
 Périphériques technologiques
IA
Après l'émergence des très grands modèles, la partie est-elle terminée pour l'IA ? Gary Marcus : La route est étroite
Périphériques technologiques
IA
Après l'émergence des très grands modèles, la partie est-elle terminée pour l'IA ? Gary Marcus : La route est étroite
Après l'émergence des très grands modèles, la partie est-elle terminée pour l'IA ? Gary Marcus : La route est étroite

Ces derniers temps, la technologie de l'intelligence artificielle a fait des percées dans les grands modèles, proposés hier par Google, qui ont une fois de plus déclenché des discussions sur les capacités de l'IA. Grâce à un apprentissage préalable à partir de grandes quantités de données, l’algorithme possède des capacités sans précédent pour créer des images réalistes et comprendre le langage.
De l'avis de beaucoup de gens, nous sommes proches de l'intelligence artificielle générale, mais Gary Marcus, chercheur bien connu et professeur à l'Université de New York, ne le pense pas.
Récemment, son article « La nouvelle science de l'intelligence alternative » a réfuté le point de vue du directeur de recherche de DeepMind, Nando de Freitas, selon lequel « gagner à grande échelle ».
Ce qui suit est le texte original de Gary Marcus :
Depuis des décennies, on suppose dans le domaine de l'IA que l'intelligence artificielle devrait s'inspirer de l'intelligence naturelle. John McCarthy a écrit un article fondateur sur les raisons pour lesquelles l'IA a besoin de bon sens - "Programs with Common Sense" ; Marvin Minsky a écrit le célèbre livre " Society of Mind ", essayant de s'inspirer de la pensée humaine, car en économie comportementale, Herb Simon, qui a remporté le prix ; Prix Nobel d'économie pour ses contributions, a écrit les célèbres "Modèles de pensée", qui visaient à expliquer "comment les langages informatiques nouvellement développés peuvent exprimer des théories de processus psychologiques afin que les ordinateurs puissent simuler un comportement humain prédit
Dans la mesure où". Je sais, une grande partie des chercheurs actuels en IA (du moins les plus influents) s’en moquent du tout. Au lieu de cela, ils se concentrent davantage sur ce que j’appelle « Alt Intelligence » (merci à Naveen Rao pour sa contribution au terme).
Alt Intelligence ne signifie pas construire des machines capables de résoudre des problèmes de la même manière que l'intelligence humaine, mais plutôt utiliser de grandes quantités de données obtenues à partir du comportement humain pour remplacer l'intelligence. Actuellement, l’objectif principal d’Alt Intelligence est la mise à l’échelle. Les partisans de tels systèmes soutiennent que plus le système est grand, plus nous nous rapprocherons de la véritable intelligence et même de la conscience.
Il n’y a rien de nouveau dans l’étude de l’Alt Intelligence elle-même, mais l’arrogance qui y est associée l’est.
Depuis un certain temps, j'ai vu des signes indiquant que les superstars actuelles de l'intelligence artificielle, et même la plupart des gens dans l'ensemble du domaine de l'intelligence artificielle, méprisent la cognition humaine, ignorant ou même se moquant de la linguistique, de la psychologie cognitive, de l'anthropologie et des chercheurs dans ce domaine. des domaines comme la philosophie.
Mais ce matin, j'ai découvert un nouveau tweet sur Alt Intelligence. Nando de Freitas, l'auteur du tweet et directeur de recherche chez DeepMind, a déclaré que l'IA "est désormais une question d'échelle". En fait, selon lui (peut-être délibérément provocateur avec une rhétorique enflammée), les défis les plus difficiles en matière d’IA ont déjà été résolus. « Jeu terminé ! » dit-il.
En substance, il n’y a rien de mal à poursuivre Alt Intelligence.
Alt Intelligence représente une intuition (ou une série d'intuitions) sur la façon de construire des systèmes intelligents. Puisque personne ne sait encore comment construire des systèmes capables d’égaler la flexibilité et l’intelligence de l’intelligence humaine, il est normal que les gens étudient de nombreuses hypothèses différentes sur la manière d’y parvenir. Nando de Freitas défend cette hypothèse le plus crûment possible, et je l'appelle Scaling-Uber-Alles.
Bien sûr, le nom ne lui rend pas entièrement justice. De Freitas est très clair sur le fait qu’on ne peut pas simplement agrandir le modèle et espérer le succès. Les gens ont fait beaucoup de développement ces derniers temps et ont obtenu de grands succès, mais ils ont également rencontré certains obstacles. Avant d’examiner la manière dont De Freitas fait face au statu quo, voyons à quoi ressemble le statu quo.
Status
Des systèmes comme DALL-E 2, GPT-3, Flamingo et Gato peuvent sembler passionnants, mais personne ayant étudié attentivement ces modèles ne les confondrait avec l'intelligence humaine.
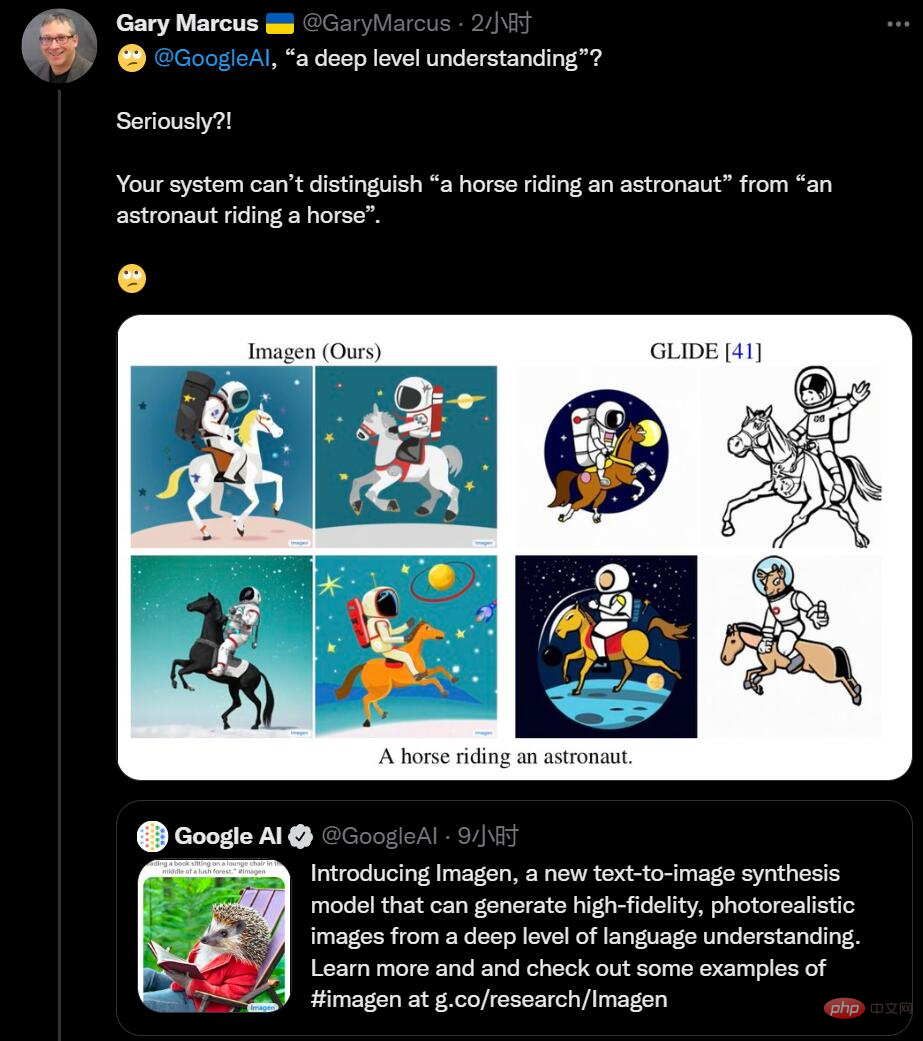
Par exemple, DALL-E 2 peut créer des œuvres d'art réalistes basées sur des descriptions textuelles, telles que « un astronaute sur un cheval » :

Mais il est également enclin à commettre des erreurs surprenantes, comme lorsque le texte Quand la description est "un carré rouge placé sur un carré bleu", les résultats générés par DALL-E sont tels que montré dans l'image de gauche, et l'image de droite est le résultat généré par le modèle précédent. De toute évidence, les résultats de la génération DALL-E sont inférieurs à ceux des modèles précédents.

Lorsque Ernest Davis, Scott Aaronson et moi avons étudié ce problème, nous avons trouvé de nombreux exemples similaires : 
De plus, Flamingo, qui a l'air incroyable en surface, a ses propres bugs, comme l'a dit Murray Shanahan, chercheur principal chez DeepMind, dans Comme indiqué dans un tweet, l'auteur principal de Flamingo, Jean-Baptiste Alayrac, a ensuite ajouté quelques exemples. Par exemple, Shanahan a montré à Flamingo une image comme celle-ci :
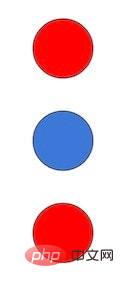
et a eu la conversation imparfaite suivante autour de l'image :

Il semblait qu'elle était "faite à partir de rien".
Il y a quelque temps, DeepMind a également publié l'agent "généraliste" multimodal, multitâche et multi-incarné Gato, mais quand vous regardez les petits caractères, vous pouvez toujours trouver un manque de fiabilité.

Bien entendu, les défenseurs du deep learning souligneront que les humains font des erreurs.
Mais toute personne honnête se rendra compte que ces erreurs indiquent que quelque chose est actuellement défectueux. Il n'est pas exagéré de dire que si mes enfants faisaient régulièrement de telles erreurs, j'abandonnerais tout ce que je fais et les emmènerais immédiatement chez un neurologue.
Alors, soyons honnêtes : la mise à l’échelle ne fonctionne pas encore, mais c’est possible, du moins c’est ce que dit la théorie de de Freitas – une expression claire de l’air du temps.
Scaling-Uber-Alles
Alors, comment de Freitas concilie-t-il réalité et ambition ? En fait, des milliards de dollars ont été investis dans Transformer et dans de nombreux autres domaines connexes, les ensembles de données de formation sont passés de mégaoctets à des gigaoctets et la taille des paramètres est passée de millions à des milliards. Cependant, des erreurs déroutantes qui ont été documentées en détail dans de nombreux travaux depuis 1988 demeurent.
Pour certains (comme moi), l'existence de ces problèmes peut signifier que nous devons procéder à une refonte fondamentale, comme celles soulignées par Davis et moi dans "Rebooting AI". Mais pour de Freitas, ce n’est pas le cas (beaucoup d’autres personnes peuvent aussi partager la même idée que lui, je n’essaie pas de le singulariser, je pense juste que ses propos sont plus représentatifs).
Dans un tweet, il a expliqué son point de vue sur la réconciliation de la réalité avec les problèmes actuels : « (Nous devons) rendre les modèles plus grands, plus sûrs, plus efficaces sur le plan informatique, échantillonner plus rapidement, stocker plus intelligemment et modéliser plus efficacement. nous devons étudier l'innovation des données, en ligne/hors ligne, etc. « Le fait est qu'aucun des mots ne vient de la psychologie cognitive, de la linguistique ou de la philosophie (peut-être qu'une mémoire plus intelligente peut à peine compter).
Dans un post de suivi, de Freitas a également déclaré :
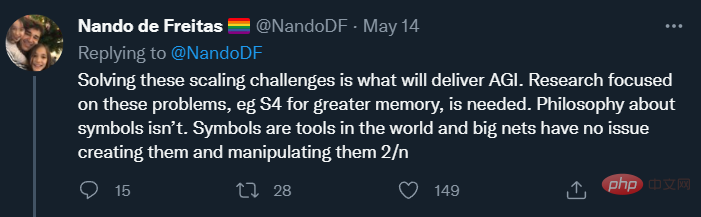
Cela confirme une fois de plus sa déclaration selon laquelle "l'échelle est plus importante que toute autre chose" et indique un objectif : son ambition n'est pas seulement une meilleure IA, mais c'est AGI.
AGI signifie Intelligence Générale Artificielle, qui est au moins aussi bonne, aussi ingénieuse et largement applicable que l'intelligence humaine. Le sens étroit de l'intelligence artificielle que nous concevons actuellement est en fait l'intelligence alternative (intelligence alternative), et ses succès emblématiques sont des jeux tels que les échecs (Deep Blue n'a rien à voir avec l'intelligence humaine) et Go (AlphaGo n'a pas grand-chose à voir avec l'intelligence humaine). . De Freitas a des objectifs plus ambitieux et, à son honneur, il a été très franc à leur sujet. Alors, comment parvient-il à atteindre son objectif ? Pour réitérer ici, de Freitas se concentre sur les outils techniques permettant de gérer des ensembles de données plus importants. D’autres idées, comme celles issues de la philosophie ou des sciences cognitives, peuvent être importantes mais sont exclues.
Il a dit : "La philosophie des symboles n'est pas nécessaire." C’est peut-être une réfutation de mon mouvement de longue date visant à intégrer la manipulation symbolique dans les sciences cognitives et l’intelligence artificielle. L'idée a refait surface récemment dans le magazine Nautilus, même si elle n'a pas été complètement élaborée. Voici ma brève réponse : ce qu'il a dit : « Les réseaux [neuraux] n'ont aucun problème à créer des [symboles] et à les manipuler » ignore à la fois l'histoire et la réalité. Ce qu'il ignore, c'est l'histoire selon laquelle de nombreux passionnés de réseaux neuronaux ont résisté aux symboles pendant des décennies ; il ignore la réalité selon laquelle des descriptions symboliques comme le « cube rouge sur un cube bleu » susmentionné peuvent encore dérouter l'esprit du modèle SOTA 2022.
À la fin du tweet, De Freitas a exprimé son approbation du célèbre article de Rich Sutton « Bitter Lessons » :
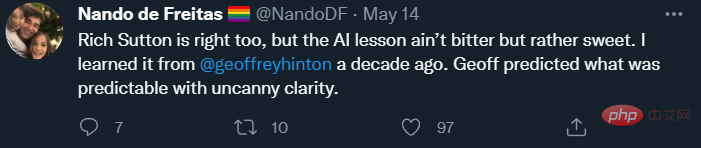
L’argument de Sutton est que la seule chose qui mènera au progrès de l’IA est davantage de données et un calcul plus efficace. À mon avis, Sutton n’a qu’à moitié raison, sa description du passé est presque correcte, mais ses prédictions inductives de l’avenir ne sont pas convaincantes.
Jusqu'à présent, le big data a (temporairement) vaincu l'ingénierie des connaissances bien conçue dans la plupart des domaines (et certainement pas dans tous les domaines).
Mais presque tous les logiciels dans le monde, des navigateurs Web aux feuilles de calcul en passant par les traitements de texte, reposent toujours sur l'ingénierie des connaissances, et Sutton l'ignore. Par exemple, l'excellente fonctionnalité Flash Fill de Sumit Gulwani est un système d'apprentissage ponctuel très utile qui n'est pas du tout construit sur le principe du Big Data, mais sur des techniques de programmation classiques.
Je ne pense pas qu’un système d’apprentissage profond/big data pur puisse égaler cela.
En fait, les principaux problèmes de l'intelligence artificielle que les scientifiques cognitifs comme Steve Pinker, Judea Pearl, Jerry Fodor et moi-même avons soulignés depuis des décennies n'ont en réalité pas encore été résolus. Oui, les machines peuvent très bien jouer à des jeux, et l’apprentissage profond a apporté d’énormes contributions dans des domaines tels que la reconnaissance vocale. Mais aucune intelligence artificielle n'a actuellement suffisamment de compréhension pour reconnaître un texte et construire un modèle capable de parler normalement et d'accomplir des tâches, ni de raisonner et de produire une réponse cohérente comme les ordinateurs des films "Star Trek".
Nous en sommes encore aux premiers stades de l’intelligence artificielle.
Réussir certains problèmes en utilisant des stratégies spécifiques ne garantit pas que nous résoudrons tous les problèmes de la même manière. Il serait tout simplement insensé de ne pas s’en rendre compte, surtout lorsque certains modes de défaillance (manque de fiabilité, bogues étranges, échecs combinatoires et incompréhension) restent inchangés depuis que Fodor et Pinker les ont signalés en 1988. Conclusion
Il est bon de voir que Scaling-Über-Alles ne sont pas encore entièrement convenus, même chez DeepMind :
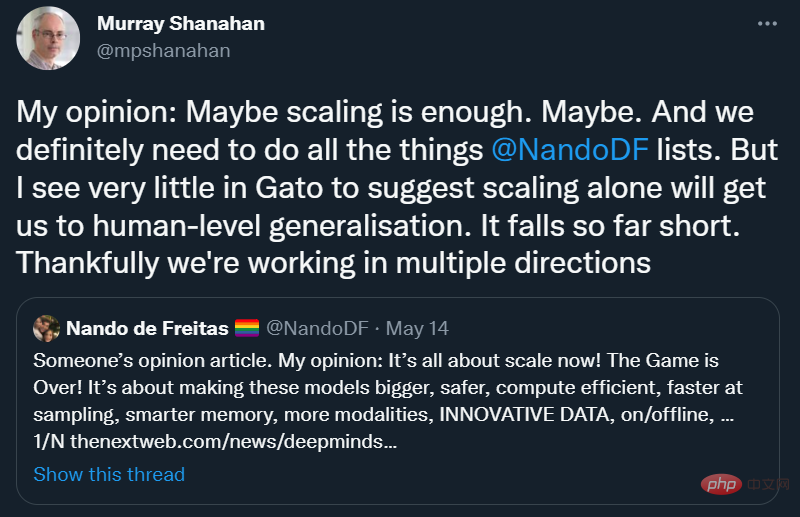
Je suis entièrement d'accord avec Murray Shanahan : « Je vois très peu de choses chez Gato pour suggérer que la mise à l'échelle à elle seule suffira. amène-nous à une généralisation au niveau humain".
Encourageons un domaine suffisamment ouvert d'esprit pour que les gens puissent orienter leur propre travail dans de nombreuses directions sans rejeter prématurément des idées qui ne sont pas encore pleinement développées. Après tout, la meilleure voie vers l’intelligence artificielle (générale) n’est peut-être pas l’Alt Intelligence.
Comme mentionné précédemment, j'aimerais considérer Gato comme une « intelligence alternative » - une exploration intéressante de façons alternatives de construire l'intelligence, mais nous devons le mettre en perspective : il ne fonctionnera pas comme un cerveau, il ne fonctionnera pas comme un enfant. Appris de cette façon, il ne comprend pas la langue, n'est pas conforme aux valeurs humaines et on ne peut pas lui faire confiance pour accomplir des tâches critiques.
C'est peut-être mieux que tout ce que nous avons actuellement, mais cela ne fonctionne toujours pas vraiment, et même après avoir investi massivement dedans, il est temps pour nous de faire une pause.
Cela devrait nous ramener à l’ère des startups de l’intelligence artificielle. L’intelligence artificielle ne devrait certainement pas être une copie aveugle de l’intelligence humaine. Après tout, elle a ses propres défauts, notamment une mauvaise mémoire et des biais cognitifs. Mais il devrait s’appuyer sur la cognition humaine et animale pour trouver des indices. Les frères Wright n'ont pas imité les oiseaux, mais ils ont appris quelque chose sur leur contrôle de vol. Savoir de quoi nous pouvons et ne pouvons pas apprendre peut représenter plus de la moitié de notre réussite.
Je pense que l'essentiel est ce que l'IA valorisait autrefois mais ne poursuit plus : si nous voulons construire l'AGI, nous allons devoir apprendre quelque chose des humains - comment ils raisonnent et comprennent le monde physique, et comment ils le représentent. informatique et acquisition du langage et des concepts complexes.
Il serait trop arrogant de nier cette idée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 Surveillez les gouttelettes MySQL et MariaDB avec Exportateur de Prometheus Mysql
Apr 08, 2025 pm 02:42 PM
Surveillez les gouttelettes MySQL et MariaDB avec Exportateur de Prometheus Mysql
Apr 08, 2025 pm 02:42 PM
Une surveillance efficace des bases de données MySQL et MARIADB est essentielle pour maintenir des performances optimales, identifier les goulots d'étranglement potentiels et assurer la fiabilité globale du système. Prometheus Mysql Exportateur est un outil puissant qui fournit des informations détaillées sur les mesures de base de données qui sont essentielles pour la gestion et le dépannage proactifs.
