

En ce qui concerne le machine learning, l'audio en lui-même est un domaine complet avec un large éventail d'applications, notamment la reconnaissance vocale, la classification musicale, la détection d'événements sonores, etc. La classification audio utilise traditionnellement des méthodes telles que l'analyse par spectrogramme et les modèles de Markov cachés, qui se sont révélées efficaces mais ont également leurs limites. Récemment, VIT est apparu comme une alternative prometteuse pour les tâches audio, Whisper d’OpenAI en étant un bon exemple.

L'ensemble de données GTZAN est l'ensemble de données public le plus couramment utilisé dans la recherche sur la reconnaissance des genres musicaux (MGR). Les fichiers ont été collectés en 2000-2001 à partir de diverses sources, notamment des CD personnels, des radios, des enregistrements de microphones, et représentent des sons dans diverses conditions d'enregistrement.
Cet ensemble de données est constitué de sous-dossiers, chaque sous-dossier est un type.
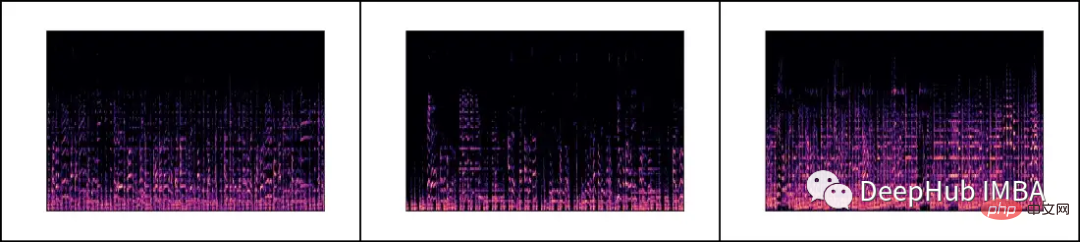
Nous chargerons chaque fichier .wav et générerons le spectre Mel correspondant via la bibliothèque librosa.
Un spectrogramme Mel est une représentation visuelle du contenu spectral d'un signal sonore, avec son axe vertical représentant la fréquence sur l'échelle Mel et l'axe horizontal représentant le temps. Il s'agit d'une représentation couramment utilisée dans le traitement du signal audio, notamment dans le domaine de la recherche d'informations musicales.
Mel scale (anglais : mel scale) est une échelle qui prend en compte la perception humaine de la hauteur. Étant donné que les humains ne perçoivent pas de plages de fréquences linéaires, cela signifie que nous sommes meilleurs pour détecter les différences aux basses fréquences qu’aux hautes fréquences. Par exemple, nous pouvons facilement faire la différence entre 500 Hz et 1 000 Hz, mais nous avons plus de mal à faire la différence entre 10 000 Hz et 10 500 Hz, même si la distance qui les sépare est la même. Ainsi, l'échelle de Mel résout ce problème : si les différences dans l'échelle de Mel sont les mêmes, cela signifie que les différences de hauteur perçues par les humains seront les mêmes.
def wav2melspec(fp):
y, sr = librosa.load(fp)
S = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128)
log_S = librosa.amplitude_to_db(S, ref=np.max)
img = librosa.display.specshow(log_S, sr=sr, x_axis='time', y_axis='mel')
# get current figure without white border
img = plt.gcf()
img.gca().xaxis.set_major_locator(plt.NullLocator())
img.gca().yaxis.set_major_locator(plt.NullLocator())
img.subplots_adjust(top = 1, bottom = 0, right = 1, left = 0,
hspace = 0, wspace = 0)
img.gca().xaxis.set_major_locator(plt.NullLocator())
img.gca().yaxis.set_major_locator(plt.NullLocator())
# to pil image
img.canvas.draw()
img = Image.frombytes('RGB', img.canvas.get_width_height(), img.canvas.tostring_rgb())
return imgLa fonction ci-dessus produira un simple spectrogramme mel :

Maintenant, nous chargeons l'ensemble de données du dossier et appliquons la transformation à l'image.
class AudioDataset(Dataset):
def __init__(self, root, transform=None):
self.root = root
self.transform = transform
self.classes = sorted(os.listdir(root))
self.class_to_idx = {c: i for i, c in enumerate(self.classes)}
self.samples = []
for c in self.classes:
for fp in os.listdir(os.path.join(root, c)):
self.samples.append((os.path.join(root, c, fp), self.class_to_idx[c]))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
fp, target = self.samples[idx]
img = Image.open(fp)
if self.transform:
img = self.transform(img)
return img, target
train_dataset = AudioDataset(root, transform=transforms.Compose([
transforms.Resize((480, 480)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]))Nous utiliserons ViT comme modèle : Vision Transformer a d'abord introduit une image égale à 16x16 mots dans l'article, et a démontré avec succès que cette méthode ne repose sur aucun CNN et est directement appliquée. Un pur transformateur d'un une séquence de correctifs d'images peut bien effectuer les tâches de classification d'images.
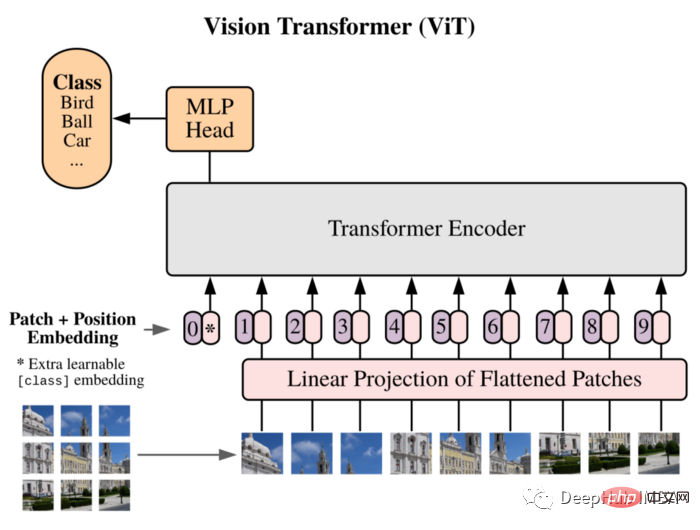
Divisez l'image en patchs et utilisez la séquence d'intégration linéaire de ces patchs comme entrée du transformateur. Les correctifs sont traités de la même manière que les jetons (mots) dans les applications NLP.
En raison de l'absence de biais inductif (tel que la localité) inhérent à CNN, Transformer ne peut pas bien généraliser lorsque la quantité de données d'entraînement est insuffisante. Mais lorsqu’il est entraîné sur de grands ensembles de données, il atteint ou dépasse l’état de l’art sur plusieurs critères de reconnaissance d’images.
La structure de l'implémentation est la suivante :
class ViT(nn.Sequential): def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 356, depth: int = 12, n_classes: int = 1000, **kwargs): super().__init__( PatchEmbedding(in_channels, patch_size, emb_size, img_size), TransformerEncoder(depth, emb_size=emb_size, **kwargs), ClassificationHead(emb_size, n_classes)
La boucle de formation est également un processus de formation traditionnel :
vit = ViT(
n_classes = len(train_dataset.classes)
)
vit.to(device)
# train
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
optimizer = optim.Adam(vit.parameters(), lr=1e-3)
scheduler = ReduceLROnPlateau(optimizer, 'max', factor=0.3, patience=3, verbose=True)
criterion = nn.CrossEntropyLoss()
num_epochs = 30
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
vit.train()
running_loss = 0.0
running_corrects = 0
for inputs, labels in tqdm.tqdm(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(True):
outputs = vit(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(train_dataset)
epoch_acc = running_corrects.double() / len(train_dataset)
scheduler.step(epoch_acc)
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))Cette implémentation personnalisée de l'architecture Vision Transformer a été formée à partir de zéro à l'aide de PyTorch. Étant donné que l'ensemble de données est très petit (seulement 100 échantillons par classe), cela affecte les performances du modèle et seule une précision de 0,71 a été obtenue.
Ceci n'est qu'une simple démonstration, si vous avez besoin d'améliorer les performances du modèle, vous pouvez utiliser un ensemble de données plus grand, ou ajuster légèrement les différents hyperparamètres de l'architecture
Le code vit utilisé ici vient de :
https : //moyen.com/artificialis/vit-visiontransformer-a-pytorch-implementation-8d6a1033bdc5
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 qu'est-ce que l'USDT
qu'est-ce que l'USDT
 Comment définir les deux extrémités pour qu'elles soient alignées en CSS
Comment définir les deux extrémités pour qu'elles soient alignées en CSS
 Le commutateur Bluetooth Win10 est manquant
Le commutateur Bluetooth Win10 est manquant
 Le but du niveau
Le but du niveau
 logiciel erp gratuit
logiciel erp gratuit
 Comment redimensionner des images dans PS
Comment redimensionner des images dans PS








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



