

Dans le travail quotidien d'exploration de données, en plus d'utiliser Python pour gérer des tâches de classification ou de prédiction, cela implique parfois également des tâches liées aux systèmes de recommandation.
Les systèmes de recommandation sont utilisés dans divers domaines, les exemples courants incluent les générateurs de playlists pour les services vidéo et musicaux, les recommandations de produits pour les boutiques en ligne ou les recommandations de contenu pour les plateformes de médias sociaux. Dans ce projet, nous créons un outil de recommandation de films.
Le filtrage collaboratif prédit (filtre) automatiquement les intérêts des utilisateurs en collectant les préférences ou les informations sur les goûts de nombreux utilisateurs. Les systèmes de recommandation sont développés depuis longtemps et leurs modèles sont basés sur diverses techniques telles que la moyenne pondérée, la corrélation, l'apprentissage automatique, l'apprentissage profond, etc.
L'ensemble de données Movielens 20M compte plus de 20 millions d'audiences de films et d'événements de marquage depuis 1995. Dans cet article, nous récupérerons les informations des fichiers movie.csv et rating.csv. Utilisez les bibliothèques Python : Pandas, Seaborn, Scikit-learn et SciPy pour entraîner le modèle en utilisant la similarité cosinus dans l'algorithme du k-voisin le plus proche.
Voici les étapes principales du projet :
MovieLens 20M d'ensembles de données de plus de 20 millions d'audiences de films et d'activités de marquage depuis 1995.
# usecols 允许选择自己选择的特征,并通过dtype设定对应类型
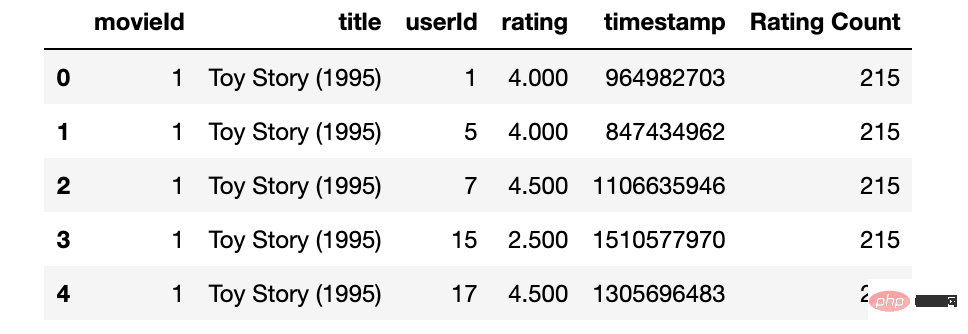
movies_df=pd.read_csv('movies.csv',
usecols=['movieId','title'],
dtype={'movieId':'int32','title':'str'})
movies_df.head()
ratings_df=pd.read_csv('ratings.csv',
usecols=['userId', 'movieId', 'rating','timestamp'],
dtype={'userId': 'int32', 'movieId': 'int32', 'rating': 'float32'})
ratings_df.head()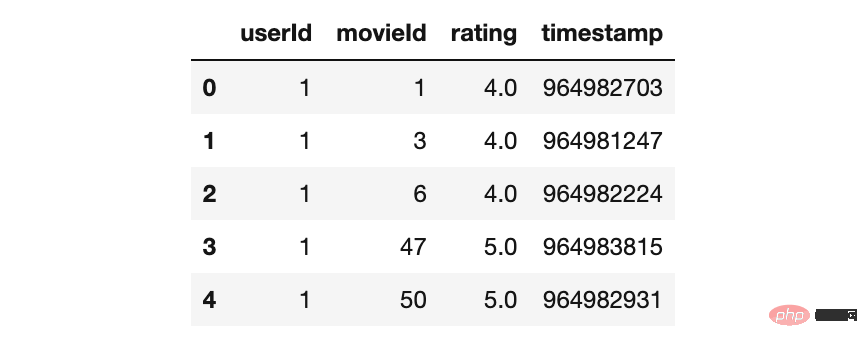
Vérifie s'il y a des valeurs nulles et le nombre d'entrées dans les deux données.
# 检查缺失值 movies_df.isnull().sum()
movieId 0
titre 0
dtype: int64
ratings_df.isnull().sum()
userId 0
movieId 0
rating 0
timestamp 0
dtype : int 64
print("Movies:",movies_df.shape)
print("Ratings:",ratings_df.shape)Films : (9742, 2 )
Notes : (100836, 4)
Fusionner la trame de données sur la colonne 'movieId'
# movies_df.info() # ratings_df.info() movies_merged_df=movies_df.merge(ratings_df, on='movieId') movies_merged_df.head()
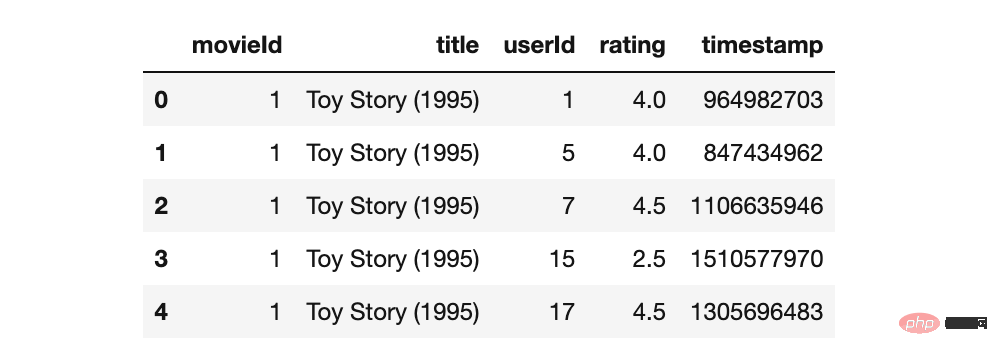
L'ensemble de données importé a maintenant été fusionné avec succès.
Ajoutez les fonctionnalités nécessaires pour analyser les données.
Créez les colonnes « Note moyenne » et « Nombre de notes » en regroupant les notes des utilisateurs par titre de film.
movies_average_rating=movies_merged_df.groupby('title')['rating']
.mean().sort_values(ascending=False)
.reset_index().rename(columns={'rating':'Average Rating'})
movies_average_rating.head()
movies_rating_count=movies_merged_df.groupby('title')['rating']
.count().sort_values(ascending=True)
.reset_index().rename(columns={'rating':'Rating Count'}) #ascending=False
movies_rating_count_avg=movies_rating_count.merge(movies_average_rating, on='title')
movies_rating_count_avg.head()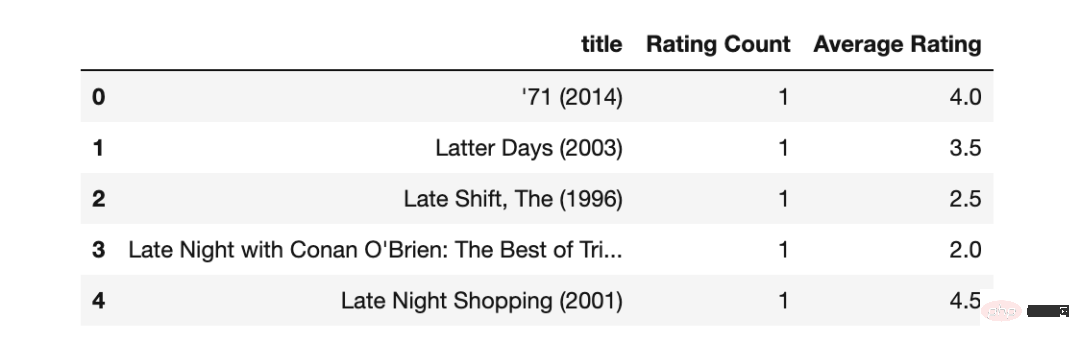
Actuellement 2 nouvelles fonctionnalités dérivées ont été créées.
Visualisation des données à l'aide de Seaborn :
Utilisez seaborn & matplotlib pour visualiser les données afin de mieux observer et analyser les données.
Tracez un histogramme des fonctionnalités nouvellement créées et voyez leur distribution. Définissez la taille du bac sur 80. Le réglage de cette valeur nécessite une analyse détaillée et un réglage raisonnable.
# 导入可视化库
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(font_scale = 1)
plt.rcParams["axes.grid"] = False
plt.style.use('dark_background')
%matplotlib inline
# 绘制图形
plt.figure(figsize=(12,4))
plt.hist(movies_rating_count_avg['Rating Count'],bins=80,color='tab:purple')
plt.ylabel('Ratings Count(Scaled)', fontsize=16)
plt.savefig('ratingcounthist.jpg')
plt.figure(figsize=(12,4))
plt.hist(movies_rating_count_avg['Average Rating'],bins=80,color='tab:purple')
plt.ylabel('Average Rating',fontsize=16)
plt.savefig('avgratinghist.jpg')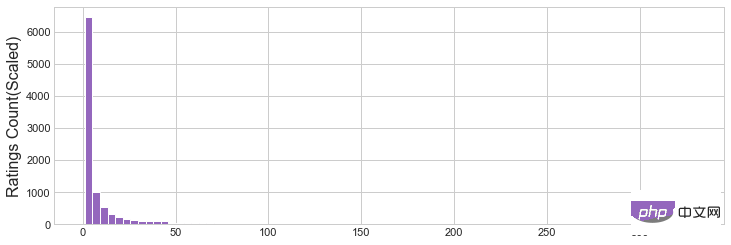
Figure 1 Histogramme de la note moyenne
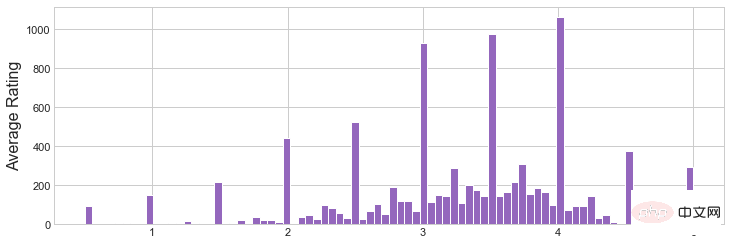
Figure 2 Histogramme du nombre de notes
Créez maintenant un graphique 2D joinplot pour visualiser ces deux caractéristiques ensemble.
plot=sns.jointplot(x='Average Rating',
y='Rating Count',
data=movies_rating_count_avg,
alpha=0.5,
color='tab:pink')
plot.savefig('joinplot.jpg')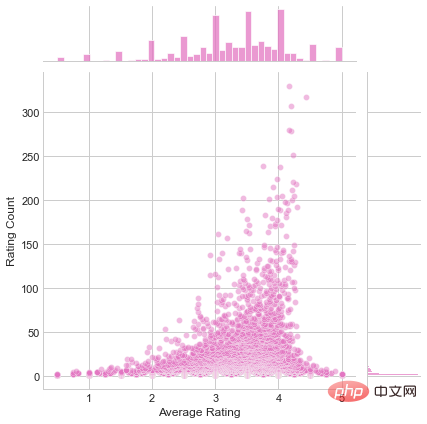
Graphique bidimensionnel de la note moyenne et du nombre de notes
运用describe()函数得到数据集的描述统计值,如分位数和标准差等。
pd.set_option('display.float_format', lambda x: '%.3f' % x)
print(rating_with_RatingCount['Rating Count'].describe())count 100836.000 mean58.759 std 61.965 min1.000 25% 13.000 50% 39.000 75% 84.000 max329.000 Name: Rating Count, dtype: float64
设置阈值并筛选出高于阈值的数据。
popularity_threshold = 50 popular_movies= rating_with_RatingCount[ rating_with_RatingCount['Rating Count']>=popularity_threshold] popular_movies.head() # popular_movies.shape
至此已经通过过滤掉了评论低于阈值的电影来清洗数据。
创建一个以用户为索引、以电影为列的数据透视表
为了稍后将数据加载到模型中,需要创建一个数据透视表。并设置'title'作为索引,'userId'为列,'rating'为值。
import os
movie_features_df=popular_movies.pivot_table(
index='title',columns='userId',values='rating').fillna(0)
movie_features_df.head()
movie_features_df.to_excel('output.xlsx')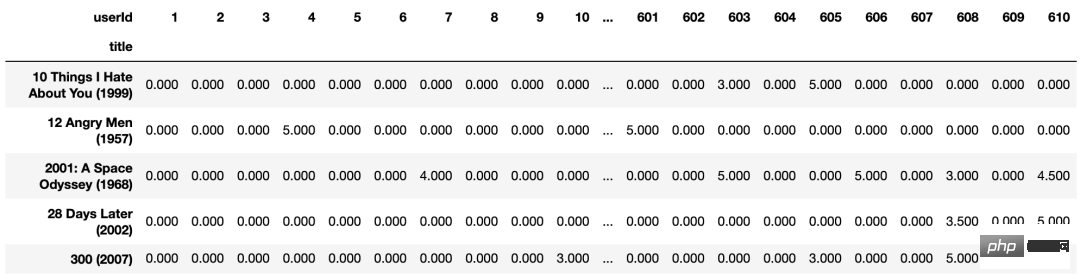
接下来将创建的数据透视表加载到模型。
建立 kNN 模型并输出与每部电影相似的 5 个推荐
使用scipy.sparse模块中的csr_matrix方法,将数据透视表转换为用于拟合模型的数组矩阵。
from scipy.sparse import csr_matrix movie_features_df_matrix = csr_matrix(movie_features_df.values)
最后,使用之前生成的矩阵数据,来训练来自sklearn中的NearestNeighbors算法。并设置参数:metric = 'cosine', algorithm = 'brute'
from sklearn.neighbors import NearestNeighbors model_knn = NearestNeighbors(metric = 'cosine', algorithm = 'brute') model_knn.fit(movie_features_df_matrix)
现在向模型传递一个索引,根据'kneighbors'算法要求,需要将数据转换为单行数组,并设置n_neighbors的值。
query_index = np.random.choice(movie_features_df.shape[0]) distances, indices = model_knn.kneighbors(movie_features_df.iloc[query_index,:].values.reshape(1, -1), n_neighbors = 6)
最后在 query_index 中输出出电影推荐。
for i in range(0, len(distances.flatten())):
if i == 0:
print('Recommendations for {0}:n'
.format(movie_features_df.index[query_index]))
else:
print('{0}: {1}, with distance of {2}:'
.format(i, movie_features_df.index[indices.flatten()[i]],
distances.flatten()[i]))Recommendations for Harry Potter and the Order of the Phoenix (2007): 1: Harry Potter and the Half-Blood Prince (2009), with distance of 0.2346513867378235: 2: Harry Potter and the Order of the Phoenix (2007), with distance of 0.3396233320236206: 3: Harry Potter and the Goblet of Fire (2005), with distance of 0.4170845150947571: 4: Harry Potter and the Prisoner of Azkaban (2004), with distance of 0.4499547481536865: 5: Harry Potter and the Chamber of Secrets (2002), with distance of 0.4506162405014038:
至此我们已经能够成功构建了一个仅基于用户评分的推荐引擎。
以下是我们构建电影推荐系统的步骤摘要:
以下是可以扩展项目的一些方法:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



