
 développement back-end
Tutoriel Python
Python dessine de superbes diagrammes de Sankey, l'avez-vous appris ?
développement back-end
Tutoriel Python
Python dessine de superbes diagrammes de Sankey, l'avez-vous appris ?
Python dessine de superbes diagrammes de Sankey, l'avez-vous appris ?

Introduction aux diagrammes Sankey
Souvent, nous avons besoin d'une situation dans laquelle nous devons visualiser la façon dont les données circulent entre les entités. Par exemple, prenons la façon dont les résidents se déplacent d’un pays à un autre. Voici une démonstration du nombre de résidents qui ont quitté l'Angleterre pour l'Irlande du Nord, l'Écosse et le Pays de Galles.
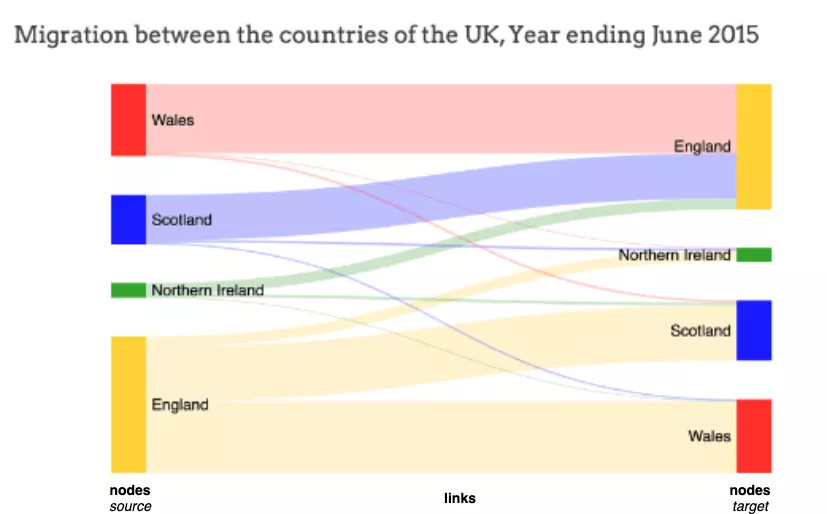
Il ressort clairement de cette visualisation de Sankey que plus de résidents ont déménagé d'Angleterre vers le Pays de Galles que d'Écosse ou d'Irlande du Nord.
Qu'est-ce qu'un diagramme Sankey ?
Les diagrammes Sankey décrivent généralement le flux de données d'une entité (ou d'un nœud) vers une autre entité (ou nœud).
Les entités vers lesquelles les données circulent sont appelées nœuds. Le nœud d'où provient le flux de données est le nœud source (comme l'Angleterre à gauche) et le nœud où le flux se termine est le nœud cible (comme le Pays de Galles à droite). ). Les nœuds source et cible sont généralement représentés sous forme de rectangles étiquetés.
Le flux lui-même est représenté par des chemins droits ou courbes, appelés liens. La largeur d'un flux/lien est directement proportionnelle au volume/nombre de flux. Dans l'exemple ci-dessus, le mouvement de l'Angleterre vers le Pays de Galles (c'est-à-dire la migration des résidents) est plus étendu (c'est-à-dire la migration des résidents) que le mouvement de l'Angleterre vers l'Écosse ou l'Irlande du Nord (c'est-à-dire la migration des résidents), ce qui indique que plus de résidents déménager au Pays de Galles plutôt que dans d'autres pays.
Les diagrammes Sankey peuvent être utilisés pour représenter le flux d'énergie, d'argent, de coûts et tout ce qui a un concept de flux.
La carte classique de Minard de l’invasion de la Russie par Napoléon est probablement l’exemple le plus célèbre de carte Sankey. Cette visualisation utilisant un diagramme de Sankey montre très efficacement comment l'armée française a progressé (ou diminué ?) sur son chemin vers la Russie et retour.

Dans cet article, nous utilisons le tracé de Python pour dessiner un diagramme de Sankey.
Comment dessiner un diagramme de Sankey ?
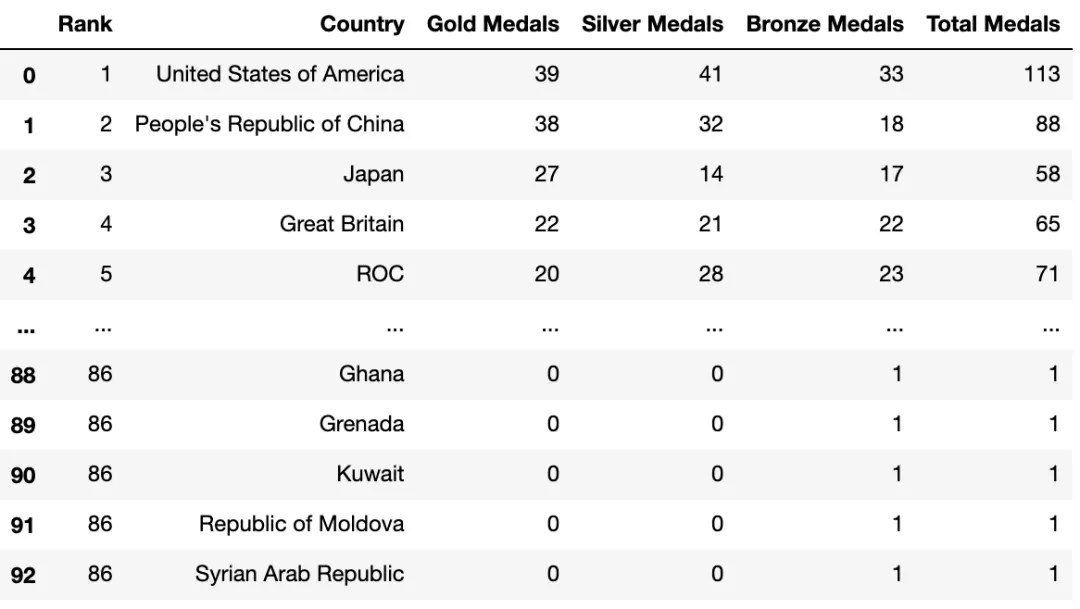
Cet article utilise l'ensemble de données des Jeux Olympiques de 2021 pour dessiner un diagramme de Sankey. L'ensemble de données contient des informations détaillées sur le nombre total de médailles : pays, nombre total de médailles et totaux individuels pour les médailles d'or, d'argent et de bronze. Nous traçons un tableau Sankey pour découvrir combien de médailles d'or, d'argent et de bronze un pays a remporté.
df_medals = pd.read_excel("data/Medals.xlsx")
print(df_medals.info())
df_medals.rename(columns={'Team/NOC':'Country', 'Total': 'Total Medals', 'Gold':'Gold Medals', 'Silver': 'Silver Medals', 'Bronze': 'Bronze Medals'}, inplace=True)
df_medals.drop(columns=['Unnamed: 7','Unnamed: 8','Rank by Total'], inplace=True)
df_medals<class 'pandas.core.frame.DataFrame'> RangeIndex: 93 entries, 0 to 92 Data columns (total 9 columns): # Column Non-Null CountDtype --------- ------------------- 0 Rank 93 non-null int64 1 Team/NOC 93 non-null object 2 Gold 93 non-null int64 3 Silver 93 non-null int64 4 Bronze 93 non-null int64 5 Total93 non-null int64 6 Rank by Total93 non-null int64 7 Unnamed: 7 0 non-nullfloat64 8 Unnamed: 8 1 non-nullfloat64 dtypes: float64(2), int64(6), object(1) memory usage: 6.7+ KB None
Bases du dessin du diagramme de Sankey
Utilisez plotly's go.Sankey Cette méthode prend 2 paramètres - nœuds et liens (nœuds et liens).
Remarque : Tous les nœuds - source et destination doivent avoir des identifiants uniques.
Dans le cas de l'ensemble de données sur les médailles olympiques de cet article :
La source est le pays. Considérez les 3 premiers pays (États-Unis, Chine et Japon) comme nœuds sources. Étiquetez ces nœuds sources avec les identifiants, étiquettes et couleurs (uniques) suivants :
- 0 : États-Unis : vert
- 1 : Chine : bleu
- 2 : Japon : orange
La cible est l'or, l'argent ou médaille de bronze. Étiquetez ces nœuds cibles avec les identifiants, étiquettes et couleurs (uniques) suivants :
- 3 : Or : Or
- 4 : Argent : Argent
- 5 : Bronze : Marron
Lien (nœud source et nœud cible) est le nombre de médailles de chaque type. Dans chaque source, il y a 3 liens, chacun se terminant par une cible : Or, Argent et Bronze. Il y a donc 9 liens au total. La largeur de chaque maillon doit correspondre au nombre de médailles d'or, d'argent et de bronze. Étiquetez ces liens vers des cibles, des valeurs et des couleurs avec les sources suivantes :
- 0 (US) à 3,4,5 : 39, 41, 33
- 1 (Chine) à 3,4,5 : 38, 32, 18
- 2 (Japon) à 3,4,5 : 27, 14, 17
Nécessite l'instanciation de 2 objets dict python pour représenter les
- nœuds (source et destination) : étiquettes et couleurs sous forme de listes séparées et
- liens : nœud source, nœud cible, valeur (largeur) et couleur du lien sous forme de listes séparées
et transmettez-le à plotly's go.Sankey.
Chaque index de la liste (libellé, source, cible, valeur et couleur) correspond à un nœud ou un lien.
NODES = dict( # 0 1 23 4 5 label = ["United States of America", "People's Republic of China", "Japan", "Gold", "Silver", "Bronze"], color = ["seagreen", "dodgerblue", "orange", "gold", "silver", "brown" ],) LINKS = dict( source = [0,0,0,1,1,1,2,2,2], # 链接的起点或源节点 target = [3,4,5,3,4,5,3,4,5], # 链接的目的地或目标节点 value =[ 39, 41, 33, 38, 32, 18, 27, 14, 17], # 链接的宽度(数量) # 链接的颜色 # 目标节点: 3-Gold4-Silver5-Bronze color = [ "lightgreen", "lightgreen", "lightgreen",# 源节点:0 - 美国 States of America "lightskyblue", "lightskyblue", "lightskyblue",# 源节点:1 - 中华人民共和国China "bisque", "bisque", "bisque"],)# 源节点:2 - 日本 data = go.Sankey(node = NODES, link = LINKS) fig = go.Figure(data) fig.show()

Il s'agit d'un diagramme de Sankey très basique. Mais avez-vous déjà remarqué que le graphique est trop large et que les médailles d'argent apparaissent avant les médailles d'or
Voici comment ajuster la position et la largeur des nœuds ?
Ajustez les positions des nœuds et la largeur du graphique
Ajoutez les positions x et y pour les nœuds afin de spécifier explicitement la position du nœud. La valeur doit être comprise entre 0 et 1.
NODES = dict( # 0 1 23 4 5 label = ["United States of America", "People's Republic of China", "Japan", "Gold", "Silver", "Bronze"], color = ["seagreen", "dodgerblue", "orange", "gold", "silver", "brown" ],) x = [ 0,0,0,0.5,0.5,0.5], y = [ 0,0.5,1,0.1,0.5,1],) data = go.Sankey(node = NODES, link = LINKS) fig = go.Figure(data) fig.update_layout(title="Olympics - 2021: Country &Medals",font_size=16) fig.show()
Nous avons donc obtenu un diagramme de Sankey compact :
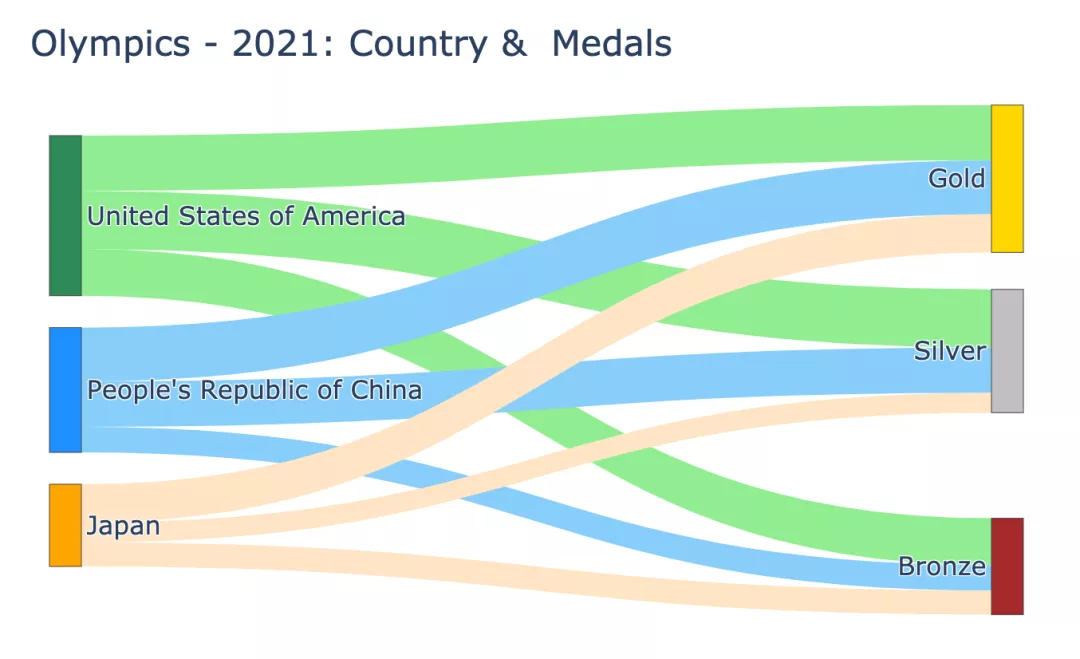
Jetons un coup d'œil à la manière dont les différents paramètres transmis dans le code sont mappés aux nœuds et aux liens du graphique.
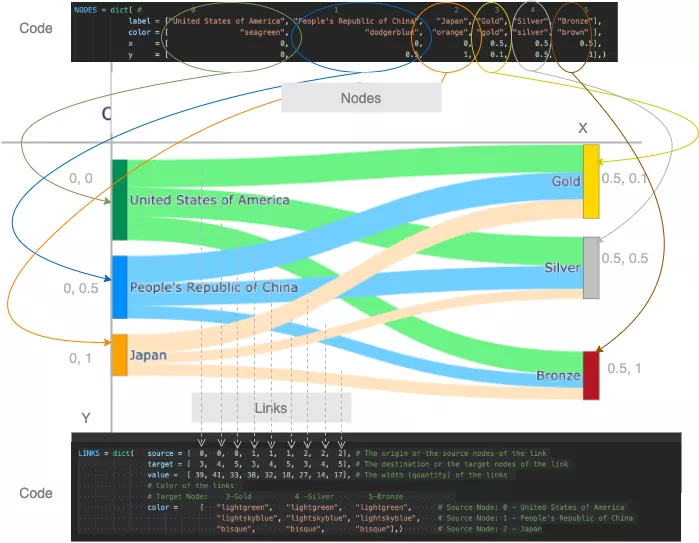
代码如何映射到桑基图
添加有意义的悬停标签
我们都知道plotly绘图是交互的,我们可以将鼠标悬停在节点和链接上以获取更多信息。
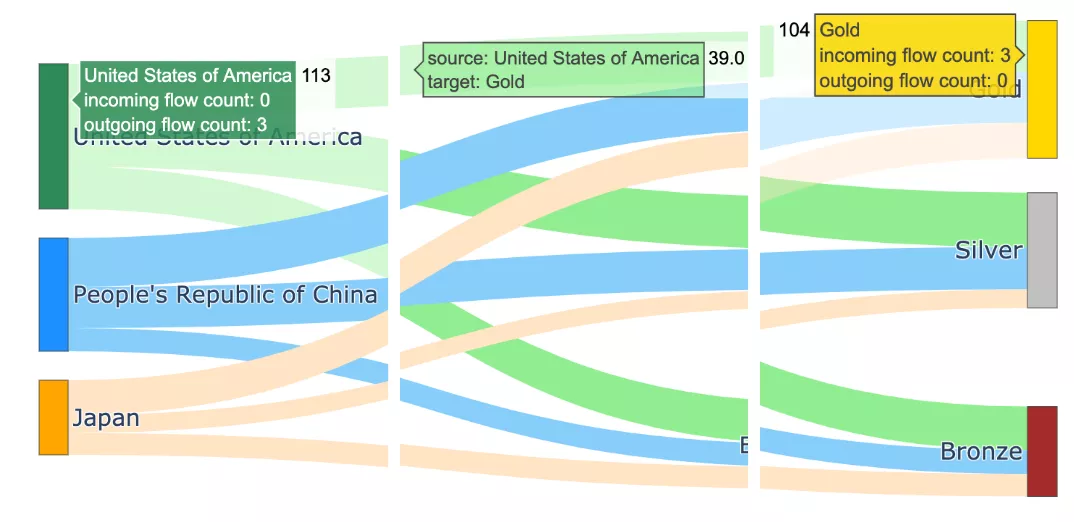
带有默认悬停标签的桑基图
当将鼠标悬停在图上,将会显示详细信息。悬停标签中显示的信息是默认文本:节点、节点名称、传入流数、传出流数和总值。
例如:
- 节点美国共获得11枚奖牌(=39金+41银+33铜)
- 节点金牌共有104枚奖牌(=美国39枚,中国38枚,日本27枚)
如果我们觉得这些标签太冗长了,我们可以对此进程改进。使用hovertemplate参数改进悬停标签的格式
- 对于节点,由于hoverlabels 没有提供新信息,通过传递一个空hovertemplate = ""来去掉hoverlabel
- 对于链接,可以使标签简洁,格式为-
- 对于节点和链接,让我们使用后缀"Medals"显示值。例如 113 枚奖牌而不是 113 枚。这可以通过使用具有适当valueformat和valuesuffix的update_traces函数来实现。
NODES = dict(
# 0 1 23 4 5
label = ["United States of America", "People's Republic of China", "Japan", "Gold", "Silver", "Bronze"],
color = ["seagreen", "dodgerblue","orange", "gold", "silver", "brown" ],
x = [ 0,0, 0,0.5,0.5,0.5],
y = [ 0,0.5, 1,0.1,0.5,1],
hovertemplate=" ",)
LINK_LABELS = []
for country in ["USA","China","Japan"]:
for medal in ["Gold","Silver","Bronze"]:
LINK_LABELS.append(f"{country}-{medal}")
LINKS = dict(source = [0,0,0,1,1,1,2,2,2],
# 链接的起点或源节点
target = [3,4,5,3,4,5,3,4,5],
# 链接的目的地或目标节点
value =[ 39, 41, 33, 38, 32, 18, 27, 14, 17],
# 链接的宽度(数量)
# 链接的颜色
# 目标节点:3-Gold4 -Silver5-Bronze
color = ["lightgreen", "lightgreen", "lightgreen", # 源节点:0 - 美国
"lightskyblue", "lightskyblue", "lightskyblue", # 源节点:1 - 中国
"bisque", "bisque", "bisque"],# 源节点:2 - 日本
label = LINK_LABELS,
hovertemplate="%{label}",)
data = go.Sankey(node = NODES, link = LINKS)
fig = go.Figure(data)
fig.update_layout(title="Olympics - 2021: Country &Medals",
font_size=16, width=1200, height=500,)
fig.update_traces(valueformat='3d',
valuesuffix='Medals',
selector=dict(type='sankey'))
fig.update_layout(hoverlabel=dict(bgcolor="lightgray",
font_size=16,
font_family="Rockwell"))
fig.show("png") #fig.show()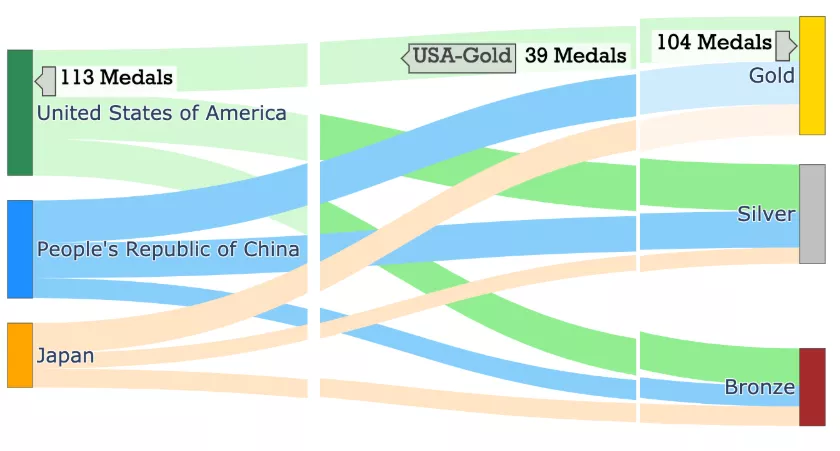
带有改进的悬停标签的桑基图
对多个节点和级别进行泛化相对于链接,节点被称为源和目标。作为一个链接目标的节点可以是另一个链接的源。
该代码可以推广到处理数据集中的所有国家。
还可以将图表扩展到另一个层次,以可视化各国的奖牌总数。
NUM_COUNTRIES = 5
X_POS, Y_POS = 0.5, 1/(NUM_COUNTRIES-1)
NODE_COLORS = ["seagreen", "dodgerblue", "orange", "palevioletred", "darkcyan"]
LINK_COLORS = ["lightgreen", "lightskyblue", "bisque", "pink", "lightcyan"]
source = []
node_x_pos, node_y_pos = [], []
node_labels, node_colors = [], NODE_COLORS[0:NUM_COUNTRIES]
link_labels, link_colors, link_values = [], [], []
# 第一组链接和节点
for i in range(NUM_COUNTRIES):
source.extend([i]*3)
node_x_pos.append(0.01)
node_y_pos.append(round(i*Y_POS+0.01,2))
country = df_medals['Country'][i]
node_labels.append(country)
for medal in ["Gold", "Silver", "Bronze"]:
link_labels.append(f"{country}-{medal}")
link_values.append(df_medals[f"{medal} Medals"][i])
link_colors.extend([LINK_COLORS[i]]*3)
source_last = max(source)+1
target = [ source_last, source_last+1, source_last+2] * NUM_COUNTRIES
target_last = max(target)+1
node_labels.extend(["Gold", "Silver", "Bronze"])
node_colors.extend(["gold", "silver", "brown"])
node_x_pos.extend([X_POS, X_POS, X_POS])
node_y_pos.extend([0.01, 0.5, 1])
# 最后一组链接和节点
source.extend([ source_last, source_last+1, source_last+2])
target.extend([target_last]*3)
node_labels.extend(["Total Medals"])
node_colors.extend(["grey"])
node_x_pos.extend([X_POS+0.25])
node_y_pos.extend([0.5])
for medal in ["Gold","Silver","Bronze"]:
link_labels.append(f"{medal}")
link_values.append(df_medals[f"{medal} Medals"][:i+1].sum())
link_colors.extend(["gold", "silver", "brown"])
print("node_labels", node_labels)
print("node_x_pos", node_x_pos); print("node_y_pos", node_y_pos)node_labels ['United States of America', "People's Republic of China", 'Japan', 'Great Britain', 'ROC', 'Gold', 'Silver', 'Bronze', 'Total Medals'] node_x_pos [0.01, 0.01, 0.01, 0.01, 0.01, 0.5, 0.5, 0.5, 0.75] node_y_pos [0.01, 0.26, 0.51, 0.76, 1.01, 0.01, 0.5, 1, 0.5]
# 显示的图
NODES = dict(pad= 20, thickness = 20,
line = dict(color = "lightslategrey",
width = 0.5),
hovertemplate=" ",
label = node_labels,
color = node_colors,
x = node_x_pos,
y = node_y_pos, )
LINKS = dict(source = source,
target = target,
value = link_values,
label = link_labels,
color = link_colors,
hovertemplate="%{label}",)
data = go.Sankey(arrangement='snap',
node = NODES,
link = LINKS)
fig = go.Figure(data)
fig.update_traces(valueformat='3d',
valuesuffix=' Medals',
selector=dict(type='sankey'))
fig.update_layout(title="Olympics - 2021: Country &Medals",
font_size=16,
width=1200,
height=500,)
fig.update_layout(hoverlabel=dict(bgcolor="grey",
font_size=14,
font_family="Rockwell"))
fig.show("png") 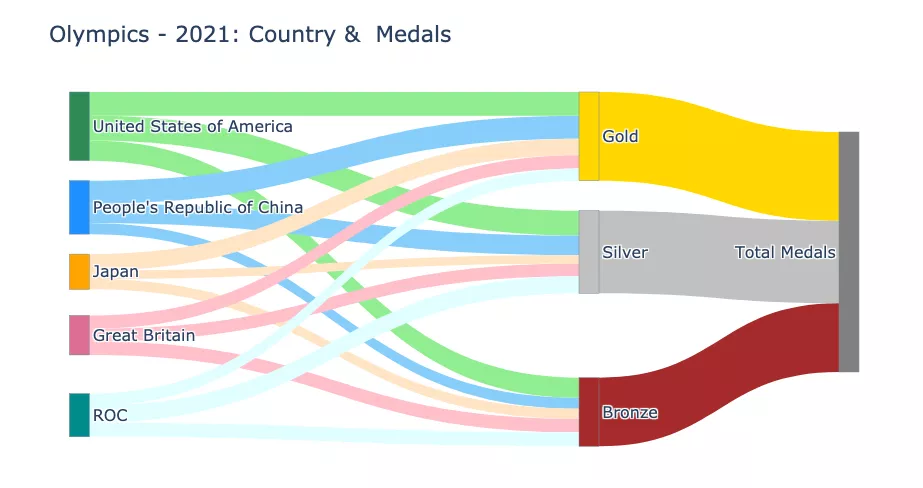
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le plan Python de 2 heures: une approche réaliste
Apr 11, 2025 am 12:04 AM
Le plan Python de 2 heures: une approche réaliste
Apr 11, 2025 am 12:04 AM
Vous pouvez apprendre les concepts de programmation de base et les compétences de Python dans les 2 heures. 1. Apprenez les variables et les types de données, 2. Flux de contrôle maître (instructions et boucles conditionnelles), 3. Comprenez la définition et l'utilisation des fonctions, 4. Démarrez rapidement avec la programmation Python via des exemples simples et des extraits de code.
 Python: Explorer ses applications principales
Apr 10, 2025 am 09:41 AM
Python: Explorer ses applications principales
Apr 10, 2025 am 09:41 AM
Python est largement utilisé dans les domaines du développement Web, de la science des données, de l'apprentissage automatique, de l'automatisation et des scripts. 1) Dans le développement Web, les cadres Django et Flask simplifient le processus de développement. 2) Dans les domaines de la science des données et de l'apprentissage automatique, les bibliothèques Numpy, Pandas, Scikit-Learn et Tensorflow fournissent un fort soutien. 3) En termes d'automatisation et de script, Python convient aux tâches telles que les tests automatisés et la gestion du système.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
En tant que professionnel des données, vous devez traiter de grandes quantités de données provenant de diverses sources. Cela peut poser des défis à la gestion et à l'analyse des données. Heureusement, deux services AWS peuvent aider: AWS Glue et Amazon Athena.
 Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Les étapes pour démarrer un serveur Redis incluent: Installez Redis en fonction du système d'exploitation. Démarrez le service Redis via Redis-Server (Linux / MacOS) ou Redis-Server.exe (Windows). Utilisez la commande redis-Cli Ping (Linux / MacOS) ou redis-Cli.exe Ping (Windows) pour vérifier l'état du service. Utilisez un client redis, tel que redis-cli, python ou node.js pour accéder au serveur.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment afficher la version serveur de redis
Apr 10, 2025 pm 01:27 PM
Comment afficher la version serveur de redis
Apr 10, 2025 pm 01:27 PM
Question: Comment afficher la version Redis Server? Utilisez l'outil de ligne de commande redis-Cli --version pour afficher la version du serveur connecté. Utilisez la commande Info Server pour afficher la version interne du serveur et devez analyser et retourner des informations. Dans un environnement de cluster, vérifiez la cohérence de la version de chaque nœud et peut être vérifiée automatiquement à l'aide de scripts. Utilisez des scripts pour automatiser les versions de visualisation, telles que la connexion avec les scripts Python et les informations d'impression.
 Dans quelle mesure le mot de passe de Navicat est-il sécurisé?
Apr 08, 2025 pm 09:24 PM
Dans quelle mesure le mot de passe de Navicat est-il sécurisé?
Apr 08, 2025 pm 09:24 PM
La sécurité du mot de passe de Navicat repose sur la combinaison de cryptage symétrique, de force de mot de passe et de mesures de sécurité. Des mesures spécifiques incluent: l'utilisation de connexions SSL (à condition que le serveur de base de données prenne en charge et configure correctement le certificat), à la mise à jour régulièrement de NAVICAT, en utilisant des méthodes plus sécurisées (telles que les tunnels SSH), en restreignant les droits d'accès et, surtout, à ne jamais enregistrer de mots de passe.
