
 Périphériques technologiques
IA
CMU publie un nouvel algorithme de robot adroit qui apprend avec précision à faire fonctionner les meubles de tous les jours
Périphériques technologiques
IA
CMU publie un nouvel algorithme de robot adroit qui apprend avec précision à faire fonctionner les meubles de tous les jours
CMU publie un nouvel algorithme de robot adroit qui apprend avec précision à faire fonctionner les meubles de tous les jours

La plupart des meubles avec lesquels les gens entrent en contact dans la vie quotidienne sont des "objets articulés", comme les tiroirs avec rails coulissants, les portes à axe de rotation vertical, les fours à axe de rotation horizontal, car les parties principales de ces objets sont reliés par diverses articulations.
Du fait de l'existence de ces articulations, les différentes parties des pièces de l'objet à connecter sont cinématiquement contraintes par les articulations, ces pièces n'ont donc qu'un seul degré de liberté (1 DoF). Ces objets sont partout dans notre vie, notamment dans notre maison quotidienne. Ils constituent une partie importante de notre vie quotidienne. En tant qu’humains, nous constatons que quel que soit le type de mobilier dont nous disposons, nous pouvons rapidement comprendre comment le manipuler et le contrôler. C'est comme si nous connaissions le mouvement de chaque articulation de ces objets.
Alors les robots peuvent-ils prédire comment les meubles bougeront comme les humains ? Ce type de capacité prédictive est difficile à obtenir, et si les robots pouvaient acquérir cette capacité, cela constituerait un énorme coup de pouce pour les robots domestiques.
Récemment, deux étudiants du laboratoire R-PAD du professeur David Held de la CMU School of Robotics, Ben Eisner et Harry Zhang, ont fait des percées dans la manipulation d'objets communs complexes et ont lancé FlowBot 3D, un réseau neuronal 3D basé sur robot. Algorithmes qui expriment et prédisent efficacement les trajectoires de mouvement de parties d’objets articulés, tels que les meubles de tous les jours. L'algorithme contient deux parties.
La première partie est la partie perception, qui utilise un réseau neuronal profond 3D pour prédire la trajectoire de mouvement instantané tridimensionnel (Flux Articulé 3D) à partir des données de nuage de points du meuble manipulé.
La deuxième partie de l'algorithme est la partie politique, qui utilise le flux articulé 3D prédit pour sélectionner la prochaine action du robot. Les deux sont entièrement appris dans le simulateur et peuvent être mis en œuvre directement dans le monde réel sans recyclage ni réglage. Grâce aux algorithmes FlowBot 3D, les robots peuvent manipuler à volonté des objets articulés tels que des meubles du quotidien, tout comme les humains.


Cet article est actuellement le meilleur article candidat (top 3%) à la plus grande conférence mondiale sur la robotique Robotics Science and Systems (RSS) 2022, et sera exposé à New York, aux États-Unis. en juillet, il a publié et concouru avec 7 autres excellents articles pour l'honneur du meilleur article.
- Adresse papier : https://arxiv.org/pdf/2205.04382.pdf
- Page d'accueil du projet : https://sites.google.com/view/articulated-flowbot-3d
FlowBot 3D s'appuie uniquement sur le simulateur et effectue un apprentissage supervisé dans des données simulées pour apprendre les trajectoires de mouvement instantanées des pièces d'objets communes telles que les meubles quotidiens (3D Articulated Flow). Le flux articulé 3D est une méthode de représentation visuelle de la trajectoire d'un nuage de points qui peut grandement simplifier la complexité de la prochaine stratégie du robot et améliorer la généralisation et l'efficacité. Il suffit au robot de suivre cette trajectoire instantanée et de re-prédire cette trajectoire en boucle fermée pour mener à bien la tâche de manipulation des objets communs.
Auparavant, la méthode conventionnelle de fonctionnement d'objets communs tels que des meubles dans le milieu universitaire consistait à calculer la direction du mouvement de la pièce à travers les caractéristiques géométriques de l'objet actionné (telles que la position et la direction des pièces connectées), ou en imiter des stratégies d'experts (généralement des humains) pour apprendre le fonctionnement d'objets spécifiques afin de réaliser des actions complexes de manipulation conjointe d'objets. Ces méthodes traditionnelles du monde universitaire ne se généralisent pas bien et sont moins efficaces dans l'utilisation des données. La formation nécessite la collecte de grandes quantités de données de démonstration humaine. Contrairement à ceux-ci, FlowBot 3D est le premier apprentissage purement basé sur simulateur qui ne nécessite pas que les humains fournissent des données de démonstration, et l'algorithme permet au robot de calculer le chemin optimal de manipulation d'objet en apprenant la trajectoire de mouvement instantanée de chaque pièce, de sorte que le l’algorithme a une grande généralisabilité. C'est cette fonctionnalité qui permet à FlowBot 3D de se généraliser à des objets invisibles lors de la formation sur simulateur, en manipulant avec succès des meubles réels du quotidien directement dans le monde réel.
Les animations suivantes démontrent le processus de manipulation de FlowBot 3D. À gauche se trouve la vidéo manipulée et à droite la trajectoire de mouvement instantanée prévue du nuage de points Articulated Flow 3D. L'algorithme FlowBot 3D permet d'abord au robot d'identifier quelle partie d'un objet peut être manipulée, puis de prédire la direction de mouvement de cette pièce.
Ouvrez la porte du réfrigérateur :


Ouvrez le couvercle des toilettes :

Ouvrez le tiroir :

Un critique de cet article a déclaré : Dans l’ensemble, cet article constitue une contribution considérable à contrôle robotique.

Alors, comment FlowBot 3D apprend-il cette compétence ?
Lorsque les humains voient un nouveau meuble, comme une porte, nous savons que la porte tourne selon un axe de porte, et nous savons que les contraintes de l'axe de la porte permettent à la porte de tourner dans un seul sens, donc. nous pouvons suivre la direction imaginée dans notre esprit pour ouvrir la porte. Par conséquent, si vous souhaitez qu'un robot soit vraiment adroit et efficace pour prédire les méthodes de manipulation et les trajectoires de mouvement d'objets communs tels que des meubles, un moyen efficace consiste à laisser le robot comprendre les contraintes cinématiques de ces pièces, afin qu'il puisse prédire le mouvement. déplacement de ces objets.
La méthode spécifique de FlowBot 3D n'est pas compliquée et repose uniquement sur des simulateurs sans données humaines réelles compliquées. De plus, un autre avantage du simulateur est que dans le simulateur, les fichiers de données 3D (URDF) de ces objets domestiques contiennent les contraintes cinématiques de chaque pièce et les paramètres spécifiques des contraintes, donc la trajectoire de mouvement de chaque pièce est dans le Le simulateur peut être calculé avec précision.
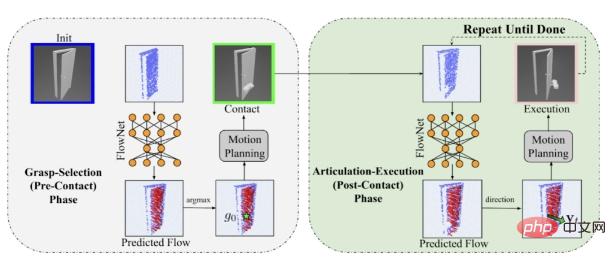

Deux modules pour FlowBot 3D.
Pendant la formation sur simulateur, le robot observe les données du nuage de points tridimensionnel de l'objet manipulé comme données d'entrée dans le module de vision du robot. Le module de vision (module de perception) utilise PointNet++ pour prédire la trajectoire du flux articulé 3D de chaque point du nuage de points d'entrée sous l'action d'une force externe (par exemple, après avoir ouvert le tiroir de 1 cm, la porte s'ouvre de 5 degrés vers l'extérieur), en utilisant le vecteur de coordonnées tridimensionnelles exprimé sous une forme médiocre. Les données réelles de cette trajectoire de mouvement peuvent être calculées avec précision grâce à la cinématique avant. En soustrayant la coordonnée vectorielle tridimensionnelle actuelle de la coordonnée vectorielle tridimensionnelle suivante, la trajectoire de mouvement de la partie d'objet manipulée peut être obtenue. Par conséquent, pendant la formation, seule la perte L2 du flux articulé 3D prévu doit être minimisée pour un apprentissage supervisé.

Dans cette image, les points bleus sont les données de nuage de points observées, et les flèches rouges représentent la trajectoire de mouvement prévue du flux articulé 3D de la façade.
En apprenant de cette manière, FlowBot 3D peut apprendre la direction du mouvement de chaque pièce sous des contraintes cinématiques ainsi que la vitesse relative et la direction relative (vitesse) de chaque point de la pièce se déplaçant sous la même force). Les articles ménagers courants sont prismatiques et révolutionnaires. Pour les pièces à contraction, telles que les tiroirs, la direction du mouvement et la vitesse de chaque point sur la surface du tiroir sont les mêmes lorsqu'ils reçoivent la même force externe. Pour les pièces rotatives, telles que les portes, la direction de mouvement de chaque point sur la surface de la porte est la même lorsqu'il reçoit la même force externe, mais la vitesse augmente à mesure que l'on s'éloigne de l'axe de rotation. Les chercheurs ont utilisé les lois physiques de la robotique (théorie des vis) pour prouver que le flux articulé 3D le plus long peut maximiser l'accélération de l'objet. Selon la deuxième loi de Newton, cette stratégie est la solution optimale.



Sur la base théorique, en fonctionnement réel, ce que le robot doit faire est de prédire la trajectoire de mouvement de chaque point grâce au module de vision de FlowBot 3D dans la trajectoire. de chaque point, trouvez le point correspondant à la direction d'écoulement articulée 3D la plus longue comme point de contrôle et prédisez la trajectoire de mouvement de ce point de contrôle en boucle fermée. Si le point de manipulation sélectionné ne peut pas être saisi avec succès (par exemple, la surface ne répond pas aux conditions de préhension de la main du robot), alors FlowBot 3D sélectionnera le point ayant la deuxième longueur la plus longue qui répond aux conditions de préhension.
De plus, grâce aux caractéristiques de PointNet++, FlowBot 3D prédit la trajectoire de mouvement de chaque point et ne s'appuie pas sur les caractéristiques géométriques de l'objet lui-même. Il est très robuste aux éventuelles occlusions d'objets par les robots. De plus, comme cet algorithme est en boucle fermée, le robot peut corriger ses éventuelles erreurs lors de l’étape suivante de prédiction.
Performances de FlowBot 3D dans le monde réelFlowBot 3D a la capacité de surmonter les défis de généralisation dans le monde réel. Le concept de conception de FlowBot 3D est que tant qu'il peut prédire avec précision la trajectoire de mouvement du flux articulé 3D de l'objet manipulé, l'étape suivante consiste à suivre cette trajectoire pour terminer la tâche.
Un autre point important est que FlowBot 3D utilise un seul modèle d'entraînement pour manipuler plusieurs catégories d'éléments, y compris des catégories qui n'ont pas été vues lors de l'entraînement. Et dans le monde réel, le robot n’a besoin que d’utiliser le modèle obtenu grâce à cette pure formation sur simulateur pour manipuler une variété d’objets réels. Ainsi, dans le monde réel, puisque les contraintes cinématiques des objets domestiques sont très largement les mêmes que dans le simulateur, FlowBot 3D peut être directement généralisé au monde réel.

Articles ménagers utilisés par FlowBot3D dans des expériences réelles (y compris les poubelles, les réfrigérateurs, les sièges de toilettes, les boîtes, les coffres-forts, etc.)
Dans le simulateur, le robot utilise certaines catégories d'articles ménagers pour la formation, y compris les agrafeuses, les poubelles, les tiroirs, les fenêtres, les réfrigérateurs, etc. Dans le simulateur et les tests réels, les données de test proviennent de nouveaux objets de la catégorie de formation et des catégories qui n'ont pas été vues pendant la formation
. 




En comparaison, dans le monde universitaire, les méthodes courantes basées sur l'apprentissage par imitation nécessitent. un guidage manuel pour apprendre à manipuler de nouveaux objets, ce qui rend irréaliste la mise en œuvre de ces robots dans le monde réel, en particulier dans les scénarios de robots domestiques. De plus, les données de nuages de points 3D sont plus puissantes que celles utilisées par d'autres méthodes. car le nuage de points peut permettre au robot de comprendre chaque articulation et la relation entre les articulations, étant ainsi capable de comprendre et de prédire la trajectoire de mouvement de la pièce à un niveau supérieur, améliorant considérablement la généralisation .
Les résultats expérimentaux montrent que FlowBot 3D peut atteindre une distance « complètement ouverte » de moins de 10 % et une portée réussie de plus de 90 % lors de l'utilisation de la plupart des objets (qu'il s'agisse de catégories vues ou non vues pendant l'entraînement). En comparaison, d’autres méthodes basées sur l’apprentissage par imitation (DAgger) ou l’apprentissage par renforcement (SAC) sont loin derrière et manquent de généralisation.

En bref, FlowBot 3D est un travail à fort potentiel. Il peut être déployé efficacement dans le monde réel sans nécessiter de réglage fin. Ce travail montre également que les progrès de la vision par ordinateur peuvent changer le domaine de la robotique, en particulier l'expression visuelle des trajectoires de mouvement appelée flux articulé 3D, qui peut être appliquée à plusieurs tâches pour simplifier la sélection de la stratégie du robot et le processus de prise de décision. Avec cette expression généralisable, les méthodes d’apprentissage sur simulateur auront le potentiel d’être directement déployées dans le monde réel, ce qui réduira considérablement le coût de la formation et de l’apprentissage futurs des robots domestiques.
Prochain plan de FlowBot 3DActuellement, l'équipe de recherche tente d'appliquer la méthode de compréhension et de prédiction du flux à des objets autres que les objets communs, par exemple comment utiliser le flux pour prédire la trajectoire d'un objet avec 6 degrés de liberté . Dans le même temps, l'auteur tente d'utiliser le flux comme expression visuelle générale pour l'appliquer à d'autres tâches d'apprentissage des robots, telles que l'apprentissage par renforcement, augmentant ainsi l'efficacité, la robustesse et la généralisabilité de l'apprentissage.
Page d'accueil du professeur agrégé David Held : https://davheld.github.io/Page d'accueil de Ben Eisner : https://beisner.me/Page d'accueil de Harry Zhang : https://harryzhangog.github.io/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Comment l'IA peut-elle rendre les robots plus autonomes et adaptables ?
Jun 03, 2024 pm 07:18 PM
Comment l'IA peut-elle rendre les robots plus autonomes et adaptables ?
Jun 03, 2024 pm 07:18 PM
Dans le domaine de la technologie de l’automatisation industrielle, il existe deux points chauds récents qu’il est difficile d’ignorer : l’intelligence artificielle (IA) et Nvidia. Ne changez pas le sens du contenu original, affinez le contenu, réécrivez le contenu, ne continuez pas : « Non seulement cela, les deux sont étroitement liés, car Nvidia ne se limite pas à son unité de traitement graphique d'origine (GPU ), il étend son GPU. La technologie s'étend au domaine des jumeaux numériques et est étroitement liée aux technologies émergentes d'IA "Récemment, NVIDIA a conclu une coopération avec de nombreuses entreprises industrielles, notamment des sociétés d'automatisation industrielle de premier plan telles qu'Aveva, Rockwell Automation, Siemens. et Schneider Electric, ainsi que Teradyne Robotics et ses sociétés MiR et Universal Robots. Récemment, Nvidiahascoll
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Afin d'aligner les grands modèles de langage (LLM) sur les valeurs et les intentions humaines, il est essentiel d'apprendre les commentaires humains pour garantir qu'ils sont utiles, honnêtes et inoffensifs. En termes d'alignement du LLM, une méthode efficace est l'apprentissage par renforcement basé sur le retour humain (RLHF). Bien que les résultats de la méthode RLHF soient excellents, certains défis d’optimisation sont impliqués. Cela implique de former un modèle de récompense, puis d'optimiser un modèle politique pour maximiser cette récompense. Récemment, certains chercheurs ont exploré des algorithmes hors ligne plus simples, dont l’optimisation directe des préférences (DPO). DPO apprend le modèle politique directement sur la base des données de préférence en paramétrant la fonction de récompense dans RLHF, éliminant ainsi le besoin d'un modèle de récompense explicite. Cette méthode est simple et stable
 Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
À la pointe de la technologie logicielle, le groupe de l'UIUC Zhang Lingming, en collaboration avec des chercheurs de l'organisation BigCode, a récemment annoncé le modèle de grand code StarCoder2-15B-Instruct. Cette réalisation innovante a permis une percée significative dans les tâches de génération de code, dépassant avec succès CodeLlama-70B-Instruct et atteignant le sommet de la liste des performances de génération de code. Le caractère unique de StarCoder2-15B-Instruct réside dans sa stratégie d'auto-alignement pur. L'ensemble du processus de formation est ouvert, transparent et complètement autonome et contrôlable. Le modèle génère des milliers d'instructions via StarCoder2-15B en réponse au réglage fin du modèle de base StarCoder-15B sans recourir à des annotations manuelles coûteuses.
 Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
01Aperçu des perspectives Actuellement, il est difficile d'atteindre un équilibre approprié entre efficacité de détection et résultats de détection. Nous avons développé un algorithme YOLOv5 amélioré pour la détection de cibles dans des images de télédétection optique haute résolution, en utilisant des pyramides de caractéristiques multicouches, des stratégies de têtes de détection multiples et des modules d'attention hybrides pour améliorer l'effet du réseau de détection de cibles dans les images de télédétection optique. Selon l'ensemble de données SIMD, le mAP du nouvel algorithme est 2,2 % meilleur que YOLOv5 et 8,48 % meilleur que YOLOX, permettant ainsi d'obtenir un meilleur équilibre entre les résultats de détection et la vitesse. 02 Contexte et motivation Avec le développement rapide de la technologie de télédétection, les images de télédétection optique à haute résolution ont été utilisées pour décrire de nombreux objets à la surface de la Terre, notamment des avions, des voitures, des bâtiments, etc. Détection d'objets dans l'interprétation d'images de télédétection
