
 développement back-end
Tutoriel Python
30 packages Python essentiels pour l'ingénierie des données
développement back-end
Tutoriel Python
30 packages Python essentiels pour l'ingénierie des données
30 packages Python essentiels pour l'ingénierie des données

Python peut être considéré comme le langage de programmation le plus simple avec lequel démarrer. Avec l'aide de packages de base tels que numpy et scipy, Python peut être considéré comme le meilleur langage actuellement pour le traitement des données et l'apprentissage automatique. Merci à tous les experts. et des contributeurs enthousiastes. Avec l'aide de Python, qui dispose d'une large communauté soutenant le développement de la technologie, deux packages Python différents ont été développés pour aider les data scientists dans leur travail.

Dans cet article, nous présenterons des packages Python très uniques et utiles qui peuvent vous aider à créer des flux de travail de données de plusieurs manières.
1. Knockknock
Knockknock est un simple package Python qui vous avertit lorsqu'une formation de modèle d'apprentissage automatique se termine ou plante. Nous pouvons recevoir des notifications via plusieurs canaux, tels que le courrier électronique, Slack, Microsoft Teams, etc.
Pour installer le package, nous utilisons le code suivant.
pip install knockknock
Par exemple, nous pouvons utiliser le code suivant pour notifier l'état de la formation à la modélisation d'apprentissage automatique à une adresse e-mail spécifiée.
from knockknock import email_senderfrom sklearn.linear_model import LinearRegressionimport numpy as np@email_sender(recipient_emails=["<your_email@address.com>", "<your_second_email@address.com>"], sender_email="<sender_email@gmail.com>")def train_linear_model(your_nicest_parameters):x = np.array([[1, 1], [1, 2], [2, 2], [2, 3]])y = np.dot(x, np.array([1, 2])) + 3 regression = LinearRegression().fit(x, y)return regression.score(x, y)
De cette façon, vous pouvez être averti lorsque quelque chose ne va pas ou lorsque la fonction est terminée.
2. tqdm
Lorsque vous avez besoin d'itérer ou de boucler, si vous avez besoin d'afficher une barre de progression, alors tqdm est ce dont vous avez besoin. Ce package fournira un simple indicateur de progression dans votre bloc-notes ou votre invite de commande.
Commençons par installer le package.
pip install tqdm
Vous pouvez ensuite utiliser le code suivant pour afficher une barre de progression pendant la boucle.
from tqdm import tqdmq = 0for i in tqdm(range(10000000)):q = i +1
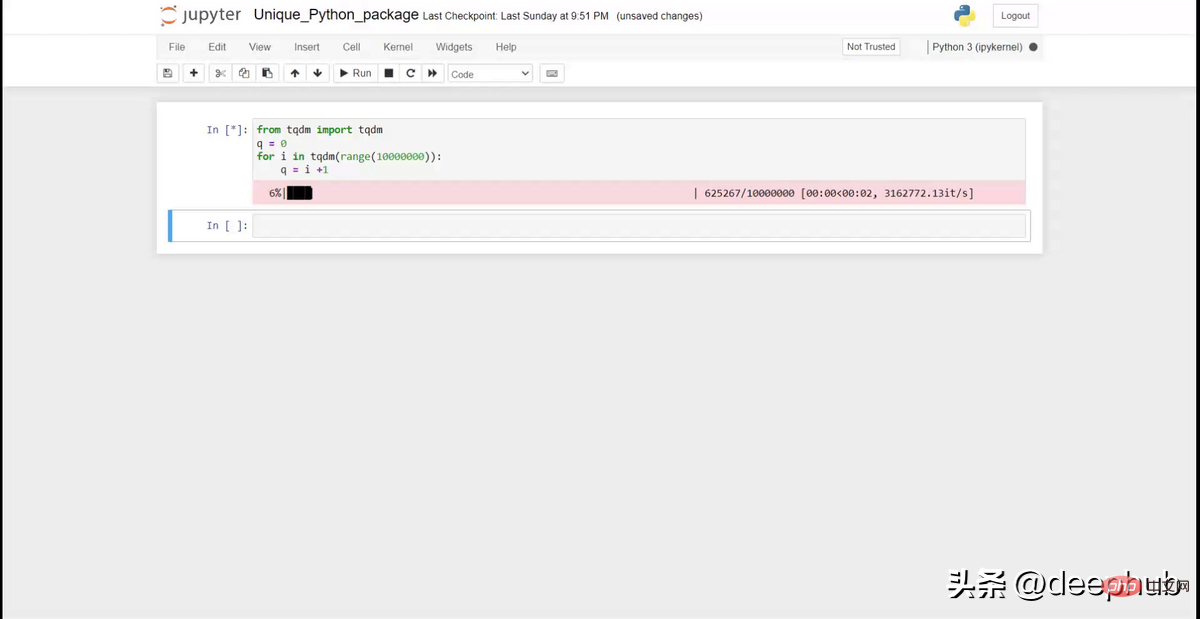
Comme le gifg ci-dessus, il permet d'afficher une jolie barre de progression sur le carnet. C'est utile lorsque vous avez une itération complexe et que vous souhaitez suivre la progression.
3. Pandas-log
Panda -log peut fournir des commentaires sur les opérations de base de Panda, telles que .query, .drop, .merge, etc. Il est basé sur R's Tidyverse et peut être utilisé pour comprendre toutes les étapes d'analyse des données.
Installez le package
pip install pandas-log
Après avoir installé le package, jetez un œil à l'exemple ci-dessous.
import pandas as pdimport numpy as npimport pandas_logdf = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],"toy": [np.nan, 'Batmobile', 'Bullwhip'],"born": [pd.NaT, pd.Timestamp("1940-04-25"), pd.NaT]})Essayons ensuite d'utiliser le code suivant pour créer un simple enregistrement d'opération de pandas.
with pandas_log.enable():res = (df.drop("born", axis = 1).groupby('name'))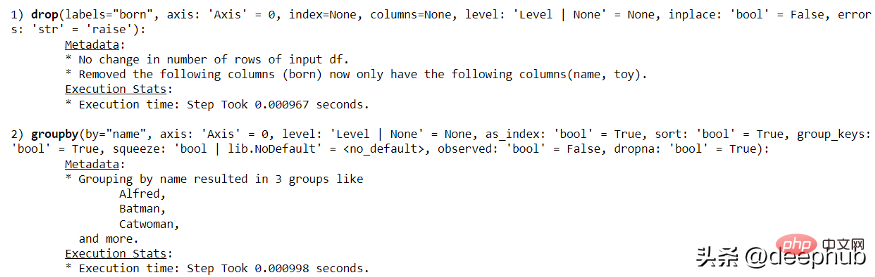
Grâce à pandas-log, nous pouvons obtenir toutes les informations d'exécution.
4. Emoji
Comme son nom l'indique, Emoji est un package Python qui prend en charge l'analyse du texte emoji. Habituellement, il nous est difficile de gérer les emojis en Python, mais le package Emoji peut nous aider dans la conversion.
Utilisez le code suivant pour installer le package Emoji.
pip install emoji
Regardez le code ci-dessous :
import emojiprint(emoji.emojize('Python is :thumbs_up:'))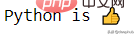
Avec ce package, vous pouvez facilement générer des émoticônes.
5. TheFuzz
TheFuzz utilise la distance de Levenshtein pour faire correspondre le texte afin de calculer la similarité.
pip install thefuzz
Le code suivant décrit comment utiliser TheFuzz pour la correspondance de texte de similarité.
from thefuzz import fuzz, process#Testing the score between two sentencesfuzz.ratio("Test the word", "test the Word!")
TheFuzz peut également extraire les scores de similarité de plusieurs mots simultanément.
choices = ["Atlanta Falcons", "New York Jets", "New York Giants", "Dallas Cowboys"]process.extract("new york jets", choices, limit=2)
TheFuzz convient à toute détection de similarité de données textuelles, ce travail est très important en PNL.
6. Numerizer
Numerizer peut convertir le texte numérique écrit en nombre entier ou à virgule flottante correspondant.
pip install numerizer
Essayons ensuite quelques entrées à convertir.
from numerizer import numerizenumerize('forty two')
Si vous utilisez un autre style d'écriture, cela fonctionnera aussi.
numerize('forty-two')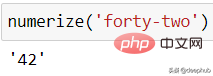
numerize('nine and three quarters')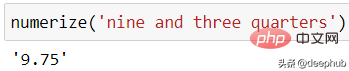
Si la saisie n'est pas une expression numérique, alors elle sera conservée :
numerize('maybe around nine and three quarters')
7、PyAutoGUI
PyAutoGUI 可以自动控制鼠标和键盘。
pip install pyautogui
然后我们可以使用以下代码测试。
import pyautoguipyautogui.moveTo(10, 15)pyautogui.click()pyautogui.doubleClick()pyautogui.press('enter')上面的代码会将鼠标移动到某个位置并单击鼠标。 当需要重复操作(例如下载文件或收集数据)时,非常有用。
8、Weightedcalcs
Weightedcalcs 用于统计计算。 用法从简单的统计数据(例如加权平均值、中位数和标准变化)到加权计数和分布等。
pip install weightedcalcs
使用可用数据计算加权分布。
import seaborn as snsdf = sns.load_dataset('mpg')import weightedcalcs as wccalc = wc.Calculator("mpg")然后我们通过传递数据集并计算预期变量来进行加权计算。
calc.distribution(df, "origin")

9、scikit-posthocs
scikit-posthocs 是一个用于“事后”测试分析的 python 包,通常用于统计分析中的成对比较。 该软件包提供了简单的类似 scikit-learn API 来进行分析。
pip install scikit-posthocs
然后让我们从简单的数据集开始,进行 ANOVA 测试。
import statsmodels.api as saimport statsmodels.formula.api as sfaimport scikit_posthocs as spdf = sa.datasets.get_rdataset('iris').datadf.columns = df.columns.str.replace('.', '')lm = sfa.ols('SepalWidth ~ C(Species)', data=df).fit()anova = sa.stats.anova_lm(lm)print(anova)
获得了 ANOVA 测试结果,但不确定哪个变量类对结果的影响最大,可以使用以下代码进行原因的查看。
sp.posthoc_ttest(df, val_col='SepalWidth', group_col='Species', p_adjust='holm')

使用 scikit-posthoc,我们简化了事后测试的成对分析过程并获得了 P 值
10、Cerberus
Cerberus 是一个用于数据验证的轻量级 python 包。
pip install cerberus
Cerberus 的基本用法是验证类的结构。
from cerberus import Validatorschema = {'name': {'type': 'string'}, 'gender':{'type': 'string'}, 'age':{'type':'integer'}}v = Validator(schema)定义好需要验证的结构后,可以对实例进行验证。
document = {'name': 'john doe', 'gender':'male', 'age': 15}v.validate(document)
如果匹配,则 Validator 类将输出True 。 这样我们可以确保数据结构是正确的。
11、ppscore
ppscore 用于计算与目标变量相关的变量的预测能力。 该包计算可以检测两个变量之间的线性或非线性关系的分数。 分数范围从 0(无预测能力)到 1(完美预测能力)。
pip install ppscore
使用 ppscore 包根据目标计算分数。
import seaborn as snsimport ppscore as ppsdf = sns.load_dataset('mpg')pps.predictors(df, 'mpg')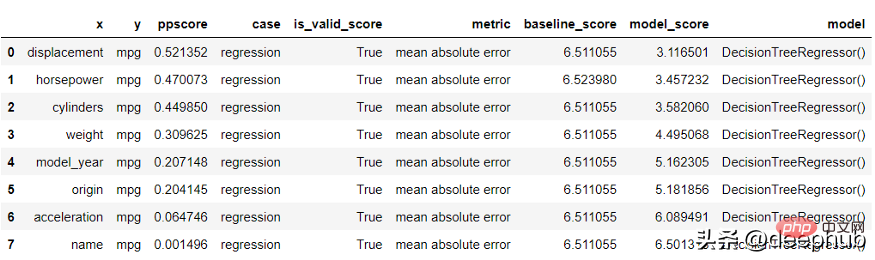
结果进行了排序。 排名越低变量对目标的预测能力越低。
12、Maya
Maya 用于尽可能轻松地解析 DateTime 数据。
pip install maya
然后我们可以使用以下代码轻松获得当前日期。
import mayanow = maya.now()print(now)
还可以为明天日期。
tomorrow = maya.when('tomorrow')tomorrow.datetime()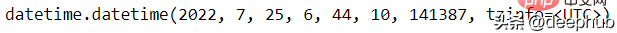
13、Pendulum
Pendulum 是另一个涉及 DateTime 数据的 python 包。 它用于简化任何 DateTime 分析过程。
pip install pendulum
我们可以对实践进行任何的操作。
import pendulumnow = pendulum.now("Europe/Berlin")now.in_timezone("Asia/Tokyo")now.to_iso8601_string()now.add(days=2)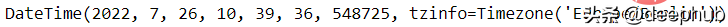
14、category_encoders
category_encoders 是一个用于类别数据编码(转换为数值数据)的python包。 该包是各种编码方法的集合,我们可以根据需要将其应用于各种分类数据。
pip install category_encoders
可以使用以下示例应用转换。
from category_encoders import BinaryEncoderimport pandas as pdenc = BinaryEncoder(cols=['origin']).fit(df)numeric_dataset = enc.transform(df)numeric_dataset.head()
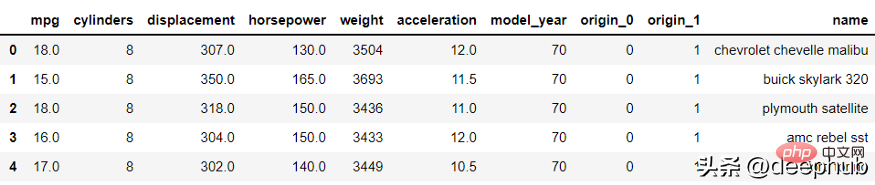
15、scikit-multilearn
scikit-multilearn 可以用于特定于多类分类模型的机器学习模型。 该软件包提供 API 用于训练机器学习模型以预测具有两个以上类别目标的数据集。
pip install scikit-multilearn
利用样本数据集进行多标签KNN来训练分类器并度量性能指标。
from skmultilearn.dataset import load_datasetfrom skmultilearn.adapt import MLkNNimport sklearn.metrics as metricsX_train, y_train, feature_names, label_names = load_dataset('emotions', 'train')X_test, y_test, _, _ = load_dataset('emotions', 'test')classifier = MLkNN(k=3)prediction = classifier.fit(X_train, y_train).predict(X_test)metrics.hamming_loss(y_test, prediction)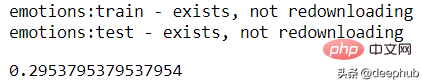
16、Multiset
Multiset类似于内置的set函数,但该包允许相同的字符多次出现。
pip install multiset
可以使用下面的代码来使用 Multiset 函数。
from multiset import Multisetset1 = Multiset('aab')set1
17、Jazzit
Jazzit 可以在我们的代码出错或等待代码运行时播放音乐。
pip install jazzit
使用以下代码在错误情况下尝试示例音乐。
from jazzit import error_track@error_track("curb_your_enthusiasm.mp3", wait=5)def run():for num in reversed(range(10)):print(10/num)这个包虽然没什么用,但是它的功能是不是很有趣,哈
18、handcalcs
handcalcs 用于简化notebook中的数学公式过程。 它将任何数学函数转换为其方程形式。
pip install handcalcs
使用以下代码来测试 handcalcs 包。 使用 %%render 魔术命令来渲染 Latex 。
import handcalcs.renderfrom math import sqrt
%%rendera = 4b = 6c = sqrt(3*a + b/7)
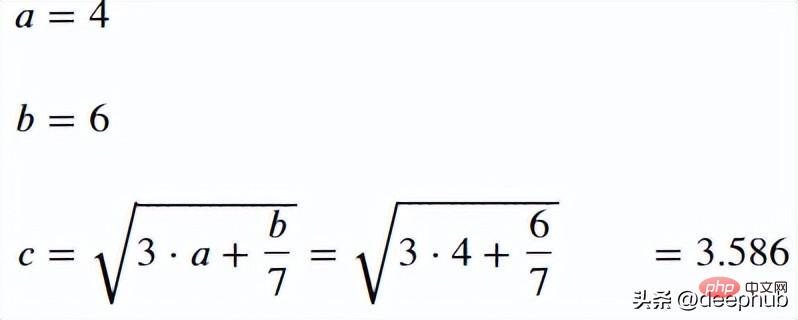
19、NeatText
NeatText 可简化文本清理和预处理过程。 它对任何 NLP 项目和文本机器学习项目数据都很有用。
pip install neattext
使用下面的代码,生成测试数据
import neattext as nt mytext = "This is the word sample but ,our WEBSITE is https://exaempleeele.com ✨."docx = nt.TextFrame(text=mytext)
TextFrame 用于启动 NeatText 类然后可以使用各种函数来查看和清理数据。
docx.describe()
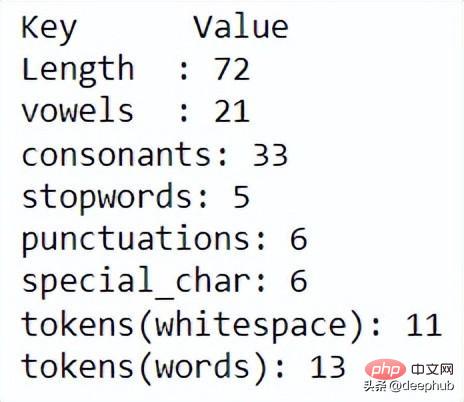
使用 describe 函数,可以显示每个文本统计信息。进一步清理数据,可以使用以下代码。
docx.normalize()
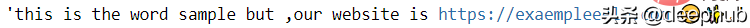
20、Combo
Combo 是一个用于机器学习模型和分数组合的 python 包。 该软件包提供了一个工具箱,允许将各种机器学习模型训练成一个模型。 也就是可以对模型进行整合。
pip install combo
使用来自 scikit-learn 的乳腺癌数据集和来自 scikit-learn 的各种分类模型来创建机器学习组合。
from sklearn.tree import DecisionTreeClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.ensemble import GradientBoostingClassifierfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.model_selection import train_test_splitfrom sklearn.datasets import load_breast_cancerfrom combo.models.classifier_stacking import Stackingfrom combo.utils.data import evaluate_print
接下来,看一下用于预测目标的单个分类器。
# Define data file and read X and yrandom_state = 42X, y = load_breast_cancer(return_X_y=True)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4,random_state=random_state)# initialize a group of clfsclassifiers = [DecisionTreeClassifier(random_state=random_state),LogisticRegression(random_state=random_state),KNeighborsClassifier(),RandomForestClassifier(random_state=random_state),GradientBoostingClassifier(random_state=random_state)]clf_names = ['DT', 'LR', 'KNN', 'RF', 'GBDT']for i, clf in enumerate(classifiers):clf.fit(X_train, y_train)y_test_predict = clf.predict(X_test)evaluate_print(clf_names[i] + ' | ', y_test, y_test_predict)print()

使用 Combo 包的 Stacking 模型。
clf = Stacking(classifiers, n_folds=4, shuffle_data=False,keep_original=True, use_proba=False,random_state=random_state)clf.fit(X_train, y_train)y_test_predict = clf.predict(X_test)evaluate_print('Stacking | ', y_test, y_test_predict)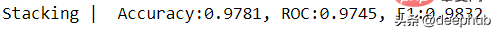
21、PyAztro
你是否需要星座数据或只是对今天的运气感到好奇? 可以使用 PyAztro 来获得这些信息! 这个包有幸运数字、幸运标志、心情等等。 这是我们人工智能算命的基础数据,哈
pip install pyaztro
使用以下代码访问今天的星座信息。
import pyaztropyaztro.Aztro(sign='gemini').description
22、Faker
Faker 可用于简化生成合成数据。 许多开发人员使用这个包来创建测试的数据。
pip install Faker
要使用 Faker 包生成合成数据
from faker import Fakerfake = Faker()
生成名字
fake.name()

每次从 Faker 类获取 .name 属性时,Faker 都会随机生成数据。
23、Fairlearn
Fairlearn 用于评估和减轻机器学习模型中的不公平性。 该软件包提供了许多查看偏差所必需的 API。
pip install fairlearn
然后可以使用 Fairlearn 的数据集来查看模型中有多少偏差。
from fairlearn.metrics import MetricFrame, selection_ratefrom fairlearn.datasets import fetch_adultdata = fetch_adult(as_frame=True)X = data.datay_true = (data.target == '>50K') * 1sex = X['sex']selection_rates = MetricFrame(metrics=selection_rate,y_true=y_true,y_pred=y_true,sensitive_features=sex)fig = selection_rates.by_group.plot.bar(legend=False, rot=0,title='Fraction earning over $50,000')
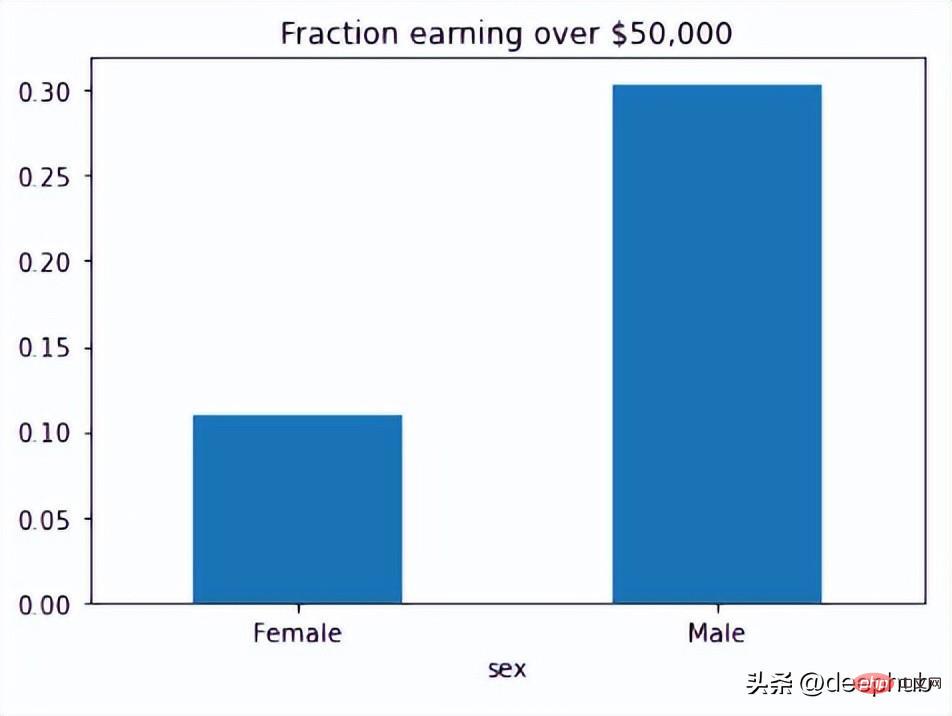
Fairlearn API 有一个 selection_rate 函数,可以使用它来检测组模型预测之间的分数差异,以便我们可以看到结果的偏差。
24、tiobeindexpy
tiobeindexpy 用于获取 TIOBE 索引数据。 TIOBE 指数是一个编程排名数据,对于开发人员来说是非常重要的因为我们不想错过编程世界的下一件大事。
pip install tiobeindexpy
可以通过以下代码获得当月前 20 名的编程语言排名。
from tiobeindexpy import tiobeindexpy as tbdf = tb.top_20()

25、pytrends
pytrends 可以使用 Google API 获取关键字趋势数据。如果想要了解当前的网络趋势或与我们的关键字相关的趋势时,该软件包非常有用。这个需要访问google,所以你懂的。
pip install pytrends
假设我想知道与关键字“Present Gift”相关的当前趋势,
from pytrends.request import TrendReqimport pandas as pdpytrend = TrendReq()keywords = pytrend.suggestions(keyword='Present Gift')df = pd.DataFrame(keywords)df
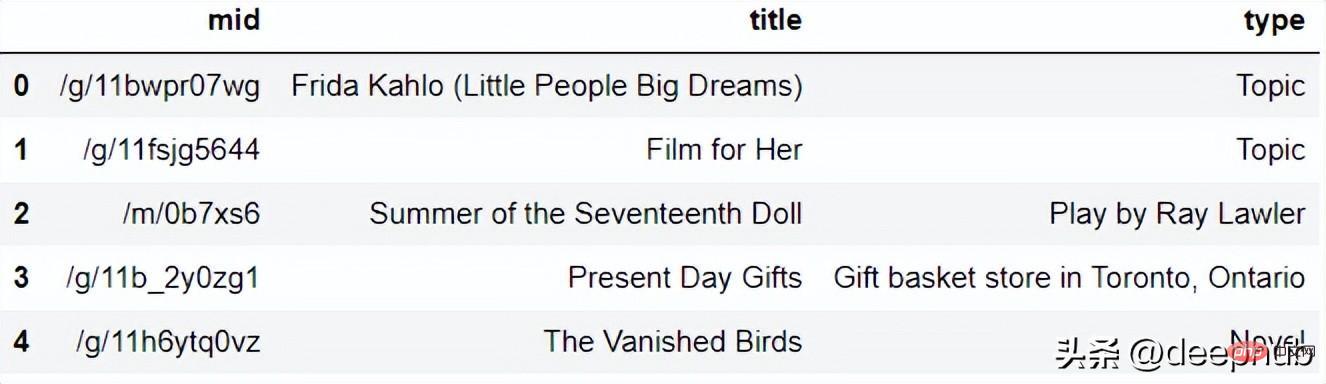
该包将返回与关键字相关的前 5 个趋势。
26、visions
visions 是一个用于语义数据分析的 python 包。 该包可以检测数据类型并推断列的数据应该是什么。
pip install visions
可以使用以下代码检测数据中的列数据类型。 这里使用 seaborn 的 Titanic 数据集。
import seaborn as snsfrom visions.functional import detect_type, infer_typefrom visions.typesets import CompleteSetdf = sns.load_dataset('titanic')typeset = CompleteSet()converting everything to stringsprint(detect_type(df, typeset))
27、Schedule
Schedule 可以为任何代码创建作业调度功能
pip install schedule
例如,我们想10 秒工作一次:
import scheduleimport timedef job():print("I'm working...")schedule.every(10).seconds.do(job)while True:schedule.run_pending()time.sleep(1)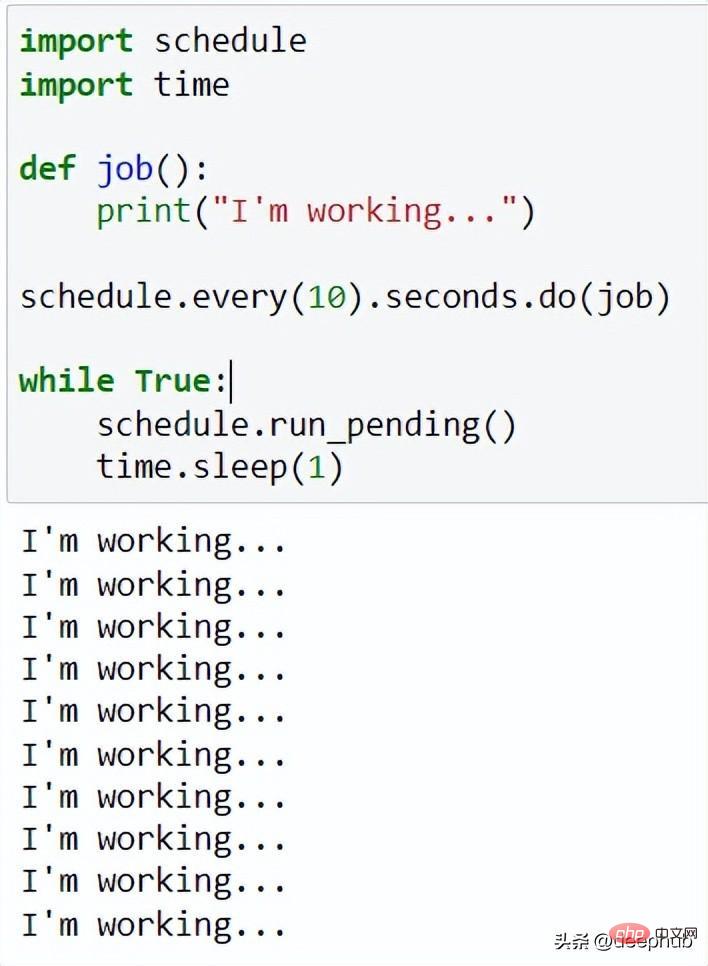
28、autocorrect
autocorrect 是一个用于文本拼写更正的 python 包,可应用于多种语言。 用法很简单,并且对数据清理过程非常有用。
pip install autocorrect
可以使用类似于以下代码进行自动更正。
from autocorrect import Spellerspell = Speller()spell("I'm not sleaspy and tehre is no place I'm giong to.")
29、funcy
funcy 包含用于日常数据分析使用的精美实用功能。 包中的功能太多了,我无法全部展示出来,有兴趣的请查看他的文档。
pip install funcy
这里只展示一个示例函数,用于从可迭代变量中选择一个偶数,如下面的代码所示。
from funcy import select, evenselect(even, {i for i in range (20)})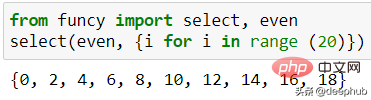
30、IceCream
IceCream 可以使调试过程更容易。该软件包在打印/记录过程中提供了更详细的输出。
pip install icecream
可以使用下面代码
from icecream import icdef some_function(i):i = 4 + (1 * 2)/ 10 return i + 35ic(some_function(121))

也可以用作函数检查器。
def foo():ic()if some_function(12):ic()else:ic()foo()
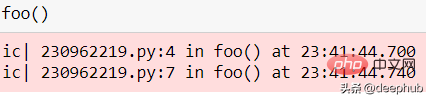
Le niveau de détail imprimé est idéal pour l’analyse.
Résumé
Dans cet article, 30 packages Python uniques utiles dans le travail sur les données sont résumés. La plupart des progiciels sont faciles à utiliser, simples et clairs, mais certains peuvent avoir plus de fonctions et nécessiter une lecture plus approfondie de leur documentation. Si vous êtes intéressé, veuillez vous rendre sur le site Web de pypi pour rechercher et consulter la page d'accueil et la documentation du package I. j'espère que cet article vous sera utile.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 HTML: Est-ce un langage de programmation ou autre chose?
Apr 15, 2025 am 12:13 AM
HTML: Est-ce un langage de programmation ou autre chose?
Apr 15, 2025 am 12:13 AM
HtmlisnotaprogrammingNanguage; itisamarkupLanguage.1) htmlstructuresAndFormaSwebContentUsingTags.2) itworkswithcssforStylingandjavaScriptForIterActivity, EnhancingWebDevelopment.
 PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python ont leurs propres avantages et inconvénients, et le choix dépend des besoins du projet et des préférences personnelles. 1.Php convient au développement rapide et à la maintenance des applications Web à grande échelle. 2. Python domine le domaine de la science des données et de l'apprentissage automatique.
 Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 PHP: une introduction au langage des scripts côté serveur
Apr 16, 2025 am 12:18 AM
PHP: une introduction au langage des scripts côté serveur
Apr 16, 2025 am 12:18 AM
PHP est un langage de script côté serveur utilisé pour le développement Web dynamique et les applications côté serveur. 1.Php est un langage interprété qui ne nécessite pas de compilation et convient au développement rapide. 2. Le code PHP est intégré à HTML, ce qui facilite le développement de pages Web. 3. PHP traite la logique côté serveur, génère une sortie HTML et prend en charge l'interaction utilisateur et le traitement des données. 4. PHP peut interagir avec la base de données, traiter la soumission du formulaire et exécuter les tâches côté serveur.
 Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
La formation distribuée par Pytorch sur le système CentOS nécessite les étapes suivantes: Installation de Pytorch: La prémisse est que Python et PIP sont installés dans le système CentOS. Selon votre version CUDA, obtenez la commande d'installation appropriée sur le site officiel de Pytorch. Pour la formation du processeur uniquement, vous pouvez utiliser la commande suivante: pipinstalltorchtorchVisionTorChaudio Si vous avez besoin d'une prise en charge du GPU, assurez-vous que la version correspondante de CUDA et CUDNN est installée et utilise la version Pytorch correspondante pour l'installation. Configuration de l'environnement distribué: la formation distribuée nécessite généralement plusieurs machines ou des GPU multiples uniques. Lieu
 Pourquoi utiliser PHP? Avantages et avantages expliqués
Apr 16, 2025 am 12:16 AM
Pourquoi utiliser PHP? Avantages et avantages expliqués
Apr 16, 2025 am 12:16 AM
Les principaux avantages du PHP comprennent la facilité d'apprentissage, un soutien solide sur le développement Web, les bibliothèques et les cadres riches, les performances élevées et l'évolutivité, la compatibilité multiplateforme et la rentabilité. 1) Facile à apprendre et à utiliser, adapté aux débutants; 2) une bonne intégration avec les serveurs Web et prend en charge plusieurs bases de données; 3) ont des cadres puissants tels que Laravel; 4) Des performances élevées peuvent être obtenues grâce à l'optimisation; 5) prendre en charge plusieurs systèmes d'exploitation; 6) Open source pour réduire les coûts de développement.
