

Dans le domaine de l'apprentissage automatique, il existe un dicton intitulé « Il n'y a pas de repas gratuit dans le monde ». En bref, cela signifie qu'aucun algorithme ne peut avoir le meilleur effet sur chaque problème. Cette théorie concerne particulièrement les aspects de l'apprentissage supervisé. important.
Par exemple, on ne peut pas dire que les réseaux de neurones sont toujours meilleurs que les arbres de décision, ou vice versa. L'exécution du modèle est influencée par de nombreux facteurs, tels que la taille et la structure de l'ensemble de données.
Par conséquent, vous devriez essayer de nombreux algorithmes différents en fonction de votre problème, tout en utilisant un ensemble de données de test pour évaluer les performances et choisir le meilleur.
Bien sûr, l'algorithme que vous essayez doit être pertinent par rapport à votre problème, et la clé est la tâche principale de l'apprentissage automatique. Par exemple, si vous vouliez nettoyer votre maison, vous pourriez utiliser un aspirateur, un balai ou une vadrouille, mais vous ne prendriez pas une pelle pour commencer à creuser un trou.
Pour les nouveaux venus dans le machine learning et désireux de comprendre les bases du machine learning, voici les dix meilleurs algorithmes de machine learning utilisés par les data scientists pour vous présenter les caractéristiques de ces dix meilleurs algorithmes afin que chacun puisse mieux les comprendre et les appliquer. . Allez, regarde.
La régression linéaire est probablement l'un des algorithmes les plus connus et les plus faciles à comprendre en matière de statistiques et d'apprentissage automatique.
Étant donné que la modélisation prédictive vise principalement à minimiser l'erreur du modèle, ou à faire les prédictions les plus précises au détriment de l'interprétabilité. Nous empruntons, réutilisons et volons des algorithmes dans de nombreux domaines différents, et certaines connaissances statistiques sont impliquées.
La régression linéaire est représentée par une équation qui décrit la relation linéaire entre la variable d'entrée (x) et la variable de sortie (y) en trouvant le poids spécifique (B) de la variable d'entrée.
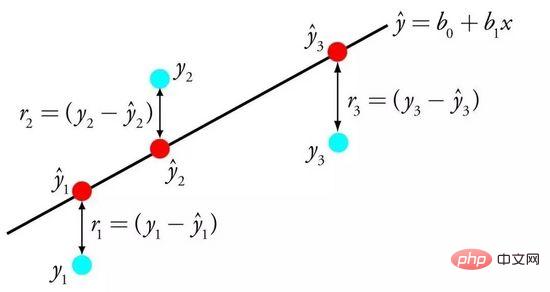
Régression linéaire
Étant donné l'entrée x, on va prédire y, le but de l'algorithme d'apprentissage par régression linéaire est de retrouver les valeurs des coefficients B0 et B1.
Les modèles de régression linéaire peuvent être appris à partir de données en utilisant différentes techniques, telles que les solutions d'algèbre linéaire pour les moindres carrés ordinaires et l'optimisation de la descente de gradient.
La régression linéaire existe depuis plus de 200 ans et a fait l'objet de nombreuses recherches. Certaines règles empiriques lors de l'utilisation de cette technique consistent à supprimer les variables très similaires (corrélées) et à supprimer le bruit des données si possible. Il s'agit d'une technique simple et rapide et d'un bon premier algorithme.
La régression logistique est une autre technique que l'apprentissage automatique emprunte au domaine des statistiques. Il s'agit d'une méthode spécialisée pour les problèmes de classification binaire (problèmes avec deux valeurs de classe).
La régression logistique est similaire à la régression linéaire dans la mesure où le but des deux est de trouver la valeur de poids de chaque variable d'entrée. Contrairement à la régression linéaire, la valeur prédite du résultat est transformée à l’aide d’une fonction non linéaire appelée fonction logistique.
Les fonctions logistiques ressemblent à un grand S et convertissent n'importe quelle valeur dans la plage de 0 à 1. Ceci est utile car nous pouvons appliquer les règles correspondantes à la sortie de la fonction logistique, classer les valeurs en 0 et 1 (par exemple, si IF est inférieur à 0,5, alors sortir 1) et prédire la valeur de la classe.
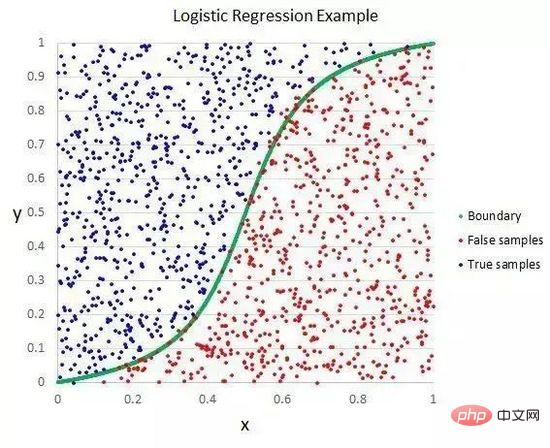
Régression logistique
En raison de la méthode d'apprentissage unique du modèle, les prédictions faites par régression logistique peuvent également être utilisées pour calculer la probabilité d'appartenir à la classe 0 ou à la classe 1. Ceci est utile pour les problèmes qui nécessitent beaucoup de justification.
Comme la régression linéaire, la régression logistique fonctionne mieux lorsque vous supprimez les attributs qui ne sont pas liés à la variable de sortie et les attributs qui sont très similaires (corrélés) les uns aux autres. Il s'agit d'un modèle qui apprend rapidement et gère efficacement les problèmes de classification binaire.
La régression logistique traditionnelle est limitée aux problèmes de classification binaire. Si vous avez plus de deux classes, l'analyse discriminante linéaire (LDA) est la technique de classification linéaire préférée.
La représentation de LDA est très simple. Il se compose de propriétés statistiques de vos données, calculées en fonction de chaque catégorie. Pour une seule variable d'entrée, cela inclut :
La valeur moyenne pour chaque catégorie.
Variance calculée sur toutes les catégories.
Analyse discriminante linéaire
LDA est effectuée en calculant la valeur discriminante de chaque classe et en faisant une prédiction pour la classe avec la valeur maximale. Cette technique suppose que les données ont une distribution gaussienne (courbe en cloche), il est donc préférable de supprimer d'abord manuellement les valeurs aberrantes des données. Il s’agit d’une approche simple mais puissante pour les problèmes de modélisation prédictive de classification.
L'arbre de décision est un algorithme important pour l'apprentissage automatique.
Le modèle d'arbre de décision peut être représenté par un arbre binaire. Oui, c'est un arbre binaire issu d'algorithmes et de structures de données, rien de spécial. Chaque nœud représente une seule variable d'entrée (x) et les enfants gauche et droit de cette variable (en supposant que les variables sont des nombres).
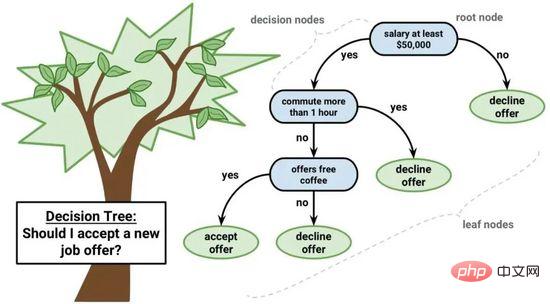
Arbre de décision
Les nœuds feuilles de l'arbre contiennent les variables de sortie (y) utilisées pour faire des prédictions. La prédiction est effectuée en parcourant l'arborescence, en s'arrêtant lorsqu'un certain nœud feuille est atteint et en produisant la valeur de classe du nœud feuille.
Les arbres de décision ont une vitesse d'apprentissage rapide et une vitesse de prédiction rapide. Les prévisions sont souvent précises pour de nombreux problèmes et vous n'avez pas besoin de préparer spécialement les données.
Naive Bayes est un algorithme de modélisation prédictive simple mais extrêmement puissant.
Le modèle se compose de deux types de probabilités qui peuvent être calculées directement à partir de vos données d'entraînement : 1) la probabilité de chaque classe ; 2) la probabilité conditionnelle de la classe étant donné chaque valeur x. Une fois calculé, le modèle probabiliste peut être utilisé pour faire des prédictions sur de nouvelles données en utilisant le théorème de Bayes. Lorsque vos données sont numériques, il est courant de supposer une distribution gaussienne (courbe en cloche) afin que ces probabilités puissent être facilement estimées.
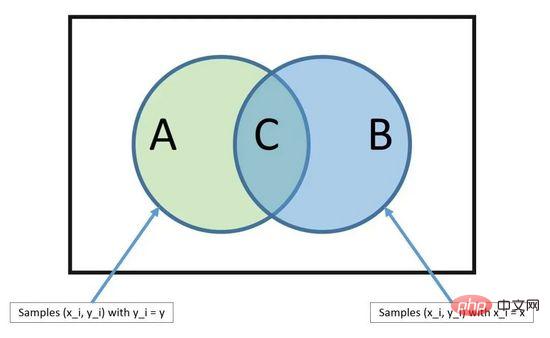
Théorème de Bayes
La raison pour laquelle Naive Bayes est appelé naïf est qu'il suppose que chaque variable d'entrée est indépendante. Il s’agit d’une hypothèse forte, irréaliste pour des données réelles, mais la technique reste très efficace pour des problèmes complexes à grande échelle.
L'algorithme KNN est très simple et très efficace. Le modèle de KNN est représenté par l'ensemble des données de formation. N'est-ce pas très simple ?
Prédisez de nouveaux points de données en recherchant les K instances (voisines) les plus similaires dans l'ensemble de la formation et en résumant les variables de sortie de ces K instances. Pour les problèmes de régression, les nouveaux points peuvent être la variable de sortie moyenne, et pour les problèmes de classification, les nouveaux points peuvent être la valeur de la catégorie de mode.
Le secret du succès réside dans la manière de déterminer les similitudes entre les instances de données. Si vos attributs sont tous sur la même échelle, le moyen le plus simple consiste à utiliser la distance euclidienne, qui peut être calculée directement à partir de la différence entre chaque variable d'entrée.
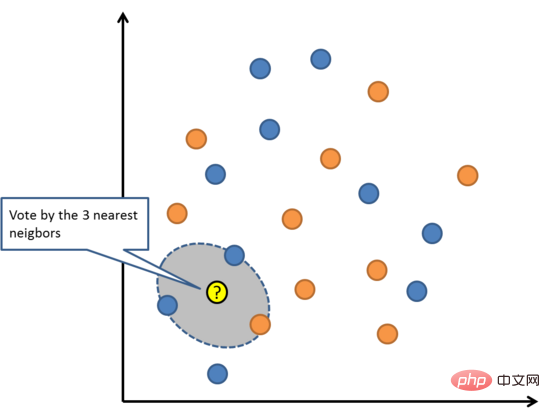
K-Nearest Neighbours
KNN peut nécessiter beaucoup de mémoire ou d'espace pour stocker toutes les données, mais n'effectuera des calculs (ou un apprentissage) que lorsque des prédictions sont nécessaires. Vous pouvez également mettre à jour et gérer votre ensemble d'entraînement à tout moment pour maintenir la précision des prédictions.
Le concept de distance ou de proximité peut s'effondrer dans des environnements de grande dimension (grand nombre de variables d'entrée), ce qui peut avoir un impact négatif sur l'algorithme. De tels événements sont connus sous le nom de malédictions dimensionnelles. Cela implique également que vous ne devez utiliser que les variables d'entrée les plus pertinentes pour prédire la variable de sortie.
L'inconvénient des K-voisins les plus proches est que vous devez conserver l'ensemble des données d'entraînement. Learning Vector Quantization (ou LVQ en abrégé) est un algorithme de réseau neuronal artificiel qui vous permet de suspendre un nombre illimité d'instances de formation et de les apprendre avec précision.
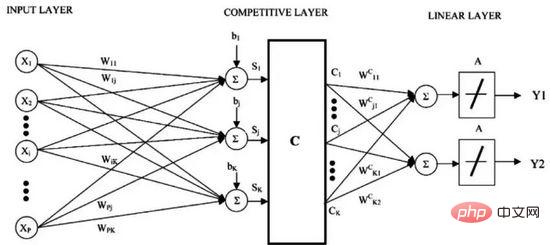
Quantisation des vecteurs d'apprentissage
LVQ est représenté par une collection de vecteurs de livres de codes. Commencez par sélectionner des vecteurs au hasard, puis répétez plusieurs fois pour vous adapter à l'ensemble de données d'entraînement. Après l'apprentissage, le vecteur du livre de codes peut être utilisé pour la prédiction comme les K-voisins les plus proches. Recherchez le voisin le plus similaire (meilleure correspondance) en calculant la distance entre chaque vecteur de livre de codes et la nouvelle instance de données, puis renvoyez la valeur de classe de la meilleure unité correspondante ou la valeur réelle en cas de régression comme prédiction. Les meilleurs résultats sont obtenus si vous limitez les données à la même plage (par exemple entre 0 et 1).
Si vous constatez que KNN donne de bons résultats sur votre ensemble de données, essayez d'utiliser LVQ pour réduire les besoins en mémoire liés au stockage de l'intégralité de l'ensemble de données d'entraînement.
Les machines à vecteurs de support sont peut-être l'un des algorithmes d'apprentissage automatique les plus populaires et les plus discutés.
Un hyperplan est une ligne qui divise l'espace des variables d'entrée. Dans SVM, un hyperplan est sélectionné pour séparer les points dans l'espace variable d'entrée en fonction de leurs catégories (catégorie 0 ou catégorie 1). Elle peut être considérée comme une ligne dans un espace bidimensionnel, et tous les points d'entrée peuvent être complètement séparés par cette ligne. L'algorithme d'apprentissage SVM consiste à trouver les coefficients qui permettent à l'hyperplan de séparer au mieux les catégories.
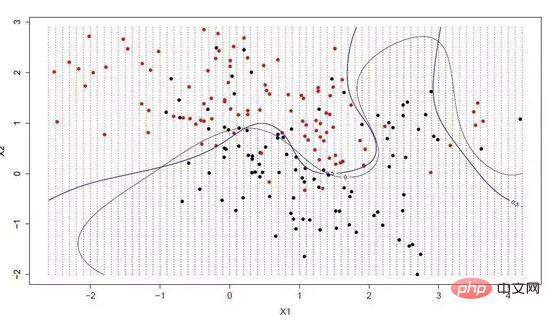
Support Vector Machine
La distance entre l'hyperplan et le point de données le plus proche est appelée la limite. L'hyperplan avec la plus grande limite est le meilleur choix. Dans le même temps, seuls ces points de données proches sont liés à la définition de l'hyperplan et à la construction du classificateur. Ces points sont appelés vecteurs de support, et ils supportent ou définissent l'hyperplan. Dans la pratique spécifique, nous utiliserons des algorithmes d'optimisation pour trouver des valeurs de coefficient qui maximisent la limite.
SVM est probablement l'un des classificateurs prêts à l'emploi les plus puissants et vaut la peine d'être essayé sur votre ensemble de données.
Random Forest est l'un des algorithmes d'apprentissage automatique les plus populaires et les plus puissants. Il s'agit d'un algorithme d'apprentissage automatique intégré appelé Bootstrap Aggregation ou Bagging.
Bootstrap est une méthode statistique puissante utilisée pour estimer une quantité, telle que la moyenne, à partir d'un échantillon de données. Il prend un grand nombre d'échantillons de données, calcule la moyenne, puis fait la moyenne de toutes les moyennes pour obtenir une estimation plus précise de la vraie moyenne.
La même méthode est utilisée pour le bagging, mais les arbres de décision sont le plus souvent utilisés au lieu d'estimer l'ensemble du modèle statistique. Il multi-échantillonne les données d'entraînement, puis crée un modèle pour chaque échantillon de données. Lorsque vous devez faire une prédiction sur de nouvelles données, chaque modèle effectue une prédiction et fait la moyenne des prédictions pour obtenir une meilleure estimation de la véritable valeur de sortie.
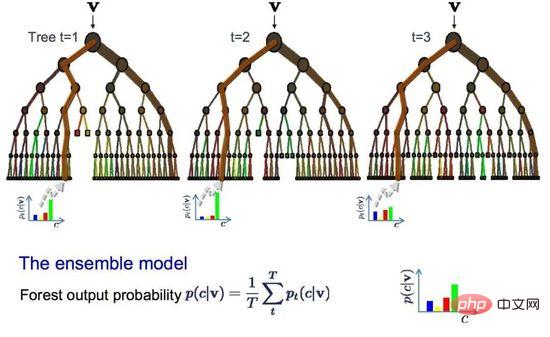
Random Forest
Random Forest est un ajustement de l'arbre de décision au lieu de sélectionner le meilleur point de partage, Random Forest réalise une segmentation sous-optimale en introduisant le hasard.
Par conséquent, les modèles créés pour chaque échantillon de données seront plus différents les uns des autres, mais toujours précis dans leur propre sens. La combinaison des résultats de prédiction fournit une meilleure estimation de la valeur de sortie potentielle correcte.
Si vous obtenez de bons résultats en utilisant des algorithmes à forte variance (tels que les arbres de décision), l'ajout de cet algorithme vous donnera de meilleurs résultats.
Le Boosting est une technique d'ensemble qui crée un classificateur fort à partir de certains classificateurs faibles. Il construit d'abord un modèle à partir des données d'entraînement, puis crée un deuxième modèle pour tenter de corriger les erreurs du premier modèle. Ajoutez continuellement des modèles jusqu'à ce que l'ensemble d'entraînement prédit parfaitement ou ait été ajouté à la limite supérieure.
AdaBoost est le premier algorithme de Boosting véritablement réussi développé pour la classification binaire, et c'est également le meilleur point de départ pour comprendre le Boosting. L'algorithme le plus célèbre actuellement construit sur la base d'AdaBoost est l'augmentation du gradient stochastique.
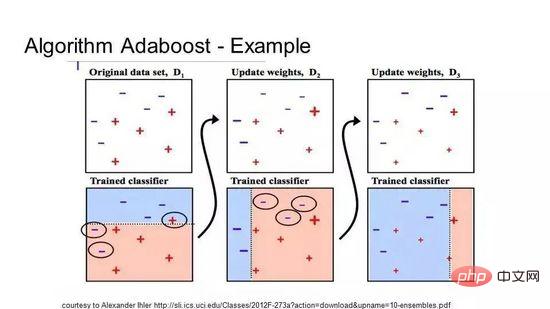
AdaBoost
AdaBoost est souvent utilisé avec des arbres de décision courts. Une fois la première arborescence créée, les performances de chaque instance de formation sur l’arborescence déterminent l’attention que l’arborescence suivante doit consacrer à cette instance de formation. Les données d'entraînement difficiles à prédire reçoivent plus de poids, tandis que les instances faciles à prédire reçoivent moins de poids. Les modèles sont créés séquentiellement et chaque mise à jour du modèle affecte l'effet d'apprentissage de l'arborescence suivante dans la séquence. Une fois tous les arbres construits, l'algorithme fait des prédictions sur les nouvelles données et pondère les performances de chaque arbre en fonction de sa précision sur les données d'entraînement.
Étant donné que l'algorithme accorde une grande attention à la correction des erreurs, des données propres et sans valeurs aberrantes sont très importantes.
Une question typique posée par les débutants confrontés à la grande variété d'algorithmes d'apprentissage automatique est "Quel algorithme dois-je utiliser ?". La réponse à la question dépend de nombreux facteurs, notamment :
Même un data scientist expérimenté n'a aucun moyen de savoir quel algorithme fonctionnera le mieux jusqu'à ce qu'il essaie différents algorithmes. Bien qu’il existe de nombreux autres algorithmes d’apprentissage automatique, ces algorithmes sont les plus populaires. Si vous débutez dans l’apprentissage automatique, c’est un excellent point de départ.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Algorithme de remplacement de page
Algorithme de remplacement de page
 Introduction aux touches de raccourci de capture d'écran dans le système Windows 7
Introduction aux touches de raccourci de capture d'écran dans le système Windows 7
 Méthodes pour prévenir les attaques CC
Méthodes pour prévenir les attaques CC
 Que faire si la connexion win8wifi n'est pas disponible
Que faire si la connexion win8wifi n'est pas disponible
 numéro de série Photoshop CS5
numéro de série Photoshop CS5
 Quelle plateforme est la meilleure pour le trading de devises virtuelles ?
Quelle plateforme est la meilleure pour le trading de devises virtuelles ?
 Combien de personnes pouvez-vous élever sur Douyin ?
Combien de personnes pouvez-vous élever sur Douyin ?
 Plug-in TV Mango
Plug-in TV Mango
 Comment activer les achats groupés Douyin
Comment activer les achats groupés Douyin








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



