 Périphériques technologiques
IA
Algorithme d'apprentissage d'ensemble profond pour la classification des images rétiniennes
Périphériques technologiques
IA
Algorithme d'apprentissage d'ensemble profond pour la classification des images rétiniennes
Algorithme d'apprentissage d'ensemble profond pour la classification des images rétiniennes

Traducteur | Zhu Xianzhong
Critique | Sun Shujuan

Figure 1 : La couverture du projet Iluminado conçue par l'auteur original lui-même
En 2019, l'Organisation mondiale de la santé a estimé qu'il Il y a environ 2,2 milliards de personnes dans le monde ayant une déficience visuelle, dont au moins 1 milliard auraient pu être évitées ou sont encore traitées. En matière de soins oculaires, le monde est confronté à de nombreux défis, notamment les inégalités dans la couverture et la qualité des services préventifs, thérapeutiques et de réadaptation. Il y a un manque de personnel qualifié en matière de soins oculaires et les services de soins oculaires sont mal intégrés dans le système de santé principal. Mon objectif est d’inspirer des actions pour relever ensemble ces défis. Le projet présenté dans cet article fait partie d'Iluminado, un projet de synthèse de science des données sur lequel je travaille actuellement.
Objectifs de conception du projet Capstone
Le but de la création de ce projet d'article est de former un modèle d'ensemble d'apprentissage en profondeur qui est finalement très accessible aux familles à faible revenu et peut effectuer un diagnostic initial du risque de maladie à faible coût. En utilisant ma procédure modèle, les ophtalmologistes peuvent déterminer si une intervention immédiate est nécessaire sur la base de la photographie du fond d'œil rétinien.
Source de l'ensemble de données du projet
OphthAI fournit un ensemble de données d'images accessible au public appelé Retinal Fundus Multi-Disease Image Dataset (« RFMiD »), qui contient 3 200 images. Les images du fond d'œil, qui ont été capturées par trois caméras de fond d'œil différentes, ont été annotées. par deux experts chevronnés en rétine, sur la base d'un consensus.
Ces images ont été extraites de milliers d'inspections menées en 2009-2010, sélectionnant à la fois des images de haute qualité et un certain nombre d'images de mauvaise qualité, ce qui rend l'ensemble de données plus difficile.
L'ensemble de données est divisé en trois parties, dont l'ensemble d'entraînement (60 % ou 1920 images), l'ensemble d'évaluation (20 % ou 640 images) et l'ensemble de test (20 % et 640 images). En moyenne, les proportions de personnes atteintes de maladies dans l'ensemble de formation, l'ensemble d'évaluation et l'ensemble de tests étaient respectivement de 60 ± 7 %, 20 ± 7 % et 20 ± 5 %. L'objectif fondamental de cet ensemble de données est d'aborder diverses maladies oculaires qui surviennent dans la pratique clinique quotidienne, avec un total de 45 catégories de maladies/pathologies identifiées. Ces étiquettes se trouvent dans trois fichiers CSV, à savoir RFMiD_Training_Labels.CSV, RFMiD_Validation_Labels.SSV et RFMiD_Testing_Labels.CSV.
Source de l'image
L'image ci-dessous a été prise à l'aide d'un outil appelé caméra de fond. Une caméra de fond d'œil est un microscope spécialisé de faible puissance attaché à un appareil photo flash utilisé pour photographier le fond d'œil, la couche rétinienne située à l'arrière de l'œil.
De nos jours, la plupart des caméras de fond d'œil sont portables, le patient n'a donc qu'à regarder directement dans l'objectif. Parmi eux, la partie clignotante indique que l'image du fond d'œil a été prise.
Les caméras portables ont leurs avantages car elles peuvent être transportées à différents endroits et peuvent accueillir des patients ayant des besoins particuliers, tels que les utilisateurs de fauteuils roulants. De plus, tout employé possédant la formation requise peut faire fonctionner les caméras, permettant ainsi aux patients diabétiques mal desservis de subir leurs examens annuels rapidement, en toute sécurité et efficacement.
Situation photographique du système d'imagerie du fond d'œil rétinien :
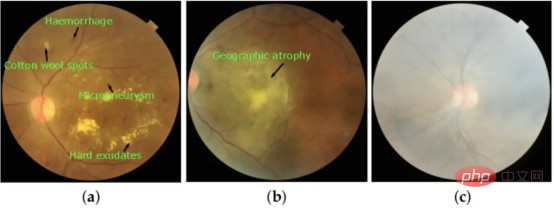
Figure 2 : Images prises en fonction des caractéristiques visuelles respectives : (a) rétinopathie diabétique (RD), (b) dégénérescence maculaire liée à l'âge (DMLA) et (c) brume modérée (MH).
Où est effectué le diagnostic final ?
Le processus de dépistage initial peut être assisté par l'apprentissage profond, mais le diagnostic final est posé par un ophtalmologiste à l'aide d'un examen à la lampe à fente.
Ce processus est également appelé diagnostic biomicroscopique et implique l'examen de cellules vivantes. Le médecin peut procéder à un examen microscopique pour déterminer s'il existe des anomalies dans les yeux du patient.
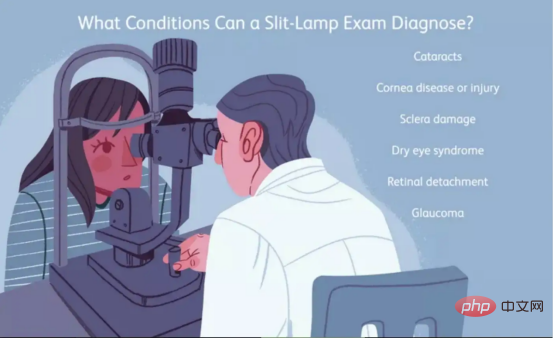
Figure 3 : Illustration de l'examen par lampe à fente
Application de l'apprentissage profond dans la classification des images rétiniennes
Différent des algorithmes d'apprentissage automatique traditionnels, les réseaux neuronaux convolutifs profonds (CNN) peuvent utiliser des modèles multicouches pour réaliser une extraction et une classification automatiques caractéristiques à partir de données brutes.
Récemment, la communauté universitaire a publié un grand nombre d'articles sur l'utilisation des réseaux de neurones convolutifs (CNN) pour identifier diverses maladies oculaires, telles que la rétinopathie diabétique et le glaucome avec des résultats anormaux (AUROC>0,9).
Data Metrics
Le score AUROC résume la courbe ROC en un nombre qui décrit les performances du modèle lors de la gestion simultanée de plusieurs seuils. Il convient de noter qu’un score AUROC de 1 représente un score parfait, tandis qu’un score AUROC de 0,5 correspond à une supposition aléatoire.
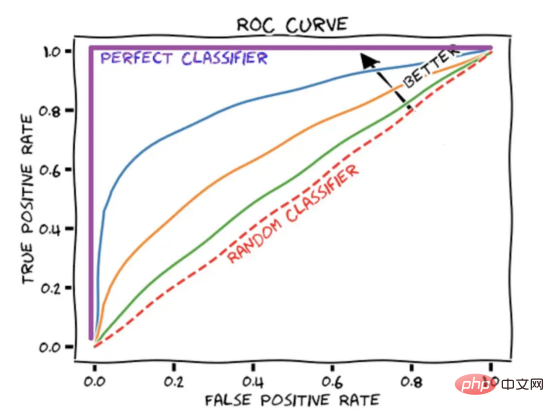
Figure 4 : Diagramme schématique de la courbe ROC montrant
Méthode utilisée - Fonction de perte d'entropie croisée
L'entropie croisée est généralement utilisée comme fonction de perte dans l'apprentissage automatique. L'entropie croisée est une métrique dans le domaine de la théorie de l'information qui s'appuie sur la définition de l'entropie et est généralement utilisée pour calculer la différence entre deux distributions de probabilité, tandis que l'entropie croisée peut être considérée comme le calcul de l'entropie totale entre deux distributions.
L'entropie croisée est également liée à la perte logistique, appelée perte logarithmique. Bien que ces deux mesures proviennent de sources différentes, lorsqu’elles sont utilisées comme fonction de perte pour un modèle de classification, les deux méthodes calculent la même quantité et peuvent être utilisées de manière interchangeable.
(Pour plus de détails, veuillez vous référer à : https://machinelearningmastery.com/logistic-regression-with-maximum-likelihood-estimation/)
Qu'est-ce que l'entropie croisée ?
L'entropie croisée est une mesure de la différence entre deux distributions de probabilité pour une variable aléatoire ou un ensemble d'événements donné. Vous vous souviendrez peut-être que les informations quantifient le nombre de bits requis pour coder et transmettre un événement. Les événements à faible probabilité ont tendance à contenir plus d’informations, tandis que les événements à forte probabilité contiennent moins d’informations.
En théorie de l'information, on aime décrire la « surprise » des événements. Moins un événement est susceptible de se produire, plus il est surprenant, c’est-à-dire qu’il contient plus d’informations.
- Événement à faible probabilité (surprenant) : Plus d'informations.
- Événement à forte probabilité (pas de surprise) : moins d'informations.
Étant donné la probabilité de l'événement P(x), l'information h(x) peut être calculée pour l'événement x comme suit :
h(x) = -log(P(x))
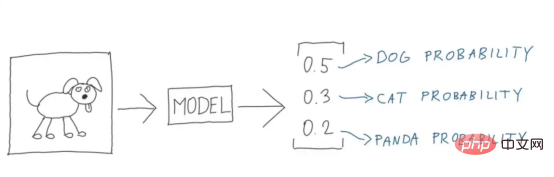
Figure 4 : Illustration parfaite (Crédit image : Vlastimil Martinek)
L'entropie est le nombre de bits requis pour transmettre un événement sélectionné au hasard à partir d'une distribution de probabilité. Les distributions asymétriques ont une entropie plus faible, tandis que les distributions avec des probabilités d'événements égales ont généralement une entropie plus élevée.
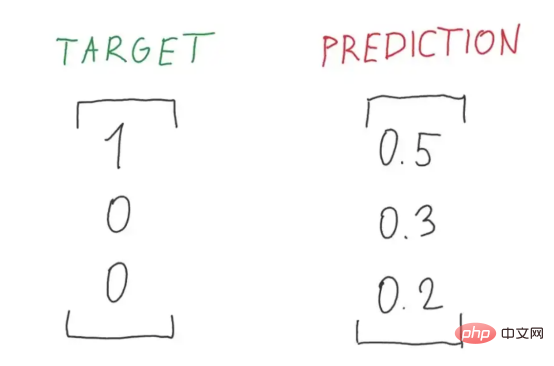
Figure 5 : Une illustration parfaite du rapport entre les probabilités cibles et les probabilités prédites (Source de l'image : Vlastimil Martinek)
Une distribution de probabilité asymétrique a moins de « surprises » et, à son tour, une entropie plus faible, autant que possible les événements dominent. Relativement parlant, la distribution à l’équilibre est plus surprenante et présente une entropie plus élevée car les événements ont la même probabilité de se produire.
- Distribution de probabilité asymétrique (pas de surprise) : faible entropie.
- Distribution de probabilité équilibrée (étonnamment) : entropie élevée.
L'entropie H(x) peut être calculée pour une variable aléatoire avec un ensemble de x dans x états discrets et sa probabilité P(x) comme le montre la figure ci-dessous :
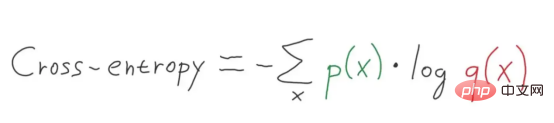
Figure 6 : Formule d'entropie croisée multi-niveaux (Source de l'image : Vlastimil Martinek)
Classification multi-catégories - nous utilisons l'entropie croisée multi-catégories - un cas d'application spécifique de l'entropie croisée, dans lequel l'objectif Un schéma vectoriel de codage à chaud est utilisé. (Les lecteurs intéressés peuvent se référer à l'article de Vlastimil Martinek)

Figure 7 : Diagramme de décomposition parfait du calcul des pertes de pandas et de chats (Source photo : Vlastimil Martinek)
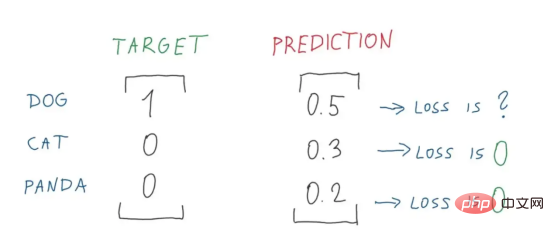
Figure 8 : Valeur de perte Figure 9 : Décomposition parfaite de la valeur de perte Figure 2 (Source de l'image : Vlastimil Martinek) Figure 9 : À propos de la probabilité et de la perte Représentation visuelle de (Crédit image : Vlastimil Martinek)
Que diriez-vous de l'entropie croisée binaire ? 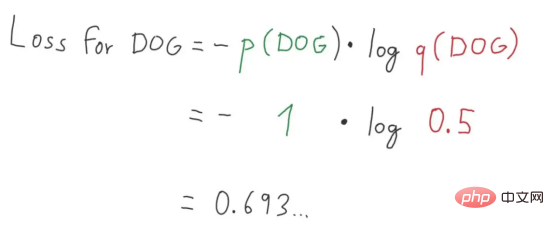
Figure 10 : Illustration de la formule d'entropie croisée de classification (Source de l'image : Vlastimil Martinek)
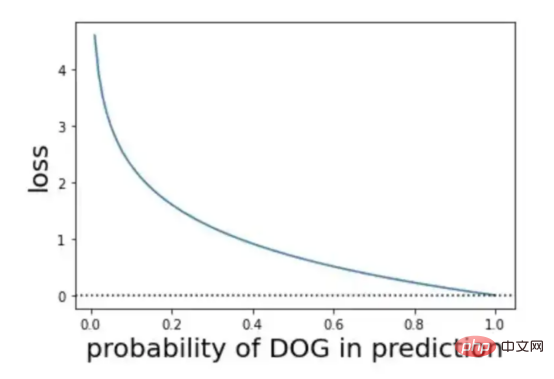
Dans notre projet, nous avons choisi d'utiliser la classification binaire - schéma d'entropie croisée binaire, c'est-à-dire que la cible est 0 ou 1 schéma d'entropie croisée. Si nous convertissons les cibles en vecteurs de codage à chaud de [0,1] ou [1,0] respectivement et prédisons, nous pouvons alors utiliser la formule d'entropie croisée pour calculer.
 Figure 11 : Illustration de la formule de calcul d'entropie croisée binaire (Source de l'image : Vlastimil Martinek)
Figure 11 : Illustration de la formule de calcul d'entropie croisée binaire (Source de l'image : Vlastimil Martinek)
Utilisation d'un algorithme de perte asymétrique pour traiter des données déséquilibrées
Dans un environnement de modèle multi-étiquette typique, le Les caractéristiques des données d'un ensemble peuvent avoir un nombre disproportionné d'étiquettes positives et négatives. À ce stade, la tendance de l’ensemble de données à favoriser les étiquettes négatives a une influence dominante sur le processus d’optimisation et conduit finalement à une sous-accentuation du gradient d’étiquettes positives, réduisant ainsi la précision des résultats de prédiction.
C'est exactement la situation à laquelle est confronté l'ensemble de données que je choisis actuellement. 
Ce projet utilise l'algorithme de perte asymétrique développé par BenBaruch et al. (voir Figure 12). Il s'agit d'une méthode pour résoudre la classification multi-étiquettes, mais les catégories présentent également de graves situations de distribution déséquilibrée.
La façon dont j'ai trouvé est de réduire le poids de la partie étiquette négative en modifiant asymétriquement les composantes positives et négatives de l'entropie croisée, et enfin de mettre en évidence le poids de la partie étiquette positive qui est plus difficile à traiter .
Figure 12 : Algorithme de classification asymétrique multi-label (2020, auteur : Ben-Baruch et al.)
Architecture système à tester
Pour résumer, ce projet utilise celui présenté dans le figure Architecture :
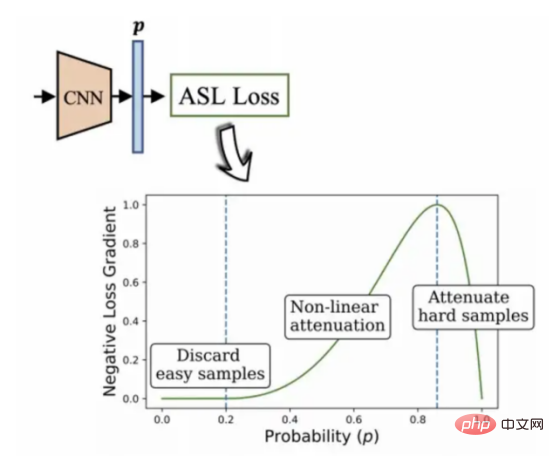
Figure 13 (Source de l'image : Sixu)
Les algorithmes clés utilisés dans l'architecture ci-dessus incluent principalement : VGG16
- De plus, le algorithmes associés ci-dessus Le contenu sera mis à jour une fois que j'aurai terminé le projet Capstone pour cet article ! Lecteurs intéressés, restez à l’écoute !
- Présentation du traducteur Zhu Xianzhong, rédacteur en chef de la communauté 51CTO, blogueur expert 51CTO, conférencier, professeur d'informatique dans une université de Weifang et vétéran de l'industrie de la programmation indépendante.
- Titre original :
- Deep Ensemble Learning for Retinal Image Classification (CNN)
, auteur : Cathy Kam
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Méthodes et étapes d'utilisation de BERT pour l'analyse des sentiments en Python
Jan 22, 2024 pm 04:24 PM
Méthodes et étapes d'utilisation de BERT pour l'analyse des sentiments en Python
Jan 22, 2024 pm 04:24 PM
BERT est un modèle de langage d'apprentissage profond pré-entraîné proposé par Google en 2018. Le nom complet est BidirectionnelEncoderRepresentationsfromTransformers, qui est basé sur l'architecture Transformer et présente les caractéristiques d'un codage bidirectionnel. Par rapport aux modèles de codage unidirectionnels traditionnels, BERT peut prendre en compte les informations contextuelles en même temps lors du traitement du texte, de sorte qu'il fonctionne bien dans les tâches de traitement du langage naturel. Sa bidirectionnalité permet à BERT de mieux comprendre les relations sémantiques dans les phrases, améliorant ainsi la capacité expressive du modèle. Grâce à des méthodes de pré-formation et de réglage fin, BERT peut être utilisé pour diverses tâches de traitement du langage naturel, telles que l'analyse des sentiments, la dénomination
 Analyse des fonctions d'activation de l'IA couramment utilisées : pratique d'apprentissage en profondeur de Sigmoid, Tanh, ReLU et Softmax
Dec 28, 2023 pm 11:35 PM
Analyse des fonctions d'activation de l'IA couramment utilisées : pratique d'apprentissage en profondeur de Sigmoid, Tanh, ReLU et Softmax
Dec 28, 2023 pm 11:35 PM
Les fonctions d'activation jouent un rôle crucial dans l'apprentissage profond. Elles peuvent introduire des caractéristiques non linéaires dans les réseaux neuronaux, permettant ainsi au réseau de mieux apprendre et simuler des relations entrées-sorties complexes. La sélection et l'utilisation correctes des fonctions d'activation ont un impact important sur les performances et les résultats de formation des réseaux de neurones. Cet article présentera quatre fonctions d'activation couramment utilisées : Sigmoid, Tanh, ReLU et Softmax, à partir de l'introduction, des scénarios d'utilisation, des avantages, Les inconvénients et les solutions d'optimisation sont abordés pour vous fournir une compréhension complète des fonctions d'activation. 1. Fonction sigmoïde Introduction à la formule de la fonction SIgmoïde : La fonction sigmoïde est une fonction non linéaire couramment utilisée qui peut mapper n'importe quel nombre réel entre 0 et 1. Il est généralement utilisé pour unifier le
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Intégration d'espace latent : explication et démonstration
Jan 22, 2024 pm 05:30 PM
Intégration d'espace latent : explication et démonstration
Jan 22, 2024 pm 05:30 PM
L'intégration d'espace latent (LatentSpaceEmbedding) est le processus de mappage de données de grande dimension vers un espace de faible dimension. Dans le domaine de l'apprentissage automatique et de l'apprentissage profond, l'intégration d'espace latent est généralement un modèle de réseau neuronal qui mappe les données d'entrée de grande dimension dans un ensemble de représentations vectorielles de basse dimension. Cet ensemble de vecteurs est souvent appelé « vecteurs latents » ou « latents ». encodages". Le but de l’intégration de l’espace latent est de capturer les caractéristiques importantes des données et de les représenter sous une forme plus concise et compréhensible. Grâce à l'intégration de l'espace latent, nous pouvons effectuer des opérations telles que la visualisation, la classification et le regroupement de données dans un espace de faible dimension pour mieux comprendre et utiliser les données. L'intégration d'espace latent a de nombreuses applications dans de nombreux domaines, tels que la génération d'images, l'extraction de caractéristiques, la réduction de dimensionnalité, etc. L'intégration de l'espace latent est le principal
 Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Dans la vague actuelle de changements technologiques rapides, l'intelligence artificielle (IA), l'apprentissage automatique (ML) et l'apprentissage profond (DL) sont comme des étoiles brillantes, à la tête de la nouvelle vague des technologies de l'information. Ces trois mots apparaissent fréquemment dans diverses discussions de pointe et applications pratiques, mais pour de nombreux explorateurs novices dans ce domaine, leurs significations spécifiques et leurs connexions internes peuvent encore être entourées de mystère. Alors regardons d'abord cette photo. On constate qu’il existe une corrélation étroite et une relation progressive entre l’apprentissage profond, l’apprentissage automatique et l’intelligence artificielle. Le deep learning est un domaine spécifique du machine learning, et le machine learning
 Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Près de 20 ans se sont écoulés depuis que le concept d'apprentissage profond a été proposé en 2006. L'apprentissage profond, en tant que révolution dans le domaine de l'intelligence artificielle, a donné naissance à de nombreux algorithmes influents. Alors, selon vous, quels sont les 10 meilleurs algorithmes pour l’apprentissage profond ? Voici les meilleurs algorithmes d’apprentissage profond, à mon avis. Ils occupent tous une position importante en termes d’innovation, de valeur d’application et d’influence. 1. Contexte du réseau neuronal profond (DNN) : Le réseau neuronal profond (DNN), également appelé perceptron multicouche, est l'algorithme d'apprentissage profond le plus courant lorsqu'il a été inventé pour la première fois, jusqu'à récemment en raison du goulot d'étranglement de la puissance de calcul. années, puissance de calcul, La percée est venue avec l'explosion des données. DNN est un modèle de réseau neuronal qui contient plusieurs couches cachées. Dans ce modèle, chaque couche transmet l'entrée à la couche suivante et
 Des bases à la pratique, passez en revue l'historique du développement de la récupération de vecteurs Elasticsearch.
Oct 23, 2023 pm 05:17 PM
Des bases à la pratique, passez en revue l'historique du développement de la récupération de vecteurs Elasticsearch.
Oct 23, 2023 pm 05:17 PM
1. Introduction La récupération de vecteurs est devenue un élément essentiel des systèmes modernes de recherche et de recommandation. Il permet une correspondance de requêtes et des recommandations efficaces en convertissant des objets complexes (tels que du texte, des images ou des sons) en vecteurs numériques et en effectuant des recherches de similarité dans des espaces multidimensionnels. Des bases à la pratique, passez en revue l'historique du développement d'Elasticsearch. vector retrieval_elasticsearch En tant que moteur de recherche open source populaire, le développement d'Elasticsearch en matière de récupération de vecteurs a toujours attiré beaucoup d'attention. Cet article passera en revue l'historique du développement de la récupération de vecteurs Elasticsearch, en se concentrant sur les caractéristiques et la progression de chaque étape. En prenant l'historique comme guide, il est pratique pour chacun d'établir une gamme complète de récupération de vecteurs Elasticsearch.
 AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
Editeur | Radis Skin Depuis la sortie du puissant AlphaFold2 en 2021, les scientifiques utilisent des modèles de prédiction de la structure des protéines pour cartographier diverses structures protéiques dans les cellules, découvrir des médicaments et dresser une « carte cosmique » de chaque interaction protéique connue. Tout à l'heure, Google DeepMind a publié le modèle AlphaFold3, capable d'effectuer des prédictions de structure conjointe pour des complexes comprenant des protéines, des acides nucléiques, de petites molécules, des ions et des résidus modifiés. La précision d’AlphaFold3 a été considérablement améliorée par rapport à de nombreux outils dédiés dans le passé (interaction protéine-ligand, interaction protéine-acide nucléique, prédiction anticorps-antigène). Cela montre qu’au sein d’un cadre unique et unifié d’apprentissage profond, il est possible de réaliser
